字符串(String)
string 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。
string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据,比如jpg图片或者序列化的对象。
string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。
分布式ID生成器
相信大家经常会遇到需要生成唯一ID的场景,例如标识码每次请求、生成一个订单号、创建用户。
分布式ID生成器需要满足以下特性:
- 趋势递增,mysql是最常用的数据库,如果ID不是趋势递增,那么B+树为了维护ID有序性,会频繁在索引的中间位置插入节点,从而影响后面节点的位置,甚至频繁导致页分裂,这对于性能的影响是极大的。
- 全局唯一性,ID不唯一就会出现主键冲突。
- 高性能,生成ID是高频操作,如果性能缓慢,系统的整体性能就会受到限制。
- 高可用,也就是在给定的时间间隔内,一个系统总的可用时间占的比例。
- 存储空间小,例如对于mysql的B+树,普通索引会存储主键值,主键越大,每个Page可以存储的数据就越少,访问磁盘I/O的次数就会增加。
Redis集群能保证高可用和高性能,为了节省内存,ID可以使用数字的形式,并且通过递增的方式来创建新的ID。为了防止重启数据丢失,还需要开启redis的aof持久化。虽然,开启aof持久化,为了性能配置everysec策略还是有可能丢失1s的数据,因此还可以使用一个异步机制(例如将id发送到mq消息队列中)将生成的最大ID持久化到一个mysql。
设计思路
假设订单ID生成器的键是"counter:order",当应用服务启动时先从mysql中查询出最大值M,然后执行exists命令判断是否存在键。
- 如果redis中不存在键,则执行set命令将值M写入redis。
- 如果redis中存在键,值为N,则比较M和N的值,执行SET命令将M与N的最大值写入redis,相等则不操作。
- 应用服务启动完成后,在每次需要生成ID时,应用程序就向redis服务器发送incr命令。
- 应用程序将获取到的ID值发送到mq对象,消费者监听队列把值持久化到mysql。
代码实现
javascript
async generateDistributedId(key, value, callback: (id) => void) {
try {
let flag = await this.redis.exists(key)
if (flag == 0) {
//不存在该健
await this.redis.set(key, value??0)//不存在该键,就初始化为0或value
} else {
let redis_value = await this.redis.get(key)
await this.redis.set(key, Math.max(redis_value, value))
}
// 使用 INCR 命令对指定的键进行自增操作
const id = await this.redis.incr(key);
callback(id)
return id;
} catch (error) {
this.logger.error(`生成分布式 ID 时出错: ${error}`);
throw error;
}
}当然,还需要其他的分布式ID生成发送,例如,雪花算法、UUID等
列表(List)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。列表最多可以存储 2^32 - 1 个元素。
分布式系统中必备的一个中间件就是消息队列,它可以进行服务间异步解耦、流量消峰,实现最终一致性。目前市面上已有的消息队列又kaqfka、pulsar等。
那么,redis适合做消息队列吗?想要回答这个问题之前,得先从本质思考
- 消息队列提供了什么特性?
- Redis如何实现消息队列?是否满足存取需求?
什么是消息队列
消息队列是一种异步的服务间通信方式,适用于分布式和微服务架构。消息在被处理和删除之前一直存储在队列上。
它基于先进先出的原则,允许生产者向队列中发送消息,而消费者则可以从队列中获取消息并进行处理。
消息队列通常被用于解耦应用程序的各个组件,实现异步通信、削峰填谷、解耦合、流量控制等功能。

- Producer:消息生产者,负责产生和发送消息到消息处理中心(Broker)。
- Broker:消息处理中心,负责消息存储、确认、重试等,一般会包含多个queue。
- Consumer:消息消费者,负责从Broker中获取消息,并进行相应处理。
消息队列在实际应用中包括如下4个场景。
- 应用耦合:发送方、接收方的系统之间不需要互相了解,只需要认识消息。多应用间通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败。
- 异步处理:多应用对消息队列中的同一消息进行处理,应用间并发处理消息,相比串行处理,减少处理时间。
- 限流削峰:广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统"挂掉"的情况。
- 消息驱动的系统:系统中有消息队列、消息生产者和消息消费者,生产者负责产生消息,消费者负责处理消息。
消息队列满足哪些特性
- 消息有序性:消息是异步处理的,但是消费者需要按照生产者发送消息的顺序来消费,避免出现后发送的消息被先处理的情况。
- 重复消息处理:当因为网络问题出现消息重传时,消费者可能收到多条重复消息。同样的消息重复多次可能造成同一业务逻辑被多次执行,在这种情况下,应用系统需要确保幂等性。
- 可靠性:保证一次性传递消息。如果发送消息时消费者不可用,那么消息队列会保留消息,直到成功传递它。当消费者重启后,可以继续读取消息进行处理,防止消息遗漏。
- LPUSH:生产者使用LPUSH命令将消息插入队列头部,如果key不存在则会创建一个空的队列再插入消息,LPUSH命令的返回值表示插入队列的消息个数。
- 使用BLPOP、BRPOP阻塞读取的命令,消费者在读取队列没有数据时会自动阻塞,直到有新的消息写入队列,才继续读取消息执行业务逻辑。
注意:Lists方式实现的消息队列并没有提供类似kafka的消费者组的概念,由多个消费者组成一个消费者组来分担处理队列消息的任务。如果,生产者发送消息的速度过快,消费者处理不过来,则会导致消息积压,占用过多的内存。从redis5.0版本开始,可以使用Stream来实现。
重复消费解决方案
- 消息队列自动为每条消息生成一个全局ID。
- 生产者为每条消息创建一个全局ID,消费者把处理过的消息ID记录下来判断是否重复。
其实这就是幂等,对于同一条消息,消费者收到后处理一次的结果和处理多次的结果是一致的。
消息可靠性解决方案
消费者读取消息,处理过程中宕机了就会导致消息没有处理完成,可是数据已经不在队列中了。这种现象的本质就是消费者在处理消息时崩溃了,无法再读取消息,缺乏一个消息确认的可靠机制。可以使用BLMOVE命令,以阻塞的方式从原队列中读取消息,同时把这条消息复制到另一个队列中(备份),并且是原子操作。
设计思路
- 生产者使用LPUSH命令将消息依次存入队列队头。
- 消费者消费消息时在while循环使用BLMOVE,以阻塞的方式从队列队尾弹出消息,同时把该消息复制到备份队列中,该操作是原子性的。
- 如果消费消息成功,就是用LREM把备份队列中的对应的消息删除,从而实现ACK确认机制。
- 如果消费异常,那么应用程序使用BRPOP命令从备份队列再次读取消息。
代码实现
javascript
// 定义队列名称
private MAIN_QUEUE = 'main_queue';
private BACKUP_QUEUE = 'backup_queue';
private DEAD_LETTER_QUEUE = 'dead_letter_queue';
// 定义最大重试次数
private MAX_RETRIES = 3;
// 定义消息过期时间(单位:毫秒)
private MESSAGE_EXPIRATION_TIME = 60000;
// 生产者:向主队列中添加消息
async produceMessage(message) {
try {
const msgId = Date.now() + '_' + Math.random().toString(36).slice(2);
const fullMsg = {
id: msgId,
content: message,
retries: 0,
createdAt: Date.now()
};
await this.redis.lpush(this.MAIN_QUEUE, JSON.stringify(fullMsg));
this.logger.info(`Produced message: ${JSON.stringify(fullMsg)}`);
} catch (error) {
this.logger.error(`Error producing message: ${error}`);
}
}
// 消费者:从主队列消费消息
async consumeMessages(processMessageCallback: (msg: any) => Promise<void>) {
while (true) {
try {
// 原子性地将消息从主队列移到备份队列
const msg = await this.redis.blmove(
this.MAIN_QUEUE,
this.BACKUP_QUEUE,
'RIGHT',
'LEFT',
0
);
if (msg) {
const parsedMsg = JSON.parse(msg);
// 检查消息是否过期
if (Date.now() - parsedMsg.createdAt > this.MESSAGE_EXPIRATION_TIME) {
// 消息过期,将其移动到死信队列
await this.redis.lrem(this.BACKUP_QUEUE, 1, msg);
await this.redis.lpush(this.DEAD_LETTER_QUEUE, JSON.stringify(parsedMsg));
this.logger.warn(`Message ${parsedMsg} has expired and moved to dead letter queue.`);
continue;
}
this.logger.info(`Processing message: ${parsedMsg}`);
//消息处理
await processMessageCallback(parsedMsg);
// 确认消费成功,从备份队列中移除消息
await this.redis.lrem(this.BACKUP_QUEUE, 1, msg);
}
} catch (error) {
this.logger.error(`Error consuming message:${error}`);
// 从备份队列取出消息进行重试
const [, retryMsg] = await this.redis.brpop(this.BACKUP_QUEUE, 0);
const parsedRetryMsg = JSON.parse(retryMsg);
// 增加重试次数
parsedRetryMsg.retries++;
if (parsedRetryMsg.retries >= this.MAX_RETRIES) {
// 达到最大重试次数,将消息移到死信队列
await this.redis.lpush(this.DEAD_LETTER_QUEUE, JSON.stringify(parsedRetryMsg));
this.logger.warn(`Message ${parsedRetryMsg} moved to dead letter queue.`);
} else {
// 未达到最大重试次数,重新放回主队列
await this.redis.lpush(this.MAIN_QUEUE, JSON.stringify(parsedRetryMsg));
this.logger.info(`Message ${parsedRetryMsg} will be retried.`);
}
}
}
}集合(Set)
Redis 的 Set 是 string 类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
使用场景
需要存储多个元素,并且要求不能出现重复数据,无须考虑元素的有序性时,可以使用Set。Set还支持在集合之间做交集、并集、差集操作。例如统计如下场景中多个集合元素的聚合结果。
- 统计多个元素的共有数据(交集)。
- 对于两个集合,统计其中的一个独有元素(差集)。
- 统计多个集合的所有元素(并集)。
常见的使用场景如下:
- 社交软件中共同关注:通过交集实现。
- 每日新增关注数:对近两天的总注册用户量集合取差集。
- 打标签:为自己收藏的每一篇文章打标签,例如微信收藏功能,这样可以快速找到被添加了某个标签的所有文章。
代码实现
javascript
async getCommonElements(keys:RedisKey[], storeKey:RedisKey) {
if (!keys || keys.length < 2) {
throw new Error("至少需要2个集合键");
}
// 执行交集操作
if (storeKey) {
// 存储结果到新键并返回数量
const count = await this.redis.sinterstore(storeKey, ...keys);
return count;
} else {
// 直接获取交集数据
const elements = await this.redis.sinter(...keys);
return elements;
}
}哈希(Hash)
Redis hash 是一个键值(key=>value)对集合,类似于一个小型的 NoSQL 数据库。
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
每个哈希最多可以存储 2^32 - 1 个键值对。
常用命令
- HSET key field value:设置哈希表中字段的值。
- HGET key field:获取哈希表中字段的值。
- HGETALL key:获取哈希表中所有字段和值。
- HDEL key field:删除哈希表中的一个或多个字段。
- DEL key:删除整个哈希表。
- HLEN key:查询散列表中有多少个field-value pairs。
- HSETNX key value:当key不存在时配置value,否则什么也不干。
有序集合(Sorted Set)
Sorted Set和Set类似,是一种集合类型,这种集合中不会出现重复的member(数据)。它们之间的区别在于:Sorted Set中的元素由两部分组成,分别是member和score。
member会关联一个double类型的score,Sorted Set默认会根据这个score对member从小到大进行排序,如果member关联的score相同,则按照字符串的字典顺序排序。
应用场景
- 排行榜:维护大型在线游戏中根据分数排名的Top10有序列表。
- 速率限流器:根据排序集合构建滑动窗口速率限制器。
- 延迟队列:使用score存储过期时间,从小到大排序,最靠前的就是最先到期的数据。
例如,很多地方都会用到排行榜功能,如微博热搜、游戏战力排行榜等,我们可以使用sorted sets实现一个实时游戏高分排行榜。
玩家的得分越高,排名越靠前,如果分数相同则先达到该分数的玩家排在前面,游戏排行榜提供的功能如下:
- 按照分数从高到低排名,查询前N位玩家的信息。
- 新注册玩家,需要把新玩家信息添加到排行榜中。
- 能查看某个玩家的排名和分数。
sorted sets的每个元素都由member和score两部分组成,可以利用score进行排序,正好满足我们的需求。用score保存玩家的游戏得分,member保存玩家ID。那么如何实现最先达到该分数的玩家排在前面这个功能。我们可以指定一个非常大的时间作为基准时间,时间排序值 = (基准时间-玩家达到分数时间)/基准时间。
以上公式得到的结果一定小于1,正好可以作为score的小数部分。越早达到,这个值就越大,满足排序要求。
Bitmap
在移动应用的业务场景中,我们需要保存这样的信息:一个key关联了一个数据集合。
常见的场景如下:
- 用户在线状态统计:可以使用Bitmap来记录用户的在线状态,其中每位表示一个用户的在线状态(在线为1,离线为0).这样可以高效地统计在线用户数量和在线用户的分布情况。
- 用户签到记录:Bitmap可以用于记录用户的签到情况,其中每位表示一个日期(已签到为1,未签到为0).这样可以轻松统计用户的连续签到天数、活跃用户数等信息。
- 页面点击量统计:Bitmap可以用于统计网站的页面点击量,其中每位表示一个页面的点击情况(点击为1,未点击为0).这样可以快速获取每个页面的点击量以及总点击量。
面向bit的操作是在字符串类型上定义的,将bitmap存储在字符串中,每个字符都是由8bit组成的数据,其中的每位只能是1或0.字符串类型的最大容量是512MB,所以一个Bitmap最多可配置2^32个不同位。
bitmap解决的是二值状态统计场景问题。也就是集合中的元素的值只有0和1两种,在签到打卡和用户是否登录的场景中,只需记录签到或未签到。
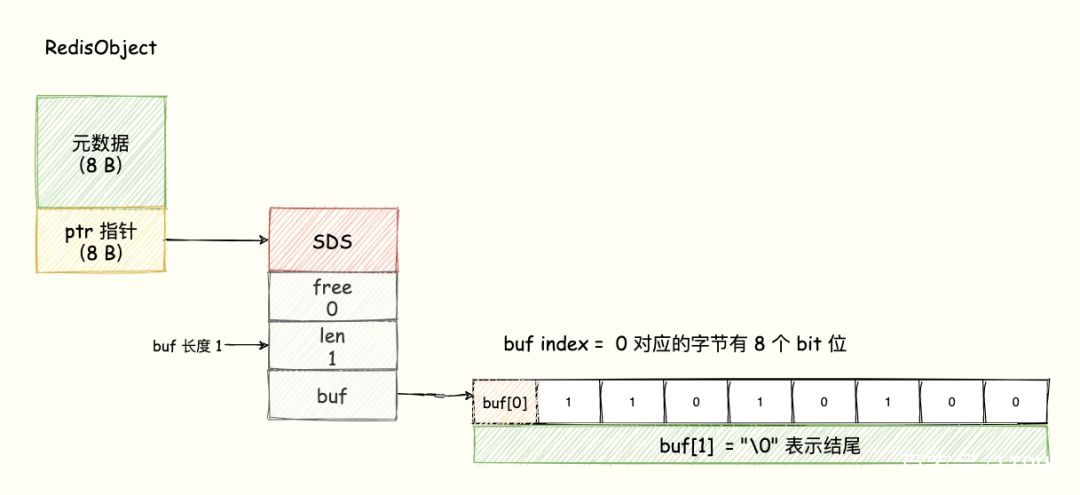
假如我们使用redis的字符串类型判断用户是否登录,如果以字符串的形式存储100万个用户的登录状态,那么需要存储100万个字符串,内存开销太大。因为redis是用c语言编写的redis提供的字符串类型本质上还是c语言中的字节数组,末尾还需要加上"\0"的那种,除此之外,redis还在此基础上封装了一层,记录数组已使用的长度,数组分配的空间总长度等,组成一个结构体。这些都是需要占用额外的存储空间。
bitmap的底层使用字符串类型的SDS数据结构来保存位数组,redis把每字节数组的8bit利用起来,每位表示一个元素的二值状态(不是1就是0).可以将bitmap看作一个以bit为单位的数组,数组的每位只能存储0或者1,数组的每位下标在bitmap中叫做offset偏移量。
使用场景
用户登录判断,bitmap提供了GETBIT、SETBIT操作,通过一个偏移值offset对bit数组的偏移量offset的bit进行读/写操作,需要注意的是,offset从0开始。bitmap的大小为byte的整数倍,例如你使用了31个bit,但是实际上为占用32bit,没用的会自动补0。
SETBIT:
例如:记录用户在2025年3月1日和2025年3月31日打卡情况。
javascript
SETBIT uid:sign:xxxx:202503 0 1
SETBIT uid:sign:xxx:202503 31 1执行以上两个命令后,bitmap的数据就是100000000000000000000000000010(一共32bit)。
相关命令
-
SETBIT:
- 设置或清除位的值。
- 语法:
SETBIT key offset value - 例子:
SETBIT mykey 7 1(将mykey的第 8 位设为1)
-
GETBIT:
- 获取指定偏移量的位的值。
- 语法:
GETBIT key offset - 例子:
GETBIT mykey 7(获取mykey的第 8 位的值)
-
BITCOUNT:
- 计算字符串中被设置为
1的位的数量。 - 语法:
BITCOUNT key [start end] - 例子:
BITCOUNT mykey(计算mykey中所有位中1的数量)
- 计算字符串中被设置为
-
BITOP:
- 对一个或多个字符串执行按位运算(AND、OR、XOR、NOT)。
- 语法:
BITOP operation destkey key [key ...] - 例子:
BITOP AND resultkey key1 key2(对key1和key2执行按位与运算,并将结果存储在resultkey中)
-
BITPOS:
- 找到字符串中第一个设置为
1或0的位的索引。 - 语法:
BITPOS key bit [start end] - 例子:
BITPOS mykey 1(查找mykey中第一个1的位置)
- 找到字符串中第一个设置为
使用场景
- 用户行为记录: 通过 Bitmap 可以高效地记录某个用户是否在某一天执行了某个操作,比如签到。
- 大规模布尔值存储: 可以在极小的空间内存储大量布尔值。
- 快速统计 : 使用
BITCOUNT可以快速统计某个集合或用户群体的某个行为发生次数。
Bitmap 的优点是空间效率高和操作速度快,适合用于需要处理大量布尔值或类似布尔值的数据场景。通过这些命令,你可以非常灵活地操作位数组,并根据具体需求进行优化和调整。
HyperLogLog
在移动互联网的业务场景中,数据量很大,系统需要保存这样的信息:一个key关联了一个数据集合,同时将这个数据集合以统计报表的形式呈现给运营人员。例如:
- 统计一个App的日活、月活人数。
- 统计一个页面每天被多少个不同账户访问。
- 统计用户每天搜索不同词条的个数。
- 统计注册IP地址数。
这些是典型的HyperLogLog(基数统计)应用场景。基数统计指统计一个集合中不重复元素的数量,这些不重复的元素被称为基数。
基数统计
HyperLogLog是一种概率数据结构,用于估计集合的基数。每个HyperLogLog最多消耗12kb内存,在标准误差0.81%的前提下,可以计算2^64个元素的基数。其主要特点如下。
- 高效存储:HyperLogLog的内存消耗是固定的,与集合中的元素数量无关。这使得它特别适用于处理大规模数据集,因为它不需要存储所有不同的元素,只需要存储估计基数所需的信息。
- 概率估计:HyperLogLog提供的结果是概率性的,不是精确的基数计数。它通过哈希函数将输入元素映射到Bitmap中的某些位置,并基于Bitmap的统计信息来估计基数的。由于这是一种概率方法,因此可能存在一定的误差,但在实际应用中,这个误差通常可以接受。
- 高速计算:HyperLogLog可以在常量时间内计算估计的基数,无论集合的大小如何。
应用场景
HyperLogLog的主要使用场景是基数统计。例如,海量网页访问量的统计,统计文章每天被多少用户访问过,一个用户一天访问多次只能记一次。
对于上面的场景,可以使用Sets、Bitmap和HyperLogLog来解决。
- Sets:统计精度高,对于少量的数据统计建议使用,大量的数据统计会占用很大的内存空间。
- Bitmap:位图算法,统计精度高,内存占用比Sets少,但是在统计大量数据时还是会占用大量内存。
- HyperLogLog:存在一定的误差,占用内存少(稳定占用12kb左右)。
Redis 中的 HyperLogLog 是一种概率性数据结构,用于估计集合中唯一元素的基数(即不重复元素的数量)。HyperLogLog 的优点是它占用极小的内存空间(大约 12 KB),即使是非常大的数据集也能保持这种低内存消耗。虽然它是一个估计器,但误差率非常小(大约 0.81%)。
以下是 Redis 中与 HyperLogLog 相关的命令:
-
PFADD:
- 向 HyperLogLog 添加元素。
- 语法:
PFADD key element [element ...] - 例子:
PFADD hllkey user1 user2 user3(将user1、user2和user3添加到hllkey)
-
PFCOUNT:
- 返回存储在 HyperLogLog 中的唯一元素的近似数量。
- 语法:
PFCOUNT key [key ...] - 例子:
PFCOUNT hllkey(返回hllkey中估计的唯一元素数量)
-
PFMERGE:
- 合并多个 HyperLogLog 数据结构为一个。
- 语法:
PFMERGE destkey sourcekey [sourcekey ...] - 例子:
PFMERGE mergedkey hllkey1 hllkey2(将hllkey1和hllkey2合并到mergedkey)
Geospatial
基于位置服务(LBS)
经纬度是由经度与维度组成的坐标系统,又称为地理坐标系统。LBS是围绕用户当前地理位置的数据而展开的服务,为用户提供精准的"邂逅"服务。LBS的特点如下:
- 以"我"为中心,搜索附件的Ta。
- 以"我"当前的地理位置为准,计算出别人和"我"之间的距离。
- 按"我"与别人距离的远近排序,筛选出离"我"最近的用户。
Redis 提供了 Geospatial 数据类型,用于存储和查询地理空间信息(如经纬度坐标)。这些命令非常适用于需要处理地理位置信息的应用,比如基于位置的服务、地图应用等。
GeoHash编码
GeoHash编码是将二维经纬度编码转换为一维,为地址位置分区的一种算法。其核心思想是区间二分:将地球编码看成一个二维平面,然后将这个平面递归均分为更小的子块。这个过程可以分为三步。
- 将经、纬度分别变成一个N位二进制数。
- 将经、纬度的二进制数合并。
- 按照Base32进行编码。
经纬度编码
GeoHash编码会把一个经度编码成一个N位的二进制数,例如对经度范围(-180,180)做√次二分区操作,其中N可以自定义。
在进行第一次二分区时,经度范围-180,180会被分成(-180,0)和0,180两个子区间(我称之为左、右分区)。
此时,我们可以查看一下要编码的经度值落在了左分区还是右分区。如果落在左分区,就用0表示;如果落在右分区,就用1表示。这样一来,每做完一次二分区,我们就可以得到1立编码值(不是0就是1)。
再对经度值所属的分区做一次二分区,查看经度值落在了二分区后的左分区还是右分区,然后按照刚才的规则再做1位编码。当做完N次二分区后,经度值就可以用一个N位的数来表示了。
所有的地图元素坐标都被放置于唯一的方格中,分区次数越多,方格越小,坐标越精确。
然后对这些方格进行整数编码,距离越近的方格编码越接近。
编码之后,每个地图元素的坐标都将变成一个整数,通过这个整数可以还原出元素的坐标,整数越长,还原出来的坐标值的损失就越小。对于"附近的人"这个功能而言,损失的一点精度可以忽略不计。
例如,对经度值169.99进行4位编码(N=4,做4次分区),把经度区间(-180,180)分成了左分区(-180,0)和右分区0,180。
- 169.99属于右分区,使用1表示第一次分区编码。
- 再将169.99经过第一次划分所属的0,180区间继续分成(0,90)和90,180,169.99依然在右区间,编码为1。
- 将90,180分为(90,135)和135,180,这次落在左分区,编码为0。
纬度的编码思路与经度一样,不再赘述。
Geospatial 命令
-
GEOADD:
- 将地理空间位置添加到指定的键中。
- 语法:
GEOADD key longitude latitude member [longitude latitude member ...] - 例子:
GEOADD locations 13.361389 38.115556 "Palermo" 15.087269 37.502669 "Catania"
-
GEOPOS:
- 返回一个或多个成员的地理空间位置(经纬度)。
- 语法:
GEOPOS key member [member ...] - 例子:
GEOPOS locations "Palermo" "Catania"
-
GEODIST:
- 返回两个给定成员之间的距离。
- 语法:
GEODIST key member1 member2 [unit] - 可选单位:
m(米),km(公里),mi(英里),ft(英尺) - 例子:
GEODIST locations "Palermo" "Catania" km
-
GEORADIUS (已弃用,推荐使用
GEOSEARCH):- 在给定的圆形范围内查找成员,基于给定的经纬度。
- 语法:
GEORADIUS key longitude latitude radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key] - 例子:
GEORADIUS locations 15 37 200 km WITHDIST
-
GEORADIUSBYMEMBER (已弃用,推荐使用
GEOSEARCH):- 在给定的圆形范围内查找成员,基于给定的已有成员的位置。
- 语法:
GEORADIUSBYMEMBER key member radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key] - 例子:
GEORADIUSBYMEMBER locations "Palermo" 100 km WITHDIST
-
GEOSEARCH:
- 根据指定的半径或边界框条件搜索地理位置。
- 语法:
GEOSEARCH key FROMMEMBER member|FROMLOC long lat BYRADIUS radius unit|BYBOX width height unit [ASC|DESC] [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] - 例子:
GEOSEARCH locations FROMMEMBER "Palermo" BYRADIUS 100 km ASC WITHDIST
-
GEOSEARCHSTORE:
- 执行
GEOSEARCH并将结果存储在一个新的或现有的键中。 - 语法:
GEOSEARCHSTORE dest key FROMMEMBER member|FROMLOC long lat BYRADIUS radius unit|BYBOX width height unit [ASC|DESC] [COUNT count] [STOREDIST] - 例子:
GEOSEARCHSTORE nearby_locations locations FROMMEMBER "Palermo" BYRADIUS 100 km
- 执行
Stream
stream是redis5.0专门为消息队列设计的数据类型,借鉴kafka的消费组的设计思想,提供消费者组的概念,同时提供消息的持久化和主从复制机制。客户端可以访问任何时刻的数据,并且能记住每个客户端的访问位置,从而保证消息不丢失。
需要注意的是,stream是一种超轻量级的MQ,并没有完全实现消息队列的所有设计要点,所以它的使用场景需要考虑业务的数据量和对性能】可靠性的需求。对于系统消息量不大、可以容忍数据丢失的场景,使用stream作为消息队列就能享受高性能快速读/写消息的优势。
Redis Streams 是一种强大的数据结构,旨在支持高效的消息队列和事件流处理。它允许在 Redis 中存储和处理时间序列数据,提供了强大的功能用于生产者和消费者之间的消息传递。以下是 Redis Streams 相关的主要命令及其功能:
Stream 命令
-
XADD:
- 向流中添加新的条目。
- 语法:
XADD key ID field value [field value ...] - ID 可以为
*,让 Redis 自动生成一个唯一 ID。 - 例子:
XADD mystream * sensor-id 1234 temperature 19.8
-
XRANGE:
- 读取流中某个范围的条目。
- 语法:
XRANGE key start end [COUNT count] start和end可以为特殊值-和+,表示流的开始和结束。- 例子:
XRANGE mystream - + COUNT 10
-
XREVRANGE:
- 以相反的顺序读取流中某个范围的条目。
- 语法:
XREVRANGE key end start [COUNT count] - 例子:
XREVRANGE mystream + - COUNT 10
-
XLEN:
- 返回流中的条目数。
- 语法:
XLEN key - 例子:
XLEN mystream
-
XREAD:
- 从一个或多个流中读取数据。
- 语法:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] - 支持阻塞操作,等待新的条目。
- 例子:
XREAD STREAMS mystream 0
-
XGROUP CREATE:
- 创建消费者组。
- 语法:
XGROUP CREATE key groupname id|$ [MKSTREAM] id可以为$,表示从最后一个条目开始消费。- 例子:
XGROUP CREATE mystream mygroup $
-
XREADGROUP:
- 读取消息并标记为已被消费者组消费。
- 语法:
XREADGROUP GROUP groupname consumer [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] - 例子:
XREADGROUP GROUP mygroup consumer1 STREAMS mystream >
-
XACK:
- 确认消息已被处理。
- 语法:
XACK key groupname id [id ...] - 例子:
XACK mystream mygroup 1526569495631-0
-
XPENDING:
- 查看消费者组的待处理消息。
- 语法:
XPENDING key groupname [start end count] [consumer] - 例子:
XPENDING mystream mygroup
-
XCLAIM:
- 将消息的所有权转移到另一个消费者。
- 语法:
XCLAIM key groupname consumer min-idle-time id [id ...] [RETRYCOUNT count] [FORCE] [JUSTID] - 例子:
XCLAIM mystream mygroup consumer2 0 1526569495631-0
-
XDEL:
- 删除流中的条目。
- 语法:
XDEL key id [id ...] - 例子:
XDEL mystream 1526569495631-0
-
XTRIM:
- 修剪流以减少其长度。
- 语法:
XTRIM key MAXLEN [~] count - 例子:
XTRIM mystream MAXLEN 1000
使用场景
- 消息队列: 用于实现高效的生产者-消费者模型。
- 事件溯源: 在事件驱动架构中记录和处理事件。
- 日志处理: 实时收集和分析日志数据。
Redis Streams 提供了一种高效且灵活的方法来处理实时数据流,适合多种应用场景,如实时数据处理、日志分析、消息队列等。通过消费者组和阻塞读取等功能,Redis Streams 可以处理复杂的数据流管理需求。
javascript
const Redis = require('ioredis');
const redis = new Redis();
const streamKey = 'mystream';
const groupName = 'mygroup';
const consumerName = 'consumer1';
// 创建消费者组
async function createConsumerGroup() {
try {
await redis.xgroup('CREATE', streamKey, groupName, '$', 'MKSTREAM');
console.log(`Consumer group ${groupName} created.`);
} catch (err) {
if (err.message.includes('BUSYGROUP Consumer Group name already exists')) {
console.log(`Consumer group ${groupName} already exists.`);
} else {
throw err;
}
}
}
// 生产者:向流中添加消息
async function produceMessages() {
const messageId = await redis.xadd(streamKey, '*', 'field1', 'value1');
console.log(`Produced message with ID: ${messageId}`);
}
// 消费者:读取并确认消息
async function consumeMessages() {
while (true) {
try {
const messages = await redis.xreadgroup(
'GROUP', groupName, consumerName,
'BLOCK', 0,
'STREAMS', streamKey, '>'
);
if (messages) {
messages.forEach(([_stream, entries]) => {
entries.forEach(([id, fields]) => {
console.log(`Consumed message ID: ${id}, fields: ${fields}`);
// 处理消息后,确认消息
redis.xack(streamKey, groupName, id);
console.log(`Acknowledged message ID: ${id}`);
});
});
}
} catch (err) {
console.error('Error reading from stream:', err);
break;
}
}
}
(async () => {
await createConsumerGroup();
produceMessages(); // 生产消息
// 启动消费者,可以启动多个消费者
consumeMessages();
})();Radix Tree
前缀树被用于高效存储和查找字符串集合。它将字符串按照前缀拆分成一个个字符,并将每个字符作为一个节点存储在树中。
当插入一个field-value pairs时,redis会将field拆分成一个个字符,并根据字符在radix tree中的位置找到合适的节点,如果该节点不存在,则创建新节点并添加到radix tree中。
当所有字符添加完毕后,将值对象指针保存到最后一个节点中。当查询一个field时,redis按照字符顺序遍历radix tree,如果发现某个字符不存在于树中,则表示field不存在;如果最后一个节点表示一个完整的field,则返回对应的值对象。利用前缀树就可以避免相同字符串被重复存储。
Redis高性能的原因
-
基于内存实现
读、写操作都是在内存上完成的。内存直接由cpu控制,也就是由cpu内部集成内存控制器,所以说内存是直接与cpu对接的,享受与cpu通信的"最优带宽"。redis将数据存储在内存中,读/写操作不会被磁盘的I/O速度限制。
-
I/O多路复用模型
redis采用I/O多路复用技术并发处理连接。采用epoll+自己实现的简单的事件框架。将epoll中的读、写、关闭、连接都转化为事件,再利用epoll的多路复用特性实现一个ae高性能网络事件处理框架,绝不在I/O上浪费时间。
在解释I/O多路复用之前,我们先了解下基本I/O操作会经历什么。
一个基本的网络I/O模型处理get请求时,会经历如下过程。
- 服务端bind/listen绑定IP地址并监听指定端口的请求,与客户端建立accept。
- 从socket读取请求recv。
- 解析客户都安发送的请求parse。
- 指向get命令。
- send执行相应客户端数据,也就是向socket写回数据。
其中,bind、accept、recv、parse和send都属于网络I/O处理,而get命令属于键-值数据操作。既然redis是单线程的,那么,最基本的实现就是在一个线程中依次执行上述操作。其中的关键是accept和recv会出现阻塞,当redis监听到一个客户端有连接请求,但一直未能成功建立连接时,会阻塞在accept函数,导致其他客户端无法和redis建立连接。类似地,当redis通过recv函数从一个客户端读取数据时,如果数据一直没有到达,那么redis就会一直阻塞在recv函数。
"多路"指多个socket连接,"复用"指共同使用一个线程。多路复用主要有select、poll和epoll三种技术。epoll的基本原理是,内核不监视应用程序本身的连接,而是监视应用程序的文件描述符。客户端在运行时会生成具有不同事件类型的套接字。在服务器端,I/O多路复用程序会将消息放入队列,然后通过文件事件分派器将其转发到不同的事件处理器。
简单来说,在单线程条件下,内核会一直监听socket上的连接请求或者数据请求,一旦有请求到达就交给redis线程处理,这就实现了一个redis线程处理多个I/O流的效果。
select/epoll提供了基于事件的回调机制,即针对不同事件调用不同的事件处理器。所以,redis一直在处理事件,响应性能得到了提升。redis线程不会阻塞在某一个特定的监听或套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。因此,redis可以同时和多个客户端连接并处理请求,以提升并发能力。
-
单线程模型
单线程指redis的网络I/O以及field-value pairs命令读/写是由一个线程来执行的。redis的持久化、集群数据同步,异步删除等操作都是其他线程执行的。
单线程高性能的原因redis选择使用单线程处理命令以及高性能的主要原因如下:
- 不会因为创建线程消耗性能。
- 避免上下文切换引起的cpu消耗,没有多线程切换的开销。
- 避免了线程之间的竞争问题,例如添加锁、释放锁、死锁等。
- 代码更清晰。
-
高效的数据结构
redis通过一个散列表来保存所有的key-value,散列表的本质就是数组+链表,数组的槽位被叫做哈希桶。每个桶的entry保存指向具体key和value的指针。key是string类型,value的数据类型可以是5种中的任意一种。

我们可以把redis看作一个全局散列表,而全局散列表的时间复杂度是O(1)。通过计算每个键的哈希值,可以知道对应的哈希桶位置,再通过哈希桶的entry找到对应的数据,这也是redis快的原因之一。