Linux错误(6)X64向量指令访问地址未对齐引起SIGSEGV
Author: Once Day Date: 2025年4月4日
一位热衷于Linux学习和开发的菜鸟,试图谱写一场冒险之旅,也许终点只是一场白日梦...
漫漫长路,有人对你微笑过嘛...
全系列文章可参考专栏: Linux实践记录_Once_day的博客-CSDN博客
文章目录
- Linux错误(6)X64向量指令访问地址未对齐引起SIGSEGV
-
-
-
- [1. 问题分析](#1. 问题分析)
-
- [1.1 现象介绍](#1.1 现象介绍)
- [1.2 分析原因](#1.2 分析原因)
- [1.3 解决思路](#1.3 解决思路)
- [1.4 内存申请与对齐](#1.4 内存申请与对齐)
- [2. 实例验证](#2. 实例验证)
-
- [2.1 使用posix_memalign对齐内存](#2.1 使用posix_memalign对齐内存)
- [2.2 使用aligned_alloc 对齐内存](#2.2 使用aligned_alloc 对齐内存)
- [3. 总结](#3. 总结)
-
-
1. 问题分析
1.1 现象介绍
X64设备上,如果定义一个结构体,其包含连续的整数字段,并且存在类似的算术操作,编译会自动优化代码,生成向量指令SSE/AVX(xmm0),但是由于这些结构体的地址没有对齐到16字节,读取数据时会触发SIGSEGV错误,造成coredump。
如下面这段代码在O3优化等级下,会生成向量指令,从而触发SIGSEGV问题:
c
struct result128 {
uint64_t low;
uint64_t high;
} __attribute__((aligned(16)));
/* 禁止内联 */
__attribute__((noinline)) void data128_add(struct result128 *result128, uint64_t low, uint64_t high)
{
result128->low += low;
result128->high += high;
}
// data128_add函数二进制反汇编如下
// 1374: 66 48 0f 6e c6 movq %rsi,%xmm0
// 1379: 66 48 0f 6e ca movq %rdx,%xmm1
// 137e: 66 0f 6c c1 punpcklqdq %xmm1,%xmm0
// 1382: 66 0f d4 07 paddq (%rdi),%xmm0
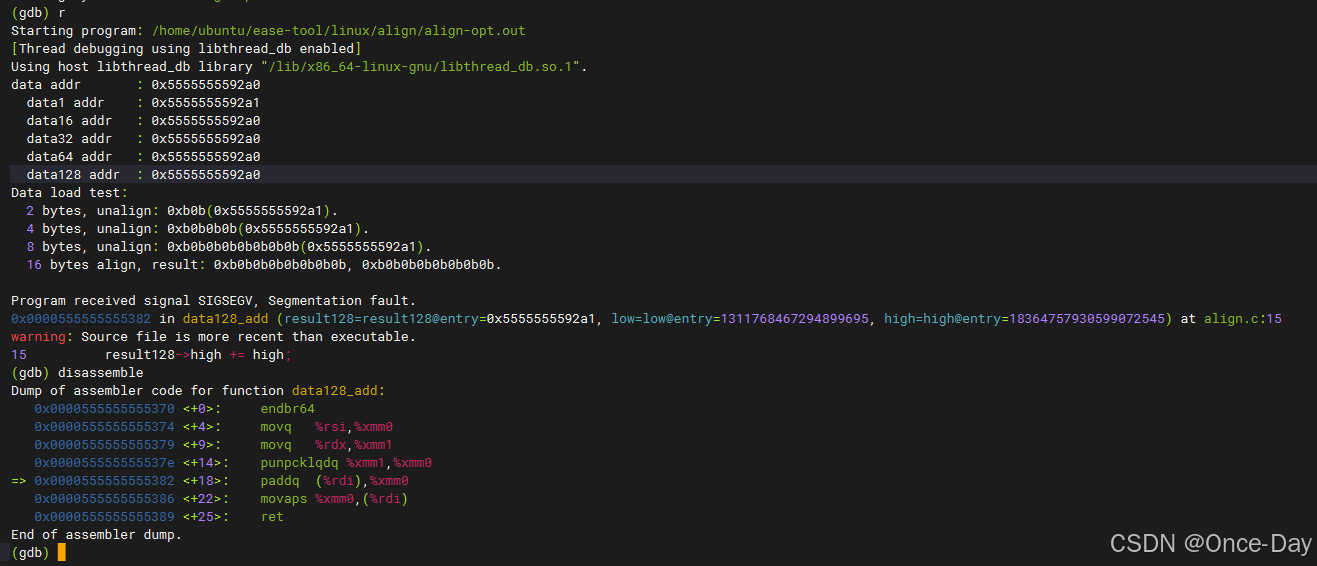
// 1386: 0f 29 07 movaps %xmm0,(%rdi)GDB调试运行结果如下,可以清晰看到执行的指令、代码行和数据地址信息:
整个源码文件如下:
c
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct result128 {
uint64_t low;
uint64_t high;
} __attribute__((aligned(16)));
/* 禁止内联 */
__attribute__((noinline)) void data128_add(struct result128 *result128, uint64_t low, uint64_t high)
{
result128->low += low;
result128->high += high;
// -O3 编译会生成如下代码
// 1374: 66 48 0f 6e c6 movq %rsi,%xmm0
// 1379: 66 48 0f 6e ca movq %rdx,%xmm1
// 137e: 66 0f 6c c1 punpcklqdq %xmm1,%xmm0
// 1382: 66 0f d4 07 paddq (%rdi),%xmm0
// 1386: 0f 29 07 movaps %xmm0,(%rdi)
}
int main(void)
{
// 申请一段内存, 64字节
uint8_t *data = malloc(64);
memset(data, 0xb, 64);
// 手动对齐到 1/2/4/8/16 字节
uint8_t *data1 = (uint8_t *)(((uintptr_t)data + 0) & ~0) + 1;
uint16_t *data16 = (uint16_t *)(((uintptr_t)data + 1) & ~1);
uint32_t *data32 = (uint32_t *)(((uintptr_t)data + 3) & ~3);
uint64_t *data64 = (uint64_t *)(((uintptr_t)data + 7) & ~7);
uint64_t *data128 = (uint64_t *)(((uintptr_t)data + 15) & ~15);
printf("data addr : %p \n", data);
printf(" data1 addr : %p \n", data1);
printf(" data16 addr : %p \n", data16);
printf(" data32 addr : %p \n", data32);
printf(" data64 addr : %p \n", data64);
printf(" data128 addr : %p \n", data128);
printf("Data load test:\n");
printf(" 2 bytes, unalign: 0x%x(%p).\n", *(uint16_t *)data1, data1);
printf(" 4 bytes, unalign: 0x%x(%p).\n", *(uint32_t *)data1, data1);
printf(" 8 bytes, unalign: 0x%lx(%p).\n", *(uint64_t *)data1, data1);
// 使用ASM内联汇编读取到xmm0寄存器
struct result128 result128;
// 读取 128位数据到xmm0寄存器
__asm__ volatile("movdqa %0, %%xmm0" : : "m"(*data128) : "%xmm0");
// 将xmm0寄存器的值存储到result128中
__asm__ volatile("movdqa %%xmm0, %0" : "=m"(result128) : : "%xmm0");
printf(" 16 bytes align, result: 0x%lx, 0x%lx.\n", result128.low, result128.high);
struct result128 *result128_addr = (struct result128 *)data1;
data128_add(result128_addr, 0x1234567890abcdef, 0xfedcba0987654321);
printf(" 16 bytes unalign, result: 0x%lx, 0x%lx.\n", result128.low, result128.high);
return 0;
}1.2 分析原因
在X64架构下,未对齐的内存访问(如2/4/8字节非对齐访问)可能会导致性能下降,但通常不会引发SIGSEGV错误。当使用SSE/AVX向量指令(如paddq)访问未对齐的内存时,会触发SIGSEGV错误,因为这些指令要求内存地址必须对齐到16字节边界。
编译器在O3优化等级下,识别出result128结构体的连续整数字段,并自动生成了向量指令来优化代码。虽然result128结构体本身声明了16字节对齐,但实际传入的结构体指针可能没有对齐到16字节边界,导致向量指令访问未对齐内存而触发SIGSEGV。
1.3 解决思路
确保传入的result128结构体指针已对齐到16字节边界。可以使用posix_memalign、aligned_alloc等函数分配对齐的内存。如果无法保证传入指针的对齐性,可以在函数内部使用memcpy将未对齐的数据复制到局部的、已对齐的result128结构体中,再进行计算和写回。
可以使用#pragma pack(16)声明结构体,强制编译器始终按16字节对齐结构体。但这可能会浪费内存空间。也可以使用__attribute__((aligned(16)))修饰函数参数,确保传入的指针已对齐。但这需要调用方遵循对齐要求。
在编译选项中使用-mno-sse或-mno-avx禁用向量指令,避免自动向量化。但这会影响性能。
如果以上方法都无法实现,可以尝试修改算法,避免在结构体上使用连续的算术操作,从而避免触发向量化。
1.4 内存申请与对齐
常见的动态内存分配函数如malloc、calloc、realloc等,默认情况下返回的内存地址已经满足了基本的对齐要求,一般是按照系统的最大基本数据类型对齐(如long double、指针等)。但这些函数无法直接指定更大的对齐字节数。
以下是一些支持指定内存对齐字节数的函数:
(1)posix_memalign (POSIX标准)
c
int posix_memalign(void **memptr, size_t alignment, size_t size);posix_memalign可以指定alignment参数,要求必须是2的幂次且至少为sizeof(void*)。函数将分配size字节的内存,并确保内存地址按alignment字节对齐。
(2)aligned_alloc (C11标准)
c
void *aligned_alloc(size_t alignment, size_t size);aligned_alloc类似于posix_memalign,但将对齐的内存地址直接返回,而不是通过指针参数传递。
(3)memalign (GNU扩展)
c
void *memalign(size_t alignment, size_t size);memalign是GNU的扩展函数,功能与aligned_alloc相似,但可移植性较差。
(4)_aligned_malloc (Windows)
c
void *_aligned_malloc(size_t size, size_t alignment);_aligned_malloc是Windows平台下的对齐内存分配函数,类似于aligned_alloc。
(5)valloc (已废弃)
c
void *valloc(size_t size);valloc分配的内存按虚拟内存页大小(通常为4KB)对齐,但已被废弃,不建议使用。
使用这些对齐内存分配函数获取的内存,必须使用对应的内存释放函数(如aligned_free、free等)来释放,以避免内存泄漏。
2. 实例验证
2.1 使用posix_memalign对齐内存
使用posix_memalign申请16字节对齐内存,执行函数,然后释放:
c
struct result128 *result128_addr;
int32_t ret = posix_memalign((void **)&result128_addr, 16, sizeof(struct result128));
if (ret != 0) {
printf("posix_memalign failed, ret: %d.\n", ret);
return -1;
}
data128_add(result128_addr, 0x1234567890abcdef, 0xfedcba0987654321);
printf(" 16 bytes unalign, result: 0x%lx, 0x%lx.\n", result128_addr->low,
result128_addr->high);
// 释放内存
free(data);
free(result128_addr);在类Unix系统(如Linux、macOS等)中,只需包含<stdlib.h>即可使用posix_memalign函数。
posix_memalign是POSIX标准定义的函数,在某些嵌入式系统或者非POSIX兼容的操作系统上可能无法使用。在这种情况下,可以考虑使用其他平台特定的对齐内存分配函数,或者自行实现对齐内存分配的逻辑。
2.2 使用aligned_alloc 对齐内存
使用与posix_memalign类似,如下:
c
struct result128 *result128_addr = aligned_alloc(16, sizeof(struct result128));
data128_add(result128_addr, 0x1234567890abcdef, 0xfedcba0987654321);
printf(" 16 bytes unalign, result: 0x%lx, 0x%lx.\n", result128_addr->low,
result128_addr->high);
// 释放内存
free(data);
free(result128_addr);aligned_alloc函数是C11标准引入的,用于分配指定对齐字节数的内存。
aligned_alloc函数返回一个指向对齐内存的指针,该内存块的大小为size字节,并按alignment字节对齐。如果分配成功,返回的指针可以直接传递给free函数释放。
aligned_alloc函数与普通的malloc函数都遵循了相同的内存管理约定,即使用free函数释放内存。
3. 总结
在X64架构下,使用未对齐的内存地址进行SSE/AVX向量指令访问时,可能会触发SIGSEGV错误。这通常发生在编译器对包含连续整数字段的结构体进行自动向量化优化时。
为了避免这类问题,可以采取以下措施:
- 确保传入的结构体指针已对齐到16字节边界,可使用posix_memalign、aligned_alloc等函数分配对齐内存。
- 在函数内部使用memcpy处理未对齐数据,复制到局部的对齐结构体中进行计算和写回。
- 在编译选项中禁用向量指令,或修改算法避免触发自动向量化。
常见的动态内存分配函数如malloc、calloc等默认返回的内存已经满足基本的对齐要求(8字节),但无法直接指定更大的对齐字节数。为此,可以使用posix_memalign、aligned_alloc、memalign、_aligned_malloc等支持指定对齐字节数的函数。
在实际应用中,应优先使用标准的对齐内存分配函数,遵循最小适配原则,并使用对应的内存释放函数,以提高代码的可移植性、兼容性和内存使用效率。