一、下载
可以去官网下载:https://kafka.apache.org/downloads
版本可选择,建议下载比较新的,新版本里面自带zookeeper

二、安装
创建一个目录,此处是D:\kafka,将文件放进去解压
如果文件后缀是gz,解压后没有文件夹,此时需要先将文件后缀修改为tgz,然后再解压

进入kafka目录,创建一个data和log目录,用作zookeeper和kafka的数据和日志目录
三、修改配置
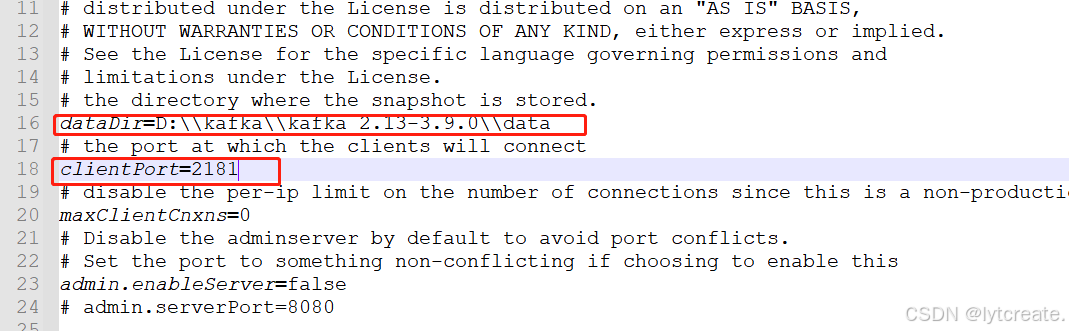
1.修改zookeeper的配置,使用编译器打开 config文件夹下面的zookeeper.properties文件,然后修改
dataDir,这个值改为自己刚才创建的data目录地址,使用\\连接
clientPort=2181
修改后,确认保存
2.修改kafka配置文件,打开config文件夹下的server.properties文件,修改内容
port,9092是默认的端口号
host.name,修改为自己的IP,一般是本机或者局域网IP
listeners,修改为自己的IP和端口
log.dirs,填写为自己刚才创建的log文件夹,\\连接
zookeeper.connect=127.0.0.1:2181,这个根据自己情况写IP和端口,上面配置的



四、启动服务
1.启动zookeeper服务
先进入kafka解压后的根目录,然后在cmd里面执行如下命令:
bin\windows\zookeeper-server-start.bat config\zookeeper.properties
2.启动kafka
先进入kafka解压后的根目录,然后在cmd里面执行如下命令:
bin\windows\kafka-server-start.bat config\server.properties
温馨提示:如果kafka没有正常关闭,可能下一次启动就会报错,可以删除data,log和logs目录里面的内容之后,再从启动zookeeper开始往下走
3.创建topic
创建一个test_topic
bin\windows\kafka-topics.bat --create --topic test_topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
4.查看topic列表
.\bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092
5.启动producer生产者
如果使用代码去创建生产者和消费者此步骤不需要
假设你要向名为 test_topic 的主题发送消息,并且 Kafka 代理地址是 localhost:9092,可以运行以下命令:
.\bin\windows\kafka-console-producer.bat --topic test_topic --bootstrap-server localhost:9092
启动后进入输入模式,等待生产者输入,输入测试的123,234

6.启动customer消费者
如果使用代码去创建生产者和消费者此步骤不需要
.\bin\windows\kafka-console-consumer.bat --topic test_topic --bootstrap-server localhost:9092 --from-beginning启动后,可以看到生产者发送的内容:

五、Python代码实现生产者和消费者
pip install kafka-python模拟生产者代码,通过输入进行内容控制:
import uuid
from kafka import KafkaProducer
import json
import time
# 配置 Kafka 生产者
producer = KafkaProducer(
bootstrap_servers=['127.0.0.1:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8')
)
# 要发送的主题名称
topic = 'test_topic'
try:
while True:
content = input("内容:")
message = {
'id': uuid.uuid4().hex,
'message': f'{content}'
}
# 发送消息
future = producer.send(topic, value=message)
# 等待消息发送结果
result = future.get(timeout=10)
print(f"Sent message {content} to partition {result.partition} at offset {result.offset}")
except Exception as e:
print(f"Error sending message: {e}")
finally:
# 刷新缓冲区并关闭生产者
producer.flush()
producer.close()消费者模拟:
from kafka import KafkaConsumer
import json
# 配置 Kafka 消费者
consumer = KafkaConsumer(
'test_topic',
bootstrap_servers=['127.0.0.1:9092'],
value_deserializer=lambda m: json.loads(m.decode('utf-8')),
auto_offset_reset='earliest'
)
try:
# 持续消费消息
for message in consumer:
print(f"Received message: {message.value} from partition {message.partition} at offset {message.offset}")
except KeyboardInterrupt:
print("Consumer interrupted by user.")
finally:
# 关闭消费者
consumer.close()在生产者输入 hello,yes进行测试:
 在消费者代码出进行获取:
在消费者代码出进行获取:

注意消费者的message本身就是一个可迭代对象,是无穷尽的。
并且**auto_offset_reset**参数控制了是从第一个开始获取还是从接入的时候再算起,移除参数就代表从接入开始获取message里面的数据,如果是 earliest 就会从第一个开始获取,即使已经处理了!
那么,如果是消费者掉线,生产者在掉线期间新增了若干条数据,如何让消费者上线后从没有处理的数据开始处理呢?可以给消费者设置三个参数并且手动commit:
auto_offset_reset='earliest', # 从最新的消息位置开始消费
enable_auto_commit=False, # 开启自动提交偏移量
group_id='aaa'参考代码:
from kafka import KafkaConsumer
import json
# 配置 Kafka 消费者
consumer = KafkaConsumer(
'test_topic',
bootstrap_servers=['127.0.0.1:9092'],
value_deserializer=lambda m: json.loads(m.decode('utf-8')),
auto_offset_reset='earliest', # 从最新的消息位置开始消费
enable_auto_commit=False, # 关闭自动提交偏移量
group_id='aaa'
)
try:
# 持续消费消息
for message in consumer:
print(f"Received message: {message.value} from partition {message.partition} at offset {message.offset}")
consumer.commit() # 手动提交偏移量
except KeyboardInterrupt:
print("Consumer interrupted by user.")
finally:
# 关闭消费者
consumer.close()