一、文件的随机读写
在前面我们学习了文件的顺序读写的函数,那么当我们要读取某个指定位置的内容的时候,是否只能顺序的读取到这个内容?还有在对文件进行输入的时候,需要对指定的位置进行写入,那么此时应该怎么办呢?
我们也可以使用函数来更改读写的位置的,从而实现随机读写。
1、fseek函数
fseek函数是用来定义文件内容的光标,光标是默认在文件的开头的,我们前面使用的顺序读写的函数,其是使用一次后,光标是会向后移动一个位置的。·而fseek函数可以通过偏移量来定位光标,然后再从这个位置进行读写。
原型:
int freek(FILE*stream,long int offset,int origin );
如果函数定位成功,那么就会返回0, 如果返回失败就返回一个非0的值。
其第一个参数是我们要定位光标的流,第二个参数是偏移量,第二个参数要看我们第三个参数来定。
然后第三个参数可以取下面的三个值:

当其取SEEK_SET的时候,光标的偏移量要从文件的头部开始计算,当其为SEEK_CUR的时候,那么光标的偏移量要从当前光标的位置开始计算,当这个值为SEEK_END的时候,那么光标的偏移量就要从尾部开始计算。
下面我们通过一个例子来理解:
我们一个文件存储着hello五个字符,然后我们此时的光标在h后面的这个位置,然后我们要获取第四个位置的字符,那么我们就要将这个光标移动到第四个字符前面的位置。但是我们要看第三个参数的值是什么才可以确定这个偏移量。
当origin的值为SEEK_SET的时候,那么我们的光标就要从头开始移动,那么我们此时的光标的偏移量应该为3才可以。
当origin的值为SEEK_CUR的时候,那么我们的光标就是从当前的位置开始计算,那么我们此时的偏移量应该为2。
当origin的值为SEEK_END的时候,那么我们的光标就会从尾部开始计算,那么我们此时的偏移量应该为-2。
所以第二个参数的值要看第三个参数的值来决定。
下面我们通过代码来实际操作:

上面这个程序,首先我以文本写的方式打开了这个文件,然后我们使用fputs函数对这个文件进行写入一个字符串,然后我们使用fseek函数对其进行随机读写,首先我们看第三个参数,此时我们的第三个参数是SEEK_SET,那么此时我们是从头开始计算偏移量,然后我们第二个参数是我们此时的偏移量,那么我们的是9,那么就使得光标此时移动到偏移量为9的位置,那么此时的光标就在n的位置的前,那么我们再使用fputs函数,从这个位置对其进行写入,我们这个写入是会将原来的内容覆盖的,还有就是空白符也是一个位置的,然后我们就将原来的内容进行修改了。
下面我们运行代码看看文件修改后的内容:

可以看到我们文件的内容就被修改成这样了。
但是我们发现这个函数还是有点不方便,就是这个偏移量的计算,如果我们一个一个数非常不方便,还有就是我们有时对于空白的地方是几个位置是不好数的。那么有没有啥是可以帮助我们计算在这个偏移量的?
下面我们就学习这个可以帮助我们计算偏移量的函数:ftell函数。
2、ftell函数
这个函数的作用就是将当前光标的位置到文件开头的偏移量返回。
原型:
long int ftell(FILE*stream);
其还是原型还是很简单的,其参数就是我们要进行操作的流,然后返回值是一个长整型,返回值就是当前这个文件的光标到开头的偏移量。
我们来使用这个函数来看看其使用效果:
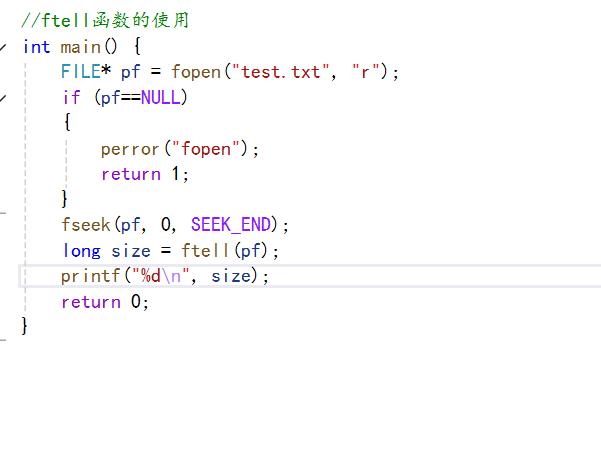
运行结果:

我们先来分析一下上面的代码,首先我们以文本读的方式打开这个文件,然后我们将这个光标移动到这个文件的尾部,然后我们使用ftell函数计算当前的光标的位置到文件头部的偏移量,那么得到的就是我们这个文件内容的字节数,刚刚好是16个字节。
3、rewind函数
这个函数的功能就是将文件中的指针回到开始的位置,也就是将这个光标重新回到开头处。
原型:
void rewind(FILE*stream);
它的参数就是我们要进行操作的流,其功能就是将文件中的光标移动到开头。
下面我们使用这个函数:
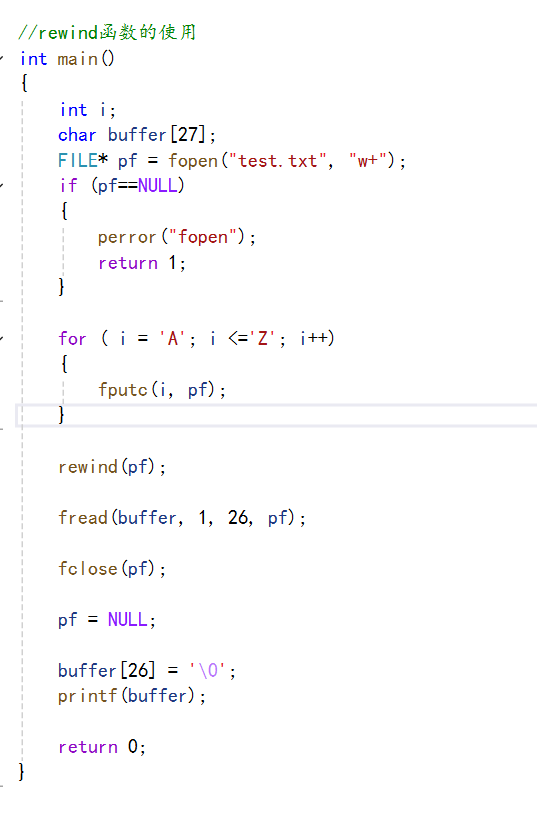
下面我们分析一下这段代码:
我们首先以读写的方式打开这个文件,然后我们使用一个循环,将大写字母A~Z的字符写入到我们的文件中,此时我们的文件的光标就应该在尾部了,然后我们再使用rewind函数,那么此时我们的光标就处于开头处了,然后我们又使用fread函数将这个文件的内容读取出来,存放在字符数组buffer中,然后我们关闭这个文件,将这个数组的内容打印出来:
运行结果:

可以发现这个数组存放的内容就是文件的内容。
不过上面还有一个问题就是,fread函数是对二进制文件进行操作的,那么我们通过上面的例子就可以发现,这个函数对于文本文件也是可以读取文本文件的。
那么fwite函数其实也可以对文本文件进行操作的。
二、文本读取结束的判断
1、被错误使用的feof
牢记:在文本读取中,不能使用feof函数的返回值来直接判断文本的读取是否结束。
feof函数的作用是当文件读取结束的时候,判断的是读取结束的原因,是否是读取到结尾结束。
那么其使用的前提是:文件读取已经结束了。
2、判断文件读取结束的方法
我们对于不同的文件,有其对应的方法:
(1)文本文件
根据我们的读取函数的返回值来确定,前面我们学习的到了文件读取的函数。
判断fgetc函数的返回值是否为EOF
判断函数fgets的返回值是否为NULL
(2)二进制文件
freacd函数判断返回值是否小于实际要读的个数。
3、判断文件读取结束的原因
我们上面学习了判断文件读取结束的方法,那么就是说,文件读取结束不一定就是正常的,那么有那些错误读取结束呢?
首先正常读取是文件读取到了文件的末尾处。
错误读取就是因为某种原因导致文件读取中途就结束了读取。
我们判断读取是否正常就使用feof函数和ferror函数。
feor这个函数我们上面已经介绍过了。
其原型如下:
int feof(FILE*stream);
ferror函数是在文件读取结束后,用来判断文件是否是错误读取结束,其原型如下:
int ferror(FILE*stream);
它是参数是要操作的流,如果文件是错误读取结束,那么就返回一个非0值,如果没有错误结束,那么就返回0
下面我们通过实例来理解:

那么在上面我们使用一个循环对这个文件进行读取,然后使用feof函数进行判断,如果其返回值是非0值,那么就说明其是非正常结束,如果是0那么就说明是正常结束。
三、文件缓冲区
我们在对文件进行写入操作的时候,这时候如果我们点进这个文件看的时候,我们写入的内容并不是立马就在文件中出现的,而我们关闭文件后,再重新打开这个文件,此时就可以在文件中找到我们写入的内容了。
这就得知道我们的文件缓冲区的内容了。
ANSIC标准采⽤"缓冲⽂件系统"处理的数据⽂件的,所谓缓冲⽂件系统是指系统⾃动地在内存中为 程序中每⼀个正在使⽤的⽂件开辟⼀块"⽂件缓冲区"。从内存向磁盘输出数据会先送到内存中的缓 冲区,装满缓冲区后才⼀起送到磁盘上。如果从磁盘向计算机读⼊数据,则从磁盘⽂件中读取数据输 ⼊到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓 冲区的⼤⼩根据C编译系统决定的。