本文较长,建议点赞收藏。更多AI大模型开发学习视频籽料, 都在这>>Github<<
一、概述
前面几篇文章写很多MCP应用,基本上一个dify工作流使用一个MCP应用。那么一个dify工作流,同时使用多个MCP应用,是否可以呢?答案是可以的。
先来看一下效果图
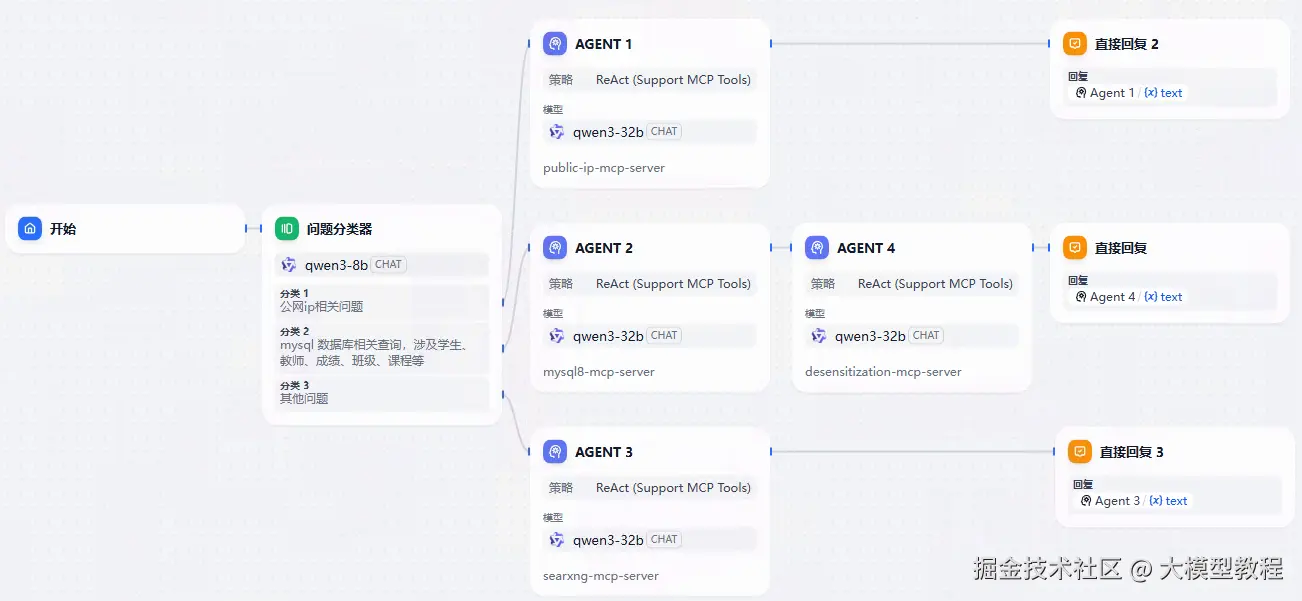
说明:
这里使用了问题分类器,用来判断用户的问题,应该调用哪个MCP应用
AGENT1~4,分别对应一个MCP应用,例如:public-ip-mcp-server,mysql8-mcp-server,desensitization-mcp-server,searxng-mcp-server
针对mysql查询输出的内容,会进行脱敏处理。
二、问题分类器
定义
通过定义分类描述,问题分类器能够根据用户输入,使用 LLM 推理与之相匹配的分类并输出分类结果,向下游节点提供更加精确的信息。
场景
常见的使用情景包括客服对话意图分类、产品评价分类、邮件批量分类等。
在一个典型的产品客服问答场景中,问题分类器可以作为知识库检索的前置步骤,对用户输入问题意图进行分类处理,分类后导向下游不同的知识库查询相关的内容,以精确回复用户的问题。
设置
对于比较精确的条件,一般使用条件分支。但是对于我这种场景,条件比较模糊,所以需要使用问题分类器
这里定义了3个分类:
公网ip相关问题
mysql 数据库相关查询,涉及学生、教师、成绩、班级、课程等
其他问题效果如下:
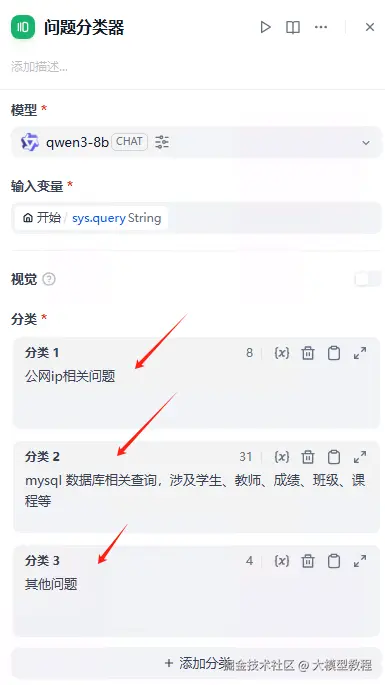
说明:
公网ip相关问题,会直接调用MCP应用public-ip-mcp-server
mysql相关问题,会调用MCP应用mysql8-mcp-server
其他问题,会调用MCP应用searxng-mcp-server,这个是一个联网搜索引擎,你可以理解为百度,想搜什么都可以。
三、环境说明
dify版本
这里使用的是最新版本1.4.0,如果你的版本没有这么高,1.3.0以上版本也可以。
mcp插件
确保已经安装了以下插件:
scss
Agent 策略(支持 MCP 工具)
MCP SSE / StreamableHTTP确保插件版本,已经升级到最新版本
mcp应用
这里的所有MCP应用,统一使用Streamable HTTP模式,全部部署在k8s里面。
当然,使用docker运行也是可以的。
mcp插件设置
点击插件MCP SSE / StreamableHTTP,输入MCP 服务配置
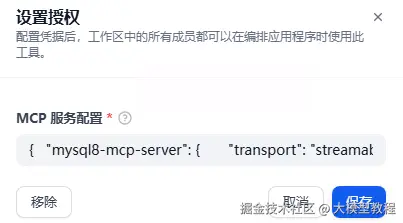
完整内容如下:
json
{
"mysql8-mcp-server": {
"transport": "streamable_http",
"url": "http://mysql8-mcp-server-svc.mcp:9000/mcp/",
"headers": {},
"timeout": 60
},
"desensitization-mcp-server": {
"transport": "streamable_http",
"url": "http://desensitization-mcp-server-svc.mcp:9000/mcp/",
"headers": {},
"timeout": 60
},
"public-ip-mcp-server": {
"transport": "streamable_http",
"url": "http://public-ip-mcp-server-svc.mcp:9000/mcp/",
"headers": {},
"timeout": 60
},
"searxng-mcp-server": {
"transport": "streamable_http",
"url": "http://searxng-mcp-server-svc.mcp:9000/mcp/",
"headers": {},
"timeout": 60
}
}注意:这里的url使用的是k8s内部地址,如果使用的是docker方式运行,请根据实际情况修改。
四、public-ip-mcp-server设置
public-ip-mcp-server核心代码如下:
python
from fastmcp import FastMCP
import json
import requests
mcp = FastMCP("public-ip-address")
@mcp.tool()
def get_public_ip_address() -> str:
"""
获取公网ip地址
返回:
str: 当前网络的公网ip地址
"""
response = requests.get("http://ip-api.com/json")
content = json.loads(response.text)
return content["query"]
if __name__ == "__main__":
mcp.run(transport="streamable-http", host="0.0.0.0", port=9000, path="/mcp")Agent配置
Agent 1详细配置如下:
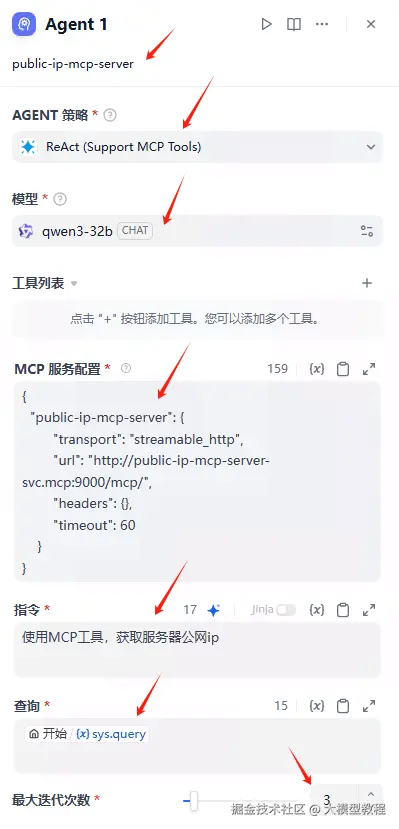
MCP服务配置
json
{
"public-ip-mcp-server": {
"transport": "streamable_http",
"url": "http://public-ip-mcp-server-svc.mcp:9000/mcp/",
"headers": {},
"timeout": 60
}
}指令
使用MCP工具,获取服务器公网ip最后直接回复,注意选择变量Agent1 text

五、mysql8-mcp-server设置
核心代码
mysql8-mcp-server核心代码如下:
python
from fastmcp import FastMCP
from mysql.connector import connect, Error
import os
mcp = FastMCP("operateMysql")
def get_db_config():
"""从环境变量获取数据库配置信息
返回:
dict: 包含数据库连接所需的配置信息
- host: 数据库主机地址
- port: 数据库端口
- user: 数据库用户名
- password: 数据库密码
- database: 数据库名称
异常:
ValueError: 当必需的配置信息缺失时抛出
"""
config = {
"host": os.getenv("MYSQL_HOST", "localhost"),
"port": int(os.getenv("MYSQL_PORT", "3306")),
"user": os.getenv("MYSQL_USER"),
"password": os.getenv("MYSQL_PASSWORD"),
"database": os.getenv("MYSQL_DATABASE"),
}
print(config)
if not all(
[
config["host"],
config["port"],
config["user"],
config["password"],
config["database"],
]
):
raise ValueError("缺少必需的数据库配置")
return config
@mcp.tool()
def execute_sql(query: str) -> list:
"""执行SQL查询语句
参数:
query (str): 要执行的SQL语句,支持多条语句以分号分隔
返回:
list: 包含查询结果的TextContent列表
- 对于SELECT查询:返回CSV格式的结果,包含列名和数据
- 对于SHOW TABLES:返回数据库中的所有表名
- 对于其他查询:返回执行状态和影响行数
- 多条语句的结果以"---"分隔
异常:
Error: 当数据库连接或查询执行失败时抛出
"""
config = get_db_config()
try:
with connect(**config) as conn:
with conn.cursor() as cursor:
statements = [stmt.strip() for stmt in query.split(";") if stmt.strip()]
results = []
for statement in statements:
try:
cursor.execute(statement)
# 检查语句是否返回了结果集 (SELECT, SHOW, EXPLAIN, etc.)
if cursor.description:
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall()
# 将每一行的数据转换为字符串,特殊处理None值
formatted_rows = []
for row in rows:
formatted_row = [
"NULL" if value is None else str(value)
for value in row
]
formatted_rows.append(",".join(formatted_row))
# 将列名和数据合并为CSV格式
results.append(
"\n".join([",".join(columns)] + formatted_rows)
)
# 如果语句没有返回结果集 (INSERT, UPDATE, DELETE, etc.)
else:
conn.commit() # 只有在非查询语句时才提交
results.append(f"查询执行成功。影响行数: {cursor.rowcount}")
except Error as stmt_error:
# 单条语句执行出错时,记录错误并继续执行
results.append(
f"执行语句 '{statement}' 出错: {str(stmt_error)}"
)
# 可以在这里选择是否继续执行后续语句,目前是继续
return ["\n---\n".join(results)]
except Error as e:
print(f"执行SQL '{query}' 时出错: {e}")
return [f"执行查询时出错: {str(e)}"]
@mcp.tool()
def get_table_name(text: str) -> list:
"""根据表的中文注释搜索数据库中的表名
参数:
text (str): 要搜索的表中文注释关键词
返回:
list: 包含查询结果的TextContent列表
- 返回匹配的表名、数据库名和表注释信息
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
sql = "SELECT TABLE_SCHEMA, TABLE_NAME, TABLE_COMMENT "
sql += f"FROM information_schema.TABLES WHERE TABLE_SCHEMA = '{config['database']}' AND TABLE_COMMENT LIKE '%{text}%';"
return execute_sql(sql)
@mcp.tool()
def get_table_desc(text: str) -> list:
"""获取指定表的字段结构信息
参数:
text (str): 要查询的表名,多个表名以逗号分隔
返回:
list: 包含查询结果的列表
- 返回表的字段名、字段注释等信息
- 结果按表名和字段顺序排序
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
# 将输入的表名按逗号分割成列表
table_names = [name.strip() for name in text.split(",")]
# 构建IN条件
table_condition = "','".join(table_names)
sql = "SELECT TABLE_NAME, COLUMN_NAME, COLUMN_COMMENT "
sql += (
f"FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = '{config['database']}' "
)
sql += f"AND TABLE_NAME IN ('{table_condition}') ORDER BY TABLE_NAME, ORDINAL_POSITION;"
return execute_sql(sql)
@mcp.tool()
def get_lock_tables() -> list:
"""
获取当前mysql服务器InnoDB 的行级锁
返回:
list: 包含查询结果的TextContent列表
"""
sql = """SELECT
p2.`HOST` AS 被阻塞方host,
p2.`USER` AS 被阻塞方用户,
r.trx_id AS 被阻塞方事务id,
r.trx_mysql_thread_id AS 被阻塞方线程号,
TIMESTAMPDIFF(SECOND, r.trx_wait_started, CURRENT_TIMESTAMP) AS 等待时间,
r.trx_query AS 被阻塞的查询,
l.OBJECT_NAME AS 阻塞方锁住的表,
m.LOCK_MODE AS 被阻塞方的锁模式,
m.LOCK_TYPE AS '被阻塞方的锁类型(表锁还是行锁)',
m.INDEX_NAME AS 被阻塞方锁住的索引,
m.OBJECT_SCHEMA AS 被阻塞方锁对象的数据库名,
m.OBJECT_NAME AS 被阻塞方锁对象的表名,
m.LOCK_DATA AS 被阻塞方事务锁定记录的主键值,
p.`HOST` AS 阻塞方主机,
p.`USER` AS 阻塞方用户,
b.trx_id AS 阻塞方事务id,
b.trx_mysql_thread_id AS 阻塞方线程号,
b.trx_query AS 阻塞方查询,
l.LOCK_MODE AS 阻塞方的锁模式,
l.LOCK_TYPE AS '阻塞方的锁类型(表锁还是行锁)',
l.INDEX_NAME AS 阻塞方锁住的索引,
l.OBJECT_SCHEMA AS 阻塞方锁对象的数据库名,
l.OBJECT_NAME AS 阻塞方锁对象的表名,
l.LOCK_DATA AS 阻塞方事务锁定记录的主键值,
IF(p.COMMAND = 'Sleep', CONCAT(p.TIME, ' 秒'), 0) AS 阻塞方事务空闲的时间
FROM performance_schema.data_lock_waits w
INNER JOIN performance_schema.data_locks l ON w.BLOCKING_ENGINE_LOCK_ID = l.ENGINE_LOCK_ID
INNER JOIN performance_schema.data_locks m ON w.REQUESTING_ENGINE_LOCK_ID = m.ENGINE_LOCK_ID
INNER JOIN information_schema.INNODB_TRX b ON b.trx_id = w.BLOCKING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.INNODB_TRX r ON r.trx_id = w.REQUESTING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.PROCESSLIST p ON p.ID = b.trx_mysql_thread_id
INNER JOIN information_schema.PROCESSLIST p2 ON p2.ID = r.trx_mysql_thread_id
ORDER BY 等待时间 DESC;"""
return execute_sql(sql)
if __name__ == "__main__":
mcp.run(transport="streamable-http", host="0.0.0.0", port=9000, path="/mcp")Agent配置
Agent 2详细配置如下:
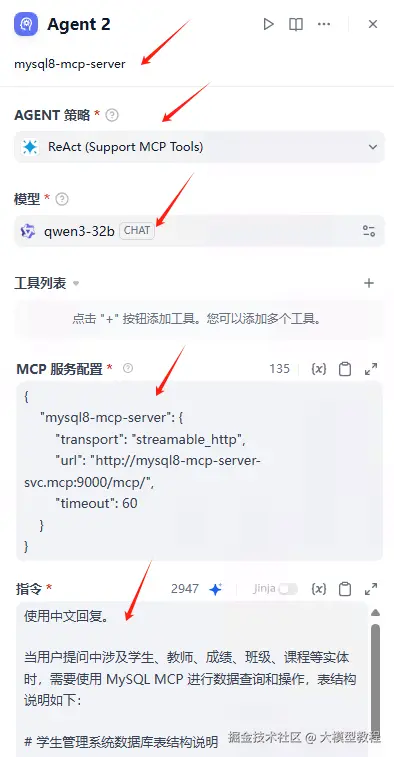
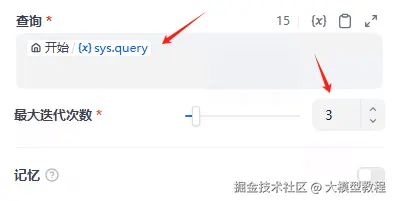
MCP服务配置
sql
使用中文回复。
当用户提问中涉及学生、教师、成绩、班级、课程等实体时,需要使用 MySQL MCP 进行数据查询和操作,表结构说明如下:
# 学生管理系统数据库表结构说明
## 1. 教师表 (teachers)
| 字段名 | 类型 | 描述 | 约束 | 示例 |
|--------|------|------|------|------|
| id | varchar | 教师ID | 主键 | "T001" |
| name | varchar | 教师姓名 | 必填 | "张建国" |
| gender | enum | 性别 | "男"或"女" | "男" |
| subject | varchar | 教授科目 | 必填 | "数学" |
| title | varchar | 职称 | 必填 | "教授" |
| phone | varchar | 联系电话 | 必填 | "13812345678" |
| office | varchar | 办公室位置 | 必填 | "博学楼301" |
| wechat | varchar | 微信(可选) | 可选 | "lily_teacher" |
| isHeadTeacher | enum | 是否为班主任,"true"或"false" | 可选 | true |
## 2. 班级表 (classes)
| 字段名 | 类型 | 描述 | 约束 | 示例 |
|--------|------|------|------|------|
| id | varchar | 班级ID | 主键 | "202301" |
| className | varchar | 班级名称 | 必填 | "2023级计算机1班" |
| grade | int | 年级 | 必填 | 2023 |
| headTeacherId | varchar | 班主任ID | 外键(teachers.id) | "T003" |
| classroom | varchar | 教室位置 | 必填 | "1号楼302" |
| studentCount | int | 学生人数 | 必填 | 35 |
| remark | varchar | 备注信息 | 可选 | "市级优秀班集体" |
## 3. 课程表 (courses)
| 字段名 | 类型 | 描述 | 约束 | 示例 |
|--------|------|------|------|------|
| id | varchar | 课程ID | 主键 | "C001" |
| courseName | varchar | 课程名称 | 必填 | "高等数学" |
| credit | int | 学分 | 必填 | 4 |
| teacherId | varchar | 授课教师ID | 外键(teachers.id) | "T001" |
| semester | varchar | 学期 | 格式"YYYY-N" | "2023-1" |
| type | enum | 课程类型 | "必修"或"选修" | "必修" |
| prerequisite | varchar | 先修课程ID | 可选,外键(courses.id) | "C003" |
## 4. 学生表 (students)
| 字段名 | 类型 | 描述 | 约束 | 示例 |
|--------|------|------|------|------|
| id | varchar | 学号 | 主键 | "S20230101" |
| name | varchar | 学生姓名 | 必填 | "王强" |
| gender | enum | 性别 | "男"或"女" | "男" |
| birthDate | date | 出生日期 | 必填 | date("2005-01-15") |
| enrollmentDate | date | 入学日期 | 必填 | date("2023-8-1") |
| classId | varchar | 班级ID | 外键(classes.id) | "202301" |
| phone | varchar | 联系电话 | 必填 | "13812345678" |
| email | varchar | 电子邮箱 | 必填 | "20230101@school.edu.cn" |
| emergencyContact | varchar | 紧急联系人电话 | 必填 | "13876543210" |
| address | varchar | 家庭住址 | 必填 | "北京市海淀区中关村大街1栋101室" |
| height | int | 身高(cm) | 必填 | 175 |
| weight | int | 体重(kg) | 必填 | 65 |
| healthStatus | enum | 健康状况 | 必填,"良好"或"一般"或"较差" | "良好" |
## 5. 成绩表 (scores)
| 字段名 | 类型 | 描述 | 约束 | 示例 |
|--------|------|------|------|------|
| id | varchar | 成绩记录ID | 主键 | "S20230101C001" |
| studentId | varchar | 学生ID | 外键(students.id) | "S20230101" |
| courseId | varchar | 课程ID | 外键(courses.id) | "C001" |
| score | int | 综合成绩 | 0-100 | 85 |
| examDate | date | 考试日期 | 必填 | date("2024-5-20") |
| usualScore | int | 平时成绩 | 0-100 | 90 |
| finalScore | int | 期末成绩 | 0-100 | 80 |
### 补考成绩记录说明
补考记录在_id后添加"_M"后缀,如"S20230101C001_M"
## 表关系说明
1. **一对多关系**:
- 一个班级(classes)对应多个学生(students)
- 一个教师(teachers)可以教授多门课程(courses)
- 一个学生(students)有多条成绩记录(scores)
2. **外键约束**:
- students.classId → classes.id
- courses.teacherId → teachers.id
- scores.studentId → students.id
- scores.courseId → courses.id
- classes.headTeacherId → teachers.id六、desensitization-mcp-server设置
核心代码
desensitization-mcp-server核心代码如下:
json
{
"mysql8-mcp-server": {
"transport": "streamable_http",
"url": "http://mysql8-mcp-server-svc.mcp:9000/mcp/",
"timeout": 60
}
}
python
from fastmcp import FastMCP
import re
mcp = FastMCP("desensitize-text")
class DataMasker:
def __init__(self):
pass
def mask_phone_number(self, phone_number):
"""
对手机号码进行脱敏处理,将中间四位替换为 *
"""
if len(phone_number) == 11:
return phone_number[:3] + "****" + phone_number[7:]
return phone_number
def mask_email(self, email):
"""
对邮箱地址进行脱敏处理,只显示邮箱名前两位和域名
"""
if "@" in email:
username, domain = email.split("@")
return username[:2] + "****@" + domain
return email
def mask_id_card(self, id_card):
"""
对身份证号码进行脱敏处理,只显示前四位和后四位
"""
if len(id_card) == 18:
return id_card[:4] + "**********" + id_card[14:]
return id_card
def mask_address(self, address):
"""
对地址进行脱敏处理,模糊化门牌号和房间号
例如,将 "1栋" 替换为 "**栋","101室" 替换为 "***室"
"""
# 使用正则表达式
desensitized_address = re.sub(r"(\d+)栋", r"**栋", address)
desensitized_address = re.sub(r"(\d+)室", r"***室", desensitized_address)
return desensitized_address
@mcp.tool()
def desensitize_text(text: str) -> str:
"""
脱敏文本信息
"""
masker = DataMasker()
# 匹配手机号
phone_pattern = r"\d{11}"
phones = re.findall(phone_pattern, text)
for phone in phones:
masked_phone = masker.mask_phone_number(phone)
text = text.replace(phone, masked_phone)
# 匹配邮箱
email_pattern = r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}"
emails = re.findall(email_pattern, text)
for email in emails:
masked_email = masker.mask_email(email)
text = text.replace(email, masked_email)
# 匹配身份证号
id_card_pattern = r"\d{18}"
id_cards = re.findall(id_card_pattern, text)
for id_card in id_cards:
masked_id_card = masker.mask_id_card(id_card)
text = text.replace(id_card, masked_id_card)
# 匹配地址
address_pattern = r"([\u4e00-\u9fa5]+省)?([\u4e00-\u9fa5]+市)?([\u4e00-\u9fa5]+区)?([\u4e00-\u9fa5]+街道)?(\d+[\u4e00-\u9fa5]+)?(\d+[\u4e00-\u9fa5]+)?"
addresss = re.findall(address_pattern, text)
# 如果没有找到地址,返回原始文本
if not addresss:
return text
# 对每个匹配的地址进行脱敏处理
for address_parts in addresss:
# 将匹配的地址部分组合成完整的地址
address = "".join([part for part in address_parts if part])
if address:
# print("address",address)
masked_address = masker.mask_address(address)
text = text.replace(address, masked_address)
return text
if __name__ == "__main__":
mcp.run(transport="streamable-http", host="0.0.0.0", port=9000, path="/mcp")Agent配置
Agent 4详细配置如下:
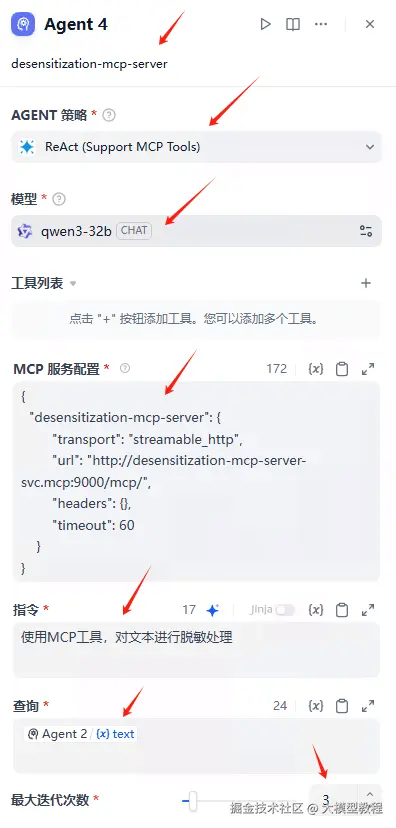
注意:查询要选择变量Agent 2 text
MCP服务配置
json
{
"desensitization-mcp-server": {
"transport": "streamable_http",
"url": "http://desensitization-mcp-server-svc.mcp:9000/mcp/",
"headers": {},
"timeout": 60
}
}指令
使用MCP工具,对文本进行脱敏处理最后直接回复,注意选择变量Agent4 text
七、searxng-mcp-server设置
核心代码
searxng-mcp-server核心代码如下:
python
from fastmcp import FastMCP
import requests
import os
mcp = FastMCP("searxng")
@mcp.tool()
def search(query: str) -> str:
"""
搜索关键字,调用searxng的API接口
参数:
query (str): 要搜索的关键词
返回:
str: 查询结果
"""
api_server = os.getenv("API_SERVER", None)
if not api_server:
print("缺少必需的API_SERVER配置")
raise ValueError("缺少必需的API_SERVER配置")
# API URL
url = "%s/search?q=%s&format=json" % (api_server, query)
print(url)
try:
# 发送GET请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 将响应内容解析为JSON
data = response.json()
# print("JSON内容:")
# print(data,type(data))
result_list = []
for i in data["results"]:
# print(i["content"])
result_list.append(i["content"])
content = "\n".join(result_list)
# print(content)
return content
else:
print(f"请求失败,状态码: {response.status_code}")
return False
except requests.exceptions.RequestException as e:
print(f"请求过程中发生错误: {e}")
return False
if __name__ == "__main__":
mcp.run(transport="streamable-http", host="0.0.0.0", port=9000, path="/mcp")Agent配置
Agent 3详细配置如下:
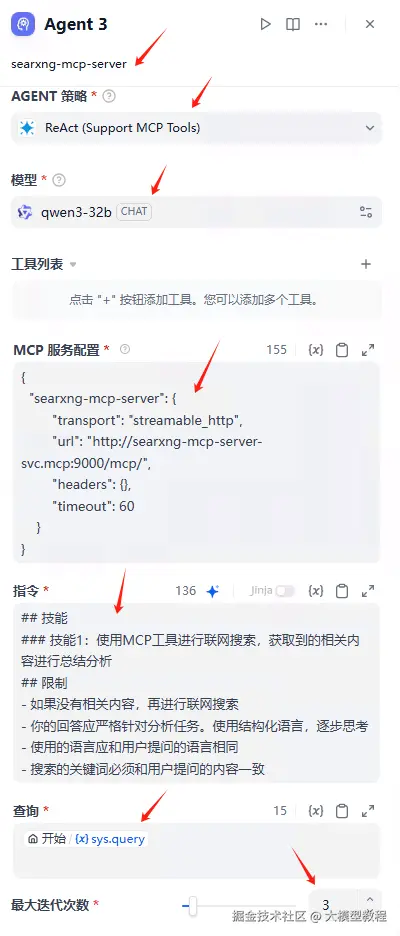
MCP服务配置
json
{
"searxng-mcp-server": {
"transport": "streamable_http",
"url": "http://searxng-mcp-server-svc.mcp:9000/mcp/",
"headers": {},
"timeout": 60
}
}指令
markdown
## 技能
### 技能1:使用MCP工具进行联网搜索,获取到的相关内容进行总结分析
## 限制
- 如果没有相关内容,再进行联网搜索
- 你的回答应严格针对分析任务。使用结构化语言,逐步思考
- 使用的语言应和用户提问的语言相同
- 搜索的关键词必须和用户提问的内容一致最后直接回复,注意选择变量Agent3 text

八、dify测试
点击右上角的预览按钮

公网ip多少
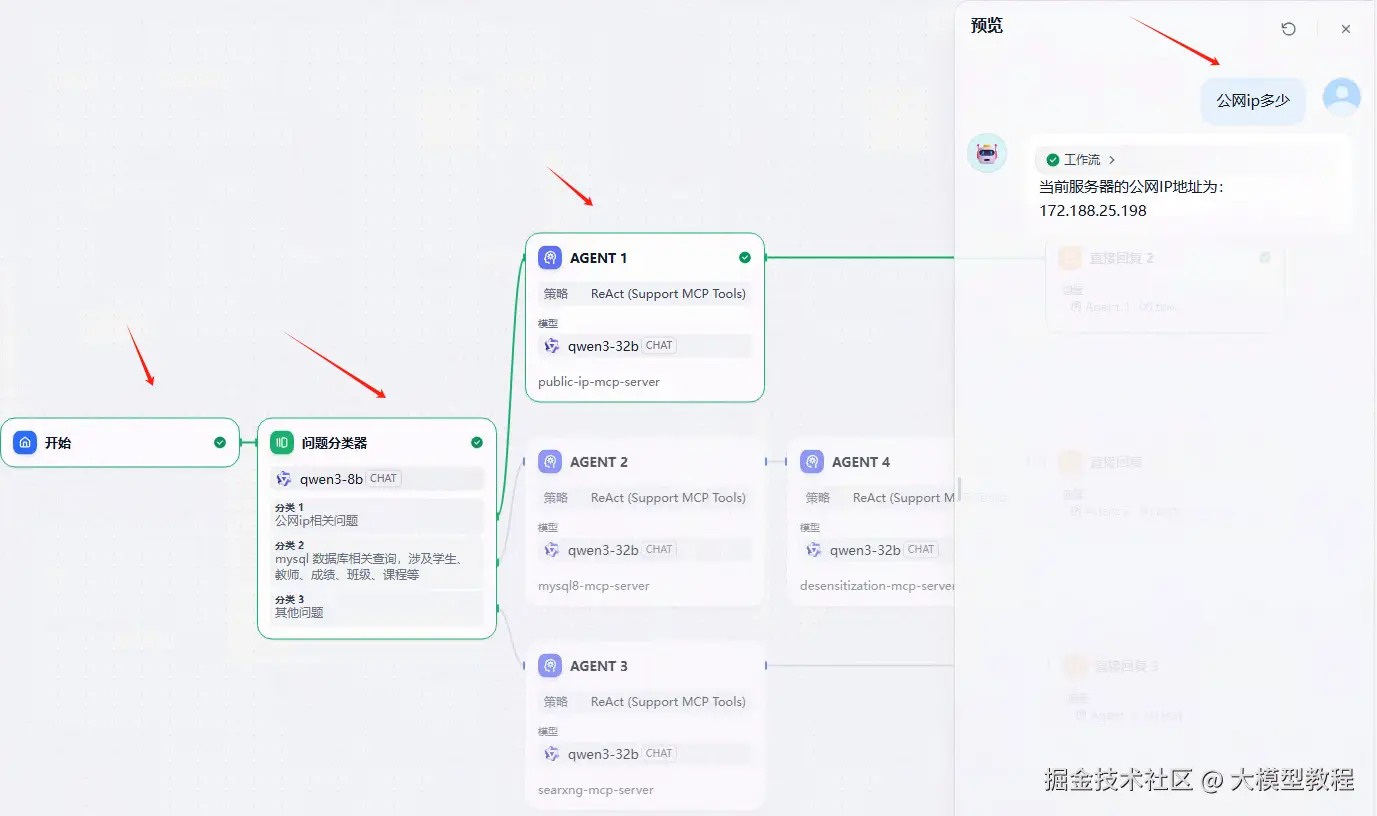
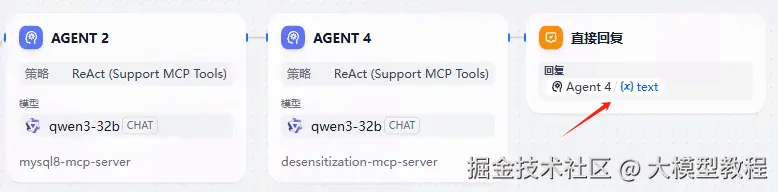
注意:这里可以看到绿色的连接线条,可以清晰的看到工作流的走向,它确实是按照我预期的方向在走。
李华的老师,查询一下个人详细信息
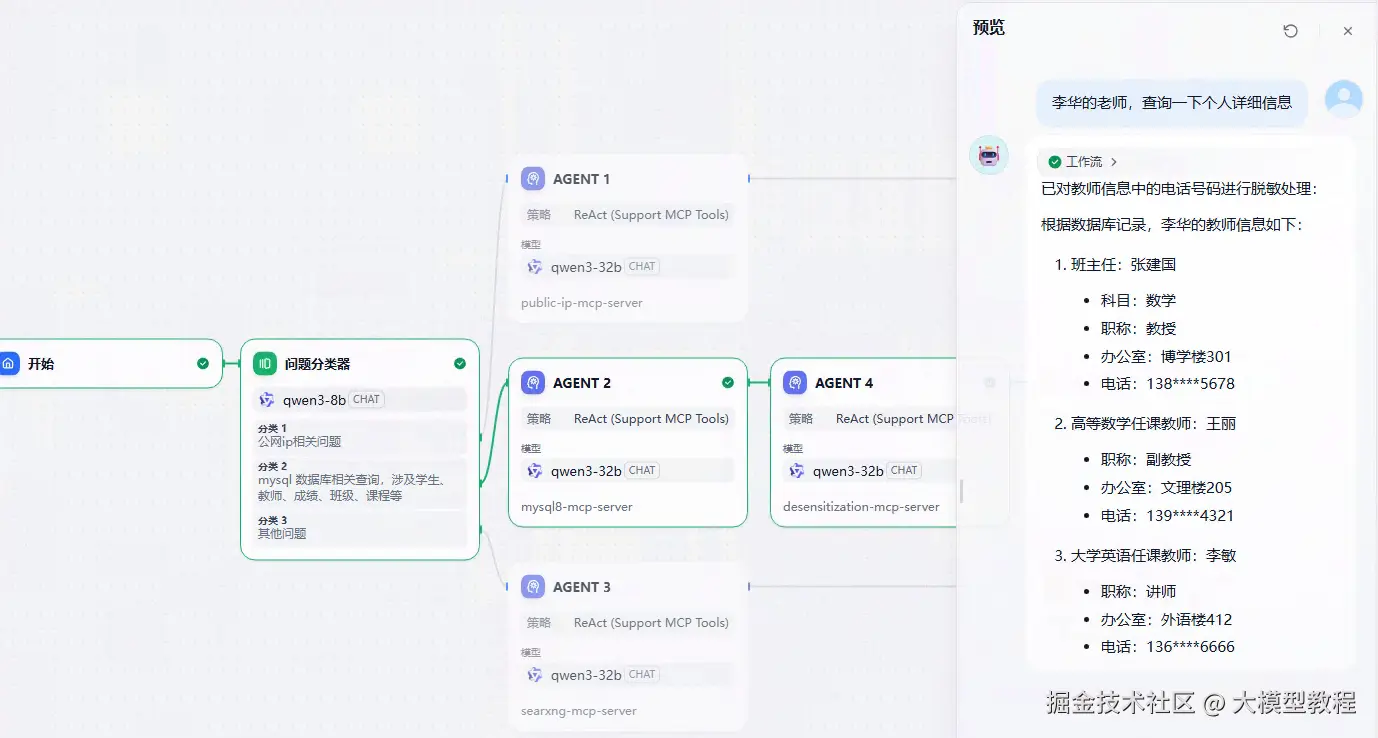
可以看到通过问题分类器,分别走向AGENT 2,AGENT 4,最终得到的答案,是进行了脱敏处理。
上海今天天气如何
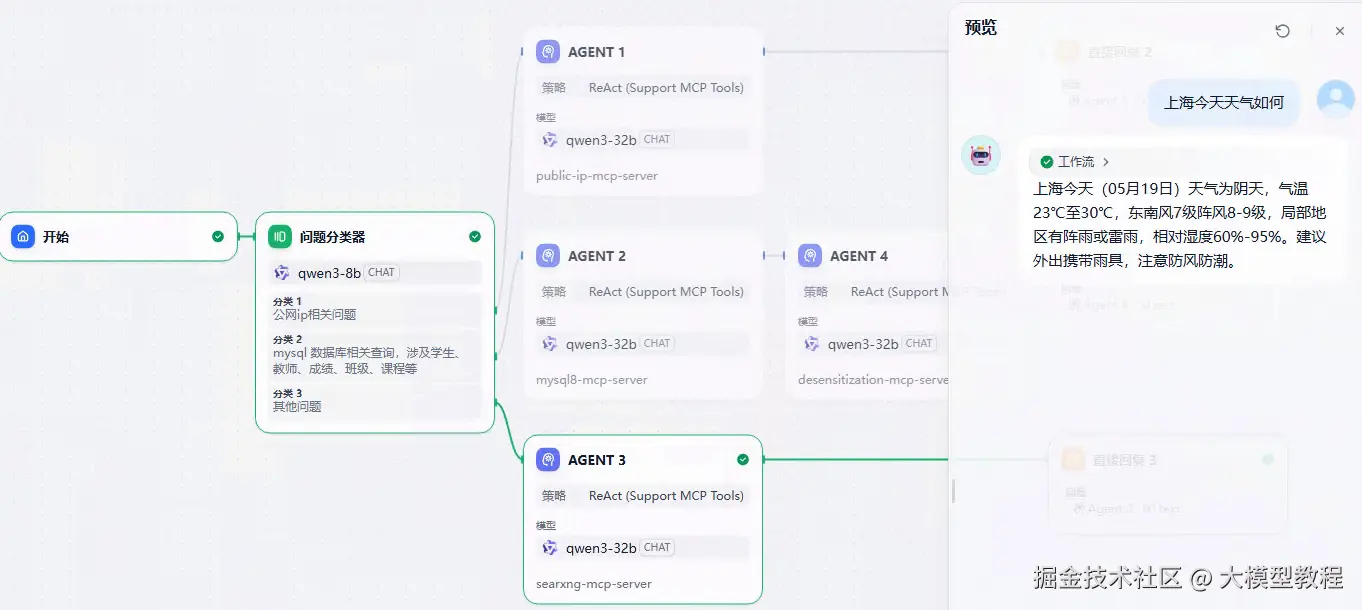
这里直接联网搜索答案了
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。