
DeepSeek-R1 会推理,GPT-4o 会看。能否让
1 LLM既能看又能推理?
DeepSeek-R1取得很大成功,但它有个问题------无法处理图像输入。
1.1 DeepSeek模型发展
自2024.12,DeepSeek已发布:
- DeepSeek-V3(2024.12):视觉语言模型(VLM),支持图像和文本输入,类似 GPT-4o
- DeepSeek-R1(2025.1):大规模推理模型(LRM),仅支持文本输入,但具备更强的推理能力,类似 OpenAI-o1
我们已领略视觉语言模型(VLM)和大规模推理模型(LRM),下一个是谁?
我们需要视觉推理模型(VRM)------既能看又能推理。本文探讨如何实现它。
2 现有模型的问题
当前VLM 不能很好推理,而 LRM 只能处理文本,无法理解视觉信息。若想要一个既能看懂图像 ,又能深度推理的模型?
物理问题示例
我是一个学生,向 LLM 提问物理问题,并附带一张图像。
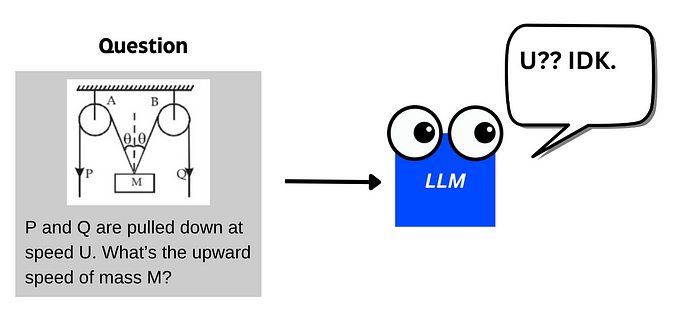
就需要一个模型能同时:
- 理解图像内容
- 进行深度推理(如分析问题、评估答案、考虑多种可能性)
就需要👉 一个大规模视觉推理模型(VRM),视觉推理模型示意图:
讨论咋训练 VRM 之前,先了解VLM(视觉语言模型)架构。
3 VLM架构
如LLaVA,L arge L anguage a nd V ision Assistant(大规模语言与视觉助手),2023年底发布的知名 VLM。
LLM 通常采用 Transformer 结构,输入文本后将其转化为 token,再通过数学计算预测下一个 token。
如若输入文本 "Donald Trump is the" ,LLM可能预测下一 token 为 "POTUS"(美国总统)。LLM 预测过程示意图:
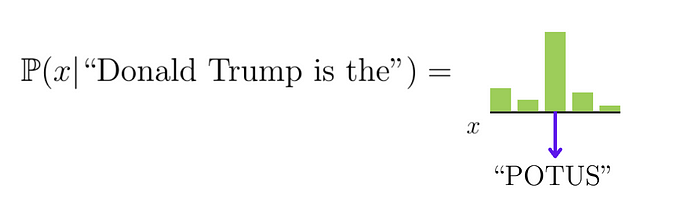
那VLM咋工作的?VLM不仅根据前面的文本预测输出,还会参考输入的图像。VLM 预测过程示意图:

但咋让 LLM 理解图像?
4 VLM咋处理图像输入?
核心思路:将图像数据转换成 LLM 能理解的格式。
LLaVA论文用 CLIP 视觉编码器 将图像转化为向量。然后,在编码器后添加一个可训练的线性层。图像编码示意图:
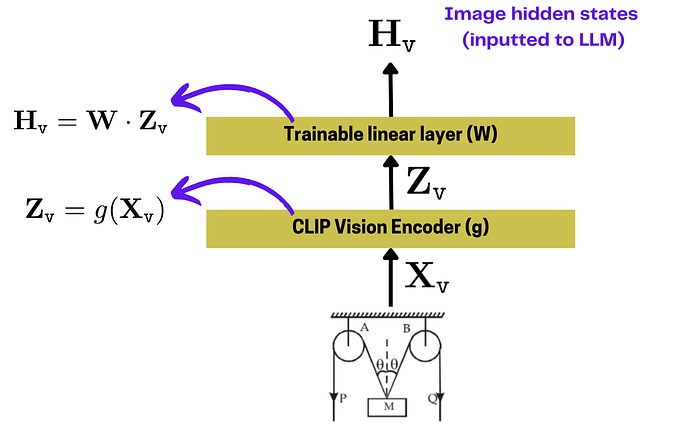
最终的视觉隐藏状态(Hv)会与文本 token 的隐藏状态拼接在一起,输入 Transformer 层,最后生成预测结果。
LLaVA 在这里使用的是 Vicuna 作为 LLM。
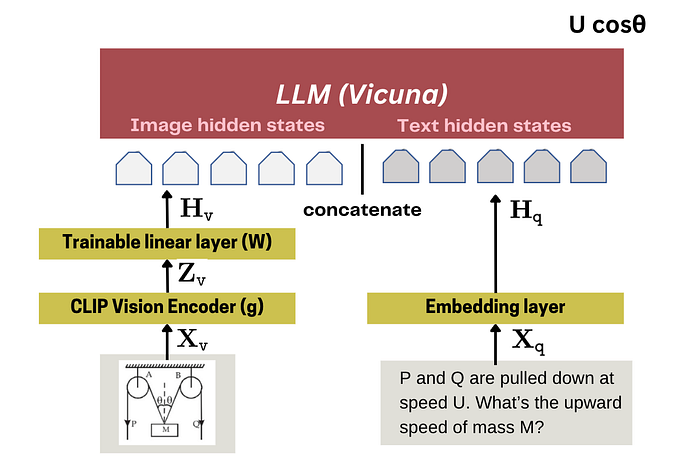
不过,仅仅有这个结构是不够的,模型还需要训练,才能真正理解图像内容。
5 VLM咋训练?
LLaVA 采用了**端到端微调(End-to-End Fine-tuning)**的方式。
端到端微调:将整个模型视作一个黑盒,并进行整体训练。
LLaVA 端到端微调示意图:
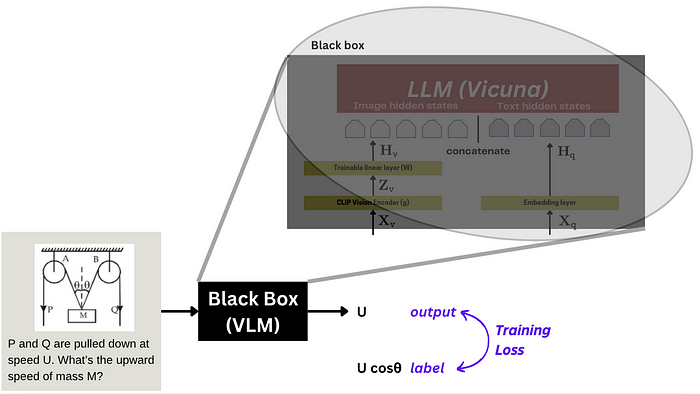
训练时,CLIP编码器的参数通常是冻结的 ,只更新线性层(W )和 LLM(ϕ)的参数。LLaVA 微调过程示意图:
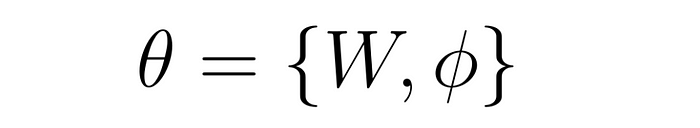
6 能否用强化学习(RL)训练 VLM?
RL在 LLM 领域表现出色,提升了推理能力(如 RLHF 训练的 GPT-4)。若用 RL 训练 VLM,是否能打造更强的视觉推理模型?
以图像分类任务为例。
6.1 任务定义:图像分类
训练时,希望模型能根据图像内容,输出正确的类别标签。
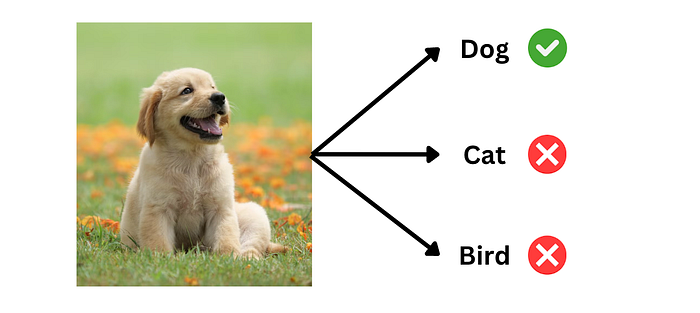
数据集中的每条数据包括:图像、标题(正确答案)、问题。

强化学习奖励设计
可设计两种奖励机制:
-
正确性奖励:如果模型输出的答案正确(例如"dog"),则奖励 +1。
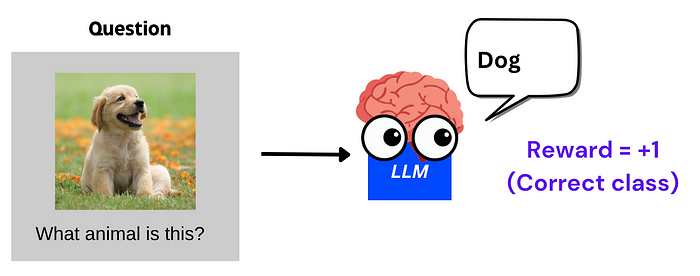
-
格式奖励 :如果模型按照固定格式输出(先思考
<think>,再回答<answer>),则额外奖励。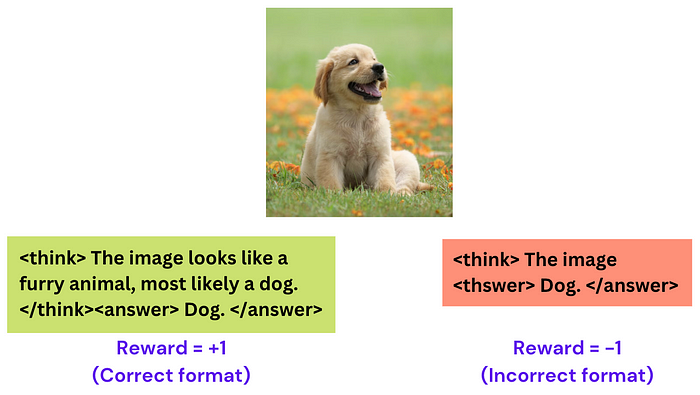
这可鼓励模型在回答前进行推理,而不是盲目给出答案。
7 实际应用
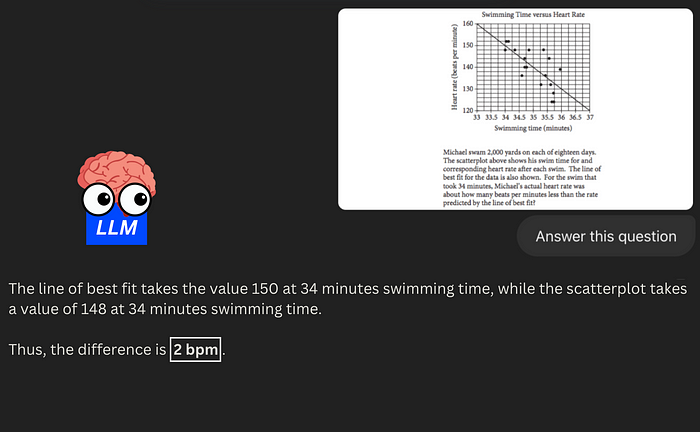
VLM目前在某些场景仍表现不佳,如数学和科学类问题。
如题目正确答案 2 bpm,但 GPT-4o 回答错误:
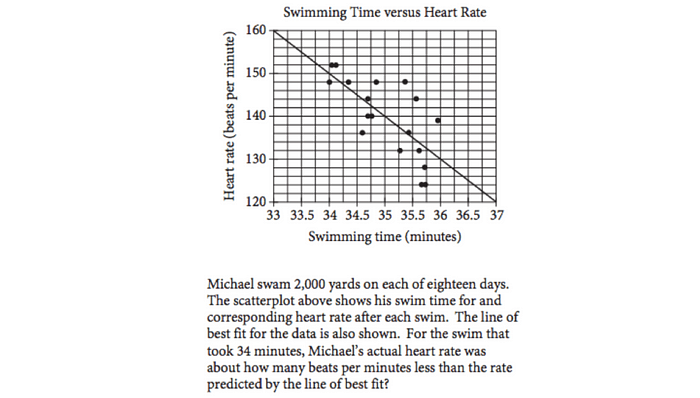
GPT-4o错误回答:
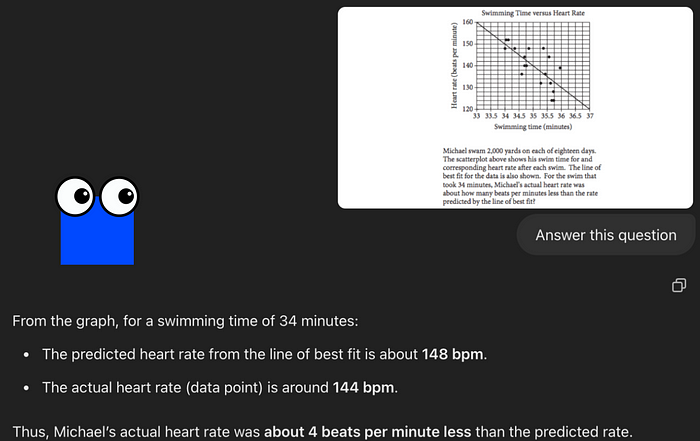
如能让 LLM 在视觉推理方面更强,或许能正确解答。期望的 VRM 结果:
本文已收录在Github,关注我,紧跟本系列专栏文章,咱们下篇再续!
- 🚀 魔都架构师 | 全网30W+技术追随者
- 🔧 大厂分布式系统/数据中台实战专家
- 🏆 主导交易系统百万级流量调优 & 车联网平台架构
- 🧠 AIGC应用开发先行者 | 区块链落地实践者
- 🌍 以技术驱动创新,我们的征途是改变世界!
- 👉 实战干货:编程严选网
本文由博客一文多发平台 OpenWrite 发布!