一、前言
什么是编程
编程就是人把自己想让计算机做的事情,用计算机
能听懂的语言(编程语言)给翻译下来
所以编程分为两个环节:
1、先想清楚做事的步骤
2、再用编程语言把做事步骤给翻译下来
为何要编程
为了让计算机能够按照人类的思维逻辑(人类编写程序)去工作,从而把人解放出来
什么是程序:
编程的结果就是程序,具体来说程序一个多个代码文件
整个程序就一个文件(实现功能相对简单、代码量少):称之为脚本
整个程序由很多文件夹组织了很多文件:称之为软件
什么是进程
进程指的是一个程序的运行过程,或者说一个正在运行的程序
编程语言分类 :
机器语言:用计算机能听懂的二进制指令去编写程序
优点:执行效率最高
缺点:开发效率最低
汇编语言:用英文标签代替二进制指令去写程序
优点:开发效率略高于机器语言(解决了机器语言二进制指令难以记忆的问题)
缺点:相比机器语言来说执行效率略低
总结:
虽然汇编语言是一种进步
但是用汇编语言开发程序的仍然比较复杂
高级语言:站在人能理解的表达方式去写程序,计算机无法直接理解
需要经过翻译才能被计算机理解执行,按照翻译方式的不同又分为两大类
1、编译型(c、go)
源代码-------编译器(类似于谷歌翻译)-----》可执行的二进制指令
特点:
拿到编译结果之后,第二次运行不需要再编译,直接拿着上次翻译的结果执行即可
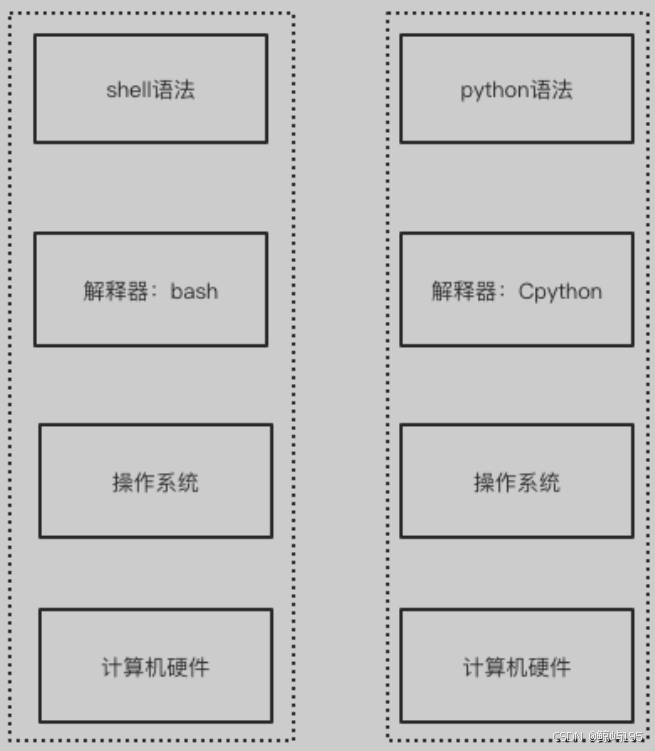
2、解释型 (shell、python)
源代码-------解释器(类似于同声传译)-----》可执行的二进制指令
特点:
每次执行 都需要让解释器解释执行 (读一行解释一行然后执行)
开发效率:
高级语言 》 汇编语言》机器语言
执行效率:
机器语言》汇编语言》高级语言(编译型>解释型)
shell两层意思:
1、shell这门编程语言
2、shell解释器:专门负责解释执行shell这门语言的语法规则
shell解释器种类:
bash
sh
shell程序可以在两个地方写
交互式环境
优点:每敲一条命令理解得到结果,然后才能执行下一条命令
缺点:无法永久保存命令
写入文件中(脚本)
优点:永久保存命令、重复执行
缺点:无法单纯测试某条命令的运行结果
编写shell脚本的组成部分
#!/bin/bash -----------》指定由哪个解释器来解释执行当前文件的代码(默认就是bash )
注释部分:是对代码的解释说明
执行shell脚本由四种方式:
1、启动了一个子bash进程,即在子bash进程执行
1、绝对路径:/a/b/b.sh
权限:
1、对沿途 的文件夹都要有x
2、对目标文件 要有r与x
2、相对路径:
cd /a
b/b.sh
cd /a/b/
./b.sh ############################(./没有空格)
权限:
1、对沿途的文件夹都要有x
2、对目标文件要有r与x
3、bash解释器+脚本文件的路径
权限:
1、对沿途的文件夹都要有x
2、对目标文件要有r(本质执行的是bash命令,不用给目标文件执行权限也能执行)
2、在当前bash进程里执行
特点:
1、对沿途文件夹有x权限
2、对目标文件有r权限即可
source /a/b/b.sh
. /a/b/b.sh ##################################(. / 中间有空格)
注释:
1、对代码进行解释说明
大前提:只在关键代码上加注释
添加的位置:
1、代码的正上方单独一行
2、或者是代码的正后方(注意要加一个空格)
2、可以将暂时不想运行的代码给注释掉
程序的调试(debug):
sh -vx login.sh # 不加-v选项,只会显示程序中运行的代码,不会显示注释信息
sh -n login.sh # 只调试语法是否有问题
cat login.sh ###set -x set +x 只调试范围内的代码段
#!/usr/bin/env bash
set -x
read -p "请输入您的名字: " name
read -p "请输入您的密码: " pwd
set +x
if \[ "$name" == "egon" \&\& "$pwd" == "123" ];then
echo "登录成功"
else
echo "账号或密码错误"
fi
. login.sh
二、变量
定义
变量本质是一种数据的存储机制,数据存放于内存中
为何要有变量
为了让计算机能够像一样去记住事物的状态,并且状态可以变化
程序=数据+功能
先定义
定义变量由三大部分构成
变量名=变量值 # 注意=左右两边不能有空格
age=18
ip="1.1.1.10"
msg="hello world"
后引用
echo $age
echo ${age}
percent=33
echo {percent}% # 注意:如果是打印百分比,建议使用{变量名}%
33%
删除
unset age
root@localhost shell# ip="192.168.11.10" # 字符串类型加引号
root@localhost shell# echo $ip
192.168.11.10
定义一个变量由三大部分组成
变量名: 用来访问到变量值的
赋值符号=: 将变量值的内存地址绑定给变量名
变量值: 即我们存的数据
#变量名 的命令应该见名知意,同时遵循如下规则
以字母或下划线开头,剩下的部分可以是:字母、数字、下划线,最好遵循下述规范:
1.以字母开头
2.使用中划线或者下划线做单词的连接
3.同类型的用数字区分
4.对于文件名的命名最好在末尾加上拓展名
例如: sql_bak.tar.gz,log_bak.tar.bz2
5、不要带有空格、?、*等特殊字符
6、不能使用bash中的关键字,例如if,for,while,do 等
7、不要和系统环境变量冲突
变量值 有三种来源
1、直接赋值
ip1="192.168.10.11"
msg1=$(date)
msg1=`date`
2、通位置参数获取命令行传入的变量值
$0
$1
$2
...
${10}
 (运行命令后直接增加参数 )
(运行命令后直接增加参数 )
3、接收用户输入的变量值
read -p "请输入你的用户名>>>: " name
格式化输出:
echo "my name is name,my age is age"
printf "my name is %s my age is %s\n" name age
预定义变量-特殊符号
\* 可以取到所有命令行传进来的位置参数(不包括0)
@ 可以取到所有命令行传进来的位置参数(不包括0)
区别:
应用该调用: ./2.sh 11 22 33 44 "55 66 77"
应该用:"$@" 可将55 66 77 识别为一个整体

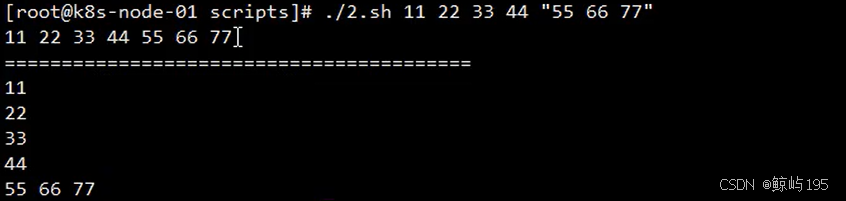
# 获取命令行传进来的位置参数的个数(不包括0)
$$ 获取当前进程自己的pid号
$PPID 获取当前进程的父进程的id号
$? 获取上一条命令的运行成功与否的标志(0代表成功 非0代表失败)
!$ 取上一条命令的参数部分
$! 取上一条命令的进程pid
$*案例:
常量
常量:不变的量
readonly x=111
y=2
readonly x
变量值的类型
为何要有类型
变量值是用来记录事物状态的,而事物的状态是分成多种多样的
例如:年龄、薪资、名字、性别
age=18
salary=3.1
name="egon"
gender="male"
gender="female"
针对不同种类的状态对应着就应该用不同类型的值去记录
补充:
强 类型:数据类型的不可以被忽略,是有明确的边界---》不同类型之间不能直接混用
弱 类型:数据类型的是可以被忽略,没有明确的边界---》不同类型之间有的可以混用
静态类型:定义变量需要声明 变量的类型,即在程序执行之前变量的类型就已经确定下来了 var age int = 18
动态类型: 定义变量不需要声明 变量的类型,即需要在执行到具体代码的时候才能识别变量的类型
age=18
总结:
shell是一门解释型、弱类型、动态语言
python是一门解释型、强类型、动态语言
go是一门编译型型、强类型、静态语言
基本数据类型:
数字
整型
age=10
用于标识:年龄、等级、号码、个数
浮点型
salary=3.1
用于标识:薪资、身高、体重
字符串
定义:在引号内包含一串字符
单引号:硬 引用,会取消掉特殊符号的意义
双引号:软 引用,特殊符号会有意义
msg="hello world"
用于标识:描述性质的状态,名字、国籍、一段话、ip、url地址
数组
什么是数组:
数据就是一系列元素的集合
为何要用数组:
为了把多个值 / 元素汇总到一起,可以非常方便的去取第n个值
数组分成两种
普通数组: 用索引对应值,索引是编号反应的是位置,0代表第一个 -1倒数第一个
四种定义方式:
array1=(111 3.3 "aaaa")
array2=(0=111 2=3.3 1="aaaa")
array40=111
array41=3.3
array42="aaaaaaaa"
array5=(`ls`) -----> ls的结果之间存在空格,符合数组标准,可以直接输入
数组的取值
echo ${array11}
echo ${array12}
echo ${array5-1}
echo ${array5-2}
记录一个人的爱好
hobbies=("read" "play" "music")
echo ${hobbies1}
关联数组 :可以用字符串对应值
declare -A info
info"name"="egon"
info"age"=18
info"gender"="male"
echo ${info"age"}
变量值操作
获取变量长度
已知变量msg='hello world!',请统计出变量中包含的字符数量
方法一:
echo ${#msg}
12
方法二:
echo $msg | wc -L
12
方法三:
echo $msg|awk '{print length}'
12
方法四:
expr length "msg" #length是一个函数,注意因为msg的值有空格,所以msg必须用引号包含
12
切片----复制粘贴
msg="abc def"
echo "${msg:3}" # 从3号索引开始,一直到最后,要带着引号,否则空格符号你看不到
def
echo ${msg**:3:2**} # 从3号索引开始,往后数2个字符
d
echo ${msg::3} # 从0开始,往后数3个字符
abc
截断
=================》一、砍掉左边的字符《=================
1.1 简单使用
url="www.sina.com.cn"
echo ${url**#**www.}
1.2 结合*=》非贪婪,默认情况下*是非贪婪,尽可能地少"吃"字符
echo ${url**#*w} # 碰到第二个** 就停
1.3 结合*=》贪婪,尽可能地多"吃"字符
echo ${url**##*w} # *会尽可能多地吃掉字符,一直匹配到最远的**那个w才停下来
.sina.com.cn
=================》二、砍掉右边的字符《=================
1.1 简单使用
url="www.sina.com.cn"
echo ${url**%**.cn}
1.2 结合*=》非贪婪
root@egon \~# echo ${url%.*}
1.3 结合*=》贪婪
root@egon \~# echo ${url%%.*}
www
内容替换
url="www.sina.com.cn"
echo ${url/sina/baidu} # 变量名/被替换内容/替换内容
echo ${url**/**n/N} # 一个
echo ${url**//**n/N} # 贪婪 全部
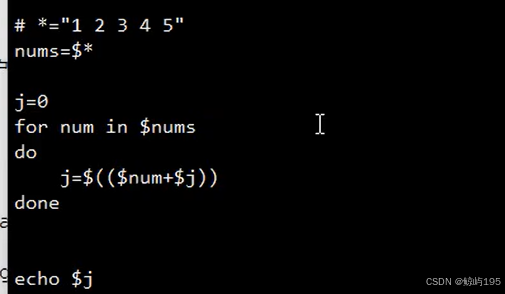
let
(1) 变量的值
j=1
let ++j
echo $j
2
(2) 表达式的值
i=1
j=1
let x=i++ # 先把i赋值给x,然后再++
let y=++j # 先++j,然后再把j的结果赋值给y
作用域: (在什么地方会被看到)
环境变量: 在当前shell及子shell生效(生效于整个环境)
全局变量: export 当前位置及其子子孙孙(其他终端中看不到)
自定义变量:仅在当前shell生效
set # 查看所有变量
env # 查看环境变量
shell接受指令方式不同-------交互式与非交互式shell
进入shell环境的方式--------登陆式与非登录式shell -----> 都会加载 /etc/bashrc
登录shell /etc/profile----在此配置文件中加入 export 变量= .... ---->在每次起bash时都会自动运行,所以改为了环境变量
bash ... 再起一个bash在其中运行命令 (非登陆式shell)
source ... 在本bash运行命令
三、引号


"" 软引用 特殊符号有自己的意义
'' 硬引用 不识别特殊符号的作用
-e \n 换行 \t 占位制表符
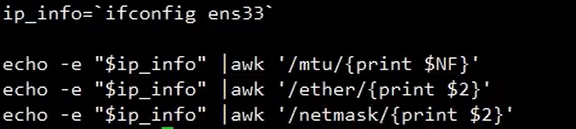
`` 取命令的运行结果 (不用每次取值都进行查询)
引号的嵌套

四、元字符
运算
bc # 支持浮点运算
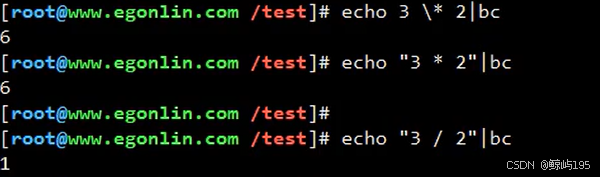
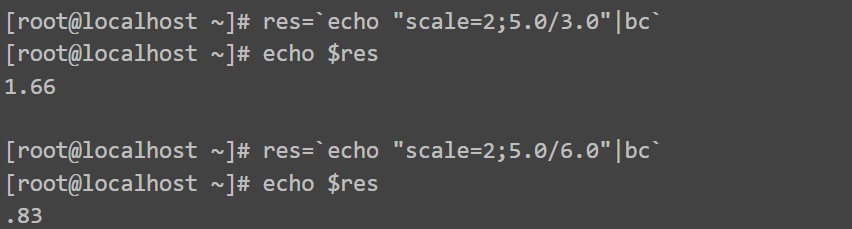
保留两位,不四舍五入
expr(不支持浮点数)
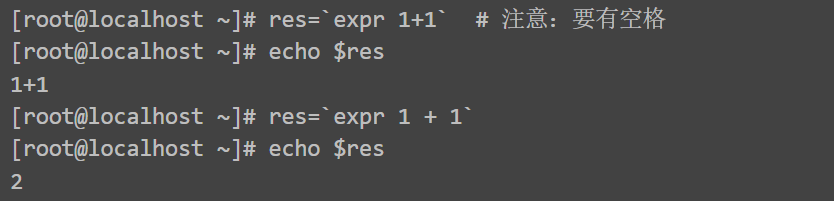
(()) \[\] # echo $(((5-3)*2)) # 不支持浮点运算
expr 判断是否为整数----特殊用法
测试
test -d /etc/ ; echo $? # -s文件非空 -w可写 -r可读 -x可执行 -d目录 -f 普通文件
-d /etc ; echo ? # \[\]左右内测要有空格 **? 值为0--->正确 值为1---->错误**
"aaa" != "aaa" ;echo $? test "a" = "a" #字符串是否相同 (**==**也可以)
-z字符串长度为0 -n字符串长不为0
####关于字符串的测试,一定要给字符串加上引号

10 -eq 10 ;echo $? # 测试数值
0
10 -eq 10 -a 10 \> 3 ;echo $?
0
$(id -u) -eq 0 && echo "当前是超级用户" || echo "you不是超级用户"
当前是超级用户
####-a -o 等同于 && ||

浮点数比大小
需要注意的是:bc的结果为1代表真,为0代表假
root@egon \~# echo "10.3 >= 10.1" | bc
1
root@egon \~# echo "10.3 != 10.1" | bc
1
root@egon \~# echo "10.3 != 10.3" | bc
0
关系运算符 配合 (( ))
**(())--->可以做整数运算,也可以做判断(最好判断数字,字符串还是用test或则 )**不支持浮点数
x=100
(($x>10))
echo $?
0
((x \< 10));echo ?
1
((x == 100));echo ?
0
赋值运算符
x=10
echo $x
10
x=10
((x%3))
echo $x
10
((x%=3))
echo $x
1
*= /= %= 同上
其他
$\[\] # 整数运算
$(()) # 整数运算
$() # 取命令结果
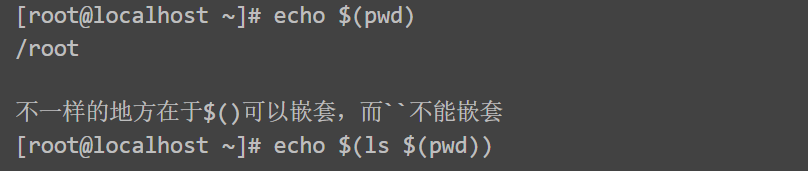
与\[ ] 用法基本一致,\[ ]支持正则匹配(内侧加空格)
\[ "$USER" == "root" ];echo $? # 注意内层\[\]中包含的内容必须左右两侧加空格
0
此外\[]内部是可以使用正则的,注意:正则表达式不要加引号
num1=123
\[ "$num1" =\~ \^\[0-9+ \]\];echo ? # 判断是否是数字
0
\[ "$num1" =\~ \^\[0-9+$ ]] && echo "是数字"
是数字
^0-9+$ 以数字开头 一直以数字循环 结尾为数字
^0-9+a-z$ 以数字开头 一直以数字循环 结尾为字母
^0-9+a-z+$ 以数字开头 先以数字循环在以字母循环 结尾为字母
!与 ^ ----->取反
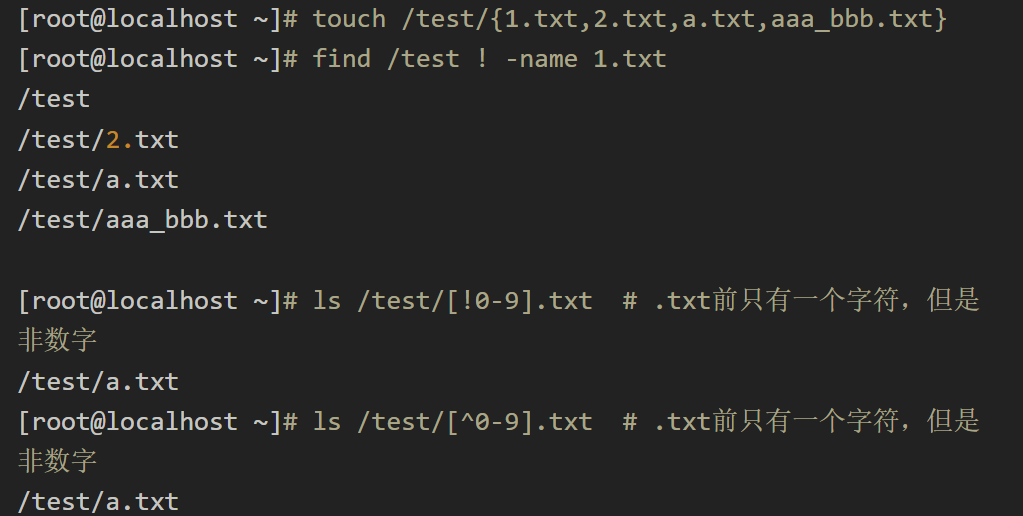
\[\] #不加空格 逐个取值
0-3 0 1 2 3 arvgba a r v g b
root@localhost \~# touch a1c a2c axc aXc axd
root@localhost \~# ls a?c
a1c a2c axc aXc
root@localhost \~# ls a1xc
a1c axc
root@localhost \~# ls aa-zc
axc aXc
root@localhost \~# ls aA-Zc # 不区分大小写
axc aXc
root@localhost \~# ls axc
axc
root@localhost \~# ls aXc
aXc
root@localhost \~# ls a0-9c
a1c a2c
root@localhost \~# ls /dev/sda-z*
/dev/sda /dev/sda1 /dev/sda2 /dev/sda3 /dev/sdb1
@分隔符
$ 取变量值
& # 在最后 后台运行 # 在&>..... 表示同时写入正确输出和错误输出(文件描述符)
() #在子shell 中执行 当前shell不显示
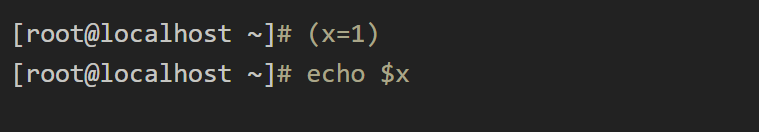
= 赋值 == 判断相等性
\ 转义特殊字符

; && ||
root@localhost home# gagaga**;**ls # 不论前一条命令运行成功与否,都会执行后续命令
bash: gagaga: 未找到命令...
egon
root@localhost home# gagaga && ls # 只有前一条命令执行成功,才会执行后续命令
bash: gagaga: 未找到命令...
root@localhost home# ls /test || mkdir /test # 前一条命令执行不成功才会执行后续命令
0.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt
? 任意一个字符 * 任意多个字符
**{ }**执行一组命令 **;**不论成功与否继续执行

``与$()
` ` 命令替换 等价于 $() 反引号中的shell命令会被先执行
root@localhost \~# touch `date +%F`_file1.txt
root@localhost \~# touch $(date +%F)_file2.txt
root@localhost \~# disk_free3="df -Ph |grep '/' \|awk '{print 4}'" # 错误
root@localhost \~# disk_free4=(df -Ph \|grep '/' |awk '{print $4}') # 正确
root@localhost \~# disk_free5=`df -Ph |grep '/' \|awk '{print 4}'` # 正确
流程控制
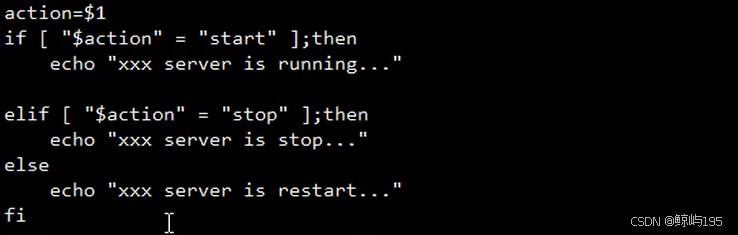
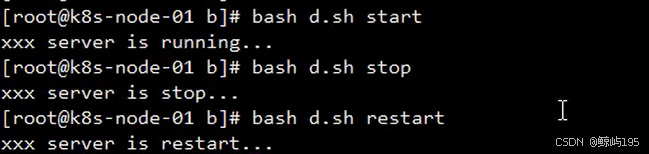
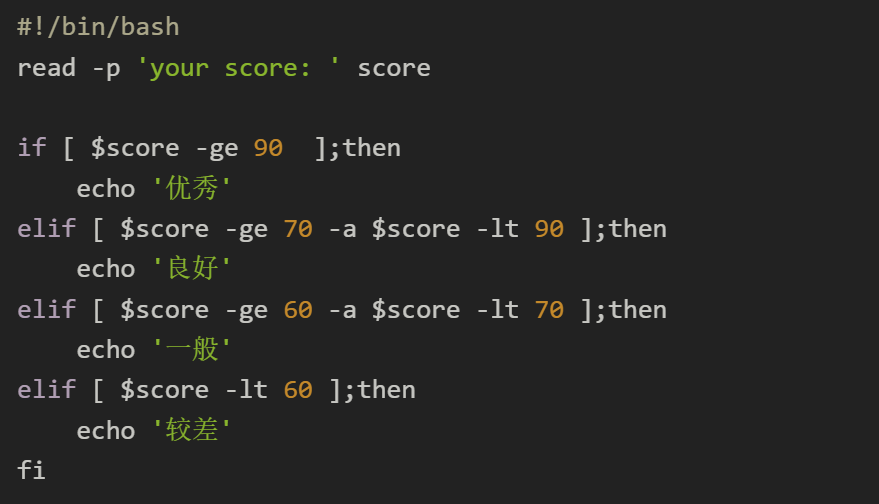
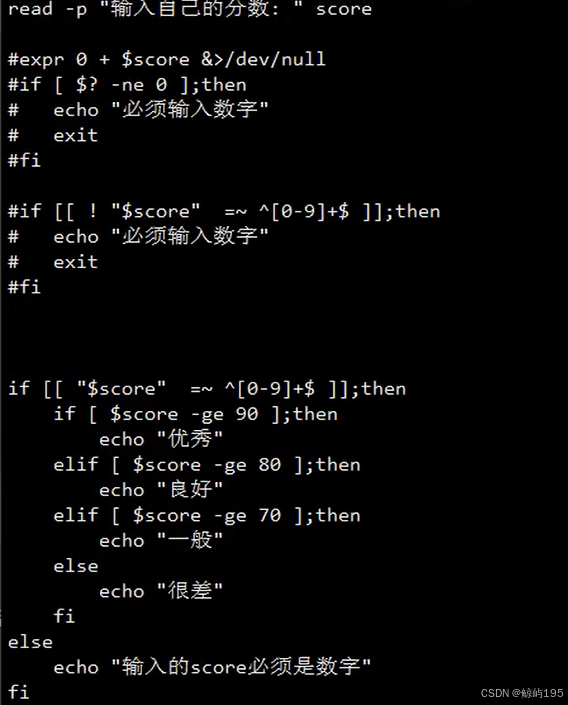
if
if 条件;then
要执行的命令1
要执行的命令2
...
elif 条件;then
要执行的命令1
要执行的命令2
...
elif 条件;then
要执行的命令1
要执行的命令2
...
...
else
要执行的命令1
要执行的命令2
...
fi
read -p "请输入用户名" name
read -p "请输入密码" password
if "$name" = "egon" && "$password" = "123" ;then
echo "用户登录成功"
else
echo "用户登录失败"
fi
for循环
#===========》Shell风格语法
for 变量名 in 取值列表
do
循环体
done
#===========》C语言风格语法
for ((初值;条件;步长))
do
循环体
done
循环次数
for i in `seq 1 3`; # for i in {1..3}
do
echo $i
done
for i in {1..3};
do
echo $i
done
案例
for i in `ls /test`;
do
echo i \|grep "txt" &>/dev/null
if $? -eq 0 ;then
#echo "$i 是txt结尾"
mv /test/i /test/{i}_bak
else
echo "$i 不是txt结尾"
fi
for i in {1..255}
do
(ip_addr="192.168.71.$i"
ping -c1 $ip_addr &>/dev/null
if $? -eq 0 ;then
echo "$ip_addr -------------- ok" >> /tmp/ip.log
else
echo "$ip_addr -------------- no" >> /tmp/ip.log
fi) &
done #写成一条命令放入后台提高运行速度
while循环
一、while语句结构:条件为真时,执行循环体代码
while 条件
do
循环体
done
二、until语法结构:条件为假时,一直执行循环体代码,直到条件变为真
until 条件
do
循环体
done
continue:默认退出本次循环
break:默认退出本层循环
案例:监控web页面状态信息,失败三次进行报警
cat f.sh
#!/bin/bash
timeout=3
fails=0
url=$1
while true
do
wget --timeout=timeout --tries=1 url -q
curl --connect-timeout timeout url &>/dev/null
if $? -ne 0
then
let fails++
echo "错误次数=====>$fails"
else
echo "页面访问成功"
break
fi
if $fails -eq 3
then
echo "失败3次,超过最大次数"
break
fi
done
测试:
./f.sh https://www.egon.com
错误次数=====>1
错误次数=====>2
错误次数=====>3
失败3次,超过最大次数
case (不常用 = if)
case 变量 in
模式1)
命令序列1
;;
模式2)
命令序列2
;;
模式3)
命令序列3
;;
*)
无匹配后命令序列
esac
#!/bin/bash
read -p "username: " -t 5 username
echo
if -z $username ;then
username="default"
fi
case $username in
root)
echo "管理员用户"
;;
user)
echo "普通用户"
;;
default)
echo "默认用户"
;;
*)
echo "其他用户"
esac