最近爆火的 MCP(Model Context Protocol)是什么?它能做什么?MCP 将如何影响大模型领域,带来哪些新的机遇和挑战?今天,我们通过一个实战案例,带您深入了解 MCP。
什么是 MCP
MCP,全称 Model Context Protocol,由 Anthropic 在 2024 年 11 月推出的,社区共建的开放协议。目的是提供一个通用的开放标准,用来连接大模型和外部数据、行为。
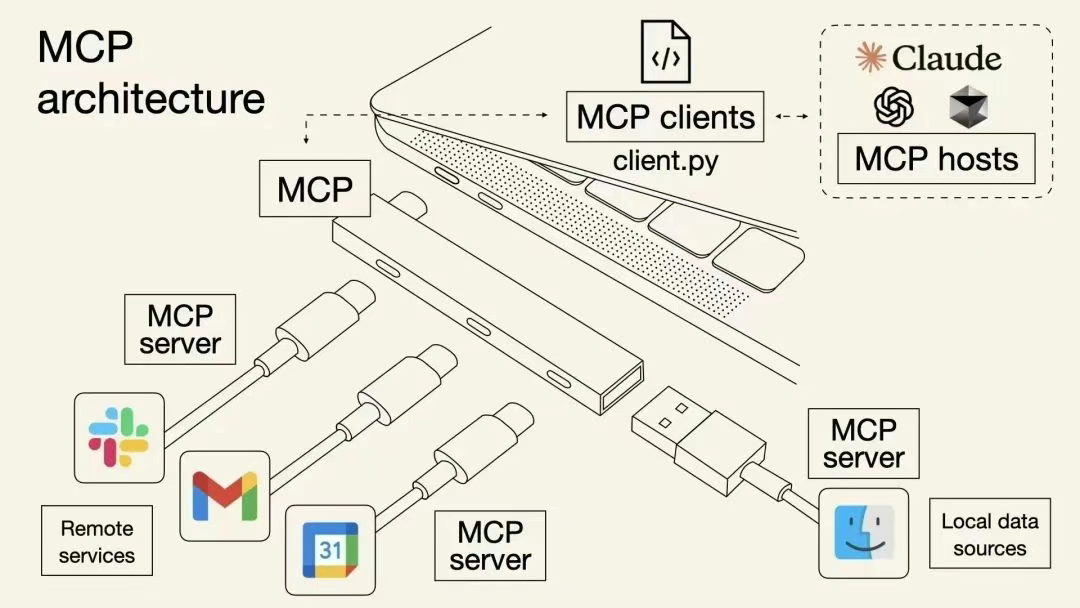
可以将 MCP 想象成 大模型应用程序的 USB-C 接口。就像 USB-C 为连接设备到各种外围设备和配件提供了标准化方式一样,MCP 为连接 AI 模型到不同数据源和工具提供了标准化方式。
为什么需要 MCP
一般来说,将 AI 系统连接到外部工具需要集成多个 API。而每个 API 集成都意味着需要单独的代码、文档、认证方式、错误处理和持续维护
| 特性 | MCP | API |
|---|---|---|
| 集成工作量 | 单一且标准化的集成 | 每个 API 需要单独集成 |
| 实时通信 | ✅ 支持 | ❌ 不支持 |
| 动态发现 | ✅ 支持 | ❌ 不支持 |
| 可扩展性 | 即插即用,容易扩展 | 需要额外集成 |
| 安全性和控制 | 工具间一致 | 因 API 而异 |
如何使用 MCP
MCP 基本架构
MCP 遵循客户端-服务器架构,其中一个宿主应用程序可以连接到多个服务器
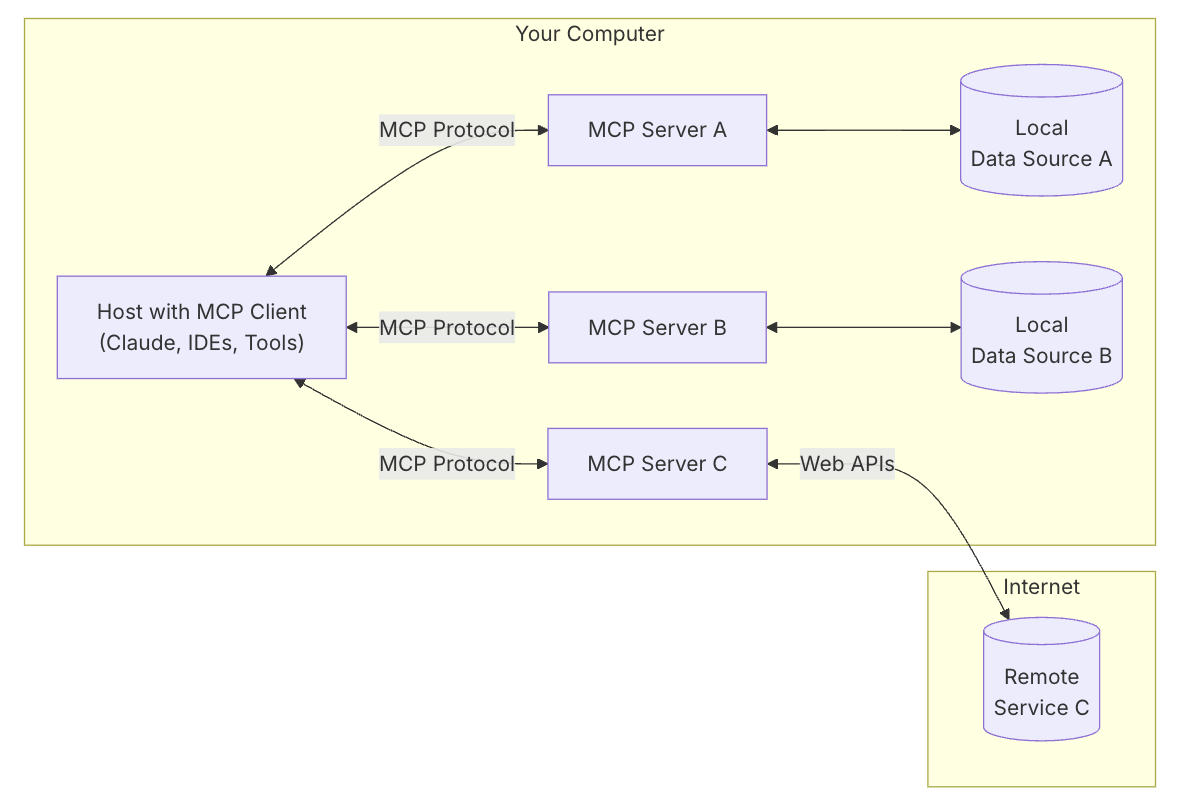
主要有以下几个概念:
-
MCP Host :LLM 的宿主应用,比如 Cursor、Cline 等等,是处理一个或多个 MCP Server 的应用程序。
-
MCP Client:Host 内部专门用于与 MCP Server 建立和维持一对一连接的模块。它负责按照 MCP 协议的规范发送请求、接收响应和处理数据。简单来说,MCP Client 是 Host 内部处理 RPC 通信的"代理",专注于与一个 MCP Server 进行标准化的数据、工具或 prompt 的交换。
-
MCP Server:提供外部能力或数据的工具,比如访问本地文件、实时获取天气、浏览网页等等能力
-
本地数据源:计算机上的文件、数据库和服务,MCP 服务器可以安全地访问这些内容
-
远程服务:通过互联网可用的外部系统(例如,通过 API),MCP 服务器可以连接到这些系统
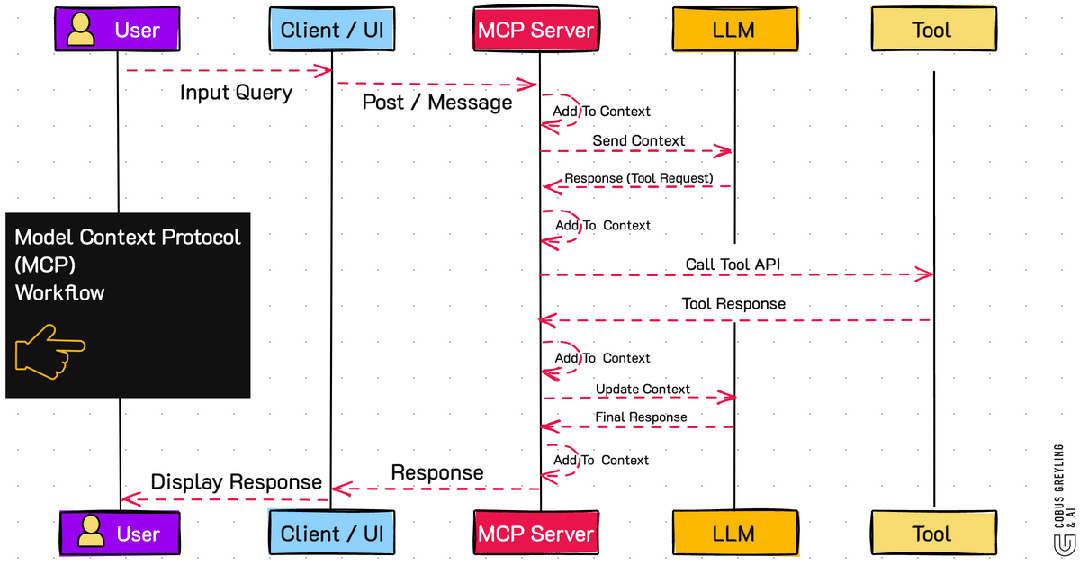
MCP 典型场景
MCP Server 开发
以 Python SDK 为例,参考文档:modelcontextprotocol.io/quickstart/...
Bash
pip install mcp将 API 调用封装为一个 MCP Server
Python
from typing import Any
import httpx
import json
from mcp.server.fastmcp import FastMCP
# Initialize FastMCP server
mcp = FastMCP("API")
# Constants
API_URL = "天气查询API地址"
async def make_api_request(data: dict) -> dict[str, Any] | None:
"""Make a request to the smartdr with proper error handling."""
headers = {
"Accept": "application/json"
}
async with httpx.AsyncClient() as client:
try:
response = await client.post(API_URL, headers=headers, data=data, timeout=30.0)
response.raise_for_status()
return response.json()
except Exception as e:
return str(e)
@mcp.tool()
async def make_api_request(location: str) -> dict[str, Any] | None:
"""根据位置信息查询对应的天气
Args:
location: 地理位置信息
"""
request = {"query": location}
data = await make_api_request(json.dumps(request))
if not data:
return "请求失败. data: {}".format(data)
return data
if __name__ == "__main__":
# Initialize and run the server
mcp.run(transport='stdio')MCP 项目实战
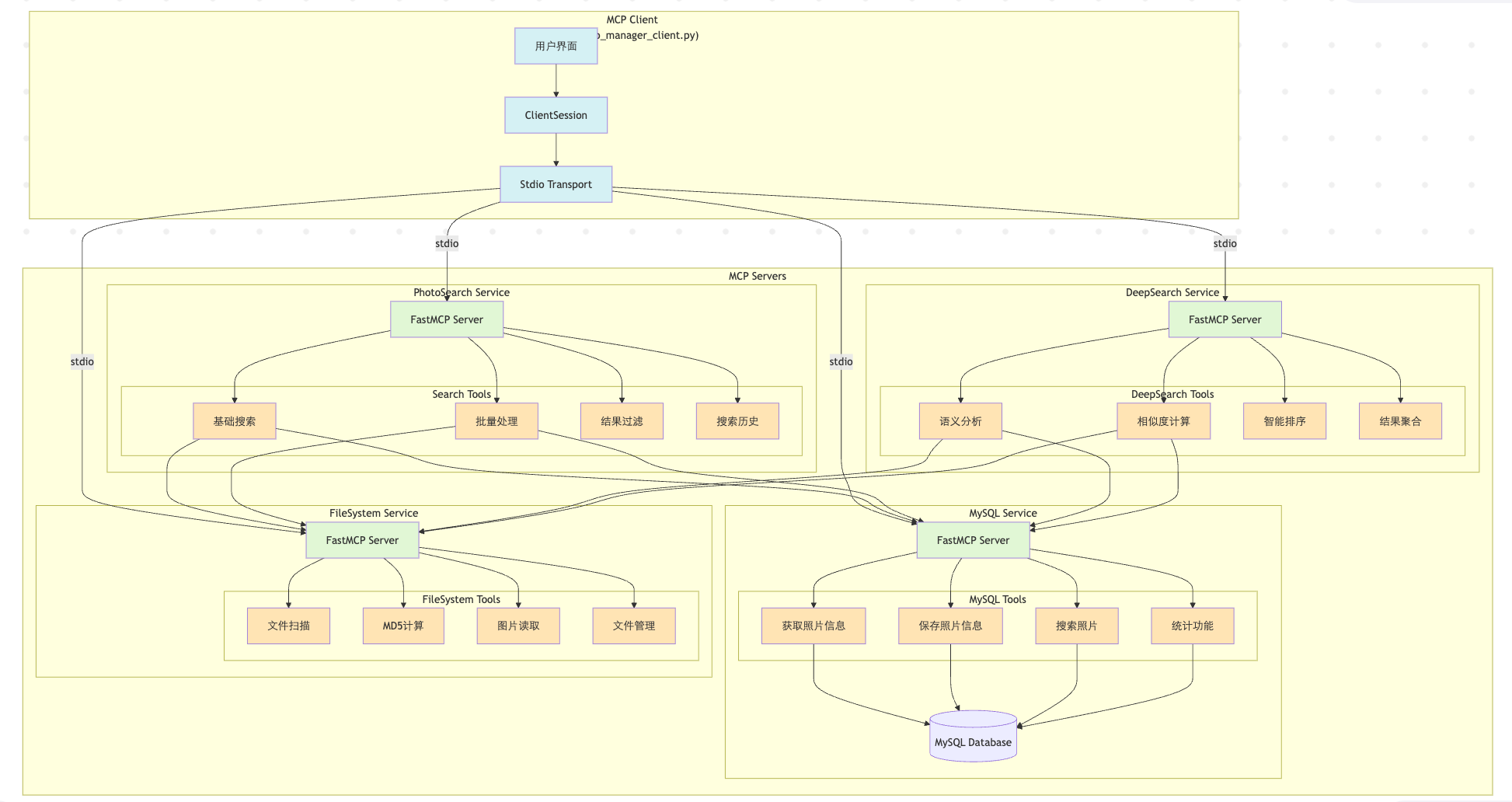
本项目基于 MCP 架构构建了一套智能图片管理系统,能够自动解析图片内容,并支持用户通过自然语言进行快速检索。
项目架构图
MCP Server 实现:
我们以 Mysql 服务为例,说明下如何搭建自己的 MCP Server
准备工作:MySQL 连接配置,以及连接池、库表初始化
Python
MYSQL_CONFIG = {
"host": "localhost",
"user": "root",
"password": "",
"database": "photo_manager",
"pool_size": 5,
"charset": "utf8mb4", # 添加字符集配置
"use_unicode": True # 确保使用Unicode
}
try:
connection_pool = mysql.connector.pooling.MySQLConnectionPool(
pool_name="photo_manager_pool",
pool_size=MYSQL_CONFIG["pool_size"],
**{k: v for k, v in MYSQL_CONFIG.items() if k != "pool_size"}
)
except Exception as e:
print(f"创建MySQL连接池失败: {e}")
connection_pool = None
def get_connection():
if connection_pool:
return connection_pool.get_connection()
raise Exception("MySQL连接池未初始化")
# 初始化数据库和表
def init_database():
#初始化库表内容,这里不再赘述然后开始创建我们的 MCP Server,这里我们使用 FastMCP 来初始化,命令很简单
Python
from mcp.server.fastmcp import FastMCP
# 初始化FastMCP服务器,指定服务名称
mcp = FastMCP("MySQL")接下来我们要进行工具函数的定义,要注意这里的注释也是很重要的,后面 client 在选择工具的时候,依据就是注释里的内容,所以要写清工具的作用。
这里我们以根据 id 获取照片信息为例,创建 tool
Python
@mcp.tool()
async def get_photo_by_id(photo_id: int) -> Dict[str, Any]:
"""根据ID获取照片信息
Args:
photo_id: 照片ID
"""
try:
conn = get_connection()
cursor = conn.cursor(dictionary=True)
cursor.execute("SELECT * FROM photos WHERE id = %s", (photo_id,))
result = cursor.fetchone()
cursor.close()
conn.close()
return result if result else {"error": "照片不存在"}
except Exception as e:
return {"error": str(e)}很简单,这样一个 tool 就创建完了,最后启动下服务就可以了。
Python
if __name__ == "__main__":
# 使用 stdio transport 运行服务器
mcp.run(transport='stdio')MCP Client 实现
接下来我们来测试下工具的功能是否符合预期,我们来写一个简单的 MCP Client。
首先定义连接 MCP Server 的参数,mcp_mysql.py 就是上面我们所创建的 MCP 服务
Python
server_params = StdioServerParameters(
command="python3",
args=["mcp_mysql.py"], # 连接到 MySQL MCP 服务器
env=None,
)然后我们再定义一个模块来实现采样消息处理,这个模块可以帮助我们获取实时的操作状态反馈,优化用户体验
Python
async def handle_sampling_message(
message: types.CreateMessageRequestParams,
) -> types.CreateMessageResult:
return types.CreateMessageResult(
role="assistant",
content=types.TextContent(
type="text",
text="MySQL服务器响应",
),
model="test-model",
stopReason="endTurn",
)通过这个处理器,我们可以看到如下的信息,这样的实现可以让用户实时了解长时间运行操作的进度,提供更好的用户体验。
Python
正在搜索照片: 已处理 450/1000 张照片 (45%)
正在保存照片信息: 正在计算MD5值接下来要定义结果处理工具,来处理不同格式的返回内容
Python
async def print_result(result):
"""打印结果的辅助函数"""
def extract_content(obj):
if hasattr(obj, 'content'):
if isinstance(obj.content, list):
return [extract_content(item) for item in obj.content]
return extract_content(obj.content)
if hasattr(obj, 'text'):
try:
return json.loads(obj.text)
except:
return obj.text
return str(obj)
try:
content = extract_content(result)
if isinstance(content, list):
for item in content:
print(json.dumps(item, ensure_ascii=False, indent=2))
else:
print(json.dumps(content, ensure_ascii=False, indent=2))
except Exception as e:
print(f"处理结果时出错: {e}")
print(f"原始结果: {result}")这部分代码是建立 MCP 客户端连接的核心部分:
-
建立标准输入输出连接
-
使用 stdio_client 创建与服务器的标准输入输出通信通道
-
server_params 就是前面我们定义的连接的服务的配置
-
read 和 write 是用于与服务器通信的流对象
-
Python
async def run():
async with stdio_client(server_params) as (read, write):-
创建客户端会话
-
使用 ClientSession 创建一个会话实例
-
传入通信流( read 和 write )
-
设置采样消息处理回调函数
-
使用上下文管理器( with )确保资源正确释放
-
Python
async with ClientSession(
read, write, sampling_callback=handle_sampling_message
) as session:-
初始化连接
-
执行会话初始化
-
与服务器建立握手
-
准备开始通信
-
Python
await session.initialize()我们来测试下刚刚封装的工具
Python
print("\n获取ID为1的照片信息:")
result = await session.call_tool("get_photo_by_id", arguments={"photo_id": 1})
await print_result(result)最后运行
Python
if __name__ == "__main__":
asyncio.run(run())可以看到脚本执行后,成功地从数据库中查询到了 id 为 1 的图片的信息,证明我们的 MCP Server 和 MCP Client 都已经工作正常了
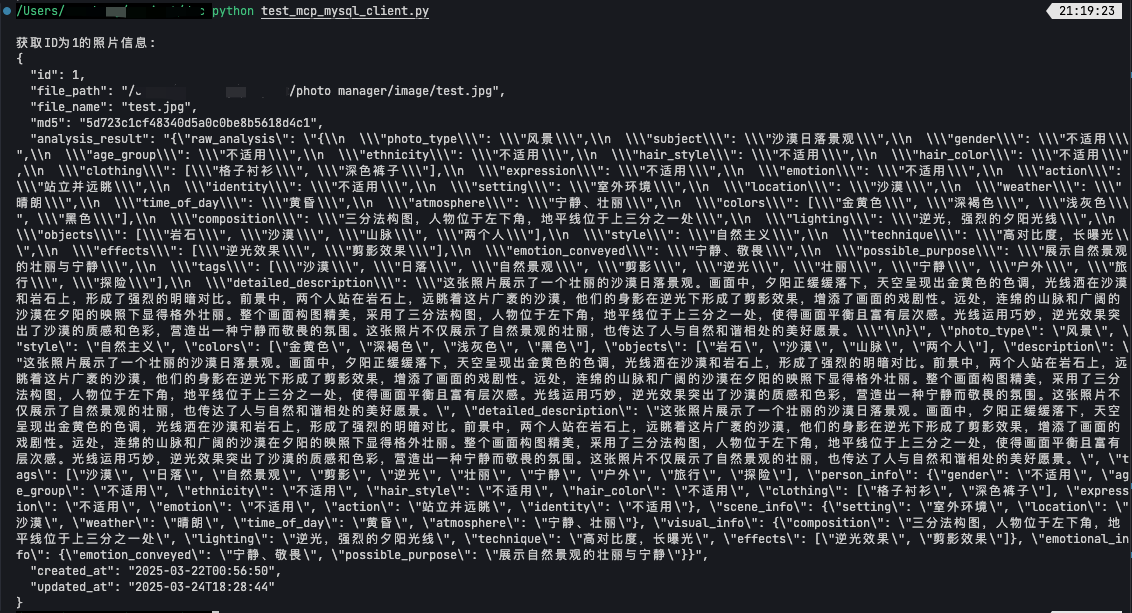
接下来要做的就是仿照上面的方法,增加更多的 MCP Server 和 Tool,然后在 Client 中去调用,为了实现我们项目的预期功能,我们共封装了几类 MCP Server:
-
Filesystem MCP Server
-
文件系统扫描和监控
-
图片文件的基础操作(读取、移动、删除等)
-
计算文件 MD5 值
-
文件元数据提取(创建时间、修改时间等)
-
目录结构管理和遍历
-
-
MySQL MCP Server
-
照片信息的持久化存储
-
照片元数据管理(路径、MD5、分析结果等)
-
数据库的 CRUD 操作
-
照片信息的批量处理
-
数据统计功能(总数、分类统计等)
-
-
PhotoSearch MCP Server
-
基于关键词的快速搜索
-
文件名匹配
-
标签匹配
-
元数据过滤
-
结果排序和分页
-
-
DeepSearch MCP Server
-
基于语义的深度搜索
-
相似度计算
-
多维度匹配(场景、物体、人物等)
-
智能排序
-
搜索结果聚合
-
-
Qianfan MCP Server
-
图像内容分析
-
场景识别
-
物体检测
-
人物特征提取
-
图片描述生成
-
语义相似度计算
-
自然语言理解
-
多模态分析
-
实现图片自动管理功能
接下来我们就可以轻松的组装这些工具,来实现图片智能管理功能了。
我们做一个定时任务,流程如下:
系统首先通过 **mcp_filesystem** 中的工具扫描指定目录,获取所有图片文件。对于每个图片,使用 **get_file_md5** 计算其MD5值,然后调用 **get_photo_by_md5** 检查数据库中是否已存在该图片。
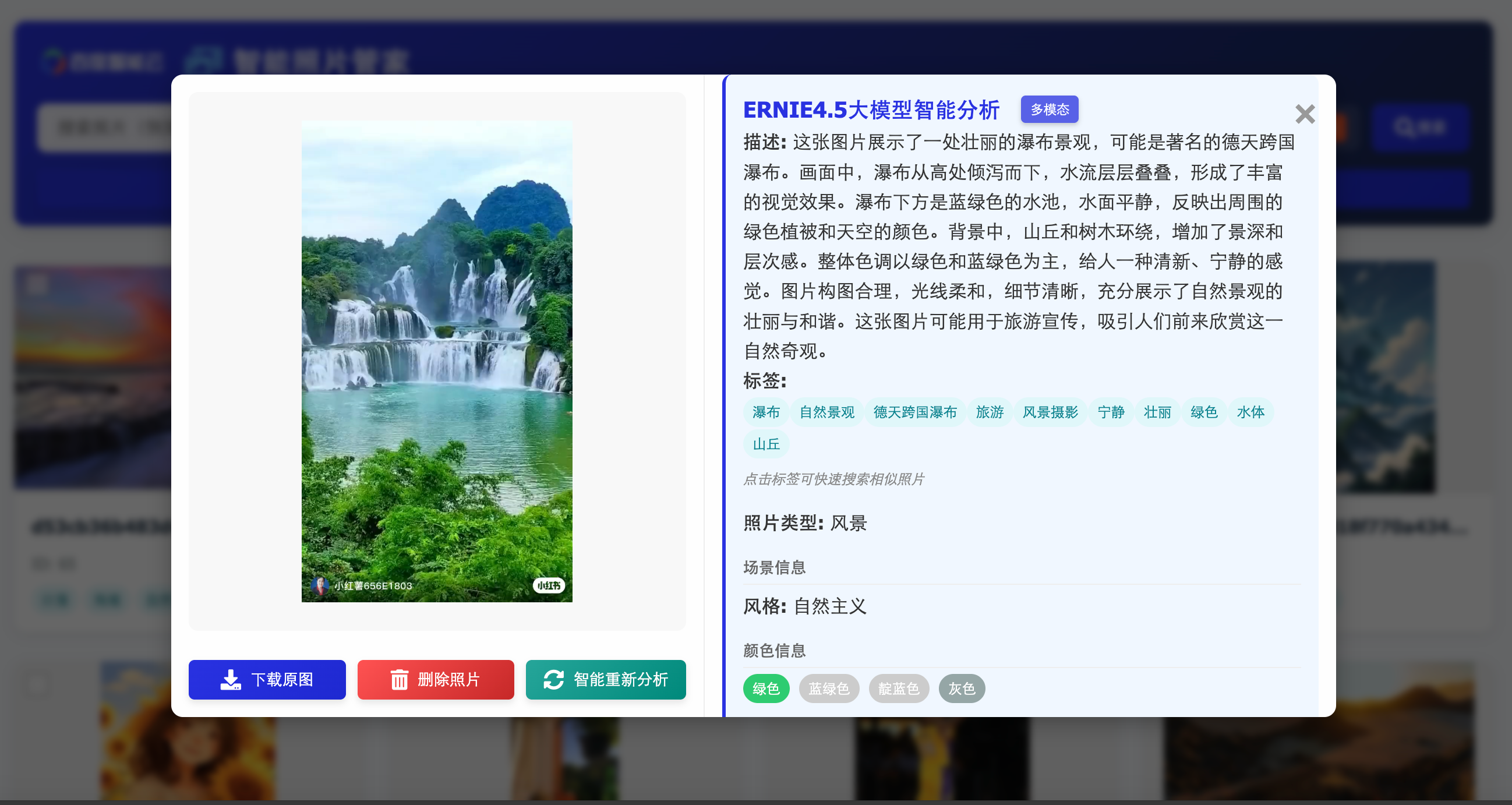
对于新图片,系统会调用 **mcp_photo_analyzer** 中的 **get_image_analysis** 工具进行内容分析,该工具会通过千帆 4.5多模态大模型对图片的场景、主题等信息进行深度分析,然后使用 **save_photo_info** 将图片信息和分析结果保存到数据库。
以下是主要代码框架
Python
class PhotoClient:
def __init__(self, watch_dir: str = "监控的图片文件夹", scan_interval: int = 3600):
self.session = None
self.watch_dir = watch_dir
self.scan_interval = scan_interval # 扫描间隔(秒)
self.running = False
async def init_session(self):
"""初始化MCP客户端会话"""
self.session = ClientSession()
await self.session.connect()
async def get_file_md5(self, file_path: str) -> str:
"""获取文件MD5值"""
return await self.session.call("FileSystem.get_file_md5", file_path)
async def check_photo_exists(self, md5: str) -> bool:
"""检查照片是否已存在于数据库"""
result = await self.session.call("MySQL.get_photo_by_md5", md5)
return not (isinstance(result, dict) and "error" in result)
async def analyze_photo(self, file_path: str) -> str:
"""调用千帆4.5分析图片"""
return await self.session.call("PhotoAnalyzer.get_image_analysis", file_path)
async def save_to_database(self, file_path: str, file_name: str, md5: str, analysis: str) -> Dict:
"""保存照片信息到数据库"""
return await self.session.call("MySQL.save_photo_info",
file_path=file_path,
file_name=file_name,
md5=md5,
analysis_result=analysis)
async def process_photo(self, file_path: str) -> Dict:
"""处理单个照片的完整流程"""
# 实现照片处理流程
pass
async def scan_directory(self):
"""扫描目录处理所有图片"""
# 实现目录扫描逻辑
pass
async def start_scheduled_scan(self):
"""启动定时扫描"""
self.running = True
while self.running:
await self.scan_directory()
await asyncio.sleep(self.scan_interval)
async def stop_scanning(self):
"""停止定时扫描"""
self.running = False
async def close(self):
"""关闭会话"""
if self.session:
await self.session.close()
async def main():
client = PhotoClient()
try:
await client.init_session()
# 启动定时扫描
# await client.start_scheduled_scan()
# 或者执行一次扫描
await client.scan_directory()
finally:
await client.close()
if __name__ == "__main__":
asyncio.run(main())实际效果如下,至此我们就完成了图片的自动纳管与分析,并使用百度最新的千帆 4.5 多模态大模型进行分析解读。
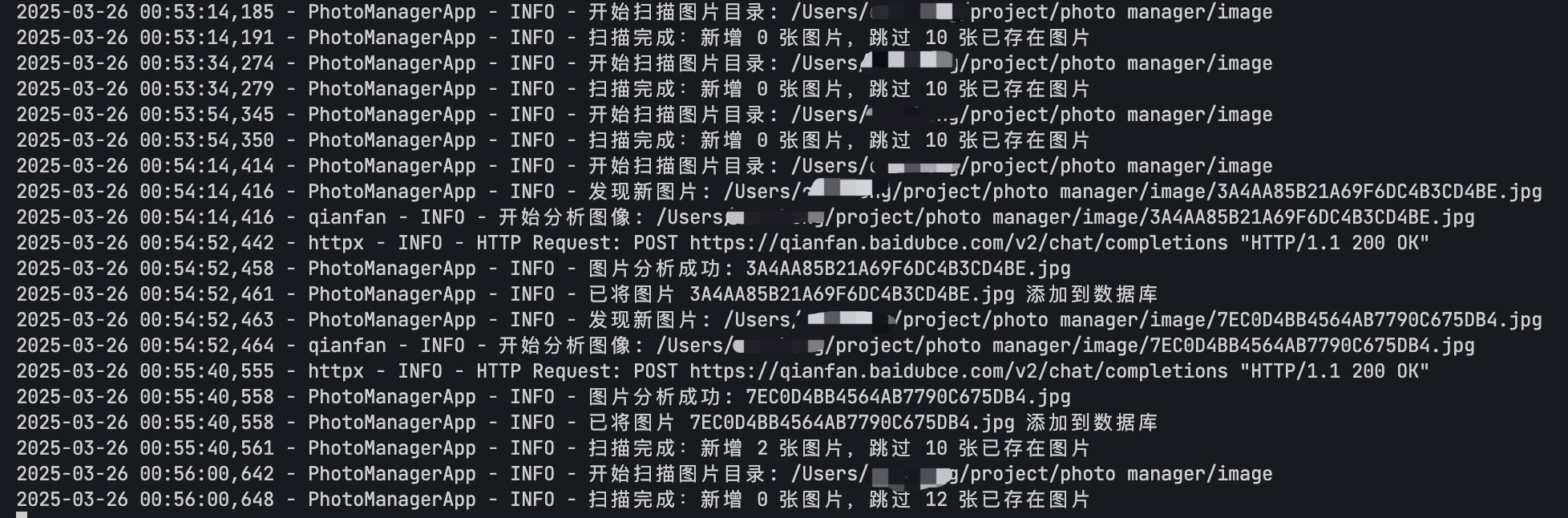
与传统的纯文本大模型相比,千帆 4.5 多模态大模型是新一代原生多模态基础大模型,通过多个模态联合建模实现协同优化,多模态理解能力优秀;具备更精进的语言能力,理解、生成、逻辑、记忆能力全面提升,去幻觉、逻辑推理、代码能力显著提升。
快速体验链接: 快速体验千帆 4.5 多模态大模型
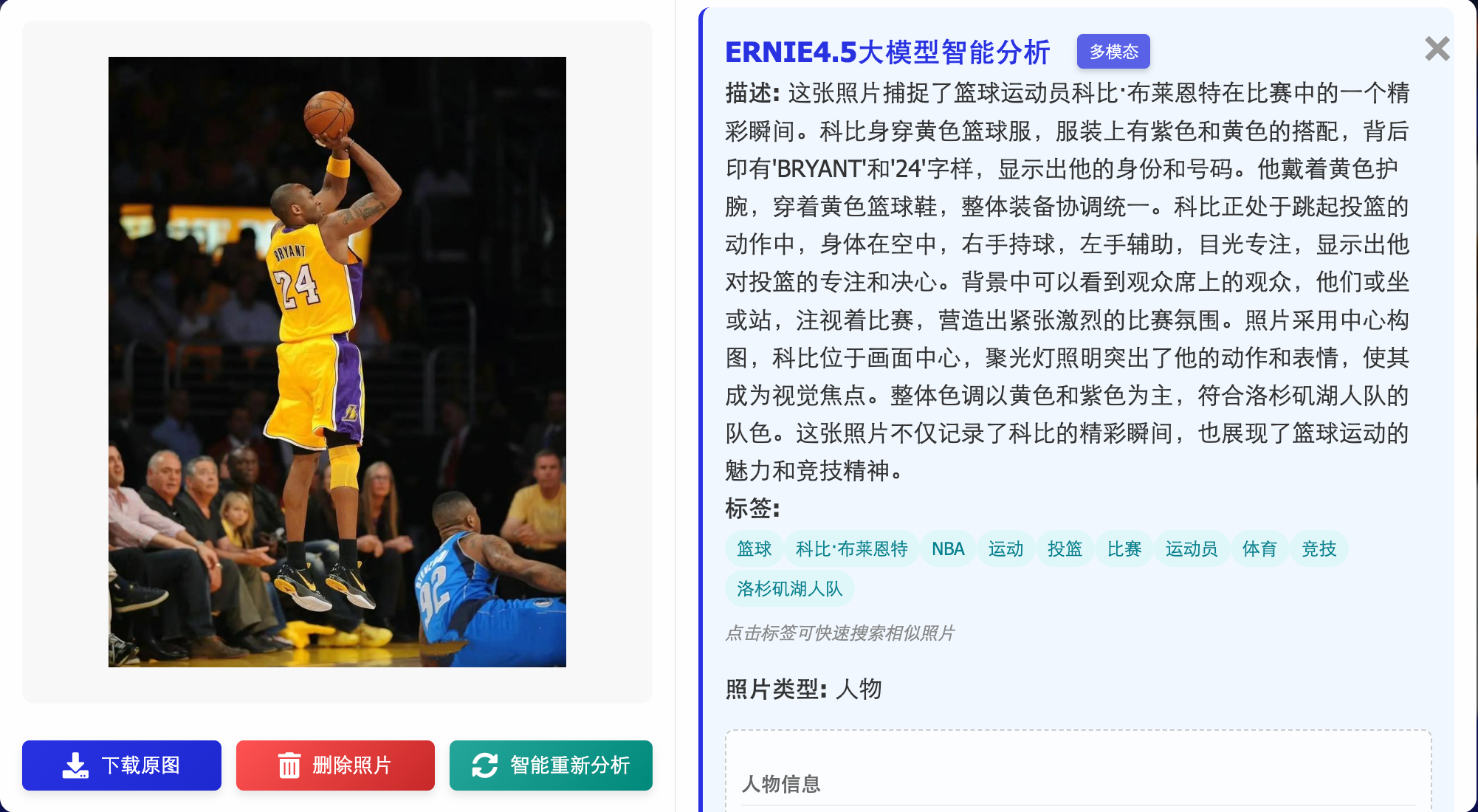
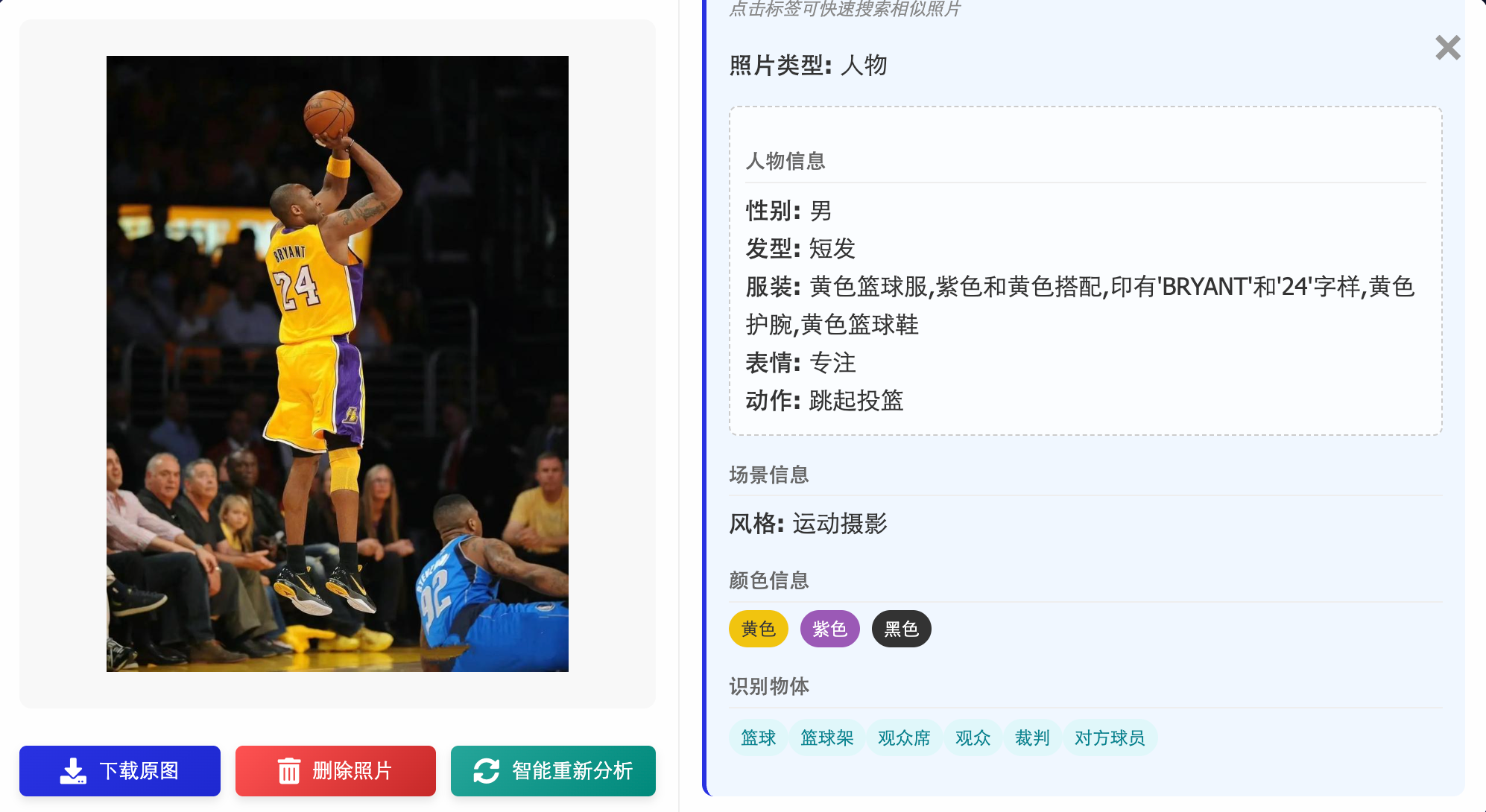
将 LLM 集成到 MCP Client 中,实现智能问答
接下来,我们要为 MCP Client 加入智能问答功能。在之前的实现中,我们是通过具体命令调用指定工具的,但既然目标是智能问答,我们希望工具能够更智能,能够理解用户的自然语言,并自动完成相应任务。因此,我们需要将大模型的能力引入到 Client 中,本项目采用 千帆大模型 作为 LLM 模块,以提升交互的智能化水平。
如我们这个实战项目所展示的,当前越来越多的企业、个人、乃至各类应用场景都在接入大模型,对 大模型开发人才的需求也在持续增长 。然而,很多开发者在接触 LLM 时,往往会遇到 难以理解 Transformer 机制、模型微调复杂、缺少实战经验 等挑战。如果你也有类似困惑,可以考虑系统性学习,以下课程或许能帮助你更快上手:
-
工信部 AIGC 应用开发工程师认证课程:涵盖大模型核心理论,结合丰富的项目实战,助力快速掌握 LLM 开发。
-
百度大模型认证课程:专注于百度大模型生态,提供系统化培训和实战指导。
-
DeepSeek 在线课程:面向大模型开发者,涵盖 Transformer 机制、微调技巧等关键知识。
接下来,我们将具体实现智能问答功能,并演示如何让 MCP Client 结合大模型,实现更自然、高效的人机交互。
首先定义我们的 client 以及可以使用的 MCP 服务,并动态加载各个 MCP 服务,使用 stdio transport 进行通信
Python
class PhotoManagerClient:
def __init__(self):
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
self.running = True
# 服务列表定义
self.available_services = [
"photo_analyzer",
"photo_search",
"deep_search",
"mysql",
"filesystem"
]
async def connect_to_services(self):
for service_name in self.available_services:
# 构建服务路径
script_path = os.path.join(
os.path.dirname(os.path.abspath(__file__)),
f"mcp_{service_name}.py"
)
# 创建服务连接
server_params = StdioServerParameters(...)
stdio_transport = await self.exit_stack.enter_async_context(...)
session = await self.exit_stack.enter_async_context(...)最关键的查询处理流程
Python
async def process_query(self, query: str) -> str:
"""处理用户查询"""
# 1. 初始化对话
messages = [{"role": "user", "content": query}]
# 2. 收集可用工具信息
available_tools = []
for service_name, session in self.service_sessions.items():
tools_response = await session.list_tools()
for tool in tools_response.tools:
available_tools.append({
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": tool.inputSchema
}
})
# 3. 第一轮对话:让大模型选择工具
response = self.client.chat.completions.create(
model="ernie-4.0-turbo-128k",
messages=messages,
tools=available_tools,
tool_choice="auto",
stream=False,
temperature=0.1
)
# 4. 执行工具调用
message = response.choices[0].message
if message.tool_calls:
all_results = [] # 存储所有工具调用结果
for tool_call in message.tool_calls:
function_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
# 执行工具调用并收集结果
session = self.service_sessions[found_service]
result = await session.call_tool(function_name, tool_args)
# 处理工具返回结果
content = result.content.text
result_json = json.loads(content)
all_results.append(result_json)
# 更新对话历史
messages.extend([
{
"role": "assistant",
"content": None,
"tool_calls": [{"id": tool_call.id, "type": "function",
"function": {"name": function_name,
"arguments": json.dumps(tool_args, ensure_ascii=False)}}]
},
{
"role": "tool",
"name": function_name,
"tool_call_id": tool_call.id,
"content": content
}
])
# 5. 第二轮对话:生成最终答案
messages.append({
"role": "user",
"content": "结合我的问题,以及工具的搜索结果,给出解答"
})
response = self.client.chat.completions.create(
model="ernie-4.0-turbo-128k",
messages=messages,
stream=False,
temperature=0.1
)
# 6. 格式化输出结果
message = response.choices[0].message
if message.content:
final_result = "=== 分析结果 ===\n"
# 添加文件信息
for result in all_results:
if isinstance(result, dict) and 'file_name' in result:
final_result += f"\n文件信息:\n"
final_result += f"- 文件名: {result['file_name']}\n"
# ... 其他文件信息 ...
final_result += f"\n内容解读:\n{message.content}"
return final_result
return message.content if message.content else "未能理解您的问题"我们来看下 client 交互的过程
首先用户提出问题,client 会去获取所有的可用工具列表
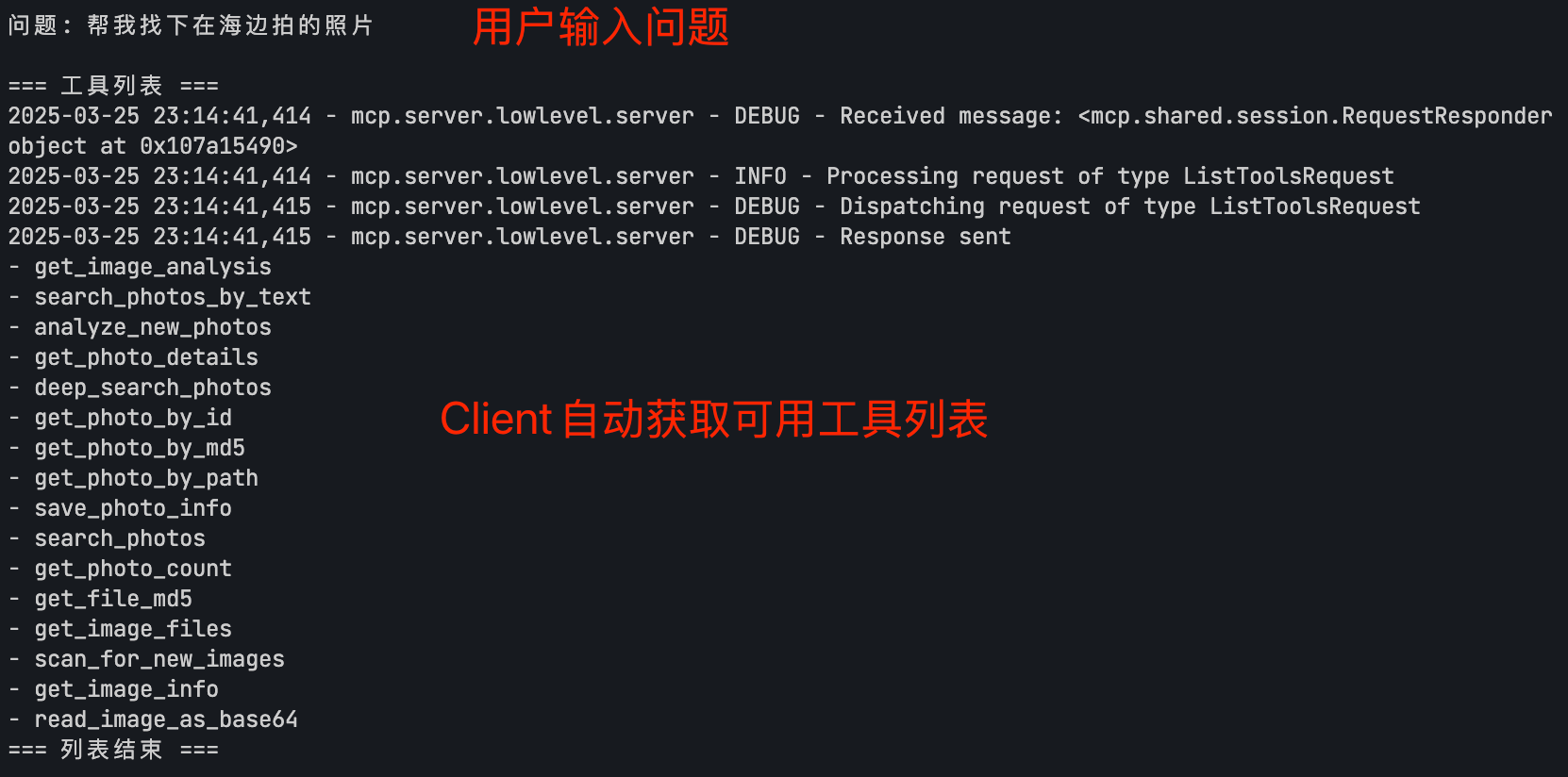
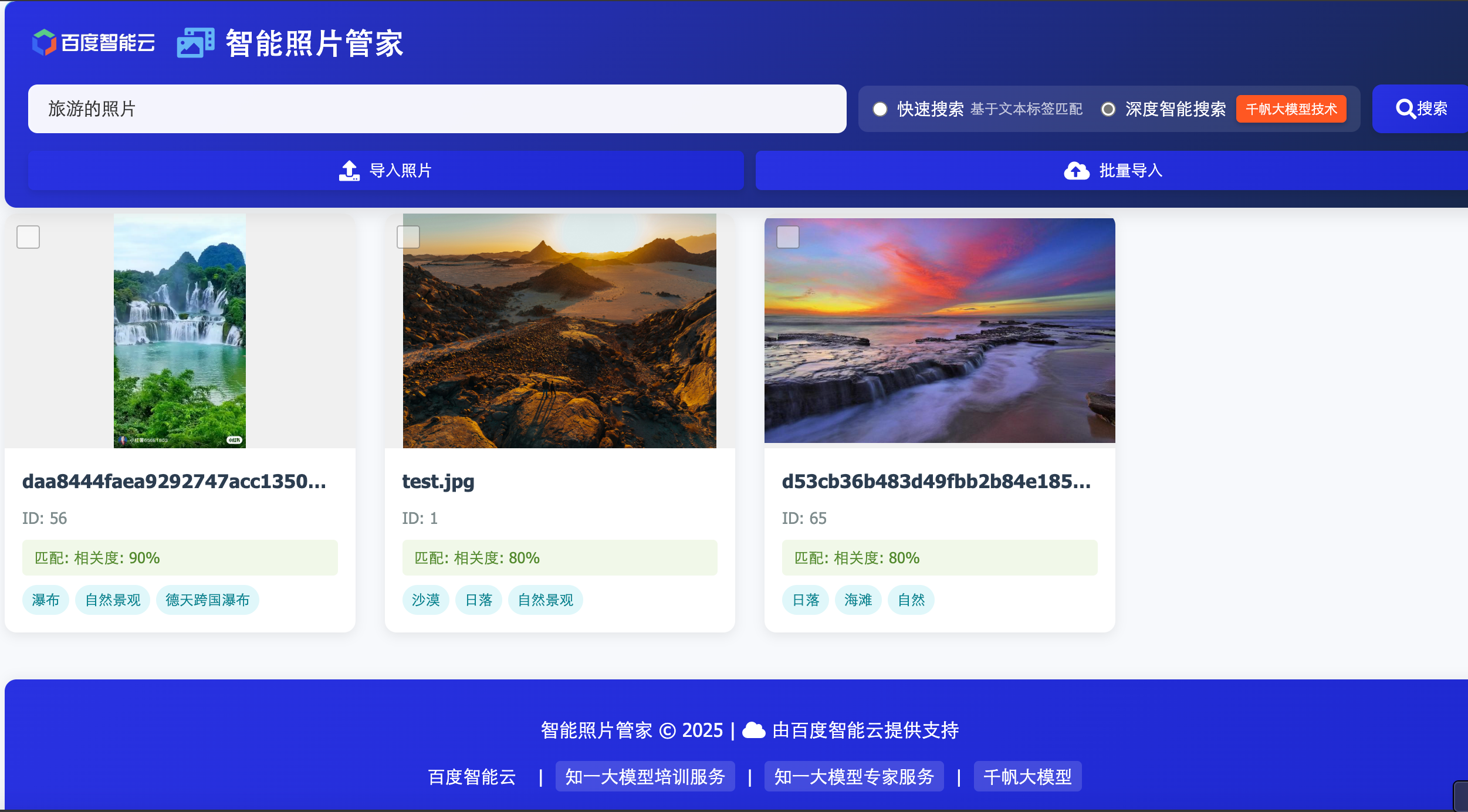
模型会根据用户问题,结合各个工具的描述,选择适合的工具来执行,并获取工具的返回结果。这里可以看到,模型自动挑选了文本快速检索和语义深度检索两个工具同时来查找,并且通过语义检索工具找到了符合条件的图片

Client 将用户问题、工具返回结果再一起给到模型,做出总结回答
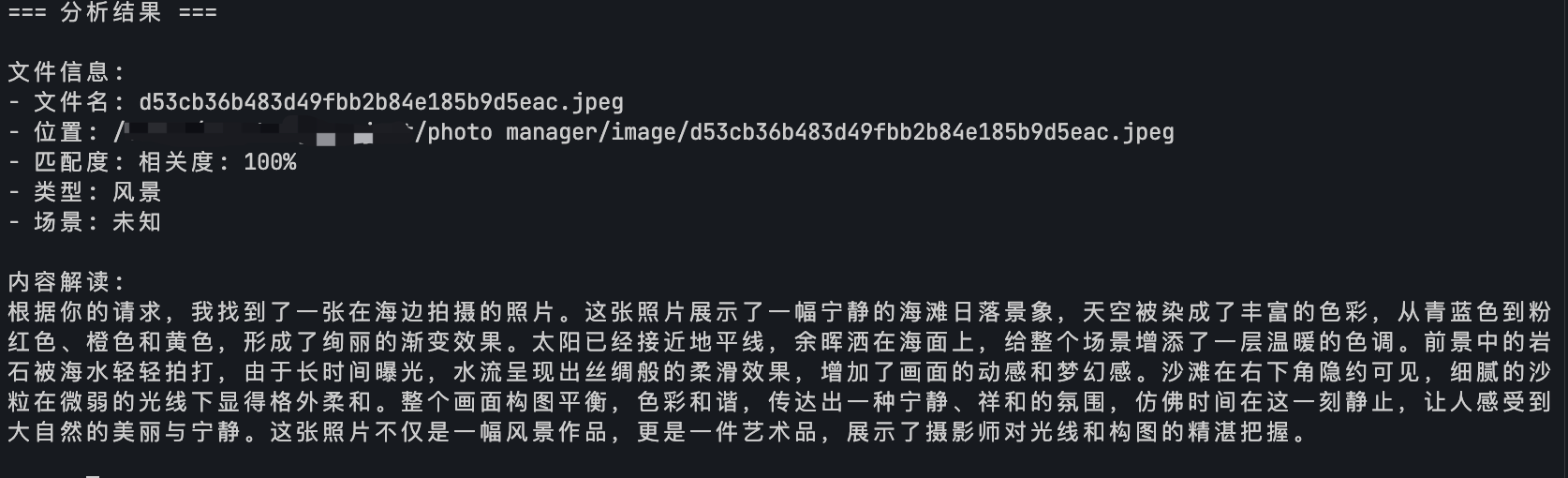
工具找到的图片如下,符合我们的要求:

这就是我们通过大模型+MCP 架构,集成各种服务来实现自动化任务的一个示例,我们可以对比下集成大模型前后,MCP Client 的工作过程
-
集成模型前
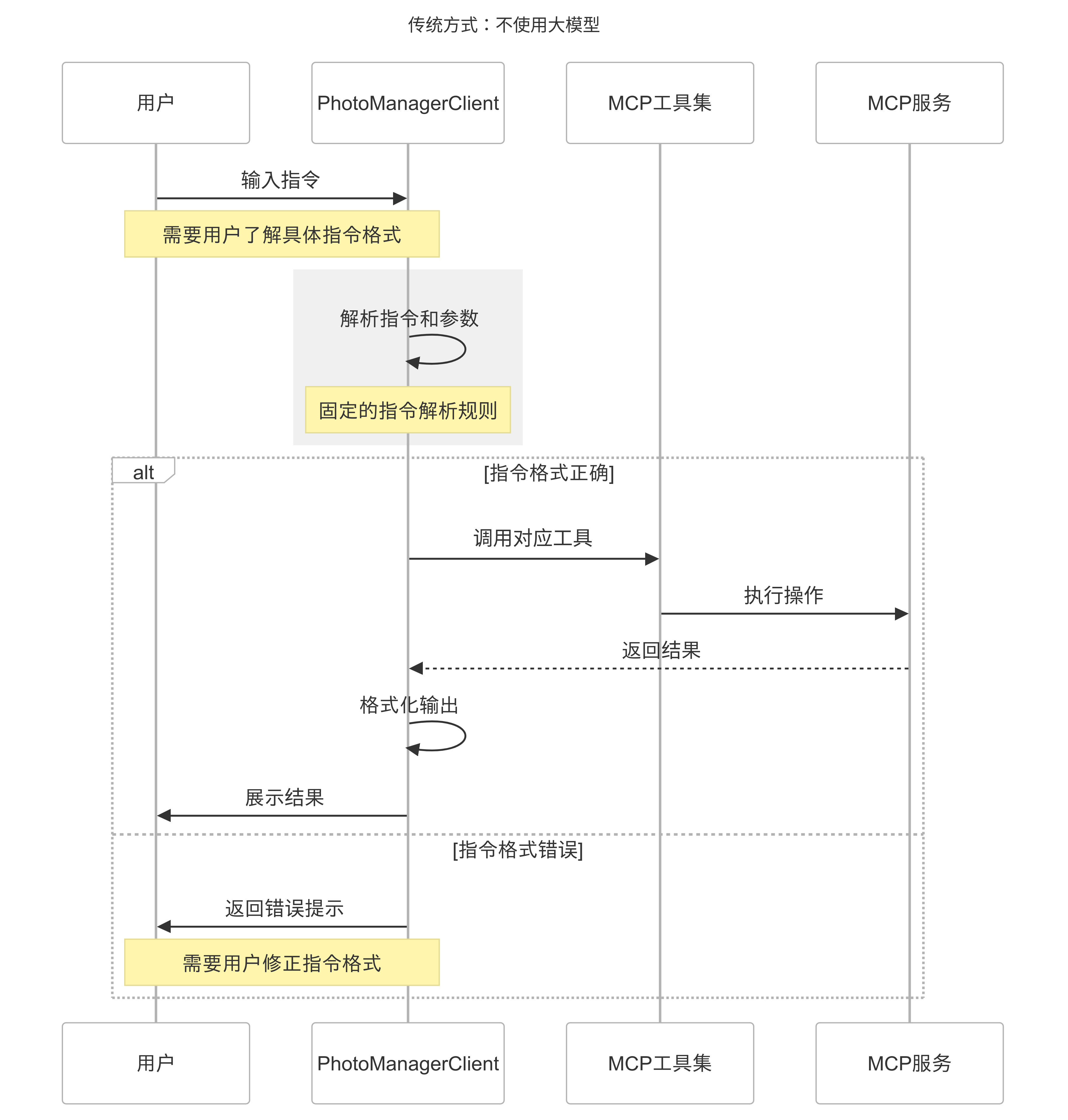
-
集成模型后
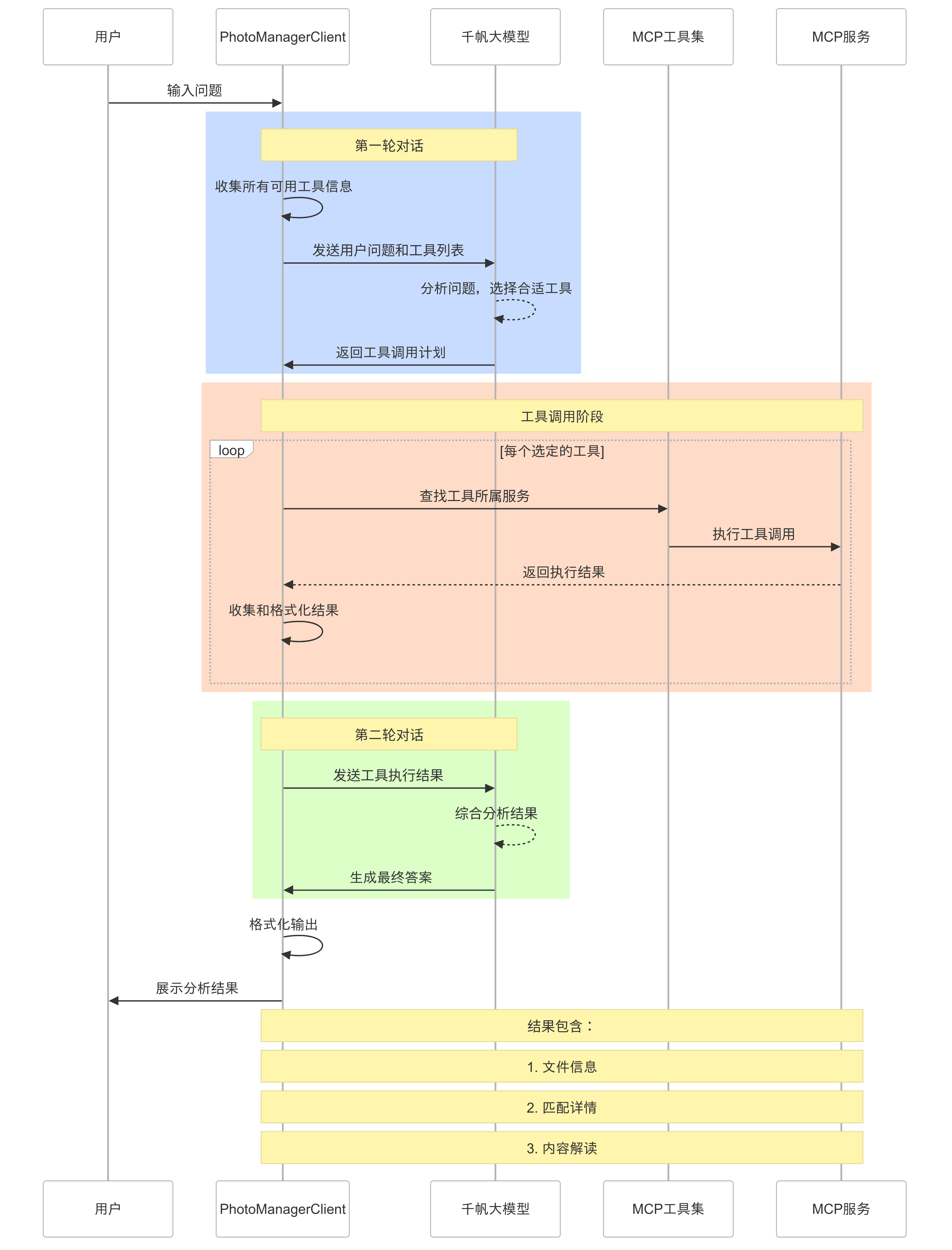
集成大模型的优势
| 功能维度 | 传统命令行方式 | 集成大模型方式 |
|---|---|---|
| 交互方式 | 需要记忆固定指令格式 search --type photo --tag sunset |
支持自然语言对话 "帮我找找夕阳的照片" |
| 容错能力 | ❌ 严格的指令格式要求 - 参数顺序固定 - 参数名称必须准确 | ✅ 智能理解用户意图 - 容忍语言表达多样性 - 自动纠正理解偏差 |
| 工具调用 | 单一指令执行 - 一次只能执行一个命令 - 需要用户手动组合多步操作 | 智能工具组合 - 自动规划执行顺序 - 多工具协同完成任务 |
| 结果呈现 | 原始数据格式 - JSON/CSV 等技术格式 - 需要用户自行解读 | 智能化解读 - 自然语言描述 - 重点信息突出展示 |
| 使用门槛 | 较高 - 需要学习命令语法 - 需要理解技术概念 | 极低 - 直接用自然语言 - 无需技术背景 |
| 功能扩展 | 复杂度高 - 需要更新命令文档 - 需要用户重新学习 | 简单高效 - 自动适应新功能 - 用户无感知学习 |
完善功能及前端页面
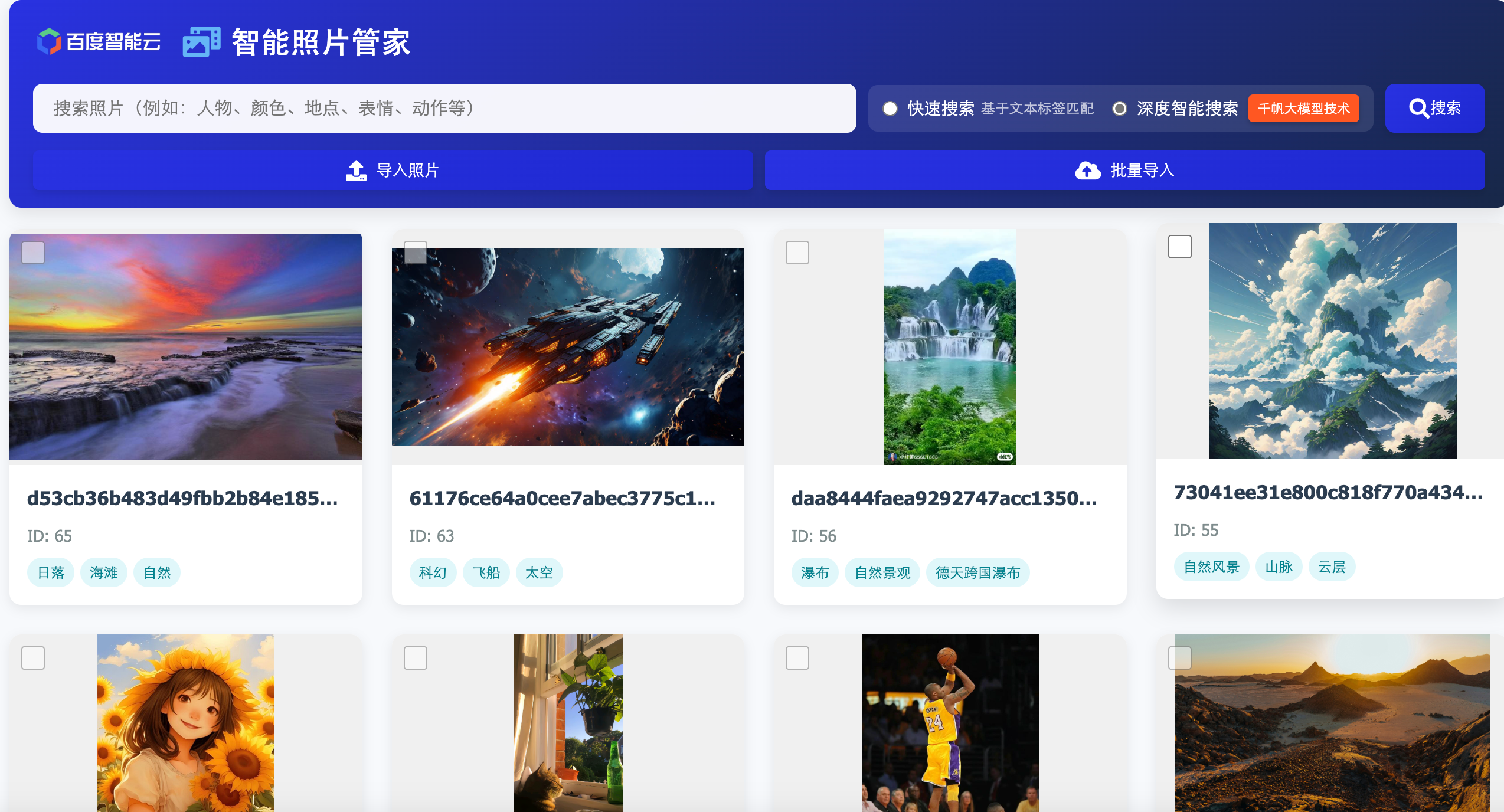
到这里,我们后端的核心功能就已经完成了,我们可以让这个程序在后台运行,定时去扫描我们的特定文件夹,根据图片 MD5 值的变化来判断是否有增加的图片,自动更新解析结果。最后我们给这个程序配上前端,一个可视化的智能图片管理系统就做好了,可以方便快速地管理及查找自己的图库了。
|--------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------|
|  |
|  |
|  |
|
如果想要get更多大模型技巧,推荐学习
工信部教考中心x百度推出的《生成式人工智能应用工程师》
百度推出的《百度AI大模型工程师》、《零基础速通 DeepSeek:AI 变革破局思考与实践》