代码实现的主要功能:
-
浏览器自动化控制
-
验证码图像获取与处理
-
OCR验证码识别
-
表单自动填写与提交
-
登录状态验证
-
异常处理与资源清理
1. 浏览器初始化与页面加载
python
driver = webdriver.Chrome()
driver.get("https://www.gushiwen.cn/user/login.aspx?from=http://www.gushiwen.cn/user/collect.aspx")
time.sleep(2)-
功能:启动Chrome浏览器并打开古诗文网登录页面
-
关键点:
-
webdriver.Chrome()初始化浏览器驱动 -
time.sleep(2)确保页面完全加载(实际建议改用WebDriverWait)
-
2.验证码捕获与预处理
python
code_img = driver.find_element(By.ID, 'imgCode')
img_bytes = code_img.screenshot_as_png
image = Image.open(io.BytesIO(img_bytes))
image = image.convert('L') # 灰度化-
功能:获取验证码图像并优化识别条件
-
关键点:
-
screenshot_as_png直接获取二进制图像数据 -
convert('L')将彩色图转为灰度图,提升OCR准确率 -
注释掉的二值化代码可用于高对比度验证码
-
3. OCR验证码识别
python
custom_config = r'--psm 7 --oem 3 -c tessedit_char_whitelist=0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'
textcode = pytesseract.image_to_string(image, config=custom_config)
textcode = textcode.strip().replace(' ', '')[:4]-
功能:通过Tesseract引擎识别验证码文本
-
关键参数:
-
--psm 7:单行文本识别模式 -
--oem 3:默认OCR引擎 -
tessedit_char_whitelist:限定识别字符集
-
-
数据处理:去除空格并截取前4位字符
4. 登录表单操作
python
driver.find_element(By.ID, 'email').send_keys("2833622025@qq.com")
driver.find_element(By.ID, 'pwd').send_keys("ckn12138")
driver.find_element(By.ID, 'code').send_keys(textcode)
driver.find_element(By.ID, 'denglu').click()-
功能:自动填写并提交登录表单
-
元素定位:
-
通过HTML元素的ID定位各输入框
-
denglu是登录按钮的ID
-
5. 登录结果验证
python
if "退出登录" in driver.page_source:
print("登录成功!")
html = driver.page_source
else:
print("登录失败,请检查账号或验证码!")-
验证逻辑:检查页面是否出现"退出登录"文本
-
成功操作:获取登录后的页面源码
-
失败处理:输出错误提示
6. 异常处理与资源释放
python
except Exception as e:
print("程序运行出错:", str(e))
finally:
driver.quit()-
异常捕获:打印任何运行时错误
-
资源清理:确保浏览器最终关闭
典型执行流程
-
打开浏览器 → 导航到登录页
-
定位验证码 → 图像预处理 → OCR识别
-
自动填写账号/密码/验证码 → 点击登录
-
检查登录结果 → 输出页面源码或错误信息
-
无论成功与否都关闭浏览器
具体代码展示
python
from selenium import webdriver
from selenium.webdriver.common.by import By
from PIL import Image
import pytesseract
import io
import time
# 初始化浏览器
driver = webdriver.Chrome()
driver.get("https://www.gushiwen.cn/user/login.aspx?from=http://www.gushiwen.cn/user/collect.aspx")
# 等待页面加载
time.sleep(2)
try:
# 获取验证码元素
code_img = driver.find_element(By.ID, 'imgCode')
# 将验证码截图保存到内存
img_bytes = code_img.screenshot_as_png
image = Image.open(io.BytesIO(img_bytes))
# 图像预处理(提高识别率)
image = image.convert('L') # 灰度化
# image = image.point(lambda x: 0 if x < 128 else 255, '1') # 二值化(根据需要启用)
# 识别验证码
custom_config = r'--psm 7 --oem 3 -c tessedit_char_whitelist=0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'
textcode = pytesseract.image_to_string(image, config=custom_config)
textcode = textcode.strip().replace(' ', '')[:4] # 清理结果并取前4位
print("识别的验证码:", textcode)
if len(textcode) == 4:
# 填写登录信息
driver.find_element(By.ID, 'email').send_keys("2833622025@qq.com")
driver.find_element(By.ID, 'pwd').send_keys("ckn12138")
driver.find_element(By.ID, 'code').send_keys(textcode)
driver.find_element(By.ID, 'denglu').click()
# 等待登录完成
time.sleep(3)
# 验证登录是否成功
if "退出登录" in driver.page_source:
print("登录成功!")
# 获取登录后的页面内容
html = driver.page_source
print(html)
else:
print("登录失败,请检查账号或验证码!")
else:
print("验证码识别失败或长度不正确")
except Exception as e:
print("程序运行出错:", str(e))
finally:
# 关闭浏览器
driver.quit()但是这个代码识别出来的验证码不准确 最好用超级鹰识别方式再识别一遍~
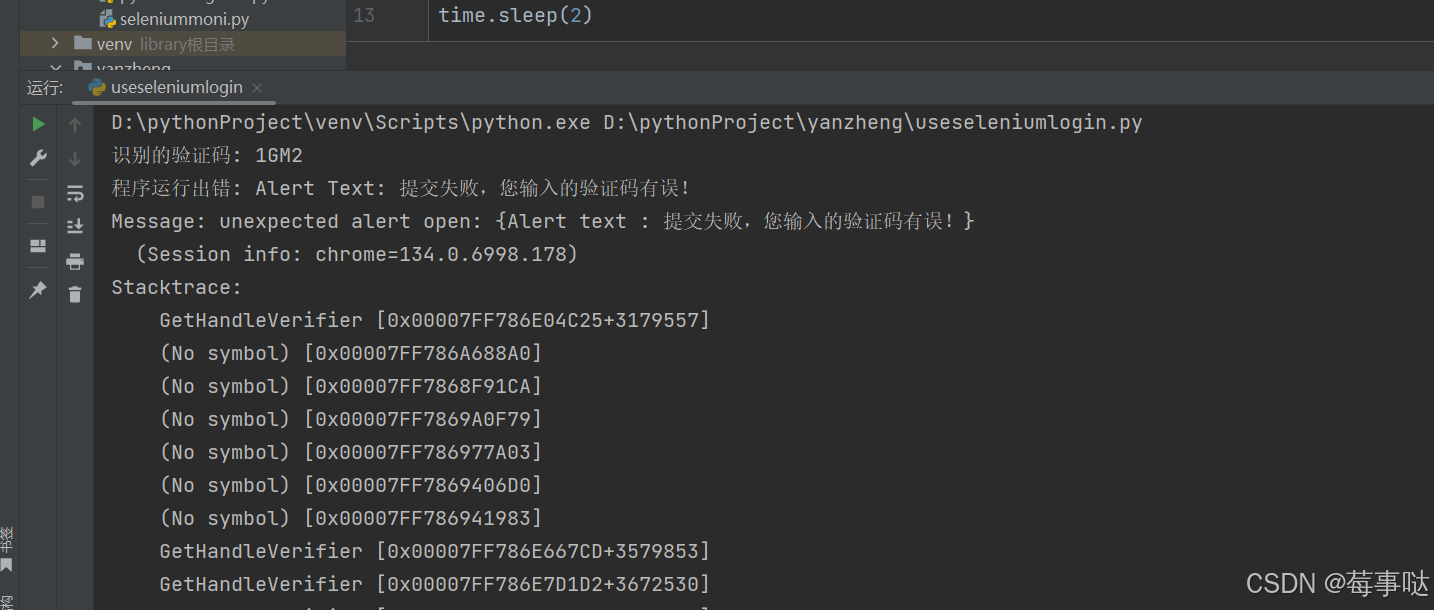
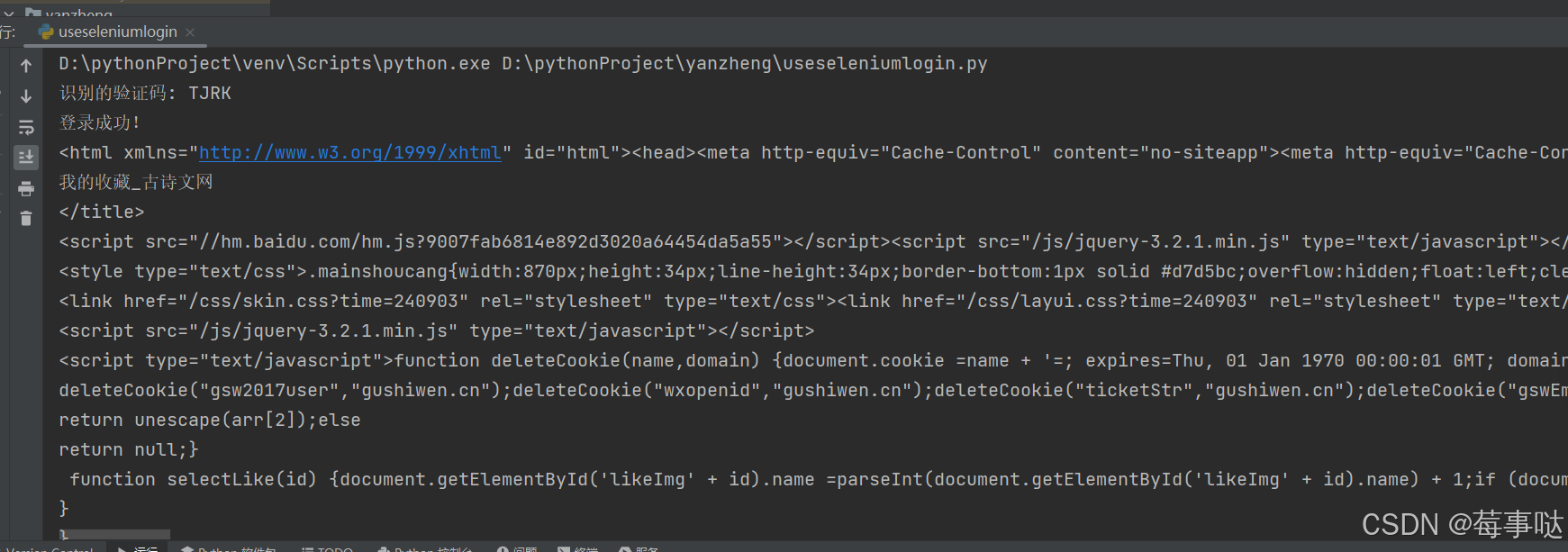
运行结果:

会自己填充账号密码之后

之后关闭浏览器
识别成功运行结果 因为验证码形式简单 比较好识别:
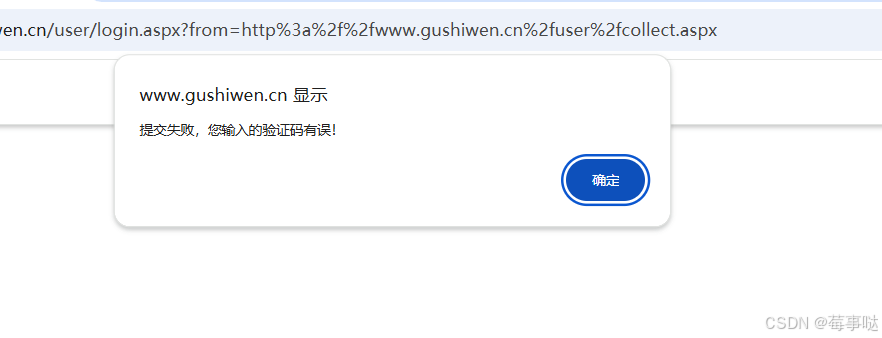
识别失败:
网页会显示验证码错误!