1、概述
前面我们学习了并发包中的一些核心的基础类,包括原子类、Lock 、以及线程间通信的一些工具类,相信你已经能够正确的处理线程同步的问题了,今天我们继续学习并发包下的工具类,我们本次主要学习线程池和异步计算框架相关的内容
2、线程池
2.1、Executor 接口
我们继续看并发包中的内容,里面有个 Executor 接口,他的源码如下
java
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}有且仅有一个方法 入参是一个 Runnable 接口,根据描述信息,他是如何工作的取决于他的具体实现类 。他还有一个子接口 ExecutorService**,**这个子接口在原来的基础上扩展了一些方法,通常下 我们使用 ThreadPoolExecutor 这个实现类。
2.2、ThreadPoolExecutor
关于ThreadPoolExecutor 前几年有个烂大街的面试问题,线程池的7大核心参数不知道大家还有没有印象,很显然 这道题很low,看过源码注释的都知道。他的构造器(参数最全的一个)如下:
java
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}接下来我们看看他的用法,相关代码如下
java
package org.wcan.juc.excutor;
import java.util.concurrent.*;
public class ThreadPoolExecutorDemo {
public static void main(String[] args) {
/**
* @ClassName 核心线程数:4,保持核心线程存活即使闲置
* 最大线程数:4,线程池允许的最大线程数
* 空闲超时时长:60秒,非核心线程闲置超时后会被回收
* 时间单位:秒,指定超时时间的单位
* 任务队列:无界LinkedBlockingQueue,用于暂存待执行任务
* 线程工厂:默认工厂,生成基础线程名称的线程
* 拒绝策略:CallerRunsPolicy,任务被提交者线程直接执行
* @Description TODO
* @Author wcan
* @Date 2025/3/30 下午 17:07
* @Version 1.0
*/
ThreadPoolExecutor executor = new ThreadPoolExecutor(
4,
4,
60,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy()
);
// 提交任务到线程池
for (int i = 0; i < 10; i++) {
int taskId = i + 1;
executor.submit(() -> {
try {
// 模拟任务的处理
System.out.println("任务 " + taskId + " 正在执行,线程ID:" + Thread.currentThread().getName());
Thread.sleep(2000); // 模拟耗时任务
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 关闭线程池
executor.shutdown();
}
}有没有发先这样创建线程池很麻烦,需要配置7个参数。下面我们来看看一个线程池的工具类
2.3、Executors
Executors 类封装了一些和线程池操作有关的方法,我们可以直接使用它来创建线程池,下面我们来看看里面都有哪些方法
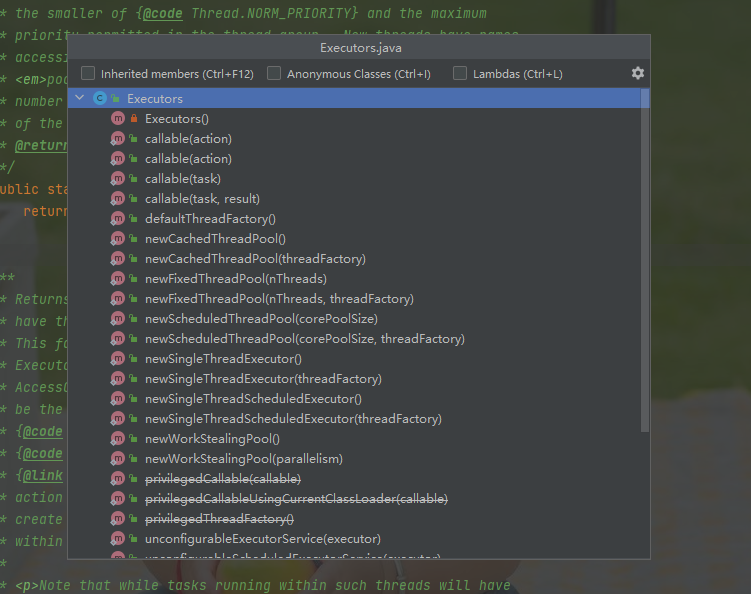
我们可以使用 newFixedThreadPool 这个方法 传入一个核心线程数的参数来创建一个线程池,同样的还有支持周期执行的线程池、以及单线程池。每种线程池的创建我都编写了一个案例,相关代码如下:
java
package org.wcan.juc.excutor;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
/**
* @Description
* @Author wcan
* @Date 2025/3/30 下午 19:56
* @Version 1.0
*/
public class ExecutorsDemo {
public static void main(String[] args) {
// newFixedThreadPool();
// newCachedThreadPool();
// newScheduledThreadPool();
// newSingleThreadExecutor();
}
/**
* @Description 创建一个支持定时任务的线程池,可以用于延时或周期性任务。
* @Author wcan
* @Date 2025/3/30 下午 20:07
* @Version 1.0
*/
private static void newScheduledThreadPool() {
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
for (int i = 0; i < 10; i++) {
executor.schedule(() -> {
System.out.println("Task executed after 1 second delay");
}, 15, TimeUnit.SECONDS);
}
executor.shutdown();
}
/**
* @Description 创建一个单线程的线程池,所有任务按提交顺序执行,且始终由一个线程执行。
* @Author wcan
* @Date 2025/3/30 下午 20:07
* @Version 1.0
*/
private static void newSingleThreadExecutor() {
ExecutorService executor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
executor.submit(() -> {
System.out.println("Task executed by thread " + Thread.currentThread().getName());
});
}
executor.shutdown();
}
/**
* @Description 创建一个可缓存的线程池,线程池中的线程数会根据需要自动增加,空闲的线程会在 60 秒后被回收。
* @Author wcan
* @Date 2025/3/30 下午 20:07
* @Version 1.0
*/
private static void newCachedThreadPool() {
ExecutorService executor = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
executor.submit(() -> {
System.out.println("Task executed by thread " + Thread.currentThread().getName());
});
}
executor.shutdown();
}
/**
* @Description 创建一个固定大小的线程池,所有提交的任务都会由固定数量的线程处理。如果任务数超过线程池的大小,任务将会被放入队列中等待执行。
* @Author wcan
* @Date 2025/3/30 下午 20:07
* @Version 1.0
*/
private static void newFixedThreadPool() {
ExecutorService executor = Executors.newFixedThreadPool(2);
for (int i = 0; i < 10; i++) {
executor.submit(() -> System.out.println("Task executed by " + Thread.currentThread().getName()));
}
executor.shutdown();
}
}2.4、线程池的比对
前面我们了解到了 五种常用的线程池,我将他们的特点以及应用场景都整理成了一张表格,如下所示
| 线程池类型 | 应用场景 | 特点 | 适用情况 |
|---|---|---|---|
| FixedThreadPool | 适用于任务数量固定且处理时间差不多的场景。常见的应用场景如处理固定数量的并发任务、数据库连接池、IO密集型任务等。 | 1、固定线程池大小。2、 如果线程数已满,新的任务会被放入队列中,直到有线程可用。 | 1、任务数量大致固定且相对均匀时。2、 任务执行时间大致相等。 |
| CachedThreadPool | 适用于任务数不确定且任务执行时间较短的场景。可以用于实时请求处理、缓存池、任务临时生成等场景,适合处理短时并发任务。 | 1、线程池大小会根据需求自动调整,空闲线程会被回收。 2、适用于处理大量短期任务。 | 1、任务数量变化大且任务较短时。 2、 需要频繁创建销毁线程的场景。 |
| SingleThreadExecutor | 适用于任务需要按顺序执行的场景,如日志处理、消息处理队列、任务调度等,确保任务按顺序依次执行。 | 1、只有一个线程,所有任务按顺序执行。2、如果一个任务执行失败,后续任务不会执行。 | 1、任务必须按顺序执行,且保证不同时有多个线程运行。 2、任务之间有依赖关系时。 |
| ScheduledThreadPool | 适用于定时任务、周期性任务、延迟执行等场景。如定时调度任务、定期清理任务、任务重试机制等。 | 1、 支持定时任务和周期性任务。 2、可以灵活调度任务的执行时间。 | 1、需要定时、延时或周期性执行任务。 2、不需要立即执行的场景。 |
| ThreadPoolExecutor | 适用于需要高度定制化的线程池,适合任务量大且线程池需要精细控制的场景,如复杂的并发任务、高并发的服务器应用、支持不同拒绝策略的复杂任务处理等。 | 1、可自定义核心线程池大小、最大线程池大小、线程空闲时间等。2、支持队列类型、拒绝策略等灵活配置。 | 1、 需要精细化控制线程池参数的场景。 2、 高并发、大量任务时。 3、任务执行时间差异较大时。 |
3、Future
Future接口也是并发包中很重要的一个接口之一,主要用于异步编程,是一个顶层接口
3.1、Future 详解
我们点开Future 的源码,可以看到里面只有5个方法,
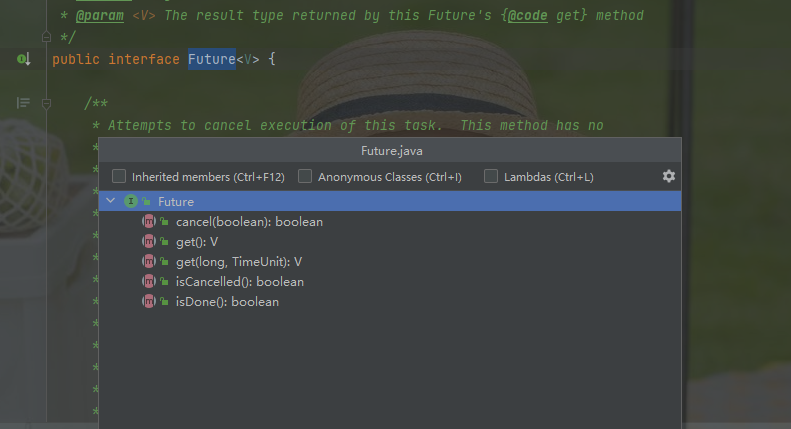
下面我整理了一份表格,总结了上述5个方法的作用
| 方法名 | 描述 | 返回值 | 异常 |
|---|---|---|---|
V get() |
阻塞当前线程,直到任务执行完成,获取结果。 | 任务的执行结果(类型 V) |
InterruptedException、ExecutionException |
V get(long timeout, TimeUnit unit) |
阻塞当前线程,直到任务执行完成,或超时。 | 任务的执行结果(类型 V) |
InterruptedException、ExecutionException、TimeoutException |
boolean cancel(boolean mayInterruptIfRunning) |
尝试取消任务的执行。如果任务正在执行且 mayInterruptIfRunning 为 true,则会中断任务。 |
true(任务成功取消)或 false(任务无法取消) |
无 |
boolean isCancelled() |
检查任务是否已取消。 | true(任务已取消)或 false(任务未取消) |
无 |
boolean isDone() |
检查任务是否已完成(无论是正常完成、异常完成,还是被取消)。 | true(任务已完成)或 false(任务未完成) |
无 |
3.2、FutureTask 详解
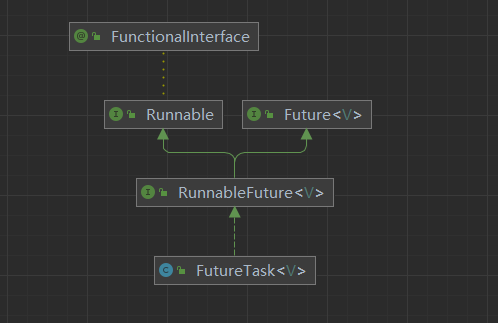
我们都知道 Runnable接口中只有一个 run 方法,主要用于定义要执行的任务,并且是没有返回值的,而 Future 接口主要是提供了, 在任务执行完毕后获取结果,或者取消任务,或者检查任务是否完成的能力。 我们可以在并发包中看到 有个接口 RunnableFuture 。分别继承了他们两。
java
package java.util.concurrent;
/**
* A {@link Future} that is {@link Runnable}. Successful execution of
* the {@code run} method causes completion of the {@code Future}
* and allows access to its results.
* @see FutureTask
* @see Executor
* @since 1.6
* @author Doug Lea
* @param <V> The result type returned by this Future's {@code get} method
*/
public interface RunnableFuture<V> extends Runnable, Future<V> {
/**
* Sets this Future to the result of its computation
* unless it has been cancelled.
*/
void run();
}可能你看着总感觉不太对的样子, Runnable 接口中的方法是没有返回值的,那 Future 获取的结果又是从哪里来的呢。别慌,我们继续看实现,RunnableFuture 接口 有很多实现类,其中有个叫FutureTask,我们就从他开始吧
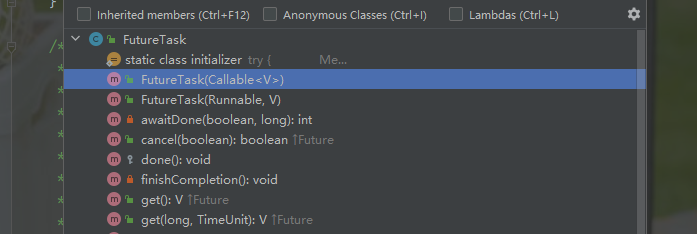
3.3、FurureTask 的使用
FurureTask 主要有两个构造器,分为有返回参数和没有返回参数
下面我给出这两种类型的基本用法,相关代码如下:
java
package org.wcan.juc.excutor;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class FutureTaskExample {
public static void main(String[] args) throws Exception {
//无返回值
runnableTask();
//有返回值
callableTask();
}
private static void runnableTask() throws InterruptedException {
// 创建 Runnable 任务
Runnable task = () -> {
System.out.println("Task is running...");
};
// 创建 FutureTask
FutureTask<Void> futureTask = new FutureTask<>(task, null);
// 使用 Thread 执行任务
Thread thread = new Thread(futureTask);
thread.start();
// 等待任务完成
futureTask.get(); // 阻塞直到任务执行完毕
System.out.println("Task has completed.");
}
private static void callableTask() throws InterruptedException, ExecutionException {
// 创建 Callable 任务
Callable<Integer> task = () -> {
System.out.println("Task is running...");
return 10 + 20;
};
// 创建 FutureTask
FutureTask<Integer> futureTask = new FutureTask<>(task);
// 使用 Thread 执行任务
Thread thread = new Thread(futureTask);
thread.start();
// 获取任务结果
Integer result = futureTask.get(); // 会阻塞直到任务执行完毕
System.out.println("Task result: " + result);
}
}需要注意的是 FutureTask 还可以提交到线程池执行,代码案例如下
java
private static void executorService() throws InterruptedException, ExecutionException {
ExecutorService executor = Executors.newFixedThreadPool(1);
// 创建 Callable 任务
Callable<Integer> task = () -> {
System.out.println("Task is running...");
return 10 + 20;
};
// 创建 FutureTask
FutureTask<Integer> futureTask = new FutureTask<>(task);
// 提交任务给线程池
executor.submit(futureTask);
// 获取任务结果
Integer result = futureTask.get(); // 阻塞直到任务执行完毕
System.out.println("Task result: " + result);
executor.shutdown(); // 关闭线程池
}4、CompletableFuture
4.1、异步执行任务
CompletableFuture 是在Java8之后新加入的一个异步编程工具,主要的目的是简化多任务编排和异步任务处理,他可以组合多个异步任务、支持链式调用,还具备灵活的异常处理机制。
我们先来上段代码看看效果
java
package org.wcan.juc.excutor;
import java.util.concurrent.*;
/**
* @Description
* @Author wcan
* @Date 2025/3/31 下午 15:21
* @Version 1.0
*/
public class CompletableFutureDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(2);
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
System.out.println(Thread.currentThread().getName());
// 异步执行的逻辑(返回值)
return "Hello";
},executorService).thenApply(s -> {
System.out.println(Thread.currentThread().getName());
return s + " World";
});
String s = future.get();
System.out.println(s);
executorService.shutdown();
}
}上述代码的运行结果是
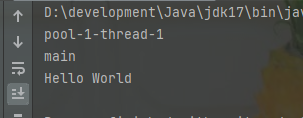
4.2、异步获取结果
CompletableFuture 主要有两个异步执行的方法
|-------------|----------|
| 方法名 | 返回值 |
| runAsync | 异步执行无返回值 |
| supplyAsync | 异步执行有返回值 |
| get | 阻塞获取结果 |
前面的案例我们使用了 有返回值的 supplyAsync 方法 ,但是我们使用了 get 方法去获取结果的话 会造成阻塞,get方法会阻塞直到任务完成,获取结果。于此对应的还有一种非阻塞的办法,传入一个回调函数,比如下面这段代码
java
package org.wcan.juc.excutor;
import java.util.concurrent.*;
/**
* @Description
* @Author wcan
* @Date 2025/3/31 下午 15:21
* @Version 1.0
*/
public class CompletableFutureDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newFixedThreadPool(2);
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
System.out.println(Thread.currentThread().getName());
// 异步执行的逻辑(返回值)
return "Hello";
},executorService).thenApply(s -> {
System.out.println(Thread.currentThread().getName());
return s + " World";
});
future.thenAccept(s -> {
System.out.println(Thread.currentThread().getName());
System.out.println(s);
});
// String s = future.get();
// System.out.println(s);
executorService.shutdown();
}
}我们通过 thenAccept 方法 传入一个回调方法,就可以实现异步获取执行结果的功能了。
4.3、组合多个异步任务
CompletableFuture 还有一个强大的功能就是可以组合多个异步任务,我们先看代码
java
private static void combine() throws ExecutionException, InterruptedException {
CompletableFuture<String> futureA = CompletableFuture.supplyAsync(() -> {
System.out.println(Thread.currentThread().getName());
return "Hello";
});
CompletableFuture<String> futureB = CompletableFuture.supplyAsync(() -> {
System.out.println(Thread.currentThread().getName());
return "World";
});
// thenCombine 合并两个CompletableFuture
CompletableFuture<String> resultFuture = futureA.thenCombine(futureB, (a, b) -> {
System.out.println(Thread.currentThread().getName());
return a + " " + b;
});
resultFuture.thenAccept(s -> {
System.out.println(Thread.currentThread().getName());
System.out.println(s);
});
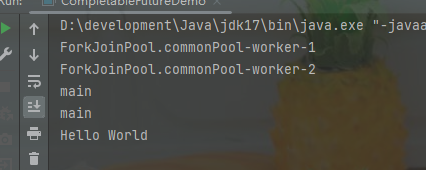
}上述代码会将两个异步任务并行执行,然后通过 thenCombine方法合并两次的运行结果。运行结果如下图示:
4.4、异常处理机制
下面我们来看下异常处理机制,CompletableFuture 提供了 exceptionally 方法 用来捕获异步任务执行过程中的异常信息,相关代码如下:
java
private static void exceptionally() throws ExecutionException, InterruptedException {
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
if (true) throw new RuntimeException("出错了!");
return 42;
}).exceptionally(ex -> {
System.out.println("捕获异常: " + ex.getMessage());
return 0;
});
}5、ForkJoin 框架
5.1、ForkJoin 设计思想
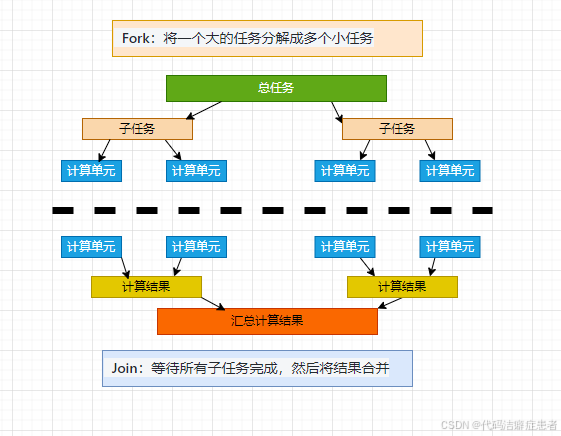
在Java 并发包中,还有一个强大的工具 -- ForkJoin,故名思意 这个工具设计思想就是 Fork 和 Join 两个步骤,效果上 就如同 一个建议版本的MapReduce 。它的工作原理如下图所示
5.2、ForkJoin 的基本使用
前面我们知道了ForkJoin 的设计原理,下面我们就来看看怎么用,我们可以在并发包下看到有个ForkJoinTask 的 抽象类 ,
既然是抽象的,那么我们继续寻找子类。 我们主要关注其中有两个子类 :
RecursiveTask:返回一个结果的任务(通常用于有返回值的计算)。RecursiveAction:没有返回值的任务。
需要注意的是这两个子类都是抽象类,所以我们在使用的时候需要重写抽象类中的抽象方法
5.3、案例实战
假设我们需要对一个长度是10000000的数组求和,这个时候我们就可以使用 ForkJoin 去并行计算了,因为需要返回值,所以我们选择继承 RecursiveTask。 实现代码如下
java
package org.wcan.juc.excutor;
import java.util.concurrent.RecursiveTask;
public class SumTask extends RecursiveTask<Long> {
public static final int INT = 10000;
private final long[] arr;
private final int start, end;
// 构造函数接收数组和任务的起始、结束索引
public SumTask(long[] arr, int start, int end) {
this.arr = arr;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 如果任务的大小小于或等于 INT,直接计算结果
if (end - start <= INT) {
long sum = 0;
for (int i = start; i < end; i++) {
sum += arr[i];
}
return sum;
} else {
// 否则分割任务
int mid = (start + end) / 2;
SumTask leftTask = new SumTask(arr, start, mid);
SumTask rightTask = new SumTask(arr, mid, end);
// fork任务
leftTask.fork();
rightTask.fork();
// 等待任务完成并合并结果
long leftResult = leftTask.join();
long rightResult = rightTask.join();
return leftResult + rightResult; // 合并结果
}
}
}上面是一个标准的写法,通过递归的形式进行任务分解,当达到最小计算单元的阈值的时候 开始计算,所有的子任务计算完成后,进行结果汇总。测试类如下
java
package org.wcan.juc.excutor;
import java.util.Arrays;
import java.util.concurrent.ForkJoinPool;
public class ForkJoinDemo {
public static void main(String[] args) {
long[] array = new long[100_000_000];
Arrays.fill(array, 9); //数组元素全为9
// 创建 ForkJoin 线程池
ForkJoinPool pool = new ForkJoinPool();
SumTask task = new SumTask(array, 0, array.length);
// 提交任务并获取结果
Long sum = pool.invoke(task);
System.out.println("总和: " + sum);
}
}我们运行上述代码就能获取到计算结果了,我们可以继续做个实验,证明一下这种处理方式效率高。
java
public static void main(String[] args) {
long[] array = new long[100_000_000];
Arrays.fill(array, 9); // 数组元素全为1
long start = System.currentTimeMillis();
Long sum = 0L;
for (int i = 0; i < array.length; i++) {
sum += array[i];
}
System.out.println("总和: " + sum); // 输出 10000
System.out.println("耗时: " + (System.currentTimeMillis() - start));
}运行上述代码,观察控制台输出内容:
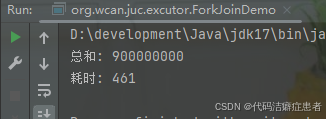
我们使用循环计算耗时 461毫秒,我们再统计下使用 ForkJoin 计算
java
public static void main(String[] args) {
long[] array = new long[100_000_000];
Arrays.fill(array, 9); // 数组元素全为1
long start = System.currentTimeMillis();
// 创建 ForkJoin 线程池
ForkJoinPool pool = new ForkJoinPool();
SumTask task = new SumTask(array, 0, array.length);
// 提交任务并获取结果
Long sum = pool.invoke(task);
System.out.println("总和: " + sum); // 输出 10000
System.out.println("耗时: " + (System.currentTimeMillis() - start));
}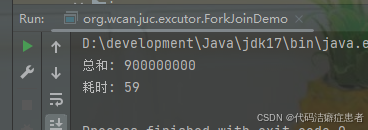
耗时 59 毫秒,完爆循环的计算效率。
5.4、最佳实践
前面我们编写了一个简单的案例,演示了 ForkJoin 的基本使用,并且和普通的循环计算做了比对,发现效率接近提升了100倍,展现了 ForkJoin强大的计算能力。那么还有没有继续优化的点呢, 答案是肯定的。
我们想想前面代码可能 存在的问题
java
SumTask leftTask = new SumTask(arr, start, mid);
SumTask rightTask = new SumTask(arr, mid, end);
// fork任务
leftTask.fork();
rightTask.fork();
// 等待任务完成并合并结果
long leftResult = leftTask.join();
long rightResult = rightTask.join();当前线程 其实做了两件事,串行提交左任务和有任务,当两个任务都提交了 在阻塞获取这两个任务的执行结果,这个过程其实是增加了两次任务调度的开销,那么我们可以怎么优化呢。
来看下面这种写法
java
int mid = (start + end) / 2;
SumPlusTask leftTask = new SumPlusTask(array, start, mid);
SumPlusTask rightTask = new SumPlusTask(array, mid, end);
// 提交左任务到队列
leftTask.fork();
// 计算右任务并合并结果
long rightResult = rightTask.compute();
long leftResult = leftTask.join();这里 当前线程在提交左任务后 直接计算有任务,这接着阻塞获取做任务的执行结果,这样是不是就能更完美的解决前面的问题了。
这里我给出完整的代码
java
package org.wcan.juc.excutor;
import java.util.concurrent.RecursiveTask;
public class SumPlusTask extends RecursiveTask<Long> {
private final long[] array;
private final int start;
private final int end;
private static final int THRESHOLD = 10000; // 拆分阈值
public SumPlusTask(long[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 如果任务足够小,直接计算
if (end - start <= THRESHOLD) {
long sum = 0;
for (int i = start; i < end; i++) sum += array[i];
return sum;
}
// 拆分任务
int mid = (start + end) / 2;
SumPlusTask leftTask = new SumPlusTask(array, start, mid);
SumPlusTask rightTask = new SumPlusTask(array, mid, end);
// 提交左任务到队列
leftTask.fork();
// 计算右任务并合并结果
long rightResult = rightTask.compute();
long leftResult = leftTask.join();
return leftResult + rightResult;
}
}同样的可以比对这两种写法,当处理的数据量在100000000 的时候 你就会感受到很明显的区别了 。
6、总结
本篇文章主要给大家介绍线程池的使用,以及异步处理任务的最佳实践,希望对大家有所帮助,后续我们将会继续给大家分享背后的实现细节以及底层原理。