一:消息队列(message queue MQ):
1.1消息队列解释:用来存储消息的队列
简单理解就是将需要的数据传输到队列里,队列可存可取,like 一个管道,但是与hdfs不同的是kafka作为临时存储
1.2消息队列中间件
消息队列中间件其实就是一个组件,简单例子就是用户对于服务器产生的数据,比如点击链接,这时服务器端会接收消息并回馈,而这个行为log将会被记录到消息队列,以后可以用应用程序来处理这些日志log.可以理解为存储消息的软件。
1.3异步处理
概念:将耗时任务放入消息队列中,生产者发送完消息后无需等待消费者处理完成,即可继续执行其他任务。从而实现快速响应。
比如:电商系统中,用户下单后,系统需要通知仓库发货。如果没有MQ,系统可能会等到仓库处理完才告诉用户下单成功,这样用户就得等很久。但有了MQ,系统可以先快速告诉用户"订单已成功",后续的仓库处理则通过MQ异步通知,用户不用等待后台所有流程结束。
1.4系统解耦
概念:一种系统架构设计策略,旨在通过消息队列中间件来减少系统各组件或服务之间的直接依赖关系。
**原理:**MQ系统作为中介,使得生产方和消费方可以独立地运行和扩展,无需相互依赖。生产方将消息发送到MQ中,不需要关心消息如何被处理以及何时被处理,而消费方则从MQ中获取消息并进行处理。这种解耦性提高了系统的灵活性和可扩展性
应用场景:
电商系统:在电商系统中,订单服务、库存服务、支付服务等可能需要相互通信。如果没有MQ,这些服务可能会紧密耦合,难以独立扩展和维护。通过引入MQ,订单服务下单后可以将消息发送到MQ中,库存服务和支付服务可以根据自己的情况异步处理消息,从而实现了解耦。
日志处理系统:在日志处理系统中,不同的日志来源(如Web服务器、数据库等)可能需要将日志发送到统一的处理中心。通过使用MQ,日志来源可以将日志消息发送到MQ中,而处理中心则可以从MQ中获取日志消息并进行统一处理,从而实现了解耦。
1.5流量削峰
概念:一种系统架构设计策略,旨在通过消息队列中间件来应对突发的高并发请求,从而保护下游系统免受流量冲击。
场景与原理:在高并发场景下,如电商秒杀活动、大型促销活动等,大量请求会在短时间内涌入系统。如果没有MQ,这些请求直接打到后端服务,很可能导致后端服务因无法处理过多请求而崩溃或响应缓慢。而MQ作为缓冲层,接收这些海量请求,将它们暂存起来。后端服务可以按照自身的处理能力,从MQ中拉取消息进行处理。
1.6日志处理
一般大型电商web处理日志不会放进database中,而是做一个log文件传入到MQ,然后用处理系统(可以是spark,flink框架)拉取进行处理,结果反馈到redis中
1.7生产者消费者模型
生产者(Producer):
生产者是消息的生产者,它将消息发布到Kafka的主题(Topic)中。
消费者(Consumer):
消费者是消息的消费者,它订阅一个或多个主题,并从Broker中消费消息**。**
MQ:
作为上两者的过渡,生产者发送到这,消费者订阅,拉取MQ。
1.8消息队列两种模式
(1)点对点模式
producer生产消息到MQ,consumer从MQ中取出message,message被消费后MQ不再存储,所以consumer不会接收到已消费的message。
特点:
每个message只对应一个consumer
producer与consumer间没有依赖性,发送message后不管consumer的运行都不会影响到producer再次发送message
(2)发布订阅模式
生产者发送消息到交换机中,由交换机分发到不同的消息队列,让不同消费者拉取进行消费

特点:每个消息有多个消费者。发布者与订阅者有时间上的依赖性,针对一个topic的订阅者必须创建一个订阅者才可消费
二:kafka概述
什么是kafka

重点词:发布订阅(publish,subscribe),存储(store),处理(process)
三、安装部署kafka
看我的部署文章
kafka安装部署![]() https://blog.csdn.net/m0_72898512/article/details/142862855
https://blog.csdn.net/m0_72898512/article/details/142862855
3.2目录结构:
bin:kafka的所有执行脚本
config:配置文件
libs:运行kafka所需的jar包
logs:日志文件
site-docs:kafka网站帮助文件
3.3一键启动脚本:(跟着修改)
启动:kafka.sh start 关闭:kafka.sh stop
bash
#! /bin/bash
case $1 in
"start"){
for i in wtk wtk1 wtk2
do
echo "============ $i ==========="
ssh $i "/export/server/kafka_2.12-3.8.0/bin/kafka-server-start.sh -daemon /export/server/kafka_2.12-3.8.0/config/server.properties"
echo "success to start $i kafka"
echo -e ""
done
};;
"stop"){
for i in wtk wtk1 wtk2
do
echo "============= $i ==============="
ssh $i "/export/server/kafka_2.12-3.8.0/bin/kafka-server-stop.sh"
echo "success to stop $i kafka"
echo -e ""
done
};;
esac3.4验证安装
命令:kafka-topics.sh --bootstrap-server wtk:9091,wtk1:9092,w2:9093 --list

四、基础操作
**(1)Producer :**消息生产者,就是向kafka broker发消息的客户端;
**(2)Consumer :**消息消费者,向kafka broker取消息的客户端;
(3)Topic : 可以理解为一个队列,生产者和消费者面向的都是一个topic;
创建topic:
命令:kafka-topics.sh --bootstrap-server wtk:9091 --create --topic first
查看topic:
命令:kafka-topics.sh --bootstrap-server wtk:9091 --list
生产消息:
kafka-console-producer.sh --bootstrap-server wtk:9091 --topic first
消费消息:
kafka-console-consumer.sh --bootstrap-server wtk:9091 --topic first --from-beginning
五:基准测试:
基准测试(benchmark testing)是一种测量和评估软件性能指标的活动。我们可以通过基准测试,了解到软件、硬件的性能水平。主要测试负载的执行时间、传输速度、吞吐量、资源占用率等。
步骤:创建topic 同时运行producer consumer,观察结果
(1)kafka-topics.sh --bootstrap-server wtk:9091,wtk1:9092,wtk2:9093 --create --topic first --partitions 1 --replication-factor 1
(2)kafka-producer-perf-test.sh --topic first --num-records 500 --throughput -1 --record-size 1000 --producer-props bootstrap.servers=wtk:9091,wtk1:9092,wtk2:9093 acks=1

运行结果:

吞吐量:377.643505 records/sec(每秒多少条记录),吞吐速率:0.36MB/sec(每秒多少数据),avg latency平均延迟时间 max latency最大延迟时间
(3)kafka-consumer-perf-test.sh --topic first --fetch-size 1048576 --messages 500 --broker-list wtk:9091,wtk1:9092,wtk2:9093

运行结果:
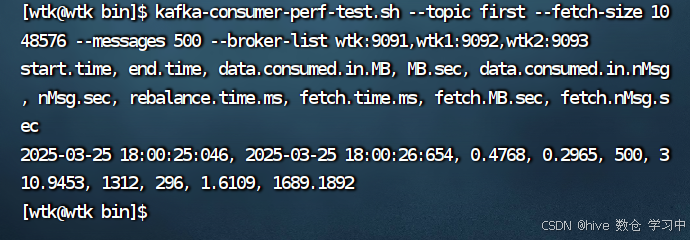
data.consumed.in.MB共计消费的数据:0.4768 MB.sec每秒消费的数量:0.2965