LangChain4J-基础
LangChain4J(LangChain For Java)是专门为了简化Java应用在接入LMM的过程,它提供了统一的API如LLM模型的调用,向量数据库等方法,可以让Java应用程序快速接入大模型
官方文档
官方文档:https://docs.langchain4j.dev/get-started
支持的大模型:https://docs.langchain4j.dev/integrations/language-models/
支持的向量数据库:https://docs.langchain4j.dev/integrations/embedding-stores
大模型接入准备
阿里百炼是由阿里云厂商提高的大模型调用平台,里面部署了很多不同类型的大模型,只需要开通账号即可使用根据token的使用量进行收费,阿里百炼平台地址https://bailian.console.aliyun.com/
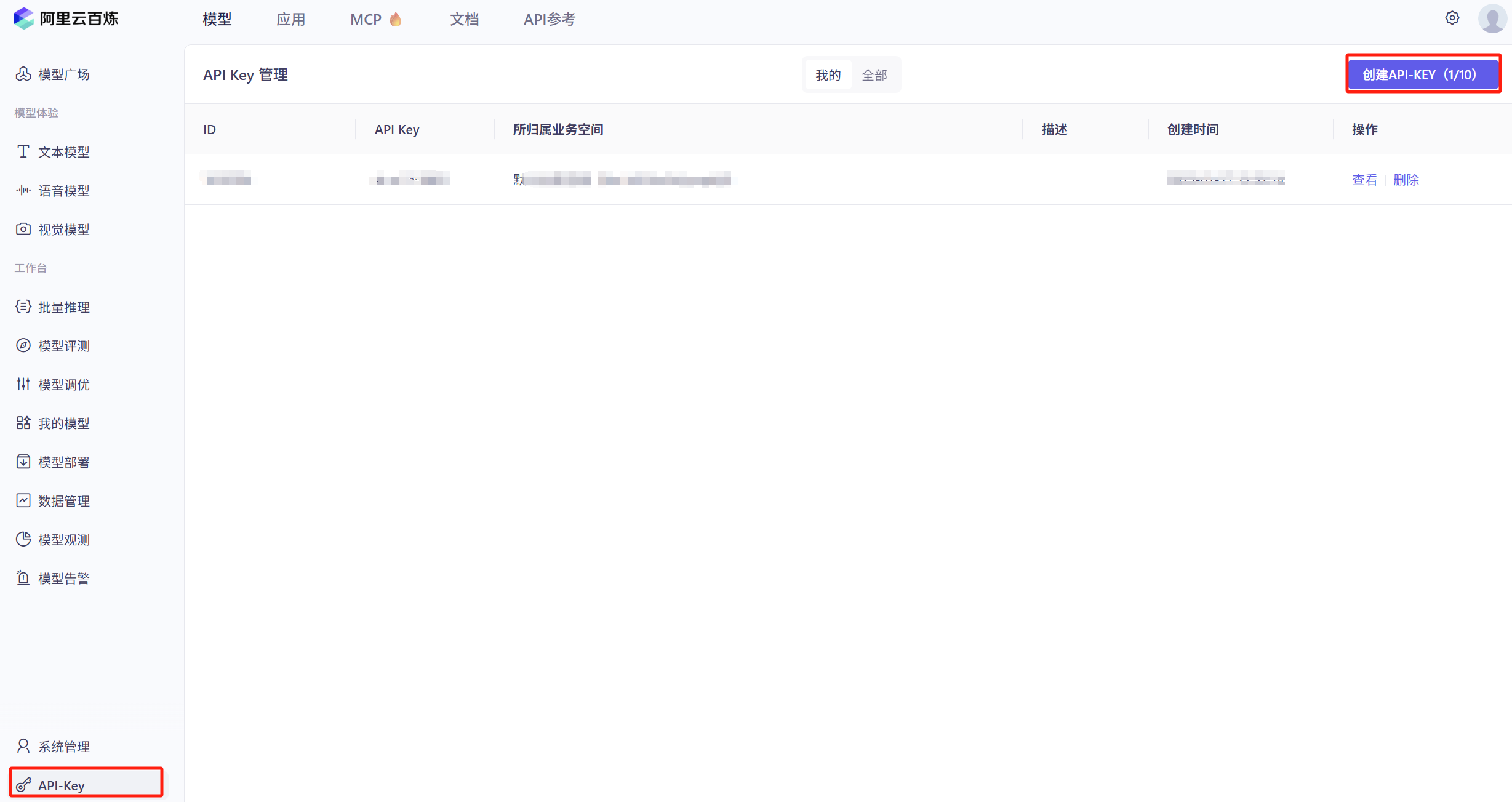
获取API调用KEY
进入到阿里云百炼平台创建一个API-KEY,该KEY可以用于调用百炼平台中的所有大模型
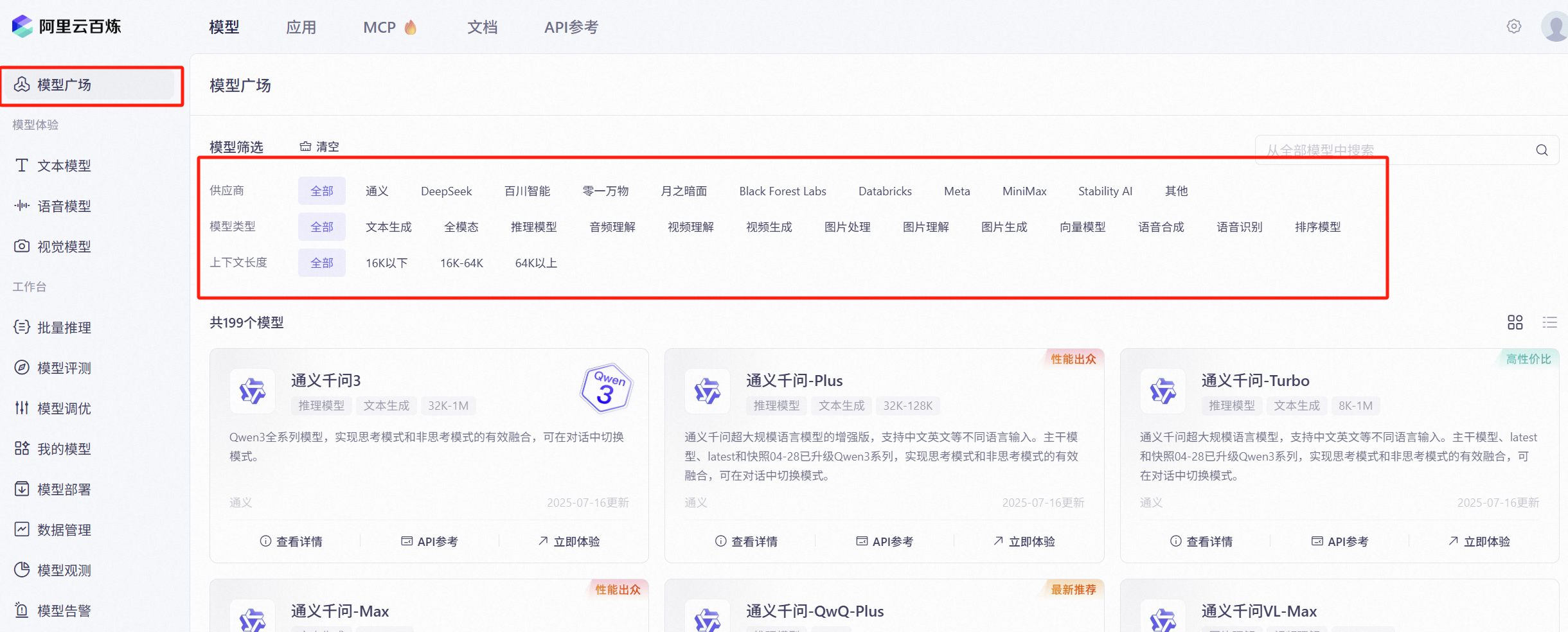
获取想调用的模型名称
阿里云百炼平台中提供了各种各样的模型,除了阿里自己研发的Qwen模型也集成了很多的第三方模型如DeepSeek等
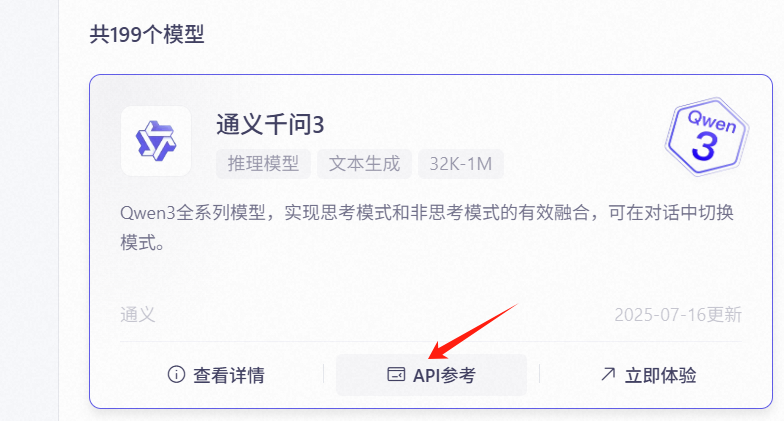
获取baseUrl
选择想要的大模型选择API参考后就能获取到对应的baseUrl

依赖引入
xml
<!--基本用法-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.1.0</version>
</dependency>
<!--更多的高阶用法-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.1.0</version>
</dependency>快速入门
普通聊天
这是一个最简单的用力,使用ChatModel与大模型对话
java
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey("百炼平台获取的key")
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
String result = chatModel.chat(question);
log.info("调用大模型回复:{}",result);Token用量计算
在大模型中计费通常是按照token的使用量进行计费,那token的用量是怎么定义的呢,下面的deepseek给出的定义

那假如我们需要统计用户每次对话消耗了多少token数量用于收费那么就可以通过如下方式获取
java
ChatResponse chatResponse = chatModel.chat(UserMessage.from(question));
//调用大模型返回的结果
String result = chatResponse.aiMessage().text();
log.info("调用大模型回复:{}",result);
//调用大模型的token使用量
TokenUsage tokenUsage = chatResponse.tokenUsage();
log.info("本次调用消耗token量:{}",tokenUsage);模型参数配置
使用OpenAiChatModel.builder()后可以设置很多的模型参数,可以参考官方,以下列出一些常用的参数
模型参数配置:https://docs.langchain4j.dev/tutorials/model-parameters
日志开启
依赖准备
项目引入SLF4J 类日志
xml
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.8</version>
</dependency>启动日志配置,这样在访问大模型时就可以看到访问日志
java
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey("百炼平台获取的key")
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
//开启日志配置
.logRequests(true)
.logResponses(true)
.build();
String result = chatModel.chat(question);
log.info("调用大模型回复:{}",result);监听器
监听器可以提供了大模型调用前、调用后、发送异常时的回调
java
//定义监听器
ChatModelListener listener1 = new ChatModelListener() {
@Override
public void onRequest(ChatModelRequestContext requestContext) {
log.info("onRequest");
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
log.info("onResponse");
}
@Override
public void onError(ChatModelErrorContext errorContext) {
log.info("onError");
}
};
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey("百炼平台获取的key")
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
//监听器,支持多个
.listeners(List.of(listener1))
.build();
String result = chatModel.chat(question);
log.info("调用大模型回复:{}",result);自动重试
当网络异常时会尝试重复调用模型
java
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey("百炼平台获取的key")
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
//最大重试次数
.maxRetries(2)
.build();
String result = chatModel.chat(question);
log.info("调用大模型回复:{}",result);超时设置
调用大模型时若时间太长就自动断开连接
java
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey("百炼平台获取的key")
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
//设置最大超时时间
.timeout(Duration.ofSeconds(60))
.build();
String result = chatModel.chat(question);
log.info("调用大模型回复:{}",result);高阶API
LangChain4J提供了底层API和高阶API
底层API:ChatModel、ChatMessage、ChatMemory等都是一些底层组件定制程度高可以灵活组合
高阶API:AI Services,可以通过声明接口+注解方式快速实现调用大模型
AI Services
java
//定义接口
public interface ChatAssistant {
String chat(String prompt);
}
//通过AI Services对定义的接口进行包装,使其能够调用大模型
ChatAssistant chatAssistant = AiServices.create(ChatAssistant.class, chatModel);
String result = chatAssistant.chat(question);
log.info("调用大模型回复:{}",result);多模态模型调用
在前面都是基于文本方式的模型对话,LangChain4J也支持多模态的聊天,用户的提问可以包含图片、音频、视频、PDF,使用LangChain4J多模态时前提是需要调用的大模型也支持多模态的消息
图文问题问答
java
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey("百炼平台获取的key")
.modelName("qwen-vl-plus") //切换成qwen的图片理解模型
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
ChatResponse result = chatModel.chat(UserMessage.from(
TextContent.from("这题答案是什么?"),
ImageContent.from("图片base64内容","png")
));
log.info("调用大模型回复:{}",result);引入第三方整合
dashscope整合
很多第三方厂家都提供了LangChain4J的整合包,里面提供了封装好的一下模型调用工具,拿阿里千问举例以下是文档地址https://docs.langchain4j.dev/integrations/language-models/dashscope
xml
<!--父工程引入bom包-->
<dependencyManagement>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>${latest version here}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencyManagement>
<!--子工程引入对应依赖-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope</artifactId>
<version>${latest version here}</version>
</dependency>
<!--Springboot项目-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
<version>${latest version here}</version>
</dependency>引入后可以使用阿里封装好的Model

文生图Mode
java
@Bean
public WanxImageModel wanxImageModel() {
return WanxImageModel.builder()
.apiKey("")
.modelName("wanx2.1-t2i-plus")
.build();
}
/**
* 图片生成
* @return
*/
@PostMapping(value = "/image/create")
public String createImage() throws IOException {
Response<Image> imageResponse = wanxImageModel.generate("猫咪");
//获取ai的回复
String result = imageResponse.content().url().toString();
log.info("调用大模型回复:{}",result);
return result;
}流式输出
大模型推理过程普遍较慢若等推理完成再返回用户会等待很久,流式输出可以让大模型推理出一部分就立即返回这样用户可以看到一个字一个字的输出不用等待那么久
https://docs.langchain4j.dev/tutorials/response-streaming
低阶API
普通用法是再chat方法中传入,StreamingChatResponseHandler,这样就能实现流失返回当收到部分内容时onPartialResponse会被调用,推理内容响应会触发onPartialThinking,整个调用完成onCompleteResponse,发生异常onError,低阶API在SpringBoot需要配合相应SseEmitter完成流式输出
java
StreamingChatModel model = OpenAiStreamingChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(GPT_4_O_MINI)
.build();
String userMessage = "Tell me a joke";
model.chat(userMessage, new StreamingChatResponseHandler() {
@Override
public void onPartialResponse(String partialResponse) {
System.out.println("onPartialResponse: " + partialResponse);
}
});高阶API引入Flux依赖
流式输出需要使用到Spring响应式Flux
xml
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.3.0-beta9</version>
</dependency>记忆缓存
上下文保存功能,是聊天的重要组件,记住之前用户的对话功能这样ai可以通过上下文更好的回答用户问题
https://docs.langchain4j.dev/tutorials/chat-memory
记忆与历史区别
历史:历史记录保存 了用户与 AI 之间的所有消息。历史记录是用户在 UI 中看到的内容,它代表了实际说过的内容
记忆:记忆会保存一些信息,这些信息会被呈现给LLM,使其表现得像是"记住"了对话一样。记忆与历史记录截然不同。根据所使用的记忆算法,它可以通过多种方式修改历史记录:删除部分消息、汇总多条消息、汇总单独的消息、从消息中删除不重要的细节、在消息中注入额外信息(例如,用于RAG)或指令(例如,用于结构化输出)等等
目前LangChain4J不支持历史保存,如果需要保存可自己保存到数据库中
记忆淘汰策略
每次对话发送除了当前问题也包含一部分之前对话内容这就是记忆,记忆越多那么消耗的token会越大,所以设定记忆的淘汰策略可以控制token的消耗,并且包装ai对话能够保留部分记忆
MessageWindowChatMemory:它的功能类似于滑动窗口,保留最近的N条消息,并移除那些超出范围的旧消息,然而,由于每条消息可能包含不同数量的标记,MessageWindowChatMemory主要适用于快速原型开发。
TokenWindowChatMemory:它也作为滑动窗口运行,但专注于保留最近的N个令牌 ,并在需要时移除较旧的消息。消息是不可分割的。如果一条消息无法容纳,它会被完全移除。TokenWindowChatMemory需要一个TokenCountEstimator来计算每条ChatMessage中的令牌数量。
不同记忆规则实现类
定义接口
java
public interface ChatMemoryAssistant {
/**
* 聊天,带记忆功能
* @param userId
* @param prompt
* @return
*/
String chatWithChatMemory(@MemoryId Long userId, @UserMessage String prompt);
}Bean注入
java
@Slf4j
@Configuration
public class LLMConfig {
/**
* 流式对话接口
* @return
*/
@Bean
public ChatModel chatModelQwen() {
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey("sk-aaaaaaaaaaaaaaaaa")
.modelName("qwen-long")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
return chatModel;
}
/**
* 高阶APi
* 使用MessageWindowChatMemory使用记忆
* @return
*/
@Bean(name = "chatMessageWindowChatMemory")
public ChatMemoryAssistant chatMessageWindowChatMemory(ChatModel chatModel) {
return AiServices.builder(ChatMemoryAssistant.class)
.chatModel(chatModel)
//记忆内存提供者
.chatMemoryProvider((memoryId -> MessageWindowChatMemory.withMaxMessages(100)))
.build();
}
/**
* 高阶APi
* 使用chatTokenWindowChatMemory使用记忆
* @return
*/
@Bean(name = "chatTokenWindowChatMemory")
public ChatMemoryAssistant chatTokenWindowChatMemory(ChatModel chatModel) {
//分词器获取,分词器用于计算token数量
TokenCountEstimator openAiTokenCountEstimator = new OpenAiTokenCountEstimator("gpt-4");
return AiServices.builder(ChatMemoryAssistant.class)
.chatModel(chatModel)
//记忆内存提供者
.chatMemoryProvider((memoryId -> TokenWindowChatMemory.withMaxTokens(1000,openAiTokenCountEstimator)))
.build();
}
}Controller
java
@Slf4j
@RestController
public class MemoryChatModelController {
@Resource
private ChatModel chatModel;
@Resource
private ChatAssistant chat;
@Resource
private ChatMemoryAssistant chatMessageWindowChatMemory;
@Resource
private ChatMemoryAssistant chatTokenWindowChatMemory;
/**
* 不带记忆缓存
*
* @return
*/
@GetMapping(value = "/not/memory")
public String notMemory(@RequestParam("question") String question) throws IOException {
return chat.chat(question);
}
/**
* 带记忆缓存(消息窗口)
*
* @return
*/
@GetMapping(value = "/message/memory")
public String messageMemory(@RequestParam("userId") Long userId,
@RequestParam("question") String question) throws IOException {
return chatMessageWindowChatMemory.chatWithChatMemory(userId, question);
}
/**
* 带记忆缓存(token窗口)
*
* @return
*/
@GetMapping(value = "/token/memory")
public String tokenMemory(@RequestParam("userId") Long userId,
@RequestParam("question") String question) throws IOException {
return chatTokenWindowChatMemory.chatWithChatMemory(userId, question);
}
}记忆持久化
记忆只是保存最近的聊天消息而且是保存到本地的,记忆那么就是把所有消息都保存下来保存到数据库中,便于日后分析用户聊天
基于Redis实现消息记忆功能
java
@Component
public class RedisChatMemoryStore implements ChatMemoryStore {
public static final String CHAT_MEMORY_PREFIX = "CHAT_MEMORY:";
@Resource
private RedisTemplate<String,String> redisTemplate;
@Override
public List<ChatMessage> getMessages(Object memoryId) {
//根据用户id获取所有消息
String value = redisTemplate.opsForValue().get(CHAT_MEMORY_PREFIX + memoryId.toString());
//反序列化
return ChatMessageDeserializer.messagesFromJson(value);
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
//消息序列化成json
String messagesToJson = ChatMessageSerializer.messagesToJson(messages);
//保存
redisTemplate.opsForValue().set(CHAT_MEMORY_PREFIX+memoryId, messagesToJson);
}
@Override
public void deleteMessages(Object memoryId) {
//删除
redisTemplate.delete(CHAT_MEMORY_PREFIX + memoryId.toString());
}
}LLMConfig配置
java
@Slf4j
@Configuration
public class LLMConfig {
@Resource
private RedisChatMemoryStore redisChatMemoryStore;
/**
* 流式对话接口
* @return
*/
@Bean
public ChatModel chatModelQwen() {
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey("sk-a")
.modelName("qwen-long")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
return chatModel;
}
/**
* 高阶APi
* 使用MessageWindowChatMemory使用记忆
* @return
*/
@Bean(name = "chatMessageWindowChatMemory")
public ChatMemoryAssistant chatMessageWindowChatMemory(ChatModel chatModel) {
//定义记忆存储提供者
ChatMemoryProvider provider = memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(1000)
.chatMemoryStore(redisChatMemoryStore)
.build();
return AiServices.builder(ChatMemoryAssistant.class)
.chatModel(chatModel)
//记忆内存提供者
.chatMemoryProvider(provider)
.build();
}
}提示词工程
提示词工程是非常重要的,通过不同的消息类型组合成提示词能够让AI根据提示词的引导完成问题的回答
提示词消息类型分类:https://docs.langchain4j.dev/tutorials/chat-and-language-models#types-of-chatmessage
SystemMessage:系统消息,通常由开发人员定义这条消息,这里面编写通常是这次如何表现、回答消息格式等
UserMessage:来自用户的消息,用户提的问题
AiMessage:大模型回复的消息,里面包含回复的消息、本次对话消耗的token等
ToolExecutionResultMessage:大模型调用工具的执行结果
CustomMessage:客户端自定义消息体(目前仅Ollama支持)
接口注解设定提示词
java
public interface LawAssistant {
@SystemMessage("""
你是一位专业的法律顾问,只回答中国法律相关的问题。
输出限制:对于其他领域的问题禁止回答,只返回'抱歉,我只能回答中国法律相关问题'
""")
@UserMessage("请回答以下法律问题:{{question}},字数控制在{{length}}以内")
String chat(@V("question")String question,@V("length") int length);
}实体类注解设定提示词
java
public interface LawAssistant {
@SystemMessage("""
你是一位专业的法律顾问,只回答中国法律相关的问题。
输出限制:对于其他领域的问题禁止回答,只返回'抱歉,我只能回答中国法律相关问题'
""")
String chat(LawPrompt lawPrompt);
@Data
@StructuredPrompt("根据中国{{legal}}法律,解答以下问题:{{question}}")
public static class LawPrompt{
private String legal;
private String question;
}
}PromptTemplate设定提示词
java
@GetMapping(value = "chat3")
public String chat3(@RequestParam("question") String question) throws IOException {
String role = "外科医生";
//构建PromptTemplate模板
PromptTemplate template = PromptTemplate.from("你是一个{{role}}助手,{{question}}怎么办");
//生成提示词
Prompt prompt = template.apply(Map.of("role", role, "question", question));
//提示词转UserMessage
UserMessage userMessage = prompt.toUserMessage();
//调用大模型
ChatResponse response = chatModel.chat(userMessage);
return response.aiMessage().text();
}工具与函数调用
大模型训练时都是历史数据,如果问大模型实时天气那么大模型就回答不出来,通过给大模型添加工具类函数调用,大模型在必要时候可以通过调用某些函数获得结果作为参考https://docs.langchain4j.dev/tutorials/tools
大模型本身并不会执行函数,它会指示应该调用那个函数以及如何调用
低阶工具封装
java
@Slf4j
@Configuration
public class LLMConfig {
@Bean
public ChatModel chatModelQwen() {
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey("sk-xxxxxxx")
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
return chatModel;
}
@Bean
public FunctionAssistant functionAssistant(ChatModel chatModel) {
//工具说明
ToolSpecification toolSpecification = ToolSpecification.builder()
.name("发票助手")
.description("根据用户提交的发票信息,开具发票")
.parameters(
JsonObjectSchema.builder()
.addStringProperty("companyName", "公司名称")
.addStringProperty("dutyNumber", "税号")
.addStringProperty("amount", "开票金额,保留两位有效数字")
.build()
).build();
//业务逻辑
ToolExecutor toolExecutor = (toolExecutionRequest, memoryId) -> {
System.out.println("id => "+toolExecutionRequest.id());
System.out.println("name => "+toolExecutionRequest.name());
System.out.println("arguments => "+toolExecutionRequest.arguments());
return "发票开具成功";
};
return AiServices.builder(FunctionAssistant.class)
.chatModel(chatModel)
.tools(Map.of(toolSpecification,toolExecutor))
.build();
}
}高阶工具封装
使用@Tool注解标记方法后
java
//实现类
@Component
public class InvoiceService {
@Tool("根据用户提供的信息开发票")
String create(@P("公司名称") String companyName,
@P("税号") String dutyNumber,
@P("开票金额,保留两位有效数字") String amount) {
System.out.println("companyName => " + companyName);
System.out.println("dutyNumber => " + dutyNumber);
System.out.println("amount => " + amount);
return "发票开具成功";
}
}修改LLMConfig
java
@Slf4j
@Configuration
public class LLMConfig {
@Bean
public ChatModel chatModelQwen() {
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey("sk-xxxxxxx")
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
return chatModel;
}
@Bean
public FunctionAssistant functionAssistant(ChatModel chatModel, InvoiceService invoiceService) {
return AiServices.builder(FunctionAssistant.class)
.chatModel(chatModel)
.tools(invoiceService)
.build();
}
}向量数据库
向量数据库安装
开放2个端口,6333用于HttpAPI,浏览器Web界面,6334用于gRPC API
shell
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant启动成功后访问:http://172.0.0.1:6333/dashboard#/welcome
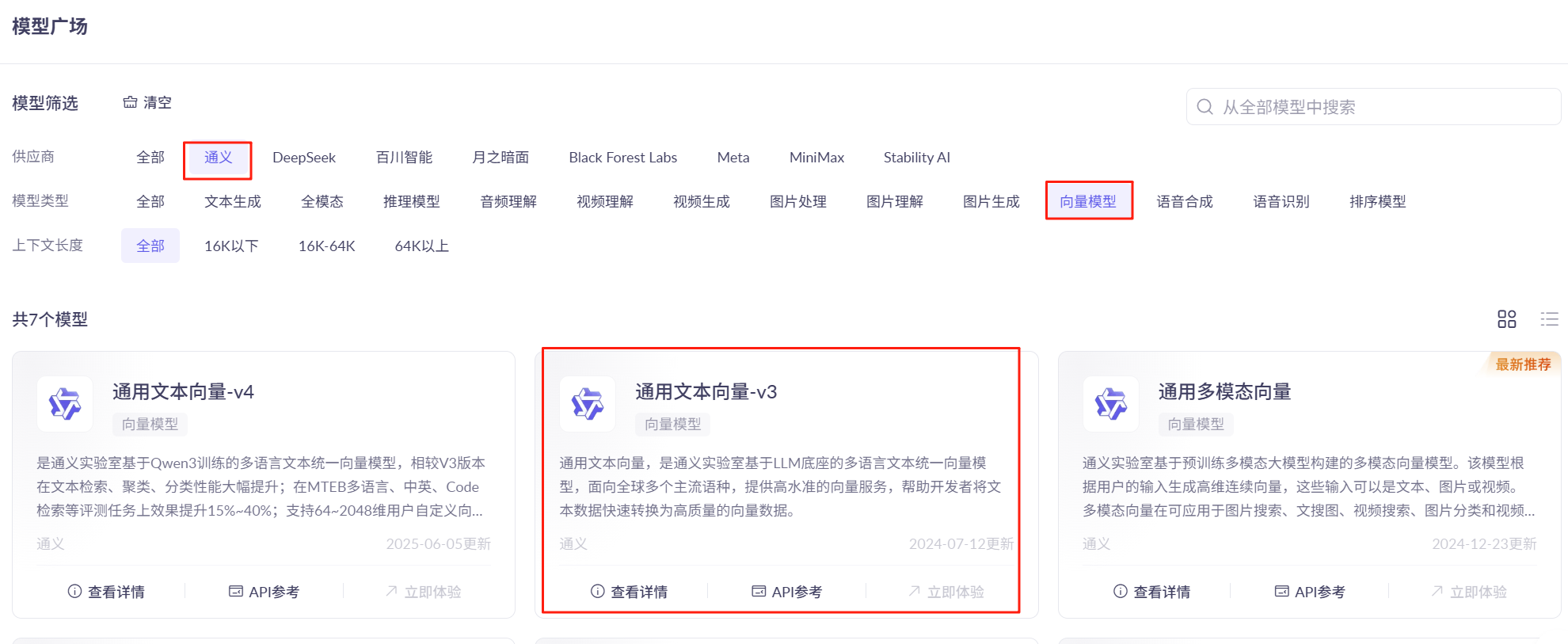
向量模型
向量模型可以将文本、图像转换成浮点数组,这里使用阿里向量模型将文本序列化
向量模型注入
使用OpenAiEmbeddingModel将模型注入到项目中
java
@Bean
public EmbeddingModel embeddingModel() {
OpenAiEmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey("sk-xxxxxxxxxxxx")
.modelName("text-embedding-v3")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
return embeddingModel;
}Qdrant客户端
Qdrant客户端将向量好的数据保存到Qdrant数据库
java
//QdrantClient客户端用于读取和查询数据
@Bean
public QdrantClient qdrantClient() {
QdrantGrpcClient grpcClient = QdrantGrpcClient
.newBuilder("192.168.88.100", 6334, false)
.build();
return new QdrantClient(grpcClient);
}
//向量存储库,名称是test-qdrant
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
return QdrantEmbeddingStore.builder()
.host("192.168.88.100")
.port(6334)
.collectionName("test-qdrant")
.build();
}向量存储、查询
将向量好的文本存储到一个向量数据库中,目前支持的数据库有很多种参考文档https://docs.langchain4j.dev/integrations/embedding-stores/,向量数据库查询与传统的数据库不同,向量数据库实现的是相似度查询
java
@Slf4j
@RestController
public class EmbeddingModelController {
@Resource
private EmbeddingModel embeddingModel;
@Resource
private QdrantClient qdrantClient;
@Resource
private EmbeddingStore<TextSegment> embeddingStore;
/**
* 文本向量化
*/
@GetMapping(value = "/text/embedding")
public String textEmbedding(@RequestParam("txt") String txt) {
Response<Embedding> embeddingResponse = embeddingModel.embed(txt);
return embeddingResponse.content().toString();
}
/**
* 创建数据库实例
*/
@GetMapping(value = "/embedding/create/collection")
public void creatCollection() {
Collections.VectorParams vectorParams = Collections.VectorParams.newBuilder()
.setDistance(Collections.Distance.Cosine) //余弦相似度
.setSize(1024)
.build();
qdrantClient.createCollectionAsync("test-qdrant", vectorParams);
}
/**
* 相似度查询
*/
@GetMapping(value = "/embedding/query1")
public String embeddingQuery1(@RequestParam("txt") String txt) {
//查询的文本向量化
Embedding queryEmbedding = embeddingModel.embed(txt).content();
//查询条件构建
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(embeddingSearchRequest);
return searchResult.matches().getFirst().embedded().text();
}
/**
* 相似度查询(带过滤)
*/
@GetMapping(value = "/embedding/query2")
public String embeddingQuery2(@RequestParam("txt") String txt) {
//查询的文本向量化
Embedding queryEmbedding = embeddingModel.embed(txt).content();
//查询条件构建
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.filter(metadataKey("auth").isEqualTo("aaa"))
.maxResults(1)
.build();
EmbeddingSearchResult<TextSegment> searchResult = embeddingStore.search(embeddingSearchRequest);
return searchResult.matches().isEmpty() ? "没有数据" : searchResult.matches().getFirst().embedded().text();
}
}RAG
RAG检索增强生成,在前面的学习已了解如何调用大模型进行文本生成以及向量数据库的写入与查询数据,现有的大模型都是预训练好的基模,在专业领域可能不是那么的擅长正好你手头上有一些秘籍想让大模型用你的秘籍回答用户问题,就可以将秘籍向量化到数据库用户提问先从向量数据库查询相关知识点,提供给大模型作为参考生成结果
RAG步骤
| 步骤 | 说明 |
|---|---|
| 加载文档 | 使用对应的DocumentLoader和DocumentParser加载文档 |
| 转换文档 | 使用DocumentTransformer清理或增强文档(可选) |
| 拆分文档 | 使用DocumentSplitter将文档拆分为更小的片段(可选) |
| 嵌入文档 | 使用EmbeddingModel将文档转换为向量 |
| 存储嵌入 | 使用EmbeddingStore将文档保存到向量数据库 |
| 索引相关内容 | 根据用户提交的问题从EmbeddingStore查询相似度最高的内容出来 |
| 生成响应 | 将检索到的相关内容与用户提交的问题一起提供给模型,生成响应结果 |
文档处理
首先我们需要把自己的知识库内容存入向量化数据库,对于超大文档直接向量化是不现实的,如100万字的书籍直接向量化到数据库那么再读取写入会消耗很多资源,并且查询时会返回很多不相关内容,所以需要把文档切割成多个小块如1万字一段,然后写入到向量数据库这样再读取时就可以查询相关的1万字,而不是整个书籍全部读取
java
@Resource
private EmbeddingModel embeddingModel;
@Resource
private EmbeddingStore<TextSegment> embeddingStore;
@Resource
private ResourceLoader resourceLoader;
/**
* 加载文档
*/
@GetMapping(value = "/load")
public void load() throws IOException {
//加载文档
InputStream inputStream = resourceLoader.getResource("classpath:时间的琥珀.txt").getInputStream();
Document document = new ApacheTikaDocumentParser().parse(inputStream);
//根据段落分片,每个段落最多100字,相邻两片重复内容10个字用于关联上下文
List<TextSegment> segmentList = new DocumentByParagraphSplitter(100, 10).split(document);
segmentList.forEach(segment -> {
//生成嵌入向量
Embedding embedding = embeddingModel.embed(segment).content();
//存入数据库
embeddingStore.add(embedding,segment);
});
}检索生成
将用户提交的问题向量化后,在向量化数据库中查询得出相关文档并且将相关文档和问题一同发给大模型,大模型参考提供的问题回答用户的问题
java
//定义接口
public interface ChatAssistant {
String chat(String msg);
}
//Bean准备
@Bean
public ChatModel chatModelQwen() {
OpenAiChatModel chatModel = OpenAiChatModel.builder()
.apiKey("sk-xxxxx")
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
return chatModel;
}
@Bean
public EmbeddingModel embeddingModel() {
OpenAiEmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey("sk-xxxx")
.modelName("text-embedding-v3")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.dimensions(1024)
.build();
return embeddingModel;
}
@Bean
public ChatAssistant chatAssistant(ChatModel chatModel,EmbeddingModel embeddingModel,EmbeddingStore<TextSegment> embeddingStore) {
//向量数据库参数配置
EmbeddingStoreContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
return AiServices.builder(ChatAssistant.class)
.chatModel(chatModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(50))
.contentRetriever(contentRetriever)
.build();
}
java
@Resource
private ChatAssistant chatAssistant;
/**
* 提问
*/
@GetMapping(value = "/question")
public String question(@RequestParam("question")String question) throws IOException {
return chatAssistant.chat(question);
}MCP
MCP(Model Context Portocol)模型上下文协议与Tool类似,Tool提供函数调用大部分用于自己实现的一些特定功能,而MCP是一个开放协议标准化了大模型的上下游调用过程,就如http实现所有http服务器相互通信的一种协议,MCP仓库地址https://mcp.so/zh
接入百度地图MCP
首先登录百度地图申请一个AKhttps://lbsyun.baidu.com/apiconsole/key/recycle
安装python依赖
shell
pip install mcp-server-baidu-maps构建ChatAssistant时把MCP服务添加进去
java
@Bean
public StreamingChatModel chatModelQwen() {
OpenAiStreamingChatModel chatModel = OpenAiStreamingChatModel.builder()
.apiKey("sk-xxxxxxx")
.modelName("qwen-plus")
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
return chatModel;
}
@Bean
public ChatAssistant chatAssistant(StreamingChatModel streamingChatModel) {
//构建MCP协议
StdioMcpTransport mcpTransport = new StdioMcpTransport.Builder()
.command(List.of("python", "-m", "mcp_server_baidu_maps"))
.environment(Map.of("BAIDU_MAPS_API_KEY", "百度平台的ak"))
.build();
//MCP客户端
McpClient mcpClient = new DefaultMcpClient.Builder()
.transport(mcpTransport)
.build();
//创建工具集
McpToolProvider toolProvider = McpToolProvider.builder()
.mcpClients(mcpClient)
.build();
//通过AIService调用
ChatAssistant mcpService = AiServices.builder(ChatAssistant.class)
.streamingChatModel(streamingChatModel)
.toolProvider(toolProvider)
.build();
return mcpService;
}编写接口
java
/**
* 调用mcp服务
*/
@GetMapping(value = "/mcp/chat")
public Flux<String> chat(@RequestParam("question")String question) throws IOException {
return chatAssistant.chat(question);
}