HTTP
 HTTP响应:这个响应的内容往往主题就是一个HTML内容。
HTTP响应:这个响应的内容往往主题就是一个HTML内容。


HTTP协议格式
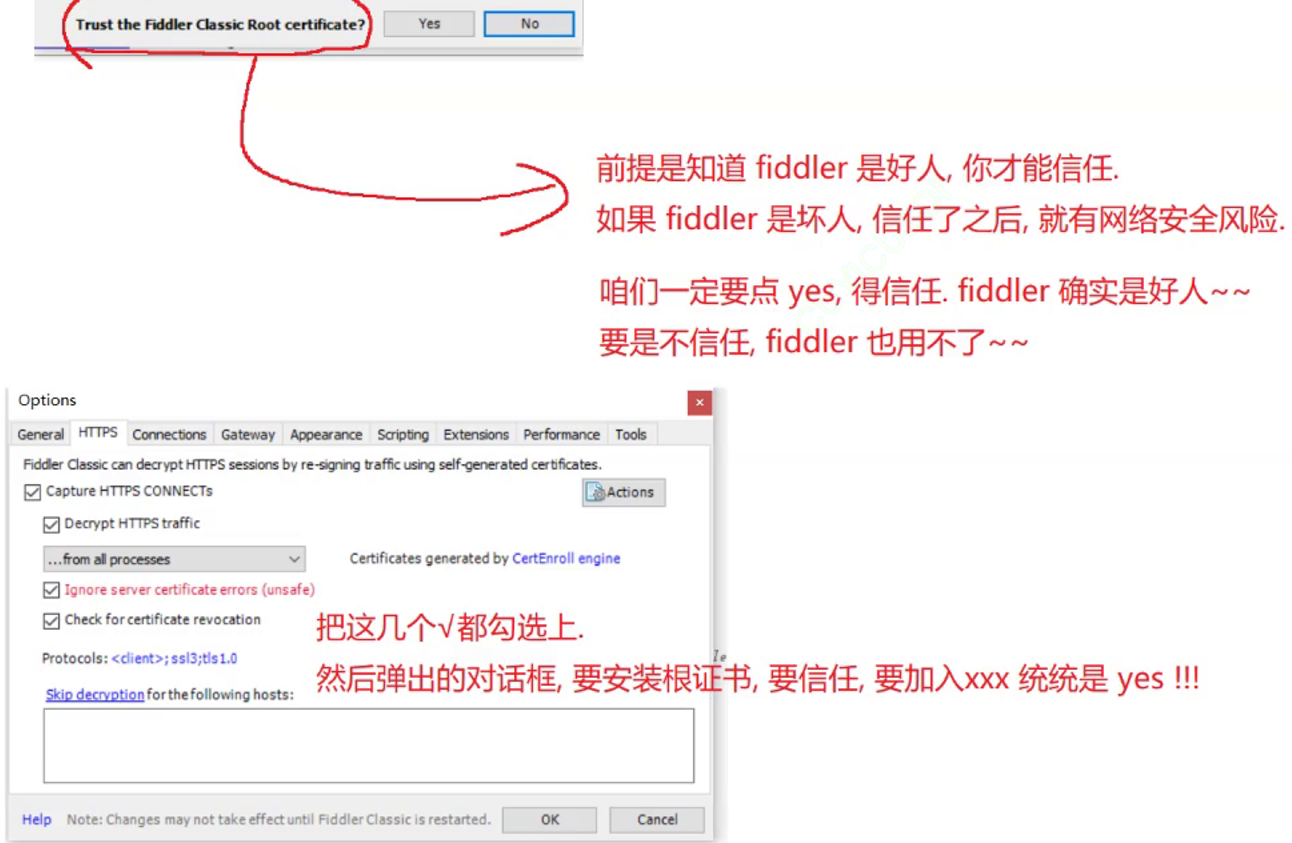
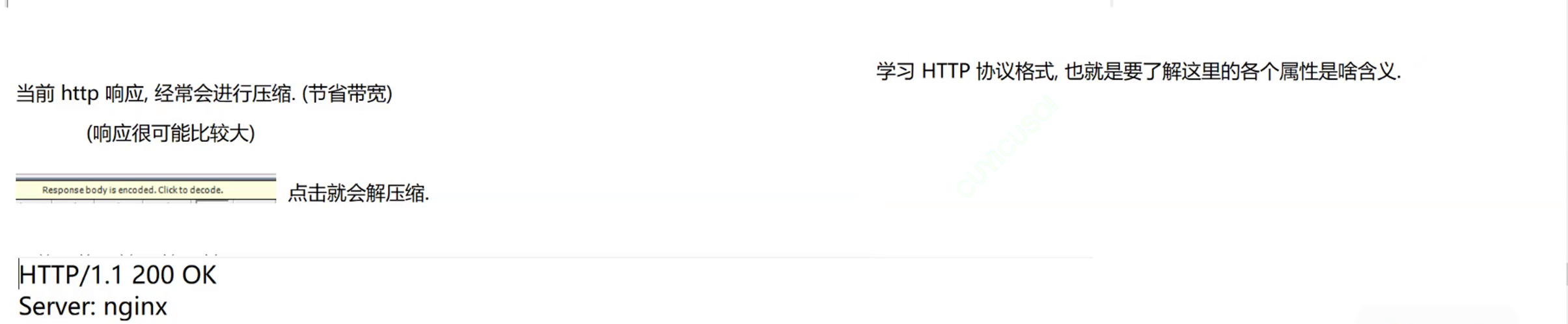
使用抓包工具进行分析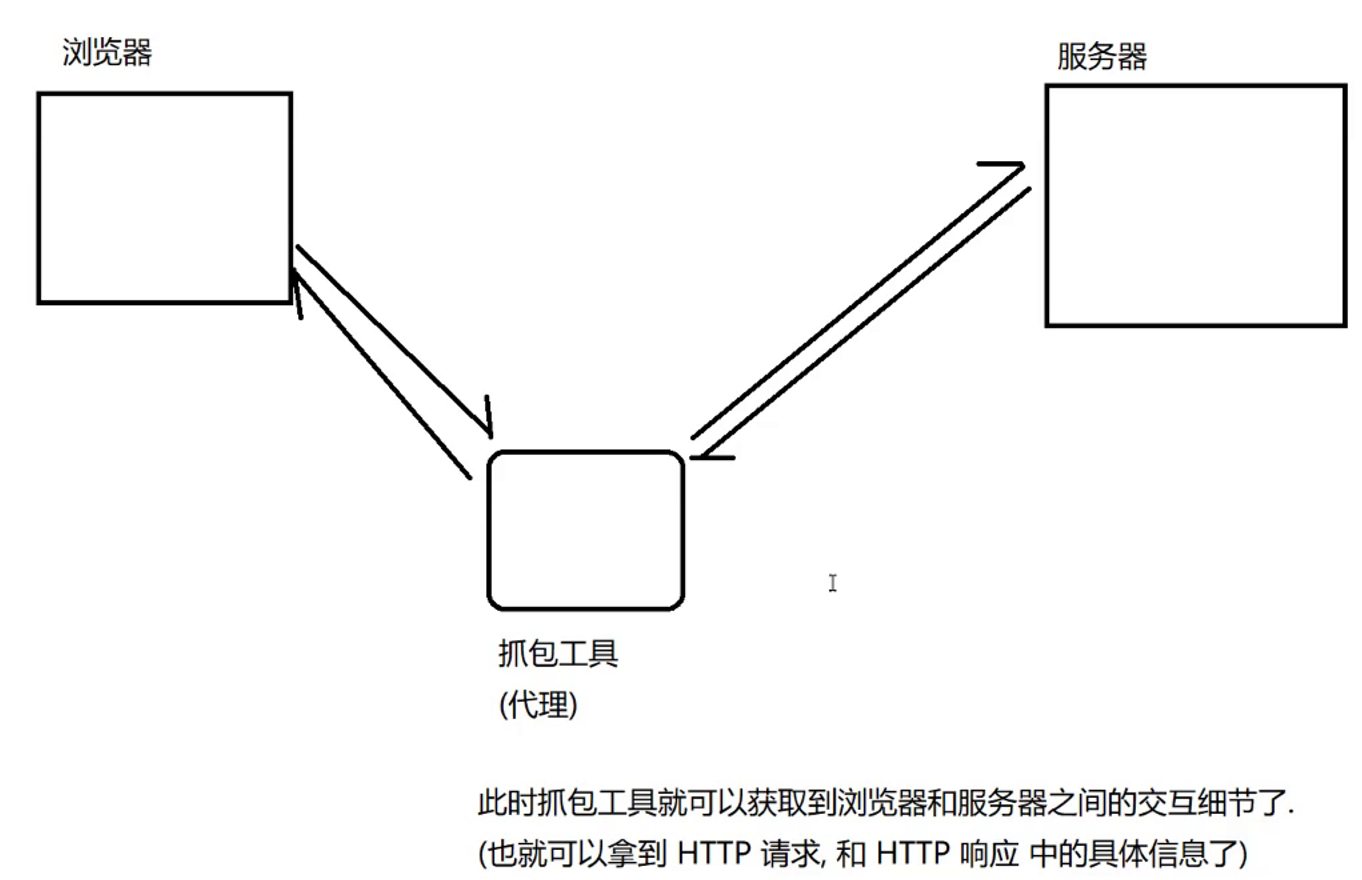


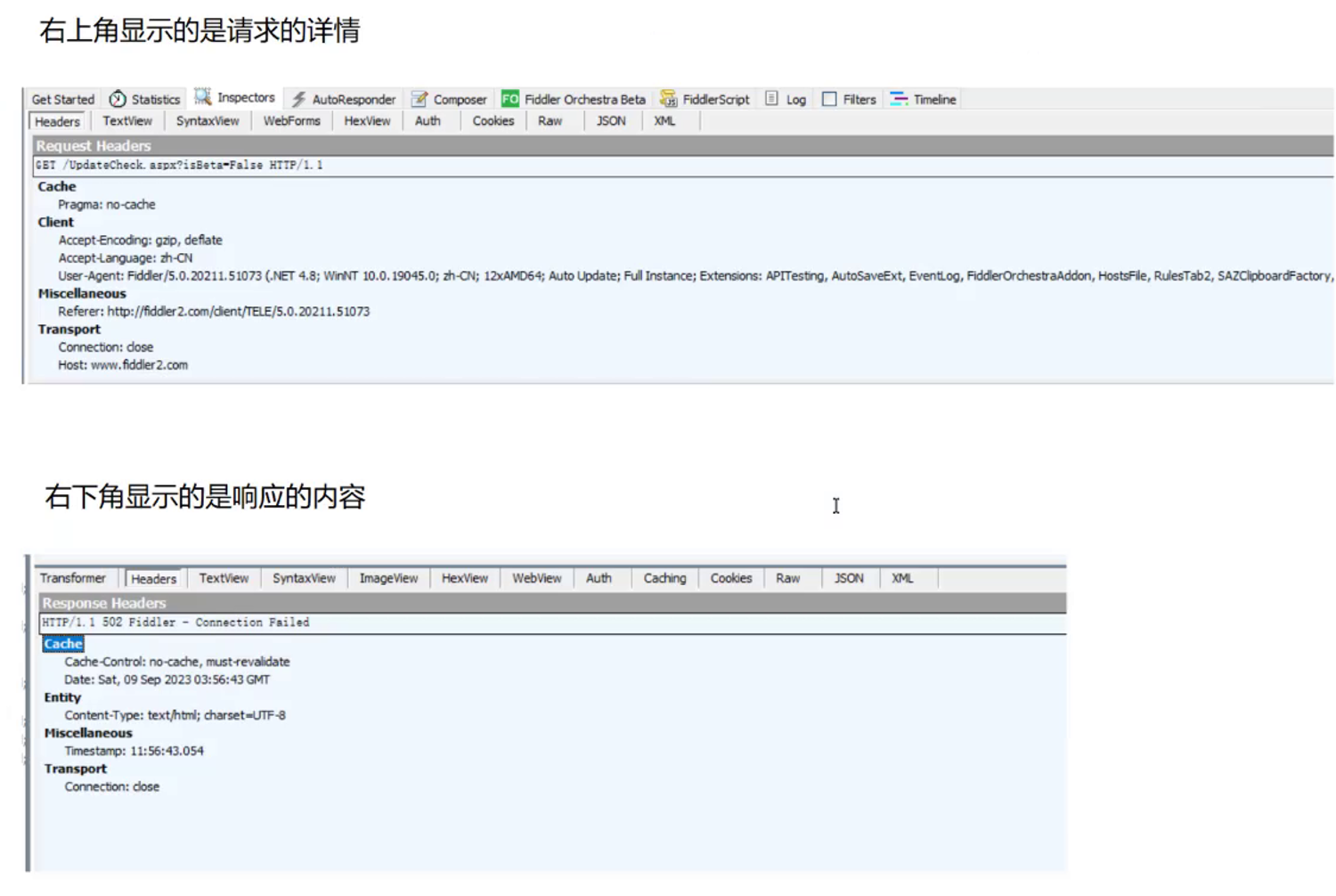


 请求
请求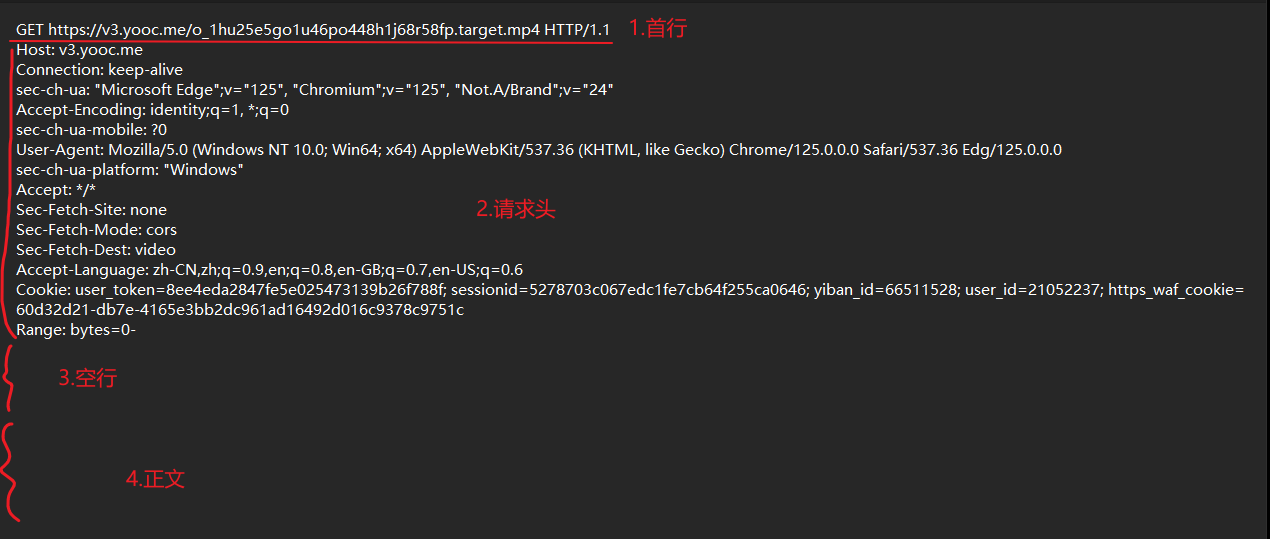
响应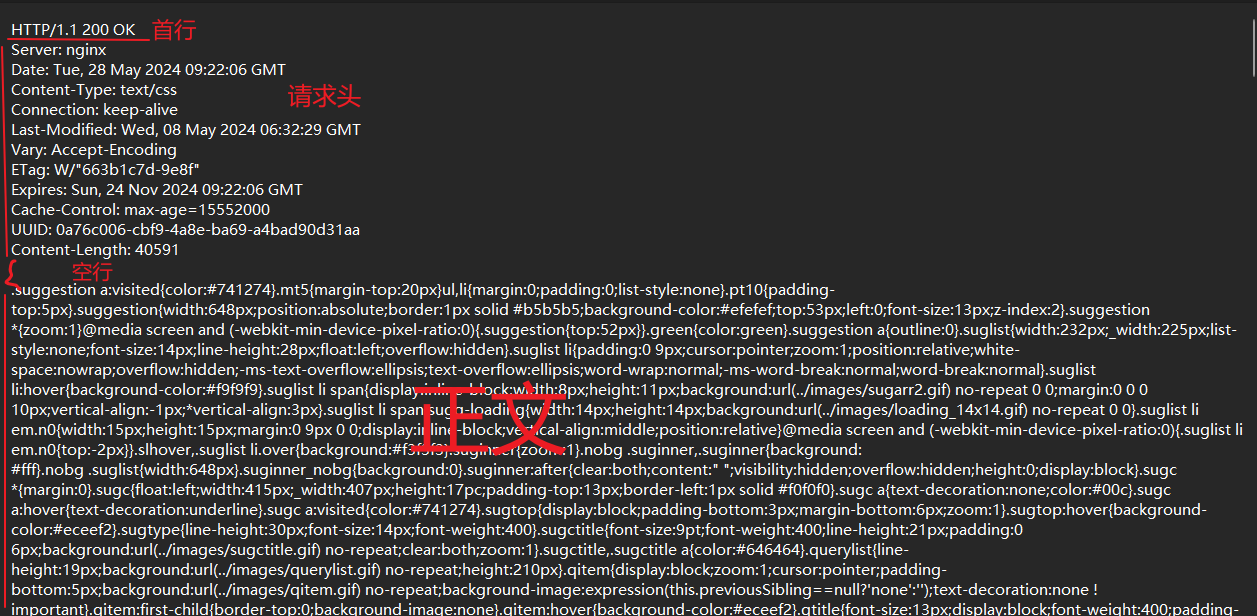
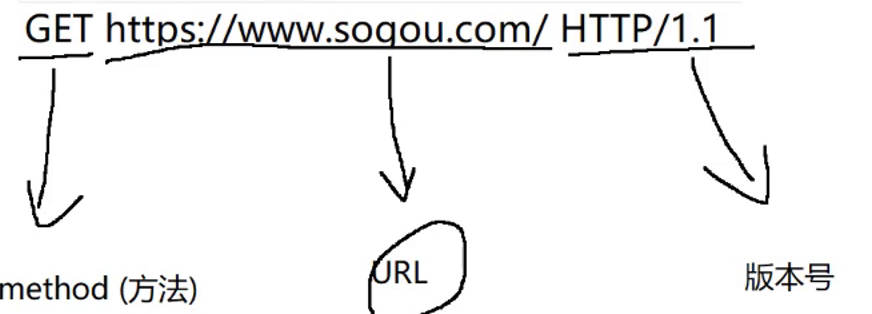 这三个部分使用空格来分割
这三个部分使用空格来分割
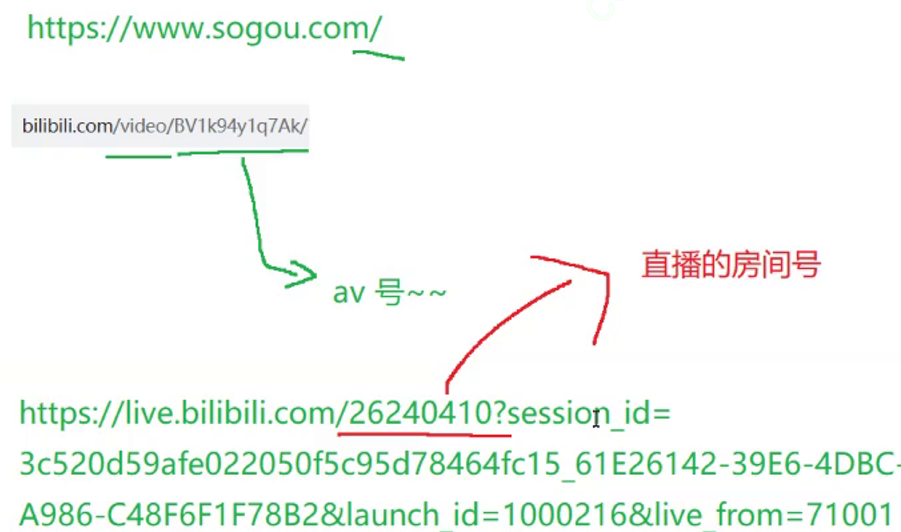
URL
URL:请求,就是客户端(浏览器)给服务器发起的一个数据,这里要明确描述出,要访问的服务器是什么,要访问的服务器的资源是什么。
URL是唯一资源定位符.用来描述网络上的资源的

查询字符串:访问资源的时候,带上什么样子的参数
片段标识符:不太常见,主要是文档类的网站中能够看到
端口号,也是可以省略的.
省略端口号时,浏览器会自动加上端口.(这个端口表示的是访问目标服务器的哪个端口)
如果是http协议,自动添加的端口就是 80
如果是https协议,自动添加的端口就是 443
回想:知名端口号
因此一个商业产品部署服务器的时候,往往就会遵守上述规则,把http服务器绑定到80,https绑定到443.这样浏览器访问你的服务器,就不必显示指定端口.当然不遵守上述规定,也是可以的.
带层次的路径也可以省略.
如果省略就相当于访问的就是/
/称之为根目录,通常对应到服务器的主页.
综上所述:
正是这样的的灵活性,使得http可以根据不同的需求场景,进行一些"自定制"工作.也就使http协议成了非常广泛的使用的协议.
URL encode
URLencode 本质上就是转义字符,只不过转义规则不一样.
转换规则:把要转换内容的二进制字节,都使用十六进制表示出来,然后每个字节前面加上一个 %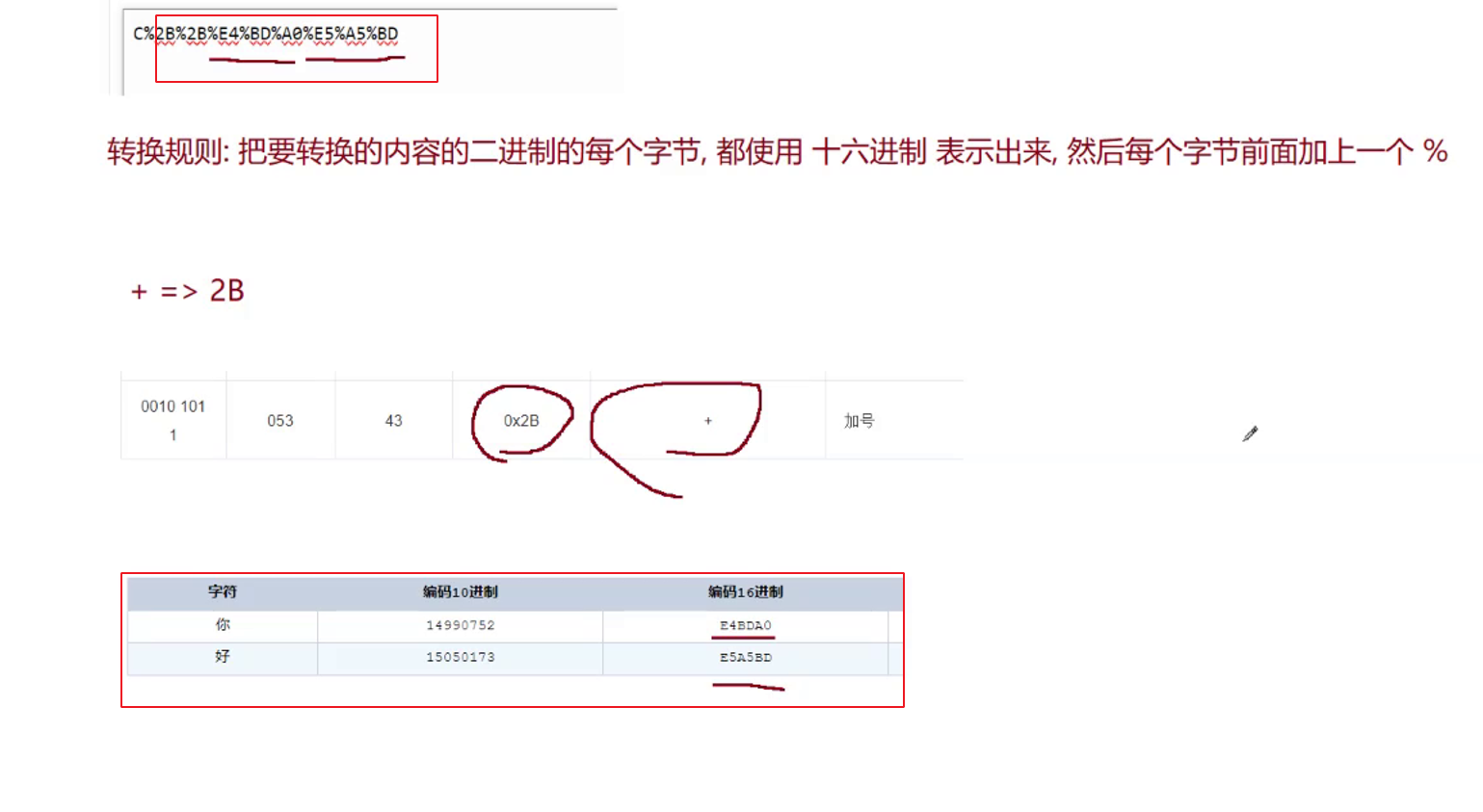
经过urlencode之后,此时query string 中就不会出现特殊含义的符号.浏览器和服务器才能正确的识别.
HTTP请求的方法

方法描述的是"语义"也就是这次要求要干什么
GET:"从服务器获取xxx"
POST:"向服务器传输一个xxx"
虽然HTTP协议设计之初,大佬们是希望程序员能够遵守这里的语义来使用HTTP的.但是实际上,事与愿违,放飞自我了.
实际上,GET POST等不一定遵守之前的语义了
登录
上传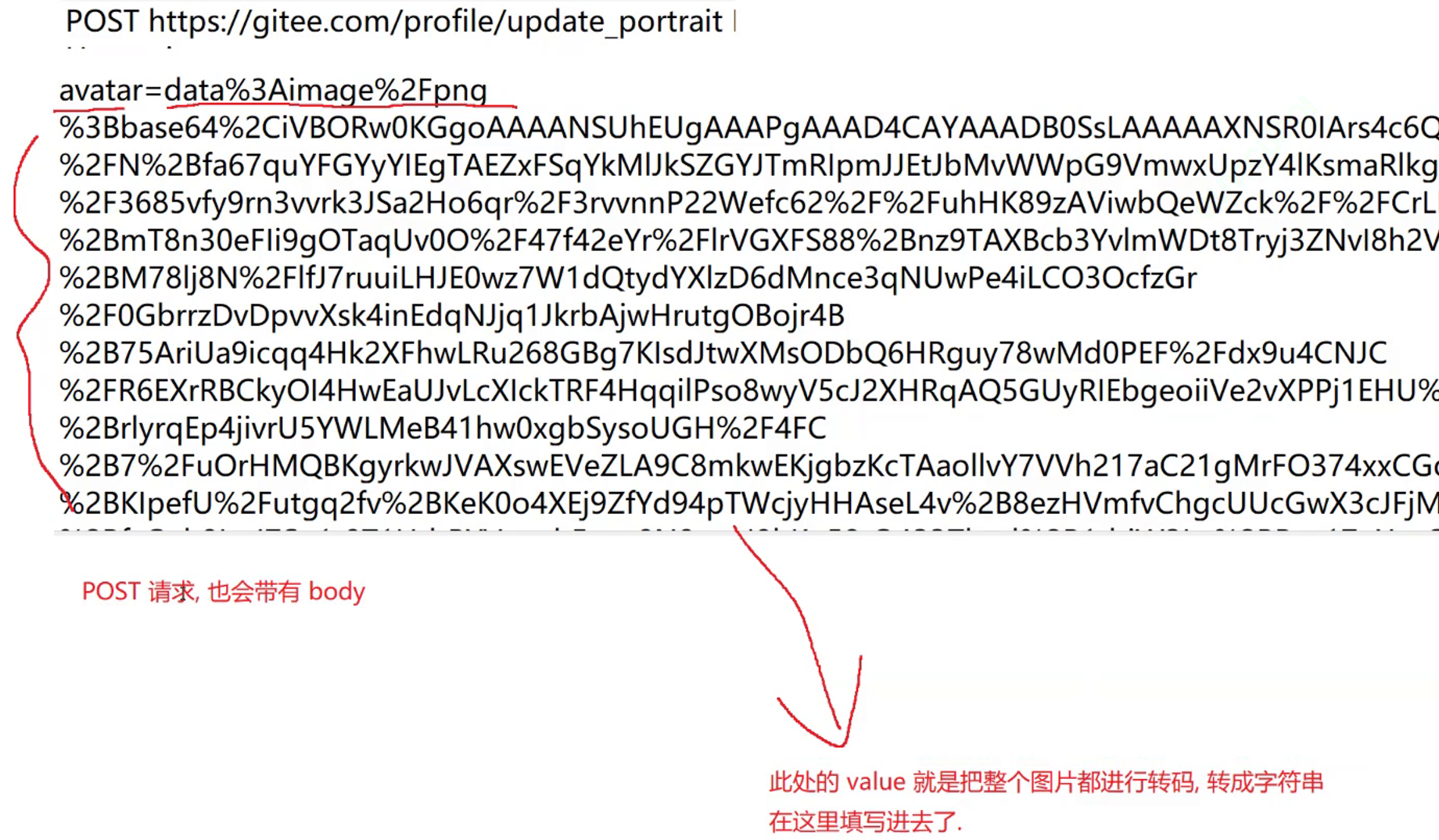
POST 和 GET 最主要的区别
GET 是吧一些自定义的数据放到query string里,body通常是空的.
POST 是吧一些自定义的数据放到body里,query string 通常是空的.
都是要传给服务器,放哪都是放,本质上没什么区别.细微的区别是:放在URL中,用户能直接看到,放在body中用户没办法直接看到.
误区
网上有些料,对于 GET 和 POST 的区别,解释的并不正确.
1.比较长的数据放到body中(使用post)原因是 GET 请求中的url长度有限制具体长度上限(好几种说法,1kb,2kb,10kb,64kb....)
首先 RFC 标准文档明确说明了,对于URL的长度不做限制要求.其次早在20年前,当年的机器资源有限,当时的浏览器对应URL确实有限制.具体限制了多长,看不同的浏览器了.这些都是老黄历了,在日常开发中,也会遇到一些非常长的URL(比如发整个图片放到URL)都是可能存在的.
2.POST 比 GET 更安全.
安全指的是咱们传输的数据不容易被黑客所截获.或者就算截获了,也不容易被破解.POST只是把传输的数据让普通用户没法直接看到,不影响黑客的截获.保证安全的关键是对敏感数据进行加密!!!
网上还有一些说法,也不能说有问题,也有一些需要注意的地方.
1.GET 和 POST 语义不同
设计者最初是赋予了不同的语义,但是实践中不一定完全遵守.比如有的公司,设计的所有接口都是POST 或者有的公司,设计的所有接口都是同时提供GET和POST...
2.GET是幂等的,POST不是幂等的(RFC文档上,建议这么设计)
给你相同的输入,每次都是相同的输出,就是幂等.如果每次输出不同,就不是幂等.
实际开发中,是否要遵守,看情况
- GET 请求可以被缓存,POST不能被缓存
缓存:有些操作,可能比较耗时,与其每次都重新计算,不如把结果保存下来,下次计算时,直接获取结果.
当然了可以缓存的前提是,你得是幂等的.
认识请求报头

这个请求报头,也是键值对结构,每一行是一个键值对,键和值之间使用 : " " 来分割
query string / body 中的键值对,完全是程序员自定义的.header中的键值对,主要是标准规定的.(有哪些健,对应的取值是有哪些,都有规定),也可以自定义的部分.
Host
表示服务器主机地址和端口
Host里的内容,不是在url中已经有了吗?为什么还要在显示一遍呢?
通常情况下,Host里的内容和url是一样的,但是也有例外.比如如果使用了代理,就不一定一样了.
Content-length
表示body中的数据长度
描述了body的长度是多少字节,有的请求有body,有的没有body,如果没有body,这个字段就可以没有.如果有body,这个字段必须由,否则就是非法请求了.
1.使用分隔符
2.使用长度
HTTP两个都有.
如果是GET,没有body,使用空行作为结束标记
Content-Type
表示请求的body中的数据格式
在http请求中,Content-Type有三种主要的情况

2.
3.


User-Agent(简称UA)

注意:从win11开始不支持使用这种方式来查看自己的操作系统的版本,win11在这里显示的是win10.
互联网发展早期,网站主要就是文字(早期的网站,相当于就是把报纸,杂志这样的传统媒体,搬到电脑上)
图片
js(交互)
播放视频/音频
......
浏览器不断地更新,支持的功能更加丰富了.
新的浏览器支持的功能更多
旧的浏览器支持的功能更少
同一时刻,市面上有的人使用的是新浏览器,有的人使用的是就浏览器
此时如果你开发一个网站,你是否要让这个网站上带有视频/音频/js等功能呢?
因此就想了个办法:
浏览器在发起http请求的时候,向服务器自报家门.告诉服务器,我是使用什么系统,什么浏览器上网的.服务器就可以根据这个信息,来分别对待不同的浏览器.
但是今天,各大浏览器功能都差不多了,UA的意义就小了不少.UA现在主要用来区分,PC端还是移动端.
Referer
描述了当前页面从哪里来
如果你是用过浏览器地址来直接输入url/点击收藏夹打开的网页,这个请求中是不带referer的.
但是如果你是点击了某个网页的内容,产生了跳转,就是带referer的.
如果我是广告主,我在搜狗上投放广告,搜狗是点击计费的(CPC).一个广告,一段时间之内被点击多少次?
这个事情谁来统计?正解是双方各统计各的,如果数字能对上,就可以计费了.
搜狗若是想统计,就会先给搜狗的一个billsever服务器发起一个请求.这个啊服务器就会记录一个日志(什么时候,哪个用户,电脑了哪个广告,这次广告的费用是多少?.....)这个日志统计就知道了.
广告主也有自己的服务器,我们跳转到广告主的网站,自然服务器就收到请求了.广告主自己也可以统计.
这个就有个问题,广告主可以在多个平台来投放广告.此时就要区分出,这个点击是来自哪个平台的,此时就需要通过referer做出区分.
Referer这个东西,是明文传输的.那么时候否有人会把这个referer给你偷偷改了???
在2014年是一个相当普遍的现象!!!
谁在修改??运营商!!!(电信,联通,移动)
1.是否有能力??
我们访问网站都是通过运营商的设备(路由器/交换机)进行转发的.
2.是否有动机??
运营商也是有自己的广告平台.本来这次请求是搜狗给广告主带来的.结果referer被修改了之后,在广告主看起来就是来自运营商的了!!!就会提高运营商的营收!!!
这种行为是违法行为!
我们称之为"运营商劫持"
除了法律武器之外,我们也要通过技术手段进行反制
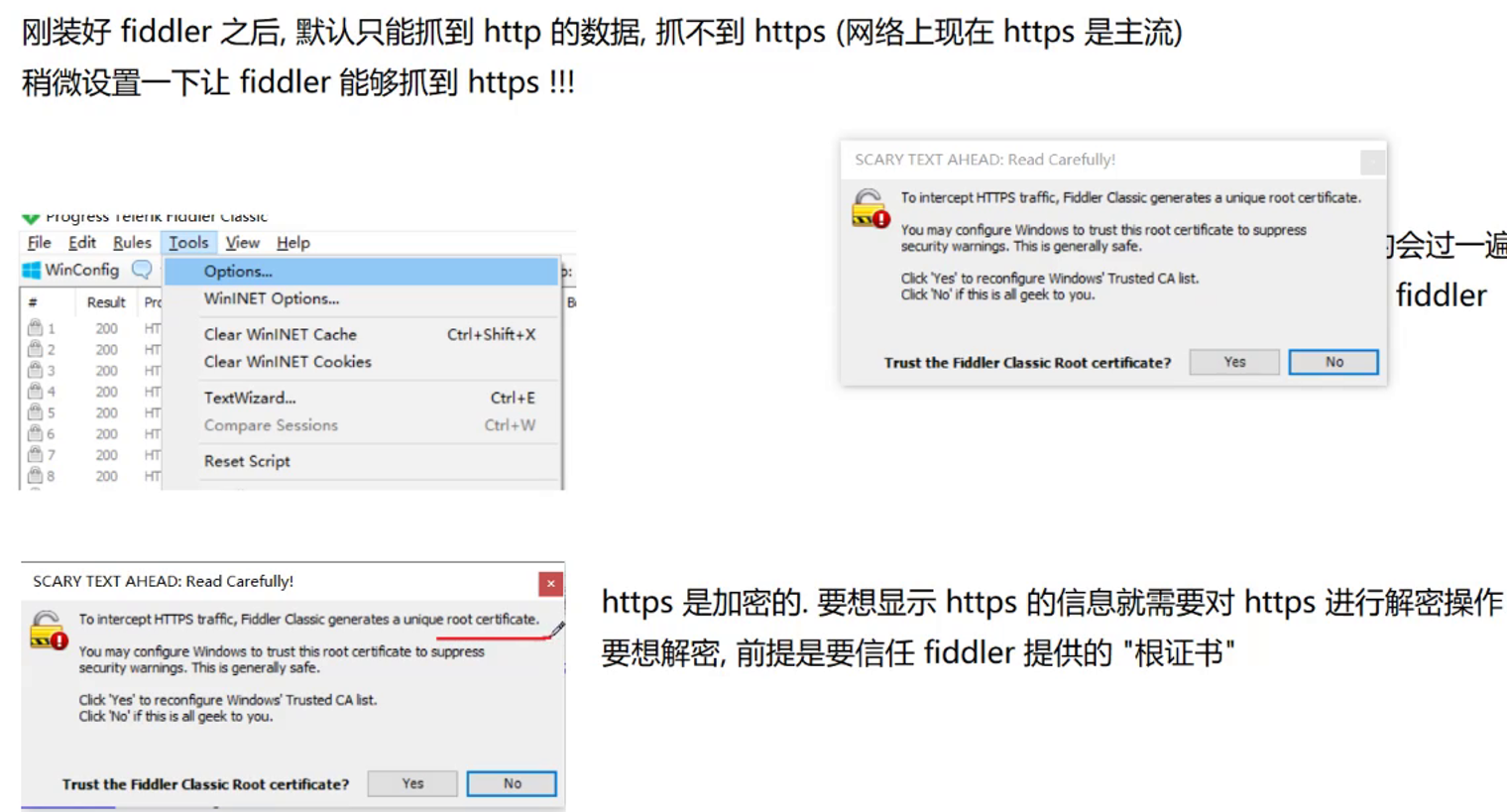
HTTPS
使用HTTPS进行加密传输,这个时候情况就不一样了
现在的网站都是HTTPS就是从2014年左右开始推进的
Cookie
是浏览器本地存储数据的一种机制!!
在浏览器访问服务器之前,此时你的啊浏览器对于这个服务器是一无所知的!你的浏览器上是没有人格这个服务器相关数据的.
当你的浏览器与服务器之间进行一个交互之后,服务器就会返回很多数据(html,css,js,json,图片...)
浏览器拿到这些数据之后就可以展示网页了.
由于此同时,用户拿着网页操作的过程中,也会产生许多"临时性"的数据.像临时数据,有的可以放到服务器这边存储(下次就可以直接获取到了)有的不太重要,就直接放到浏览器这边存储(下次访问也可以直接用,换台电脑就可能没了)
浏览器要保存数据,为什么要放到cookie当中?直接方法哦硬盘,写一个文件不行吗?
这个是不行的!如果让网页能够轻易地访问你的文件系统,这个是非常危险的!
为了保证安全,浏览器会对网页的功能做出限制(禁止直接访问硬盘,就是其中的一个规则)
为了保证安全,同时又能存储数据,浏览器就提供了cookie功能(后来又有了其他功能)
cookie是按照键值对的方式来存储一些字符串的.这些键值对往往都是服务器返回回来的.浏览器把这些键值对按照"域名"维度,分类存储.不同的网站,cookie是独立的.这些cookie内容,都是程序员自定义的.
一个网站cookie中会存储很多键值对,但是往往会有一个很重要的键值对,是用来表示用户的"身份信息"的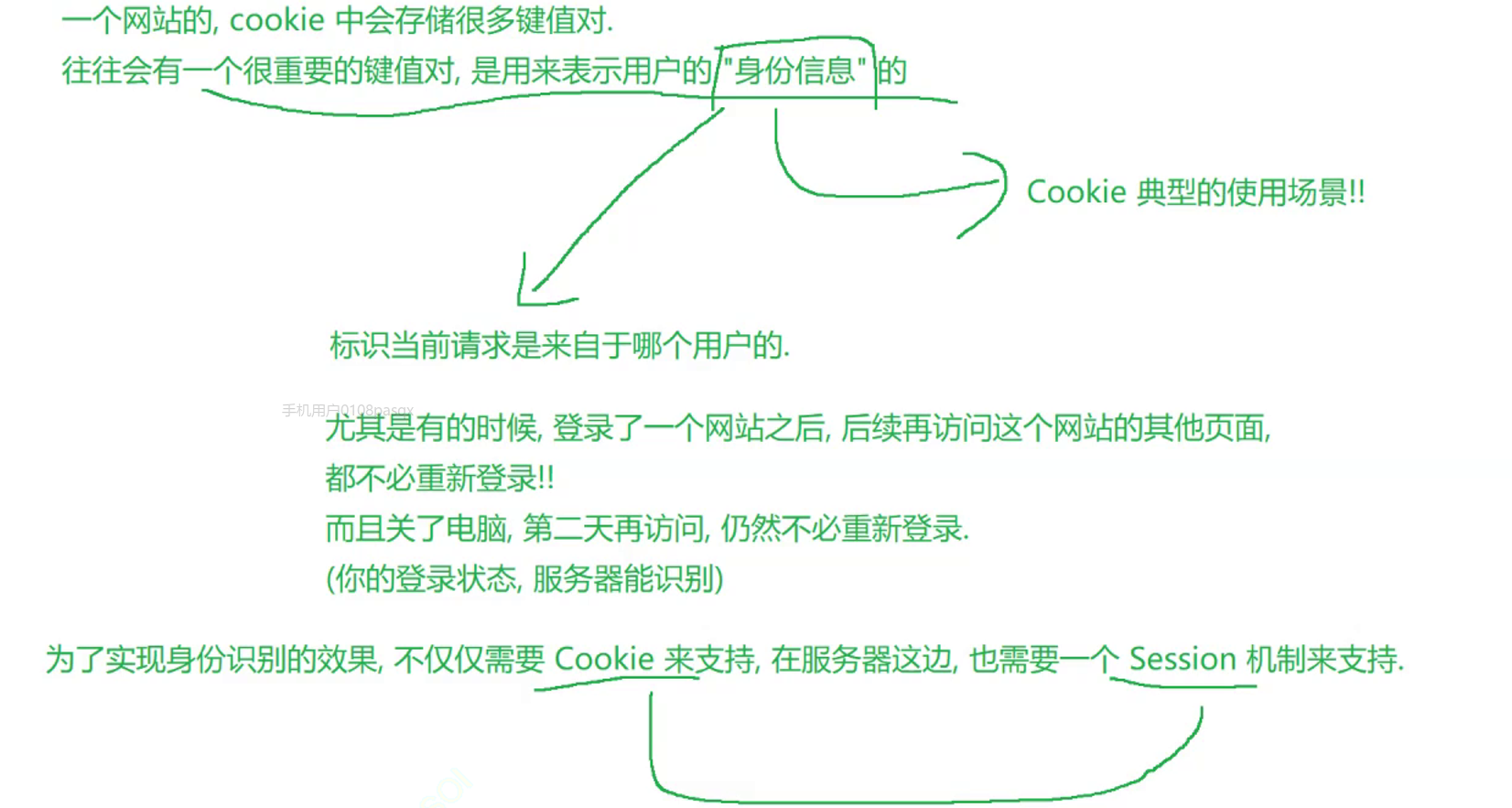

总结:
1.cookie从哪里来?
cookie是从服务器返回给浏览器的
2.cookie保存在哪里?
cookie保存在浏览器上,浏览器所在的电脑的硬盘上.每个域名都有自己的一组cookie
3.cookie里的内容是什么?
cookie中的内容是键值对结构的数据.这里的键值对都是程序员自定义的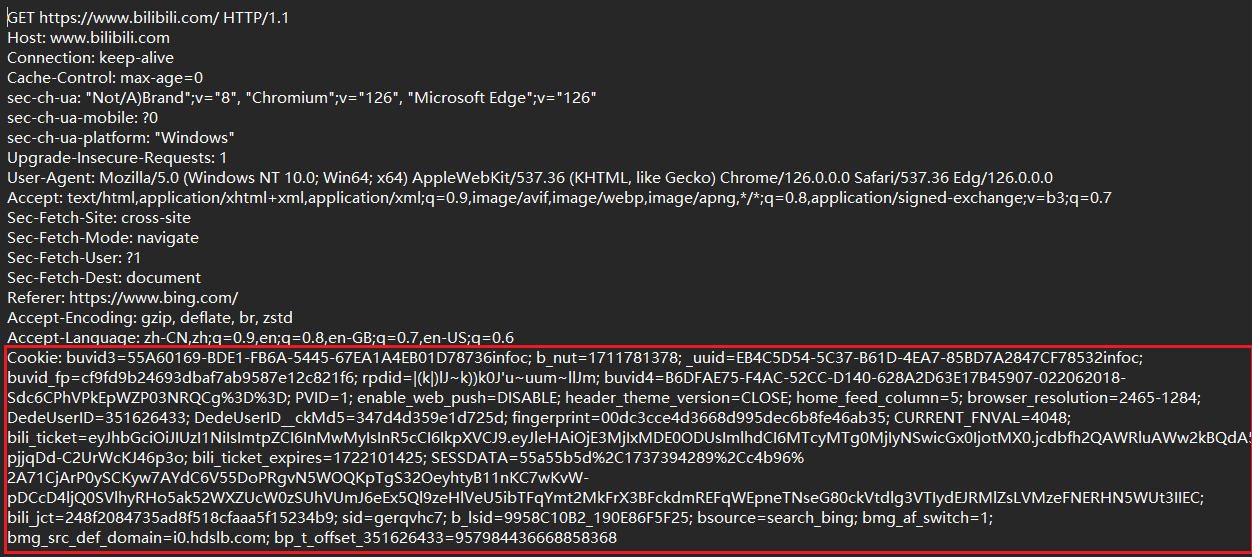
这是我登录B站后B站的cookie
其中往往会有一个键值对,作为用户的身份标识,当然不同网站的 key 和 value 都不一样
4.cookie内容都到哪里去?
后续再访问这个网站中的页面,就都会在请求中带上cookie.服务器就可以进一步的知道客户端的详细情况了.
如果你的cookie被别人获取了,别人可以冒充你的身份,但是不能知道你的账号密码
因此,对于身份标识这一块,一些安全性比较高的网站(支付宝/网银...)往往会做出更严格的限制.(比如会缩短cookie的有效时间),比如,如果我五分钟之内,不进行任何操作,cookie就失效了.想要操作就得重新登录.
因此,支付宝/网银,都是两个密码,有登录密码,也有支付密码.
HTTP响应

状态码,就是对这次响应的定性.(成功,失败,其他情况)
200 表示成功!!
计算机中通常会使用"数字"表示结果.使用不同的数字表示不同的失败原因.
404 Not Found
你要访问的资源不存在
403 Forbidden
没有权限访问
502 Bad Gateway
服务器挂了
504 Gateway Timeout
服务器响应超时了
302 Move temporarily
重定向,跳转到其他页面上
HTML
在这里我们使用VSCode进行书写代码,VSCode对于前端代码的支持是天然的.
使用!+Tab就能生成HTML的代码片段.这是HTML的起手式
HTML特点
1.由标签构成,标签可以成对出现,也可以单独出现
2.标签可以嵌套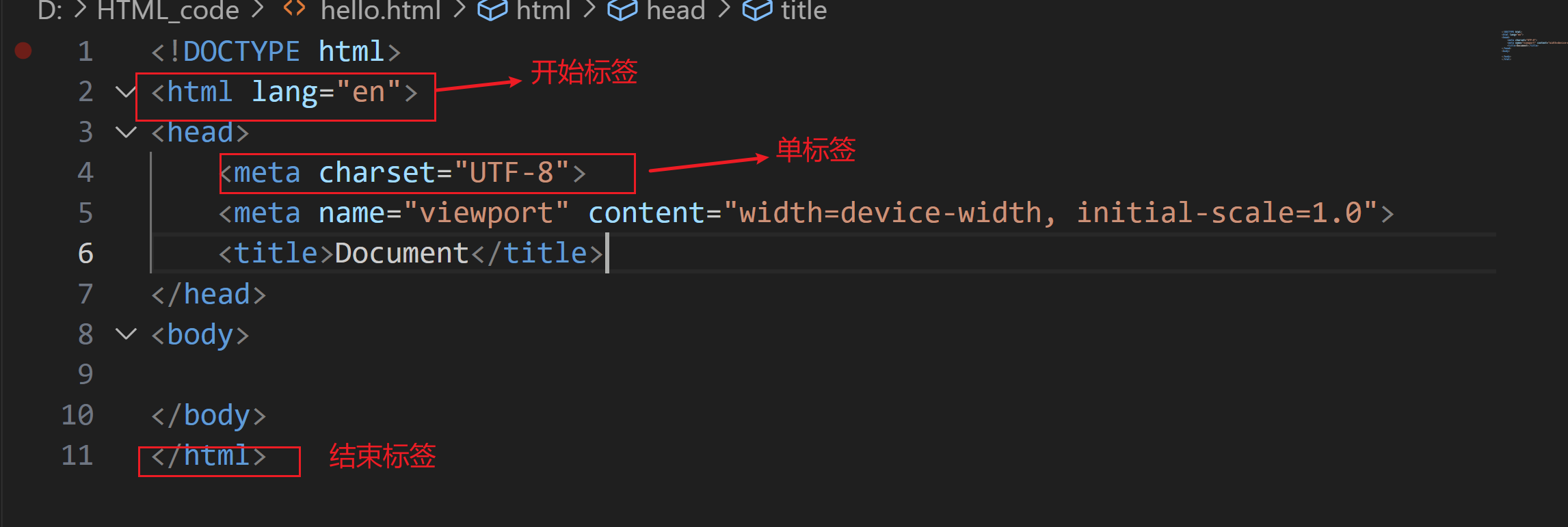
其中
标签包含了页面的属性,不会显示在页面上.
其中
中的内容是会显示在页面上的
通过HTML中的form标签(表单)构造http请求
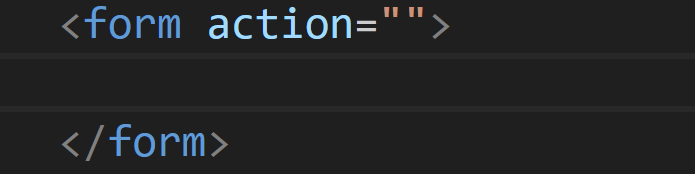
对于开始标签来说,可以写一些"属性"(键值对),action属性,描述了构造http请求的URL是什么

input标签在HTML中变化多端,有多种形态.就是通过type属性来控制的.其中text这个类型,就是一个最简单的单行输入框.name属性会被作为参数,被放到http请求的query string / body 中.那不管是query string 还是 body,都是键值对,name属性中的aaa就是键值对的健.用户在输入框中输入的内容就是键值对的值.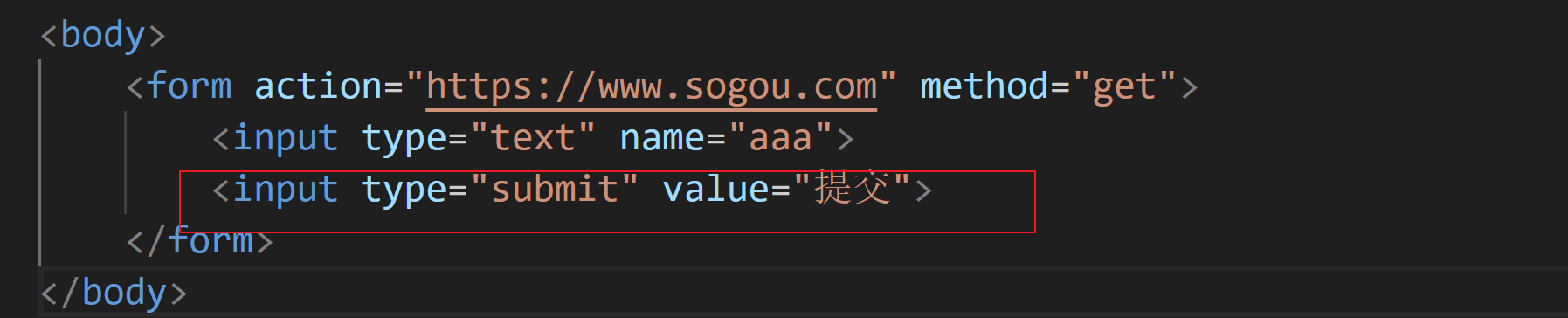
构造出一个"提交按钮",value就是按钮的文本内容
随后用fiddler进行抓包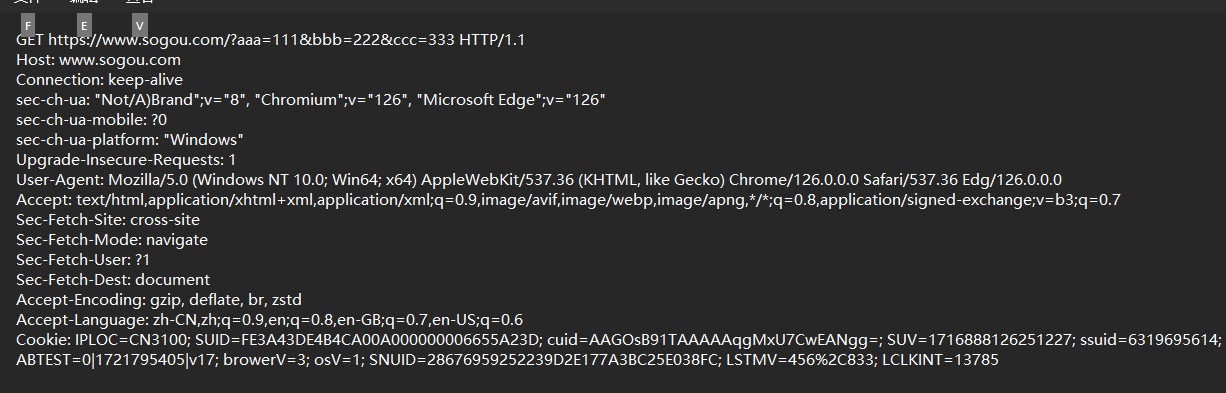
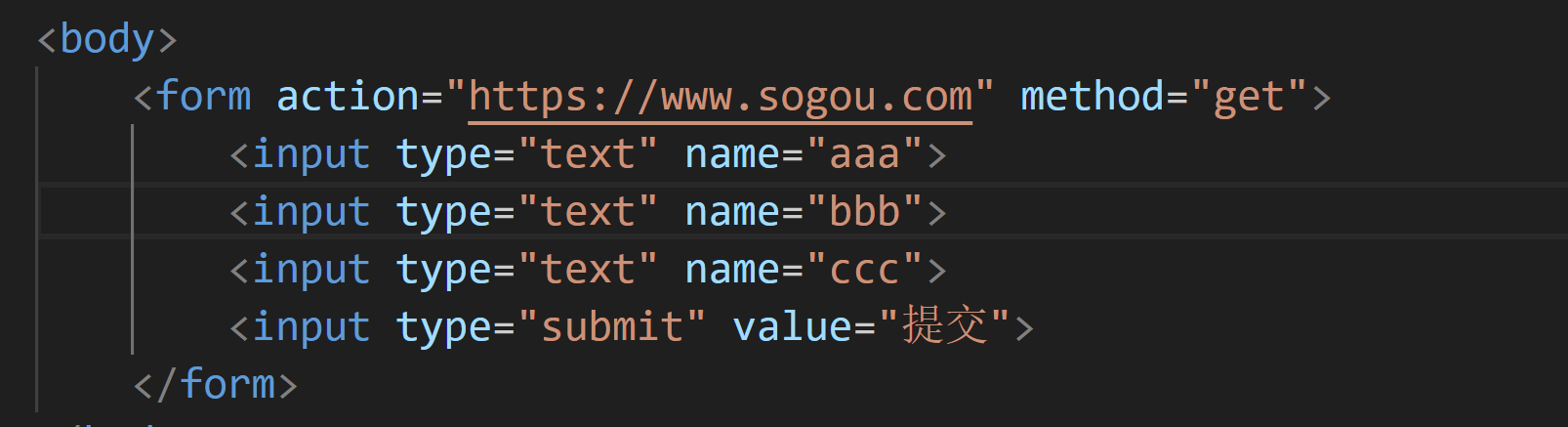

对应关系如下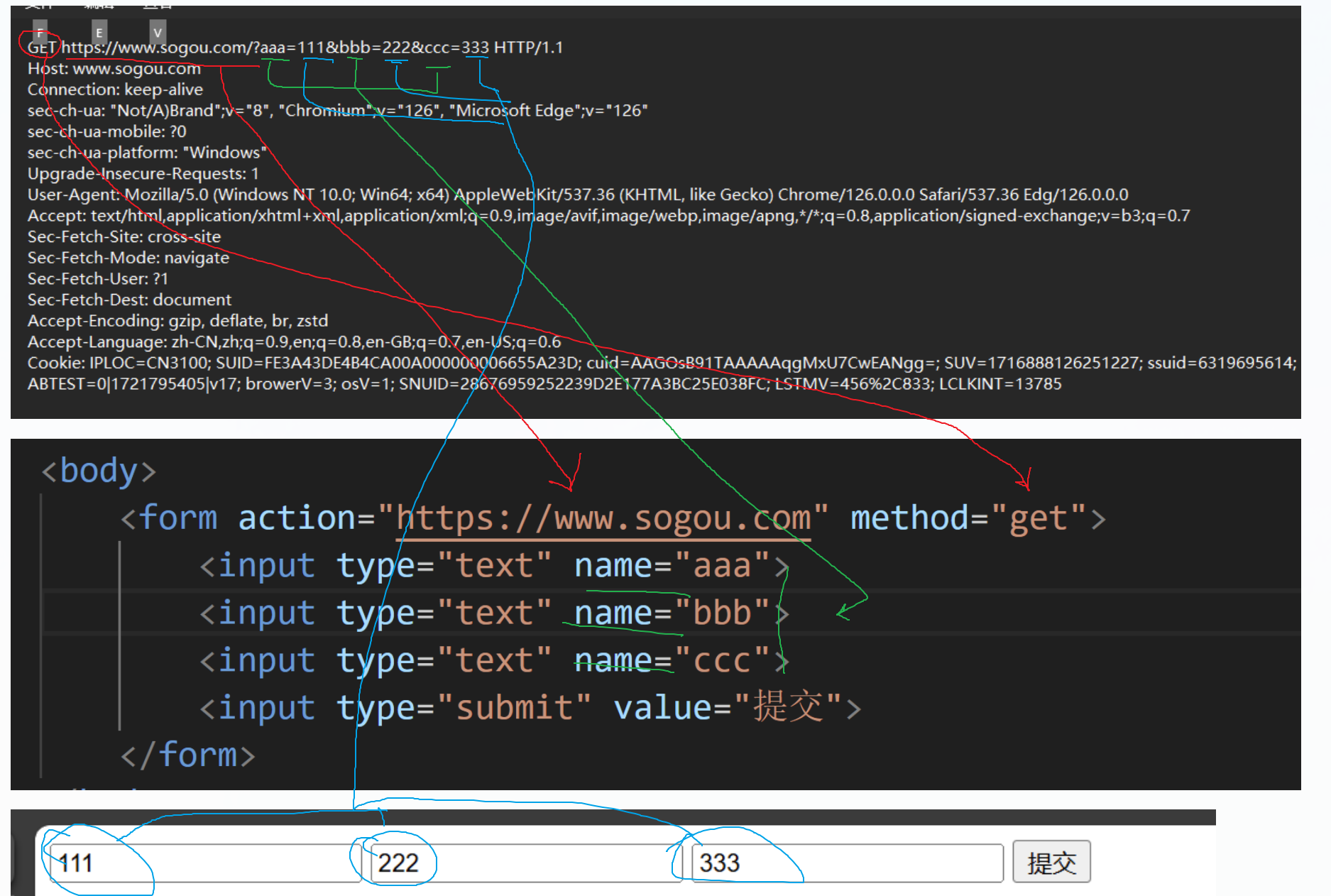

这其实就是一个form表单
当然了,登录操作大多使用post来做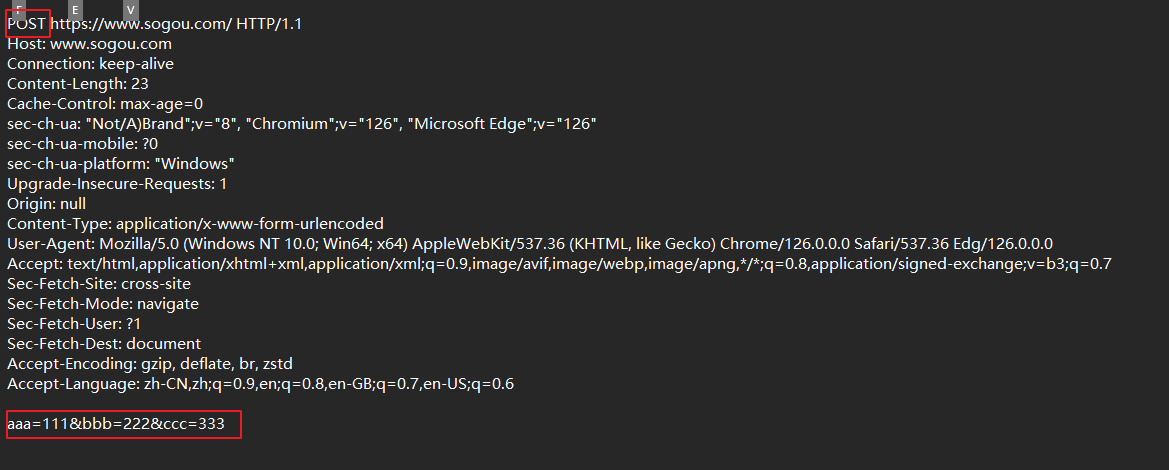
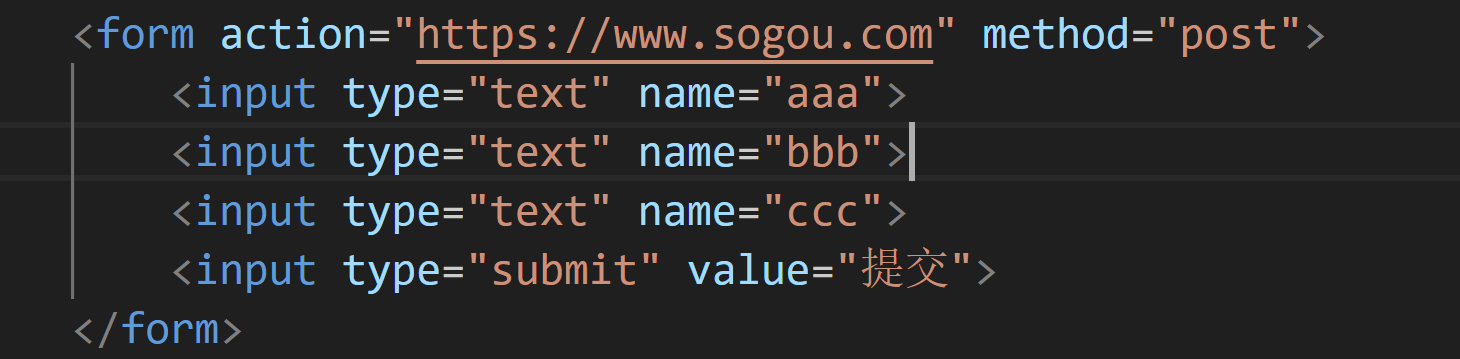
form表单只能支持post和get.
现在更常用使用ajax的方式来构造http请求.
Ajax是一种异步的通信方式.通过代码发出了http请求,请求发出去之后,js代码就继续向下执行了.当服务器的响应回来了之后,就会自动的通知到咱们的代码中,进一步就能处理响应了.
Ajax是js提供的一组api,但是js原生的Ajax api不好用.(用起来不方便)js世界中,有一个非常知名的第三方库,jQuery
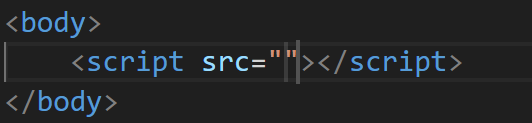
这个标签中会放js代码.src属性就可以从网络上加载一个js代码过来.
在js中是一个合法的变量名.就和abc,count,i之类的是一样的,这个变量是在jQuery中已经定义好了.
这个对象里就有很多方法,就可以通过.的形式来调用对应的方法.
$.ajax就是jQuery中封装好的,用来发起Ajax请求的方法.
Ajax的参数使用{}来表示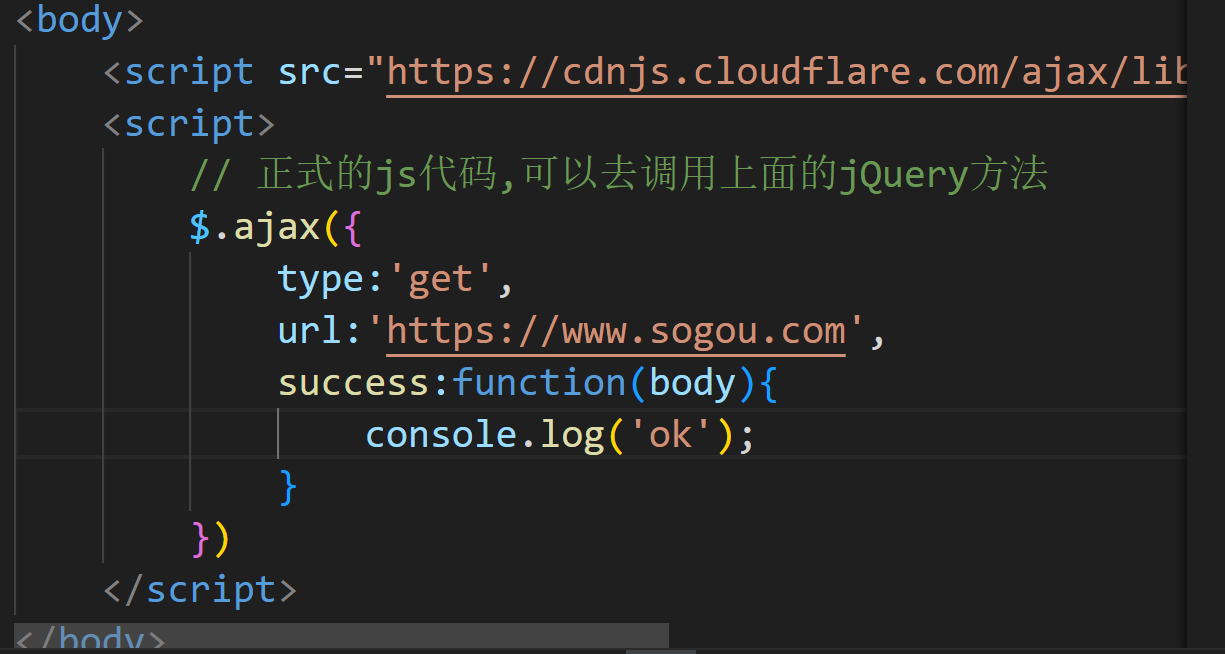
js中,{}表示的是js的对象.(键值对)
{}里可以有多个键值对,
键值对之间使用 , 分割.
键和值之间使用 : 分割
健固定都是string类型,可以写 ' 也可以写 " 也可以不写.
值的话,可以是数字,也可以是字符创,也可以是数组,还可以是对象...
注意:
这里的type不仅支持get和post,也支持各种其他的方法
url:就是网络地址
success:服务器返回响应,咱们要怎么处理?success的值是一个函数.这个函数就会在收到相应的时候,被浏览器自动调用.被浏览器自动调用这个函数的时候,就会把响应的body,通过参数,传给这个函数.
这里的body也不是必要的,看你用不用这个响应body.正常来说是需要用的.
此处所谓的"异步"
js代码在执行Ajax方法的时候,把请求发出去之后,就会立即往下执行.这个时候还没有调用到success对应的方法呢.一直到响应回来,success才会被调用.也就是我们说的"回调函数".
post的写法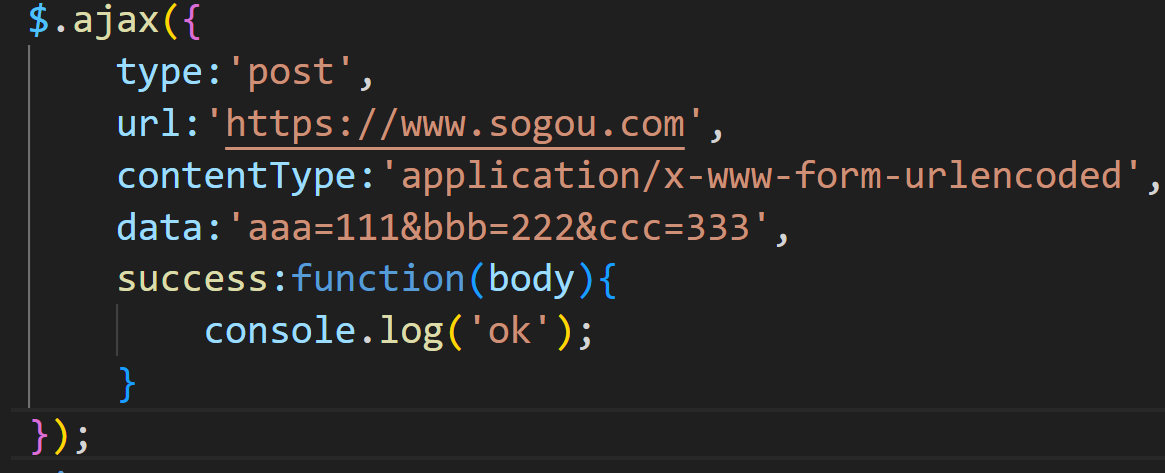
这一段代码就会在页面加载的时候被执行到.
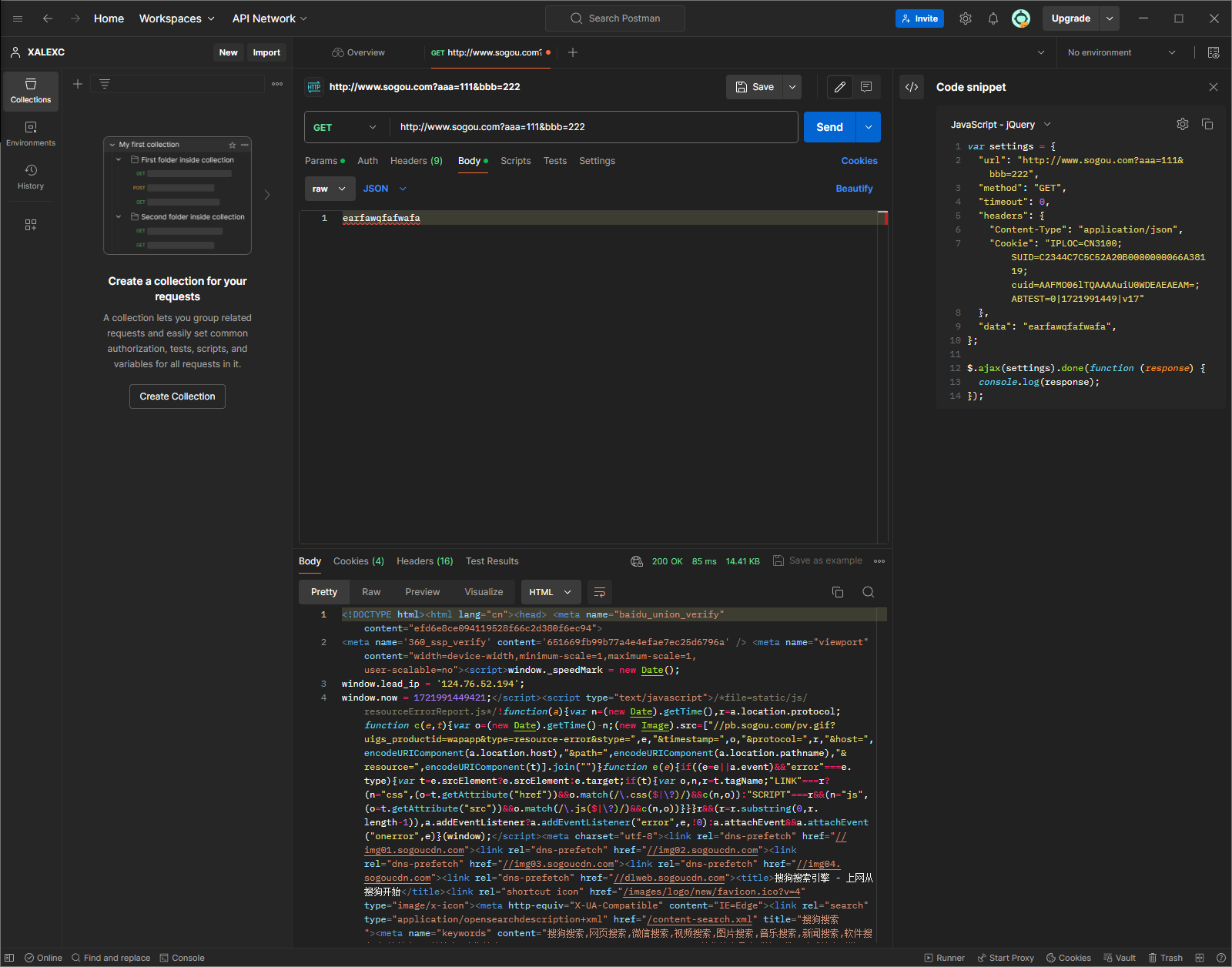
除了上面的方式之外,还可以通过第三方工具构造HTTP请求.
postman