上一节 Moddle 的讲解中,已经清楚了 bpmn-js 在 编辑图形的过程中 是通过什么方式来规定每个元素与属性的合法性的,知道了我们所说的 属性描述对象 descriptor json 到底是一个什么结构。
而从关系图中,bpmn-js 是依赖 bpmn-moddle 来处理 xml 的,而 bpmn-moddle 又依赖 moddle 与 moddle-xml。既然上一节 moddle 掌握了,那么这一节就直接进入 moddle-xml 和 bpmn-moddle。
moddle-xml - Read and write XML documents described with moddle
官方给这个仓库的定义就是 "一个用来根据 moddle 定义读写 xml 文档" 的库。
moddle-xml 对外提供了两个工具:Reader 与 Writer,分别用来解析 xml 和生成 xml。
而 Reader 的解析,则是依赖了另外一个库 ------ saxen。
Saxen - A tiny, super fast, namespace aware sax-style XML parser written in plain JavaScript.
saxen,是由 bpmn-io 团队核心成员 nikku 根据 vflash/easysax 修改之后的一个 xml 解析库,其特点是:可解析 namespace 命名空间、代码量小、解析速度快等。
当然,由于相对于其他解析库,saxen 在代码量以及解析速度上得到了提升,但是也缺少了 text trimming 文本修剪、entity decoding 实体解码等;但是这些在 BPMN 关联业务中没有特别明显的使用需求,所以影响不大。

saxen 对外提供了两个模块:Parser 构造函数与 decode 工具函数。
decode 函数 - 解析实体编码返回原始字符
decode 解码函数,主要作用就是 通过 string 字符串的 repalce 函数,将字符串中的 HTML 实体字符串转换为原来的字符。
在这个文件中,先定义了 一个实体字符串的匹配正则 ENTITY_PATTERN 和一个实体与原字符的对应关系 ENTITY_MAPPING。
js
var ENTITY_PATTERN = /&#(\d+);|&#x([0-9a-f]+);|&(\w+);/ig;
var ENTITY_MAPPING = {
'amp': '&',
'apos': '\'',
'gt': '>',
'lt': '<',
'quot': '"'
};
// map UPPERCASE variants of supported special chars
Object.keys(ENTITY_MAPPING).forEach(function(k) {
ENTITY_MAPPING[k.toUpperCase()] = ENTITY_MAPPING[k];
});也就是说,在转换后的 xml 字符串中,遇到 &、 &、 > 等字符串,都会转换成 &, > 等对应字符(正则表达式确认的匹配规则是必须以 & 作为开头)。
当然,具体的替换规则还是在 decode 相关的方法:
js
var fromCharCode = String.fromCharCode;
var hasOwnProperty = Object.prototype.hasOwnProperty;
function replaceEntities(_, d, x, z) {
if (z) {
if (hasOwnProperty.call(ENTITY_MAPPING, z)) {
return ENTITY_MAPPING[z];
} else {
return '&' + z + ';';
}
}
if (d) {
return fromCharCode(d);
}
return fromCharCode(parseInt(x, 16));
}
export default function decodeEntities(s) {
if (s.length > 3 && s.indexOf('&') !== -1) {
return s.replace(ENTITY_PATTERN, replaceEntities);
}
return s;
}在默认导出的 decodeEntities 方法中,本质就是判断字符串是否需要进行解析,然后在需要解析的时候返回解析后的结果,否则返回原字符串,核心还是在 replaceEntities 方法。
根据 MDN/String.prototype.replace() 的描述,replaceEntities 的函数参数与正则表达式结构有关。而原来的 ENTITY_PATTERN 经过分解,会分为三个分组:
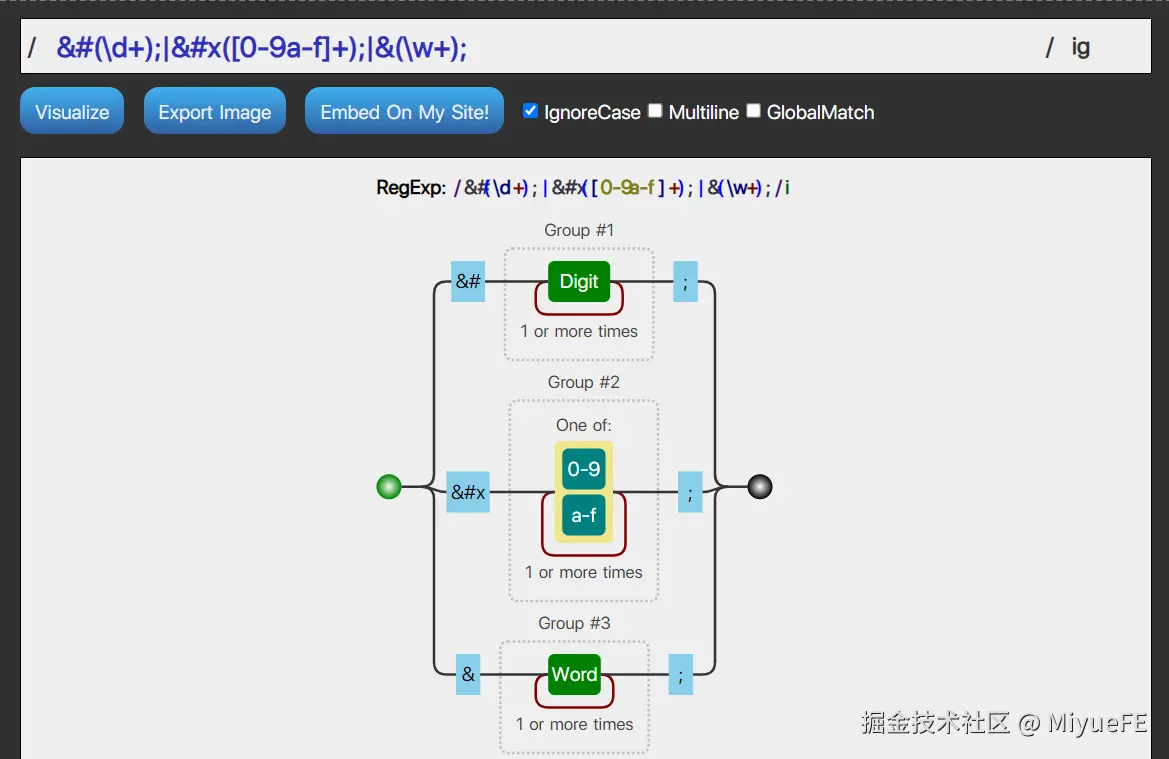
- 第一组为 匹配
&#开头且以分号;结尾,中间包含一个数字以上 ,将内部数字作为替换方法中的第二个参数d - 第二组为 匹配
&#x开头且以分号;结尾,中间包含一个或以上任意数字字母 ,将内部数字 + 字母作为替换方法中的第三个参数x - 第三组为 匹配
&开头且以;结尾,中间包含一个或及以上英文单词 ,将内部字符串作为替换方法中的第三个参数z
然后,replaceEntities 会区分以上三种情况分别进行处理:
- 第三组匹配时,
z不为空,则判断是否是ENTITY_MAPPING中的某个实体,是则返回对应的字符,不是则按初始状态返回(拼接回&与分号) - 第一组匹配时,则表示是 10 进制的数据,通过
fromCharCode将其转换为 UTF-16 码元序列字符串 - 以上两组都不匹配时,默认为 16 进制数据,则通过
parseInt将其转换回 16 进制之后再通过fromCharCode转换为 UTF-16 码元序列字符串
例如,我们有这样一个字符串:const encoded = "&'><"&Quot;"'&{İ>>&constructor;&#NaN;"
通过 decodeEntities(encoded),我们会得到这样一个结果:"&'><"&Quot;"'&{İ>>&constructor;&#NaN;"
对应如下:
text
& => &
' => '
> => >
< => <
" => "
&Quot; => &Quot;
" => "
' => '
& => &
{ => {
İ => İ
>> => >>
&constructor; => &constructor;
&#NaN; => &#NaN;Parser - 解析器
该构造函数作为解析 xml 字符串的核心,主要就是提供一个 parse 方法,接收一个 字符串 ,开始遍历(并非一个字符一个字符的遍历)字符串的并 触发相关钩子函数。
该函数接收一个 包含 proxy 布尔值的对象参数,用来确定是否开启 代理模式 ;在 Parser 的设计中,parse 方法 主要用于开启 xml 字符串解析,但没有返回值 ,解析结果 需要通过注册 openTag 之类的钩子函数 类自行处理。
在 Parser 中,支持通过 on 方法注册一下钩子函数:
openTag(elementName, attrGetter, decodeEntities, selfClosing, contextGetter)closeTag(elementName, decodeEntities, selfClosing, contextGetter)error(err, contextGetter)warn(warning, contextGetter)text(value, decodeEntities, contextGetter)cdata(value, contextGetter)comment(value, decodeEntities, contextGetter)attention(str, decodeEntities, contextGetter)question(str, contextGetter)
当然,如果开启了代理模式的话,openTag 与 closeTag 会修改为一下形式:
openTag(element, decodeEntities, selfClosing, contextGetter)closeTag(element, selfClosing, contextGetter)
代理模式下,第一个参数是一个对象,包含
name, originalName, attrs, ns四个属性。另外:
selfClosing是一个自闭合标签的标识字段,contextGetter则是 当前解析内容在xml中所处的位置和原始文本信息,这个常常用来进行错误信息提示,后面会省略这部分的说明。
Parser 构造函数,默认只提供了 4 个实例方法。
ns:接收一个命名空间与前缀的对应关系对象nsMap,将其保存在构造函数的闭包对象nsUriToPrefix中,以供后续解析使用parse:接收一个xml字符串,然后开启解析on:接收一个生命周期钩子的名称与对应的回调函数,注册对应的生命周期钩子stop:停止解析
在实际的解析过程中,我们一般会通过 栈 的形式来保存和处理当前解析到的元素,通过
openTag入栈,通过closeTag出栈,这样能保证在解析一个合法的xml时能正确的保存解析结果。而
warn和error则是在解析出现异常时,用来保存解析到的错误信息并抛出错误;或者在严重时终止执行。
text与cdata大部分情况下用来解析标签属性或者特殊标识,将其进行正确的编码解码;comment和question等在正常的业务中,通常只是用来进行说明或者标注,并不会影响xml的实际业务,所以不用处理也不会有太大影响。
Parser.parse - 开始 xml 解析
parse 方法,整个代码的长度大约有 700 行,已经算是一个比较复杂的函数了。
但是该方法的核心还是比较容易理解的:通过定义两个下标 i 和 j,通过 匹配第一个尖括号 < 来开始遍历 ,然后根据 尖括号后面的第一个字符 w 来进行分类。
w, q等字符都已经通过String.proptotype.charCodeAt进行了转码。
-
w === 33,代表是<!,此时会区分w后一个字符qq === 91且 前几位是CDATA[,则调用CDATA对应的钩子函数on('cdata', cb)将参数进行解析后调用cb(如果末尾没有]]的结束符,则会抛出异常)q === 45且q后一位也是45,表示<--注释,此时触发on('comment', cb)对应的钩子函数
-
w === 63,代表<?,作为一个问题标签进行解析,此时触发on('question', cb)对应的钩子函数
以上几种情况,都会在判断里面 首先查找对应的结束标志,例如
CDATA对应]], 注释节点<--对应-->等,找到之后会记录结束标志的下标来更新之前的位置记录变量j,然后跳出当前循环。如果都不满足以上情况,则会开始循环
i后的剩余字符,从第一个字符v = xml.charCodeAt(i+1)开始(也就是尖括号<之后的第一个字符),开始解析引号的匹配关系,作为后续的 标签属性 来处理;直到解析到反括号>停止循环,记录反括号下标j
-
w === 33,代表<!,但是这时已经是非CDATA或者注释节点的情况,此时触发on('attention', cb)对应的钩子函数 -
w === 47,则表示</,意思是解析到了 结束标签 ,此时会设置一个标志位tagEnd = true,并且将栈顶元素取出与当前解析到的标签名进行匹配,确定是否是同一个标签 -
如果以上都不满足,则进入
else部分,这里也会区分几种情况- 解析出来结尾是
/>,则是自闭合标签,设置标志位tagStart = tagEnd = true - 否则设置标志位
tagStart = true; tagEnd = false
并且会记录下标签名,然后会 验证标签名的合法性(只能以字母、下划线、英文冒号作为开头)。
然后,则是 按空格或者特殊标识(
\f\n\r\t\v)划分,找到真正的标签名 ,当tagEnd为true时,还会将这个标签名 插入到栈中。 - 解析出来结尾是
然后,则会根据 namespace 对属性进行 前缀补充 等操作。
最后,会根据 tagStart、tagEnd 的情况分别触发 on('openTag', cb) 和 on('endTag', cb) 对应的回调函数。
这个过程就是 对单个标签内容的匹配和解析 ,结束之后,还会继续解析 xml 字符串的剩余内容。
当 每次循环开始的时候 ,都会 判断剩余内容是否还有 < 尖括号 ,如果 没有尖括号,但是栈内还有元素的话,则说明 xml 结构有问题 ;如果 存在尖括号标识的起始标签,但是又存在外部的文本的话 ,则会抛出异常 non-whitespace outside of root node;最后则是 标签内部的文本内容 ,会解析出来通过 on('text', cb) 触发文本对应的回调。
大致的一些解析情况如下:
js
parser.parse(`<div></div>`) ✅
parser.parse(`<doc><element id="sample>error"></element></doc>`) ✅
parser.parse(`<doc> \n<element id="sample>error" > \n </element></doc>`) ✅
parser.parse(`\n\x01asdasd`) // Error: missing start tag
parser.parse(`</a>`) // Error: missing open tag
parser.parse(`<!-- HELLO`) // Error: unclosed comment
parser.parse(`<open /`) // Error: unclosed tag
parser.parse(`<=div></=div>`) // Error: illegal first char nodeName
parser.parse(`<div=></div=>`) // Error: illegal first char nodeName
parser.parse(`<a><b></c></b></a>`) // Error: closing tag mismatch
parser.parse(`<root></rof</root>`) // Error: closing tag mismatch
parser.parse(`<root><foo>`) // Error: unexpected end of file
parser.parse(`a<root />`) // Error: non-whitespace outside of root node
parser.parse(`<root />a`) // Error: non-whitespace outside of root node
parser.parse(`<a$uri:foo xmlns:a$uri="http://not-atom" />`) // Error: invalid nodeName尝试解析一个 xml
在了解了 parse 方法如何解析之后了,我们就可以尝试来解析一个 xml 字符串了。
在上文中,说过 parse 方法没有返回值,全靠遍历过程中触发对应的钩子函数来解析字符串,所以我们也需要通过这种方式来实现一个 xml 的基础解析工具。
假设现在有如下的 xml:
xml
<?xml version="1.0" encoding="UTF-8"?>
<bpmn:definitions
xmlns:bpmn="http://www.omg.org/spec/BPMN/20100524/MODEL"
xmlns:bpmndi="http://www.omg.org/spec/BPMN/20100524/DI"
xmlns:di="http://www.omg.org/spec/DD/20100524/DI"
xmlns:dc="http://www.omg.org/spec/DD/20100524/DC"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
id="Definitions_1"
targetNamespace="http://bpmn.io/schema/bpmn"
exporter="Camunda Modeler"
exporterVersion="1.5.0-nightly">
<bpmn:process id="Process_1" isExecutable="false">
<bpmn:exclusiveGateway id="ExclusiveGateway_0loxwm5">
<bpmn:outgoing>SequenceFlow_06jpd22</bpmn:outgoing>
</bpmn:exclusiveGateway>
<bpmn:task id="Task_1bs98ro">
<bpmn:incoming>SequenceFlow_06jpd22</bpmn:incoming>
<bpmn:multiInstanceLoopCharacteristics>
<bpmn:loopCardinality>10</bpmn:loopCardinality>
<bpmn:completionCondition>${true}</bpmn:completionCondition>
</bpmn:multiInstanceLoopCharacteristics>
</bpmn:task>
<bpmn:sequenceFlow id="SequenceFlow_06jpd22" name="" sourceRef="ExclusiveGateway_0loxwm5" targetRef="Task_1bs98ro">
<bpmn:conditionExpression>${foo}</bpmn:conditionExpression>
</bpmn:sequenceFlow>
</bpmn:process>
<bpmndi:BPMNDiagram id="BPMNDiagram_1">
<bpmndi:BPMNPlane id="BPMNPlane_1" bpmnElement="Process_1">
<bpmndi:BPMNShape id="ExclusiveGateway_0loxwm5_di" bpmnElement="ExclusiveGateway_0loxwm5" isMarkerVisible="true">
<dc:Bounds x="127" y="152" width="50" height="50" />
<bpmndi:BPMNLabel>
<dc:Bounds x="152" y="207" width="0" height="0" />
</bpmndi:BPMNLabel>
</bpmndi:BPMNShape>
<bpmndi:BPMNShape id="Task_1bs98ro_di" bpmnElement="Task_1bs98ro">
<dc:Bounds x="281" y="137" width="100" height="80" />
</bpmndi:BPMNShape>
<bpmndi:BPMNEdge id="SequenceFlow_06jpd22_di" bpmnElement="SequenceFlow_06jpd22">
<di:waypoint xsi:type="dc:Point" x="177" y="177" />
<di:waypoint xsi:type="dc:Point" x="216" y="177" />
<di:waypoint xsi:type="dc:Point" x="216" y="177" />
<di:waypoint xsi:type="dc:Point" x="281" y="177" />
<bpmndi:BPMNLabel>
<dc:Bounds x="231" y="177" width="0" height="0" />
</bpmndi:BPMNLabel>
</bpmndi:BPMNEdge>
</bpmndi:BPMNPlane>
</bpmndi:BPMNDiagram>
</bpmn:definitions>这是导出的一个简易的流程图文件。
那么第一步,我们需要定义一个 栈,用来保存和匹配解析到的元素。
js
export function createStack() {
const stack = []
Object.defineProperty(stack, 'peek', {
value: function () {
return this[this.length - 1]
}
})
return stack
}这里设置的一个属性 peek,用来获取 栈顶 元素。
然后,我们可以通过 createStack 方法创建一个栈。但是此时需要注意的是,我们 xml 元素是 存在父子关系 的,所以我们可以 通过对象变量赋值时共享引用地址 的方式,将栈元素都设置为对象,并且 通过设置 children 对象数组属性,将栈内的元素按顺序进行关联。
代码如下:
js
const stack = createStack()
// 解析到开始类标签
function handleOpen(node) {
try {
let handler = stack.peek()
if (!handler) {
stack[0] = node // 为 undefined 时说明栈内为空,直接赋值第一个元素
} else {
// 再次解析到开始标签时,说明这个标签是上一个标签的子节点,则直接插入到上一个元素的 children 数组中
!handler.children && (handler.children = [])
handler.children.push(node)
}
// 向 栈中 插入该元素
stack.push(node)
} catch (err) {
console.log(err)
}
}
// 解析到结束标签时,直接出栈
function handleClose() {
stack.pop()
}
// 解析到文字时,说明是标签内文本,直接设置为栈顶元素的 body 属性
function handleText(text) {
// 去除空格
if (!text.trim()) {
return
}
const element = stack.peek()
element.body = text
}然后,就可以初始化一个 Parser 实例并注册相应的解析钩子函数了。
js
const proxy = false
const xmlParser = new Parser({ proxy })
// 默认的命名空间
xmlParser.ns({
'http://www.omg.org/spec/BPMN/20100524/MODEL': 'bpmn',
'http://www.omg.org/spec/BPMN/20100524/DI': 'bpmndi',
'http://www.omg.org/spec/DD/20100524/DI': 'di',
'http://www.omg.org/spec/DD/20100524/DC': 'dc',
'http://www.w3.org/2001/XMLSchema-instance': 'xsi'
})
xmlParser
.on('openTag', onOpenTag)
.on('closeTag', handleClose)
.on('text', function (text, decodeEntities, getContext) {
handleText(decodeEntities(text), getContext)
})值得注意的是,这里的 openTag 对应的钩子函数,其实需要区分 proxy 来设置不同的参数处理:
js
const onOpenTag = proxy
? function (obj, decodeStr, selfClosing, getContext) {
const attrs = obj.attrs || {}
const decodedAttrs = Object.keys(attrs).reduce(function (d, key) {
d[key] = decodeStr(attrs[key])
return d
}, {})
const node = {
name: obj.name,
originalName: obj.originalName,
attributes: decodedAttrs,
ns: obj.ns
}
handleOpen(node, getContext)
}
: function (elementName, attrGetter, decodeEntities, selfClosing, getContext) {
const attrs = attrGetter()
const decodedAttrs = Object.keys(attrs).reduce(function (d, key) {
d[key] = decodeEntities(attrs[key])
return d
}, {})
const node = {
elementName,
attributes: decodedAttrs
}
handleOpen(node, getContext)
}两种方式对应的处理结果也会有部分区别:

这里因为只是 示例,所以两侧的结果看起来只是属性多少的问题,差异并不是很大。
但是在
moddle-xml中,针对不同的命名空间有不同的操作,所以基本上都会使用代理模式,读取到对应的命名空间对象来进行二次处理。
moddle-xml
作为专为 bpmn-io 团队内部的一些项目做支撑的库,moddle-xml 在 saxen 的基础上,通过 moddle 来实现 xml 字符串内容的标准化解析。
所以官方给这个仓库的定义就是:"XML import/export for documents described with moddle",意为 "根据 moddle 类型描述来实现 xml 的 解析和生成"。
既然支持 解析和生成 ,那么 moddle-xml 肯定就需要提供不同的方法来分别实现 xml 解析与生成 xml,所以它导出了两个模块(类):Reader 和 Writer。其中 Reader 负责解析,Writer 负责生成。
Reader - A reader for a meta-model
Reader 类本身依赖于 Moddle 模块,提供一个 fromXML 方法来解析 xml 字符串。
在初始化时,Reader 接受一个包含 Moddle 实例的配置参数 options:
typescript
type Options = Moddle | { model: Moddle, lax?: boolean }
export function Reader(options: Options) {
if (options instanceof Moddle) {
options = {
model: options
};
}
assign(this, { lax: false }, options);
}当然,在开始解析 formXML 方法之前,我们做一些准备工作。
common.js ------ 常量与工具函数
js
export function hasLowerCaseAlias(pkg) {
return pkg.xml && pkg.xml.tagAlias === 'lowerCase';
}
export var DEFAULT_NS_MAP = {
'xsi': 'http://www.w3.org/2001/XMLSchema-instance',
'xml': 'http://www.w3.org/XML/1998/namespace'
};
export var SERIALIZE_PROPERTY = 'property';
export function getSerialization(element) {
return element.xml && element.xml.serialize;
}
export function getSerializationType(element) {
const type = getSerialization(element);
return type !== SERIALIZE_PROPERTY && (type || null);
}在这个文件中,定义了一个默认的命名空间对象 DEFAULT_NS_MAP 和一个 序列化属性标识 SERIALIZE_PROPERTY,以及一个 小写驼峰的判断方法 hasLowerCaseAlias 和元素序列化类型判断的方法 getSerializationType。
Handlers ------ 不同的元素/属性的处理程序
在开始解析之前,Reader 定义了很多的 Handler 构造函数,用来处理不同的元素/属性,以及一个 Context 构造函数,用来记录解析过程中的上下文:
js
export function Context(options) {
assign(this, options);
this.elementsById = {};
this.references = [];
this.warnings = [];
// 添加未解析到的引用
this.addReference = function(reference) {
this.references.push(reference);
};
// 添加已解析的元素
this.addElement = function(element) {
if (!element) {
throw error('expected element');
}
var elementsById = this.elementsById;
var descriptor = getModdleDescriptor(element);
var idProperty = descriptor.idProperty,
id;
if (idProperty) {
id = element.get(idProperty.name);
if (id) {
if (!/^([a-z][\w-.]*:)?[a-z_][\w-.]*$/i.test(id)) {
throw new Error('illegal ID <' + id + '>');
}
if (elementsById[id]) {
throw error('duplicate ID <' + id + '>');
}
elementsById[id] = element;
}
}
};
// 插入警告信息
this.addWarning = function(warning) {
this.warnings.push(warning);
};
}
// 基础的抽象 Handler
function BaseHandler() {}
BaseHandler.prototype.handleEnd = function() {};
BaseHandler.prototype.handleText = function() {};
BaseHandler.prototype.handleNode = function() {};
// 一个简单的传递处理程序,除了忽略它接收的所有输入之外什么也不做。用于忽略未知的元素和属性
function NoopHandler() { }
NoopHandler.prototype = Object.create(BaseHandler.prototype);
NoopHandler.prototype.handleNode = function() {
return this;
};
// 标签内部的文本处理
function BodyHandler() {}
BodyHandler.prototype = Object.create(BaseHandler.prototype);
BodyHandler.prototype.handleText = function(text) {
this.body = (this.body || '') + text;
};
// 元素引用类型属性的处理程序
function ReferenceHandler(property, context) {
this.property = property;
this.context = context;
}
ReferenceHandler.prototype = Object.create(BodyHandler.prototype);
ReferenceHandler.prototype.handleNode = function(node) {
if (this.element) {
throw error('expected no sub nodes');
} else {
this.element = this.createReference(node);
}
return this;
};
ReferenceHandler.prototype.handleEnd = function() {
this.element.id = this.body;
};
ReferenceHandler.prototype.createReference = function(node) {
return { property: this.property.ns.name, id: '' };
};
// 最简单的属性值处理程序
function ValueHandler(propertyDesc, element) {
this.element = element;
this.propertyDesc = propertyDesc;
}
ValueHandler.prototype = Object.create(BodyHandler.prototype);
ValueHandler.prototype.handleEnd = function() {
var value = this.body || '',
element = this.element,
propertyDesc = this.propertyDesc;
value = coerceType(propertyDesc.type, value);
if (propertyDesc.isMany) {
element.get(propertyDesc.name).push(value);
} else {
element.set(propertyDesc.name, value);
}
};
// 基础的元素创建程序
function BaseElementHandler() {}
BaseElementHandler.prototype = Object.create(BodyHandler.prototype);
BaseElementHandler.prototype.handleNode = function(node) {
var parser = this,
element = this.element;
if (!element) {
element = this.element = this.createElement(node);
this.context.addElement(element);
} else {
parser = this.handleChild(node);
}
return parser;
};
// 普通的元素处理程序
export function ElementHandler(model, typeName, context) {
this.model = model;
this.type = model.getType(typeName);
this.context = context;
}
ElementHandler.prototype = Object.create(BaseElementHandler.prototype);
ElementHandler.prototype.addReference = function(reference) {
this.context.addReference(reference);
};
ElementHandler.prototype.handleText = function(text) {
var element = this.element,
descriptor = getModdleDescriptor(element),
bodyProperty = descriptor.bodyProperty;
if (!bodyProperty) {
throw error('unexpected body text <' + text + '>');
}
BodyHandler.prototype.handleText.call(this, text);
};
ElementHandler.prototype.handleEnd = function() {
var value = this.body,
element = this.element,
descriptor = getModdleDescriptor(element),
bodyProperty = descriptor.bodyProperty;
if (bodyProperty && value !== undefined) {
value = coerceType(bodyProperty.type, value);
element.set(bodyProperty.name, value);
}
};
ElementHandler.prototype.createElement = function(node) {
var attributes = node.attributes,
Type = this.type,
descriptor = getModdleDescriptor(Type),
context = this.context,
instance = new Type({}),
model = this.model,
propNameNs;
forEach(attributes, function(value, name) {
var prop = descriptor.propertiesByName[name],
values;
if (prop && prop.isReference) {
if (!prop.isMany) {
context.addReference({
element: instance,
property: prop.ns.name,
id: value
});
} else {
values = value.split(' ');
forEach(values, function(v) {
context.addReference({
element: instance,
property: prop.ns.name,
id: v
});
});
}
} else {
if (prop) {
value = coerceType(prop.type, value);
}
else if (name === 'xmlns') {
name = ':' + name;
} else {
propNameNs = parseNameNS(name, descriptor.ns.prefix);
if (model.getPackage(propNameNs.prefix)) {
context.addWarning({
message: 'unknown attribute <' + name + '>',
element: instance,
property: name,
value: value
});
}
}
instance.set(name, value);
}
});
return instance;
};
ElementHandler.prototype.getPropertyForNode = function(node) {
var name = node.name;
var nameNs = parseNameNS(name);
var type = this.type,
model = this.model,
descriptor = getModdleDescriptor(type);
var propertyName = nameNs.name,
property = descriptor.propertiesByName[propertyName];
if (property && !property.isAttr) {
const serializationType = getSerializationType(property);
if (serializationType) {
const elementTypeName = node.attributes[serializationType];
if (elementTypeName) {
const normalizedTypeName = normalizeTypeName(elementTypeName, node.ns, model);
const elementType = model.getType(normalizedTypeName);
return assign({}, property, {
effectiveType: getModdleDescriptor(elementType).name
});
}
}
return property;
}
var pkg = model.getPackage(nameNs.prefix);
if (pkg) {
const elementTypeName = aliasToName(nameNs, pkg);
const elementType = model.getType(elementTypeName);
property = find(descriptor.properties, function(p) {
return !p.isVirtual && !p.isReference && !p.isAttribute && elementType.hasType(p.type);
});
if (property) {
return assign({}, property, {
effectiveType: getModdleDescriptor(elementType).name
});
}
} else {
property = find(descriptor.properties, function(p) {
return !p.isReference && !p.isAttribute && p.type === 'Element';
});
if (property) {
return property;
}
}
throw error('unrecognized element <' + nameNs.name + '>');
};
ElementHandler.prototype.toString = function() {
return 'ElementDescriptor[' + getModdleDescriptor(this.type).name + ']';
};
ElementHandler.prototype.valueHandler = function(propertyDesc, element) {
return new ValueHandler(propertyDesc, element);
};
ElementHandler.prototype.referenceHandler = function(propertyDesc) {
return new ReferenceHandler(propertyDesc, this.context);
};
ElementHandler.prototype.handler = function(type) {
if (type === 'Element') {
return new GenericElementHandler(this.model, type, this.context);
} else {
return new ElementHandler(this.model, type, this.context);
}
};
ElementHandler.prototype.handleChild = function(node) {
var propertyDesc, type, element, childHandler;
propertyDesc = this.getPropertyForNode(node);
element = this.element;
type = propertyDesc.effectiveType || propertyDesc.type;
if (isSimpleType(type)) {
return this.valueHandler(propertyDesc, element);
}
if (propertyDesc.isReference) {
childHandler = this.referenceHandler(propertyDesc).handleNode(node);
} else {
childHandler = this.handler(type).handleNode(node);
}
var newElement = childHandler.element;
if (newElement !== undefined) {
if (propertyDesc.isMany) {
element.get(propertyDesc.name).push(newElement);
} else {
element.set(propertyDesc.name, newElement);
}
if (propertyDesc.isReference) {
assign(newElement, { element: element });
this.context.addReference(newElement);
} else {
newElement.$parent = element;
}
}
return childHandler;
};
// 需要执行特殊验证的元素的处理程序,以确保它初始化的节点与处理程序类型 (命名空间) 匹配
function RootElementHandler(model, typeName, context) {
ElementHandler.call(this, model, typeName, context);
}
RootElementHandler.prototype = Object.create(ElementHandler.prototype);
RootElementHandler.prototype.createElement = function(node) {
var name = node.name,
nameNs = parseNameNS(name),
model = this.model,
type = this.type,
pkg = model.getPackage(nameNs.prefix),
typeName = pkg && aliasToName(nameNs, pkg) || name;
if (!type.hasType(typeName)) {
throw error('unexpected element <' + node.originalName + '>');
}
return ElementHandler.prototype.createElement.call(this, node);
};
// 通用的元素处理程序
function GenericElementHandler(model, typeName, context) {
this.model = model;
this.context = context;
}
GenericElementHandler.prototype = Object.create(BaseElementHandler.prototype);
GenericElementHandler.prototype.createElement = function(node) {
var name = node.name,
ns = parseNameNS(name),
prefix = ns.prefix,
uri = node.ns[prefix + '$uri'],
attributes = node.attributes;
return this.model.createAny(name, uri, attributes);
};
GenericElementHandler.prototype.handleChild = function(node) {
var handler = new GenericElementHandler(this.model, 'Element', this.context).handleNode(node),
element = this.element;
var newElement = handler.element,
children;
if (newElement !== undefined) {
children = element.$children = element.$children || [];
children.push(newElement);
newElement.$parent = element;
}
return handler;
};
GenericElementHandler.prototype.handleEnd = function() {
if (this.body) {
this.element.$body = this.body;
}
};他们之间的继承关系如下:
js
BaseHandler
├── NoopHandler
└── BodyHandler
├── ReferenceHandler
├── ValueHandler
└── BaseElementHandler
├── ElementHandler
│ └── RootElementHandler
└── GenericElementHandlerBaseHandler 作为最基础的处理程序构造函数,定义了三个方法:handleEnd,handleText,handleNode,基于此衍生出去的 Handlers 都根据自身的需要对某一个或者多个函数进行了实现或者重写,但是大家都实现了一个方法,那就是 handleNode,并且返回值都是该 Handler 对应的实例本身(BodyHandler 是个例外,只需要处理标签内部的内容,所以只有一个 handleText 方法)。
而 ElementHandler 则是最复杂的一个处理器,需要同时处理属性、body 文本或者子元素等内容,并且需要确保标签元素解析之后的关系正确。
至于每个 Handler 的具体作用,我们可以结合 formXML 解析方法来介绍。
reader.formXML - 解析 XML 为 JS Object
fromXML 方法,逻辑上就是通过 saxen 的 parse 方法来解析 xml 字符串,通过对 parse 方法不同的钩子注册相应的钩子函数,并通过一个栈来存储和匹配已解析的结果,最后返回解析结果。
当然,这个过程中 栈 并没有作为保存解析标签内容的角色,所以还需要其他的角色来负责这部分工作。这时就引入了上文所说的 Handler 和 Context 了。
js
Reader.prototype.fromXML = function(xml, options, done) {
var rootHandler = options.rootHandler;
if (options instanceof ElementHandler) {
rootHandler = options;
options = {};
} else {
if (typeof options === 'string') {
rootHandler = this.handler(options);
options = {};
} else if (typeof rootHandler === 'string') {
rootHandler = this.handler(rootHandler);
}
}
var model = this.model,
lax = this.lax;
var context = new Context(assign({}, options, { rootHandler: rootHandler })),
parser = new SaxParser({ proxy: true }),
stack = createStack();
rootHandler.context = context;
stack.push(rootHandler);
// 。。。 后续解析过程
}
Reader.prototype.handler = function(name) {
return new RootElementHandler(this.model, name);
};
function createStack() {
var stack = [];
Object.defineProperty(stack, 'peek', {
value: function() {
return this[this.length - 1];
}
});
return stack;
}在 formXML 方法的开头,if 部分主要是用来 校验参数 ,确保 入栈的第一个元素是 ElementHandler 元素处理器 ;然后,则是将这个 rootHandler 对象作为参数初始化一个 context 对象实例,用来 作为解析过程中的上下文内容保存 ,这样在解析完成之后 context 的内容就是所有的解析结果。
最后,就是 初始化一个 stack 栈 ,并将 rootHandler 插入栈中。
然后,需要注册 saxen/Parser 的钩子函数,来处理不同的解析内容。
js
function handleError(err, getContext, lax) {
var ctx = getContext();
var line = ctx.line,
column = ctx.column,
data = ctx.data;
if (data.charAt(0) === '<' && data.indexOf(' ') !== -1) {
data = data.slice(0, data.indexOf(' ')) + '>';
}
var message = '' // 这里省略了错误信息,主要内容包含 err 对象以及 ctx 中的代码位置
if (lax) {
context.addWarning({ message, error: err });
return true;
} else {
throw error(message);
}
}
function handleWarning(err, getContext) {
return handleError(err, getContext, true);
}
// 引用收集
function resolveReferences() {
var elementsById = context.elementsById;
var references = context.references;
var i, r;
for (i = 0; (r = references[i]); i++) {
var element = r.element;
var reference = elementsById[r.id];
var property = getModdleDescriptor(element).propertiesByName[r.property];
if (!reference) {
context.addWarning({
message: 'unresolved reference <' + r.id + '>',
element: r.element,
property: r.property,
value: r.id
});
}
if (property.isMany) {
var collection = element.get(property.name),
idx = collection.indexOf(r);
if (idx === -1) {
idx = collection.length;
}
if (!reference) {
collection.splice(idx, 1); // 无法找到引用时移除
} else {
collection[idx] = reference;
}
} else {
element.set(property.name, reference);
}
}
}
function handleClose() {
stack.pop().handleEnd();
}
var PREAMBLE_START_PATTERN = /^<\?xml /i;
var ENCODING_PATTERN = / encoding="([^"]+)"/i;
var UTF_8_PATTERN = /^utf-8$/i;
function handleQuestion(question) {
if (!PREAMBLE_START_PATTERN.test(question)) {
return;
}
var match = ENCODING_PATTERN.exec(question);
var encoding = match && match[1];
if (!encoding || UTF_8_PATTERN.test(encoding)) {
return;
}
context.addWarning({
message:
'unsupported document encoding <' + encoding + '>, ' +
'falling back to UTF-8'
});
}
function handleOpen(node, getContext) {
var handler = stack.peek();
try {
stack.push(handler.handleNode(node));
} catch (err) {
if (handleError(err, getContext, lax)) {
stack.push(new NoopHandler());
}
}
}
function handleCData(text, getContext) {
try {
stack.peek().handleText(text);
} catch (err) {
handleWarning(err, getContext);
}
}
function handleText(text, getContext) {
if (!text.trim()) {
return;
}
handleCData(text, getContext);
}这里除了 resolveReferences 是用来 解析"引用类型"属性 之外,其他几个方法就分别对应 Parser 的 openTag,question 等几个解析钩子。但是这些 handle 函数参数很明显与钩子对应的回调函数声明有区别,所以钩子回调函数还需要再次处理参数。不过在此之前,还需要注册相应的 namespace map。
js
// common.js
//export var DEFAULT_NS_MAP = {
// 'xsi': 'http://www.w3.org/2001/XMLSchema-instance',
// 'xml': 'http://www.w3.org/XML/1998/namespace'
//};
var uriMap = model.getPackages().reduce(function(uriMap, p) {
uriMap[p.uri] = p.prefix;
return uriMap;
}, Object.entries(DEFAULT_NS_MAP).reduce(function(map, [ prefix, url ]) {
map[url] = prefix;
return map;
}, model.config && model.config.nsMap || {}));
parser
.ns(uriMap)
.on('openTag', function(obj, decodeStr, selfClosing, getContext) {
var attrs = obj.attrs || {};
var decodedAttrs = Object.keys(attrs).reduce(function(d, key) {
var value = decodeStr(attrs[key]);
d[key] = value;
return d;
}, {});
var node = {
name: obj.name,
originalName: obj.originalName,
attributes: decodedAttrs,
ns: obj.ns
};
handleOpen(node, getContext);
})
.on('question', handleQuestion)
.on('closeTag', handleClose)
.on('cdata', handleCData)
.on('text', function(text, decodeEntities, getContext) {
handleText(decodeEntities(text), getContext);
})
.on('error', handleError)
.on('warn', handleWarning);这里的 uriMap,对应的就是 common.js 中的 DEFAULT_NS_MAP 以及上一篇文章中通过 Moddle 初始化时传递的 descriptor json 组成的对象。这里我们以 bpmn-moddle 中的默认声明对象为例:

最终会得到一个这样的 uriMap 对象:
js
{
"http://www.w3.org/2001/XMLSchema-instance": "xsi",
"http://www.w3.org/XML/1998/namespace": "xml",
"http://www.omg.org/spec/BPMN/20100524/MODEL": "bpmn",
"http://www.omg.org/spec/BPMN/20100524/DI": "bpmndi",
"http://www.omg.org/spec/DD/20100524/DC": "dc",
"http://www.omg.org/spec/DD/20100524/DI": "di",
"http://bpmn.io/schema/bpmn/biocolor/1.0": "bioc",
"http://www.omg.org/spec/BPMN/non-normative/color/1.0": "color"
}然后,就是通过 parser.on 方法来注册上文定义好的处理函数;不过这里在 openTag 这个钩子回调函数中,会进行参数处理:
js
parser.on('openTag', function(obj, decodeStr, selfClosing, getContext) {
var attrs = obj.attrs || {};
var decodedAttrs = Object.keys(attrs).reduce(function(d, key) {
var value = decodeStr(attrs[key]);
d[key] = value;
return d;
}, {});
var node = {
name: obj.name,
originalName: obj.originalName,
attributes: decodedAttrs,
ns: obj.ns
};
handleOpen(node, getContext);
})因为 parser 是一个 代理解析器 ,所以回调函数中第一个参数是一个对象,包含 attrs 标签属性对象、name 和 originalName 标签名,ns 命名空间标识。
这里的
attrs属性对象,解析出来的值是 没有经过decode处理的原始值 ,所以这里会 遍历原始attrs对象,分别调用decode方法解析属性值。
然后,才会重新组装好 node 对象,进入 handleOpen 函数。
而 handleQuestion,则是用来 校验文件格式与编码格式,非 utf-8 格式的 xml 标识文件 ,抛出 unsupported document encoding 的错误;至于另外几个处理函数,相对而言比较基础,用到时会说明。
parse(xml) 解析过程
当前面的准备工作完成之后,就会通过 parser.parse 方法开始解析 xml 字符串了。我们假设此时有这样的 xml 与对应的 descriptor json。
js
var xml = '<props:root xmlns:props="http://properties">' +
'<props:containedCollection id="C_5">' +
'<props:complex id="C_1" />' +
'<props:complex id="C_2" />' +
'<props:complex id="C_3" />' +
'</props:containedCollection>' +
'<props:attributeReferenceCollection id="C_4" refs="C_2 C_3 C_5" />' +
'<props:complexAttrsCol xmlns:props="http://properties">' +
'<props:attrs integerValue="10" />' +
'<props:attrs booleanValue="true" />' +
'</props:complexAttrsCol>' +
'</props:root>';
// properties.json
{
"name": "Properties",
"uri": "http://properties",
"prefix": "props",
"xml" : {
"tagAlias": "lowerCase"
},
"types": [
{
"name": "Complex",
"properties": [
{ "name": "id", "type": "String", "isAttr": true, "isId": true },
{ "name": "body", "type": "String", "isBody": true }
]
},
{
"name": "ComplexAttrs",
"superClass": [ "Complex" ],
"properties": [
{ "name": "attrs", "type": "Attributes", "xml": { "serialize" : "xsi:type" } }
]
},
{
"name": "ComplexAttrsCol",
"superClass": [ "BaseWithId" ],
"properties": [
{ "name": "attrs", "type": "Attributes", "isMany": true, "xml": { "serialize" : "xsi:type" } }
]
},
{
"name": "ComplexCount",
"superClass": [ "Complex" ],
"properties": [
{ "name": "count", "type": "Integer", "isAttr": true }
]
},
{
"name": "ComplexNesting",
"superClass": [ "Complex" ],
"properties": [
{ "name": "nested", "type": "Complex", "isMany": true }
]
},
{
"name": "Body"
},
{
"name": "SimpleBody",
"superClass": [ "Base", "Body" ],
"properties": [
{
"name": "body",
"type": "String",
"isBody": true
}
]
},
{
"name": "WithBody",
"superClass": [ "Base" ],
"properties": [
{
"name": "someBody",
"type": "Body",
"xml": { "serialize" : "xsi:type" }
}
]
},
{
"name": "SimpleBodyProperties",
"superClass": [ "Base" ],
"properties": [
{
"name": "intValue",
"type": "Integer"
},
{
"name": "boolValue",
"type": "Boolean"
},
{
"name": "str",
"type": "String",
"isMany": true
}
]
},
{
"name": "WithProperty",
"superClass": [ "Base" ],
"properties": [
{ "name": "propertyName", "type": "Base", "xml": { "serialize" : "property" } }
]
},
{
"name": "Base"
},
{
"name": "BaseWithId",
"superClass": [ "Base" ],
"properties": [
{ "name": "id", "type": "String", "isAttr": true, "isId": true }
]
},
{
"name": "BaseWithNumericId",
"superClass": [ "BaseWithId" ],
"properties": [
{ "name": "idNumeric", "type": "String", "isAttr": true, "redefines": "BaseWithId#id", "isId": true }
]
},
{
"name": "Attributes",
"superClass": [ "BaseWithId" ],
"properties": [
{
"name": "realValue",
"type": "Real",
"isAttr": true
},
{
"name": "integerValue",
"type": "Integer",
"isAttr": true
},
{
"name": "booleanValue",
"type": "Boolean",
"isAttr": true
},
{
"name": "defaultBooleanValue",
"type": "Boolean",
"isAttr": true,
"default": true
}
]
},
{
"name": "SubAttributes",
"superClass": [ "Attributes" ]
},
{
"name": "Root",
"properties": [
{
"name": "any",
"type": "Base",
"isMany": true
},
{
"name": "id",
"type": "String",
"isAttr": true,
"isId": true
}
]
},
{
"name": "Embedding",
"superClass": [ "BaseWithId" ],
"properties": [
{
"name": "embeddedComplex",
"type": "Complex"
}
]
},
{
"name": "ReferencingSingle",
"superClass": [ "BaseWithId" ],
"properties": [
{
"name": "referencedComplex",
"type": "Complex",
"isReference": true,
"isAttr": true
}
]
},
{
"name": "ReferencingCollection",
"superClass": [ "BaseWithId" ],
"properties": [
{
"name": "references",
"type": "Complex",
"isReference": true,
"isMany": true
}
]
},
{
"name": "ContainedCollection",
"superClass": [ "BaseWithId" ],
"properties": [
{
"name": "children",
"type": "Complex",
"isMany": true
}
]
},
{
"name": "AttributeReferenceCollection",
"superClass": [ "BaseWithId" ],
"properties": [
{
"name": "refs",
"type": "Complex",
"isReference": true,
"isMany": true,
"isAttr": true
}
]
}
]
}
// properties-extended.json
{
"name": "Extended",
"uri": "http://extended",
"prefix": "ext",
"xml" : {
"tagAlias": "lowerCase"
},
"types": [
{
"name": "ExtendedComplex",
"superClass": [ "props:ComplexCount" ],
"properties": [
{ "name": "numCount", "type": "Integer", "isAttr": true, "redefines": "props:Complex#count" }
]
},
{
"name": "Root",
"superClass": [ "props:Root" ],
"properties": [
{ "name": "elements", "type": "Base", "isMany": true }
]
},
{
"name": "Base"
},
{
"name": "CABSBase"
}
]
}在解析时,首先需要创建一个 RootElementHandler:
js
const rootHandler = reader.handler('props:Root')这里的 handler() 方法接受一个参数,用来创建一个 RootElementHandler:
js
Reader.prototype.handler = function(name) {
return new RootElementHandler(this.model, name);
};打印如下:

此时的 handler 实例 context 属性是空的,但是绑定了我们的 new Moddle 的实例,所以可以 访问到我们声明的所有类型和属性的具体定义。
但是在 formXML 方法执行过程中,会创建一个 Context 实例绑定到该 handler 实例上:
js
var context = new Context(assign({}, options, { rootHandler: rootHandler })),
parser = new SaxParser({ proxy: true }),
stack = createStack();
rootHandler.context = context;
stack.push(rootHandler);会得到一个这样的 handler 对象:

然后,在 parse(xml) 解析我们示例中的 xml 字符串时,会首先进入到 openTag 对应的钩子回调函数中,此时调用 handleOpen 传递的参数是:
js
node: {
"name": "props:root",
"originalName": "props:root",
"attributes": { "xmlns:props": "http://properties" },
"ns": {
"xml": "xml",
"xml$uri": "http://www.w3.org/XML/1998/namespace",
"props": "props",
"props$uri": "http://properties",
"ext": "ext",
"ext$uri": "http://extended",
"xsi": "xsi",
"xsi$uri": "http://www.w3.org/2001/XMLSchema-instance"
}
}在进入 handleOpen 方法之后,就会 提取栈中的栈顶 handler 实例 ,通过该实例的 handleNode 方法处理当前节点的内容。
RootElementHandler 对应的 handleNode 方法由上文的源码中可知,是继承的 BaseElementHandler 中的方法。该方法会调用 this.createElement(noed) 来创建一个元素实例,并绑定到 this 上作为 this.element 属性。
这里的
this就是上文的RootElementHandler的对应实例。
不过我们需要注意,createElement 方法只在三个地方有定义:
-
ElementHandler:实际上的实例创建逻辑,借助Moddle模块的实例创建方式,构造特定的ModdleElement构造函数来创建,然后通过set方法实现实例属性按照descriptor json的声明来设置的实例的正确位置(不过,需要注意的一点是,这里针对reference引用定义的属性,还是会等到xml解析结束之后再设置真实的引用关系)也就是说,
createElement方法,创建的是node对应的 描述对象propertyDesc.effectiveType类型的一个实例对象,下文会说明。 -
RootElementHandler:会借助Moddle里面的所有类型声明,来校验当前传入的node是否符合我们的定义;符合则会调用ElementHandler的createElement来创建一个实例,否则则会直接抛出一个unexpected element的错误 -
GenericElementHandler:一样是借助Moddle来创建,但是这个方法 只需要命名空间前缀和uri属性 ,然后就会通过model.createAny创建一个带有attrs中所有属性的对象实例
所以当我们解析到 xml 的第一个正常标签,也就是 <props:root> 标签时,会第一次调用 RootElementHandler.prototype.handleNode 方法,并将该方法返回值插入栈中,得到这样的结果:

并且此时栈中的两个元素实际上都是同一个实例 ------ rootHandler。
当 root 标签继续往下解析,会进入 props:containedCollection 标签,此时栈顶元素仍然是 rootHandler,所以进入 handleNode 方法时,this.element 属性存在,会进入 handleChild 方法,并将该方法的返回值直接返回,并作为新的栈元素插入栈顶。
根据上文源码中的
Handler的相关定义,这几个方法都在ElementHandler原型上。
在 handleChild 方法中,会根据我们解析到的该节点的内容 node,借助 Moddle 获取到这个 node.name 对应的元素或者属性描述 propertyDesc,比如这时的 node 对象对应的描述对象就是:
js
propertyDesc = {
"name": "any",
"type": "props:Base",
"isMany": true,
"ns": { "name": "props:any", "prefix": "props", "localName": "any" },
"inherited": true,
"effectiveType": "props:ContainedCollection"
}这个对象包含了 这个标签对应的在上级标签中作为什么属性、以及该标签对应的完整标签名。
然后,会根据 propertyDesc.effectiveType || propertyDesc.type 的值,以及 propertyDesc.isReference ,创建对应的 ValueHandler、ReferenceHandler、ElementHandler 或者 GenericElementHandler 的实例 childHandler。
当实例创建完成,会调用 childHandler.handleNode(node) 来借助 Moddle 实例创建一个 node 对象对应的 element 实例作为 childHandler.element 属性(与 rootHandler.handleNode 类似)来指向该标签的解析结果,当然如果是 ValueHandler 的实例的话,element 这里是 undefined。
当 childHandler.element 存在时,则根据 propertyDesc 中的配置,将其设置为 上级节点对应属性的内容,并设置 $parent 属性指向上级节点实例 ,这里就会设置为 root 标签实例的 any 数组中的一项。然后开始继续向下解析。
当解析到 <props:complex id="C_1" /> 时,一样会进入 BaseElementHandler.prototype.handleNode,然后进入 handleChild,然后与上文一样继续后面的逻辑;但是,这个标签是一个 自闭合标签 ,会立即进入 closeTag 对应的钩子函数,将这个 handler 从栈中移除,并执行 handler.handleEnd():

这时 栈 会恢复到三个元素的状态,栈顶元素指向 <props:containedCollection> 标签对应的 ElementHandler 实例。
但是,假设我们将
xml字符串适当进行修改,将<props:complex id="C_2" />修改为<props:complex id="C_2">complex body string</props:complex>,就会进入另外一个处理函数。
上文 <props:complex id="C_1" /> 自闭合标签时虽然会入栈,然后后面就会立即出栈,但是解析 <props:complex id="C_2">complex body string</props:complex> 时,由于不是自闭合标签,所以解析到 <props:complex id="C_2"> 这里时就会执行 openTag 对应的钩子函数,然后进行上文提到的类似处理方式,得到这样的一个栈:

然后,则会一直匹配到下一个 < 尖括号,从 <props:complex id="C_2"> 到这个尖括号之间的内容,就会触发 text 钩子对应的 handleText 方法。
最终会将这个 text 字符串作为 element.body 属性挂载到 <props:complex id="C_2"> 对应的实例上;然后会解析到 </props:complex> 结束标签,触发 handleClose 执行出栈操作。
不过,虽然出栈之后 stack 栈中没有了这个元素,但是在 context 对象中,依然会记录所有的已解析内容:

然后,会继续如上文类似的处理过程,直到解析到 <props:attributeReferenceCollection id="C_4" refs="C_2 C_3 C_5" /> 标签。
在定义中,我们知道 AttributeReferenceCollection 类型的元素,会有一个 refs 数组,里面包含多个 Complex 类型的实例,并且该属性设置的 isReference,即 xml 中体现为 Complex 实例的 id 组成的字符串(isAttr 为 true,只能是数字、布尔或者字符串)。
当解析到该标签时,一样会通过 stack.push(handler.handleNode(node)) 进入到 handleChild 方法,然后创建一个新的 ElementHandler 实例再次执行 handleNode(node),最后进入新的 handler 的 createElement(node) 方法。
但是,在 createElement 创建的 childHandler 执行 handleNode(node) 时,创建的 attributeReferenceCollection 实例,属性 refs 是 引用类型属性 ,即 prop.isReference 为 true,这时 并不会直接处理实例引用,而是将当前的 attributeReferenceCollection 实例与解析出来的属性值 refs 的对应关系插入到 context 中。
<props:attributeReferenceCollection id="C_4" refs="C_2 C_3 C_5" /> 标签解析结束之后,状态结果如下:

最后,当 parser.parse(xml) 执行结束之后,才会立即执行 resolveReferences() 方法,遍历 context.references,将解析到的 element 实例与引用关系中指定的 id 对应的实例进行重新关联。当然,如果最后 找不到引用的实例 ,则会抛出一个警告,插入到 context 的 warnings 数组中。

当引用关系处理完成之后,xml 的解析过程也就基本结束了,最后就是整理输出结果并返回:
js
var rootElement = rootHandler.element;
if (!err && !rootElement) {
err = error('failed to parse document as <' + rootHandler.type.$descriptor.name + '>');
}
var warnings = context.warnings;
var references = context.references;
var elementsById = context.elementsById;
if (err) {
err.warnings = warnings;
return reject(err);
} else {
return resolve({
rootElement: rootElement,
elementsById: elementsById,
references: references,
warnings: warnings
});
}例如我们上文的 xml,最终得到的结果如下:

Writer - A writer for meta-model backed document trees
既然 Reader 是 解析 xml 得到 JavaScript 对象数据 ,那么肯定就需要有一个模块来实现 从 JavaScript 数据转换为 xml 字符串 的功能,而这部分工作就是 Writer 来完成的。
与 Reader 类似,Writer 也是一个 构造函数 ,并且也有一个方法 toXML 来实现 js 对象到 xml 的转换。
js
export function Writer(options) {
options = assign({ format: false, preamble: true }, options || {});
function toXML(tree, writer) {
// ...
}
return {
toXML
};
}由源码可见,Writer 初始化时接受一个可选对象参数 options,包含两个可选配置项:format 与 preamble,并且这两个参数具有默认值。
分别用来 处理标签换行的格式化以及 xml 文件头(文件说明和编码格式)。
如果 format 为 truth 值的话,遇到新标签会 换行并插入两个空格字符 ;如果 preamble 为 truth 值的话,会在 xml 头部插入声明部分 <?xml version="1.0" encoding="UTF-8"?> 并换行。
writer.toXML - 将 jS Object 转换为 xml
js
function toXML(tree, writer) {
var internalWriter = writer || new SavingWriter();
var formatingWriter = new FormatingWriter(internalWriter, options.format);
if (options.preamble) {
formatingWriter.append(XML_PREAMBLE);
}
var serializer = new ElementSerializer();
var model = tree.$model;
serializer.getNamespaces().mapDefaultPrefixes(getDefaultPrefixMappings(model));
serializer.build(tree).serializeTo(formatingWriter);
if (!writer) {
return internalWriter.value;
}
}作为转换方法,toXML 接收一个参数 tree 和一个可选参数 writer;tree 代表我们解析的 js 对象,writer 则是解析器实例,如果为空的话会重新创建一个 SavingWriter。
那么我们分别来看一下 toXML 里面用到的几个构造函数。
1. SavingWriter - 结果保存与更新
该函数(构造函数)只有一个作用,生成一个带有 value 属性与 write 方法的对象,value 是记录的 xml 字符串,write 负责接收一个新的子串 str 拼接到 value 上。
js
function SavingWriter() {
this.value = '';
this.write = function(str) {
this.value += str;
};
}2. FormatingWriter - xml 的格式化写入
负责格式化输出的部分,需要接收一个 SavingWriter 实例(或者一个具有 write 方法的对象),以及配置参数 format。
这个构造函数会创建一个 闭包,并创建一个具有 5 个方法的对象。
js
function FormatingWriter(out, format) {
var indent = [ '' ];
this.append = function(str) {
out.write(str);
return this;
};
this.appendNewLine = function() {
if (format) {
out.write('\n');
}
return this;
};
this.appendIndent = function() {
if (format) {
out.write(indent.join(' '));
}
return this;
};
this.indent = function() {
indent.push('');
return this;
};
this.unindent = function() {
indent.pop();
return this;
};
}其中 indent 数组用来标识 新换行的标签应该具有几个空格 ,也就是我们常说的 缩进 ,这里的缩进设置是 两个空格。
indent 与 unindent 两个方法,分别用来向 indent 数组中添加或者移除元素,通过数组元素个数来确定缩进范围;而 appendNewLine 与 appendIndent 则分别用来插入换行标识与新行缩进;append 则是直接调用 writer 对象的 write 方法,直接写入数据。
如果是自定义
writer的话,write方法就不一定是拼接了。
在 ElementSerializer 之前,我们先了解一下其他的 Serializer 和相关配置
3. ESCAPE MAPs - 转码匹配与对应关系
ESCAPE,这里指的是 转码 的意思。
在 Reader 中,我们知道 Reader 通过 saxen 进行 xml 解析的时候,会 匹配特殊字符进行解码 ,那么同样的,在转换成 xml 的时候,一样需要将特殊字符进行转换。
saxen 的解码规则,主要是依靠公共函数 decode(见上文 decode 函数 - 解析实体编码返回原始字符(/#decode 函数 - 解析实体编码返回原始字符)),里面处理了 尖括号 < >、& 符号和单双英文引号,所以这里会有对应的反向的转换关系;只是这里还 增加了 \n, \r 换行符的特殊处理 (saxen 默认不处理换行符等内容)。
js
var ESCAPE_ATTR_CHARS = /<|>|'|"|&|\n\r|\n/g;
var ESCAPE_CHARS = /<|>|&/g;
var ESCAPE_ATTR_MAP = {
'\n': '#10',
'\n\r': '#10',
'"': '#34',
'\'': '#39',
'<': '#60',
'>': '#62',
'&': '#38'
};
var ESCAPE_MAP = {
'<': 'lt',
'>': 'gt',
'&': 'amp'
};4. Namespaces - 命名空间与前缀管理
这个模块主要就是 管理和查询注册的命名空间与对应前缀,提供了以下几个属性和方法:
属性:
prefixMap:一个存储前缀到URI映射的对象。uriMap:一个存储URI到命名空间对象映射的对象。used:一个存储被使用的命名空间的对象。wellknown:一个存储被标记为"wellknown"的命名空间的数组。custom:一个存储自定义命名空间的数组。parent:一个指向父命名空间的引用。defaultPrefixMap:一个存储默认前缀到URI映射的对象。
其中 new Namespaces(parent) 时就需要传递一个 Namespaces 对象 作为父级(也可以为空);而 custom 与 wellknown 正好相反,保存不同的命名空间内容。
方法:
mapDefaultPrefixes(defaultPrefixMap):将传入的默认前缀映射对象设置为当前命名空间的默认前缀映射。defaultUriByPrefix(prefix):根据给定的前缀返回默认的URI。byUri(uri):根据给定的URI返回对应的命名空间对象。add(ns, isWellknown):将给定的命名空间对象添加到命名空间中,可以选择将其标记为"wellknown"(isWellknown为truth进入wellknown数组,反之进入custom数组)。uriByPrefix(prefix):根据给定的前缀返回对应的URI。mapPrefix(prefix, uri):将给定的前缀和URI映射关系添加到命名空间中。getNSKey(ns):根据给定的命名空间对象返回一个唯一的键。logUsed(ns):记录给定的命名空间对象被使用过。getUsed():返回所有被使用过的命名空间对象。
5. Utils - 工具函数
在开始解析 JavaScript 对象的时候,还需要一些工具函数来处理属性或者标签名:
lower(string):将字符串的第一个字符转换为小写。nameToAlias(name, pkg):根据给定的名称和包名,返回一个别名。如果包名有小写别名,则将名称转换为小写形式,否则返回原始名称。inherits(ctor, superCtor):实现继承关系,让ctor构造函数继承superCtor构造函数。nsName(ns):根据给定的命名空间对象ns,返回命名空间的字符串表示。如果命名空间是字符串类型,则直接返回;否则返回带有前缀的命名空间字符串。getNsAttrs(namespaces):根据给定的命名空间集合namespaces,获取已使用的命名空间,并将其转换为属性对象数组。过滤掉内置的xml命名空间。getElementNs(ns, descriptor):根据给定的命名空间对象ns和描述对象descriptor,获取元素命名空间。如果描述对象中这个类型是通用类型(即isGeneric为true),则返回原来的localName组成的命名空间对象;否则使用nameToAlias函数将localName转换为别名之后再返回。getPropertyNs(ns, descriptor):根据给定的命名空间对象ns和该属性的描述对象descriptor,获取属性命名空间。getSerializableProperties(element):根据给定的元素对象,获取该元素对应的描述对象descriptor,拿到properties属性数组。过滤掉虚拟属性、默认值和空值属性,返回剩余属性组成的属性对象数组。escape(str, charPattern, replaceMap):将给定的字符串str中的特定字符替换为转义字符。使用正则表达式charPattern匹配需要替换的字符,并使用replaceMap对应的转义字符进行替换。返回替换后的字符串。escapeAttr(str):将给定的字符串str中的特殊字符进行转义,以便在属性值中使用。使用ESCAPE_ATTR_CHARS正则表达式匹配需要转义的字符,并使用ESCAPE_ATTR_MAP对应的转义字符进行替换。返回转义后的字符串。escapeBody(str):将给定的字符串str中的特殊字符进行转义,以便在元素内容中使用。使用ESCAPE_CHARS正则表达式匹配需要转义的字符,并使用ESCAPE_MAP对应的转义字符进行替换。返回转义后的字符串。filterAttributes(props):根据给定的属性数组props,过滤出所有是属性(即作为xml标签的标签属性)的属性对象,并返回过滤后的属性数组。filterContained(props):根据给定的属性数组props,过滤出所有不是属性的属性对象(即包含在元素内容中的属性),并返回过滤后的属性数组,与上一个方法正好相反。
当这些准备工作做完之后,就可以进入解析和生成阶段了。
解析
JavaScript对象树生成对应xml字符串的部分,在Writer中被称为Serializer,也就是 序列化程序 ,与JSON.stringify类似,作用都是 将一个值序列化为一个字符串 ,只是Serializers会有特殊的序列化规则。
6. Serializers - 序列化程序
与 Reader 中的 Handlers 一样,Serializers 也有多个,并且部分也有继承关系:
ReferenceSerializer:引用类型序列化处理器BodySerializer:body属性序列化处理器ValueSerializer:属性值序列化处理器ElementSerializer:通用的标签元素生成器TypeSerializer:需要处理特殊数据类型的序列化处理器
其继承关系如下:
markdown
├── ReferenceSerializer
├── BodySerializer
│ └── ValueSerializer
└── ElementSerializer
└── TypeSerializer这些 Serializers 都有两个核心方法:
build:接收一个元素对象,绑定到Serializers的实例上serializeTo:接受一个Writer实例,将绑定元素序列化后的结果通过Writer插入到序列化结果中
其中 ElementSerializer 是最复杂的 Serializer,它会包含和创建多个 BodySerializer、ValueSerializer 和 ReferenceSerializer 的实例;而它也是负责构建和序列化 xml 最核心的部分,可以解析元素的属性、命名空间和包含的子元素;TypeSerializer 则通过继承 ElementSerializer 重写 parseNsAttributes 和 isLocalNs 方法,通过 检查属性描述对象中是否具有独立的 xml.serialize 序列化配置 ,来更新 xml 中的写入内容。
7. 从序列化过程开始
大致了解完相关内容之后,我们就可以回到 toXML 这个方法了。
该方法在初始化了 formatingWriter 之后,紧接着就是实例化一个 ElementSerializer,然后通过 getNamespaces 与 mapDefaultPrefixes 区分出来 custom 与 wellknown 两种不同的 nsMap 命名空间对象(这部分暂时还未发布正式版,在 v10.1.0 中只有下面一步);然后就是通过 build 方法根据 descriptor json 描述对象解析传入的 tree 对象树,最后将解析结果通过 serializeTo 写入最终结果中。
即:
js
var serializer = new ElementSerializer();
var model = tree.$model;
// 未发布内容
serializer.getNamespaces().mapDefaultPrefixes(getDefaultPrefixMappings(model));
serializer.build(tree).serializeTo(formatingWriter);首先, new ElementSerializer 创建了一个包含四个空值属性的对象 serializer:

而 getNamespaces 方法,主要是 serializer.parent 和 serializer.namespaces 来组合一个新的 Namespaces 对象实例,以 serializer.namespaces 为准,但因为此时这里两个属性都是空值,所以会根据 parent?.namespaces 创建一个新的 Namespaces 实例并挂在到 serializer 上然后返回(这里 parent?.namespaces 其实也是空的)。
然后,则是从传入的对象树上拿到 $model (也就是 Moddle 实例),来设置 serializer.namespaces 里面的内容。我们以 Reader 中用到的那个 Moddle 实例为例,解析时会得到这样的内容:
js
// Moddle 引用的属性描述对象文件,和实例化结果
import properties from '../../model/properties.json'
import propertiesExtended from '../../model/properties-extended.json'
const model = new Moddle([properties, propertiesExtended])
其中红色标注是我们后续引用的描述对应对应的命名空间前缀和 uri,蓝色标注则是 moddle-xml/common.js 中预设的两个命名空间前缀及 uri。
然后,就会进入 build 函数,进行解析和序列化。
js
ElementSerializer.prototype.build = function (element) {
this.element = element
var elementDescriptor = element.$descriptor,
propertyDescriptor = this.propertyDescriptor
var otherAttrs, properties
var isGeneric = elementDescriptor.isGeneric
if (isGeneric) {
otherAttrs = this.parseGenericNsAttributes(element)
} else {
otherAttrs = this.parseNsAttributes(element)
}
if (propertyDescriptor) {
this.ns = this.nsPropertyTagName(propertyDescriptor)
} else {
this.ns = this.nsTagName(elementDescriptor)
}
this.tagName = this.addTagName(this.ns)
if (isGeneric) {
this.parseGenericContainments(element)
} else {
properties = getSerializableProperties(element)
this.parseAttributes(filterAttributes(properties))
this.parseContainments(filterContained(properties))
}
this.parseGenericAttributes(element, otherAttrs)
return this
}根据 Moddle 的 createAny 方法的介绍,我们可以知道 isGeneric 只有在使用 model.createAny() 创建实例的时候才会为 true,而大部分情况下,我们都不会使用这个方法,所以基本上都默认为 false。
这种情况下,解析过程就分为以下步骤:
this.parseNsAttributes(element)this.ns = this.propertyDescriptor ? this.nsPropertyTagName(this.propertyDescriptor) : this.nsTagName(this.elementDescriptor)this.tagName = this.addTagName(this.ns)this.parseAttributes(filterAttributes(element.properties))this.parseContainments(filterContained(element.properties))this.parseGenericAttributes(element, otherAttrs)
这里我们创建一个与 Reader 解析结果类似的一个 实例树:
js
const complex1 = model.create('props:Complex', { id: 'C_1', body: 'this is complex c_1' })
const complex2 = model.create('props:Complex', { id: 'C_2', body: 'this is complex c_2' })
const complex3 = model.create('props:Complex', { id: 'C_3', body: 'this is complex c_3' })
const containedCollection = model.create('props:ContainedCollection', {
id: 'C_5',
children: [complex1, complex2, complex3]
})
complex1.$parent = complex2.$parent = complex3.$parent = containedCollection
const attributeReferenceCollection = model.create('props:AttributeReferenceCollection', {
id: 'C_4',
refs: [complex1, complex2, complex3]
})
const simpleBody1 = model.create('props:SimpleBody', { body: 'foo', otherAttr: 'other foo' })
const simpleBody2 = model.create('props:SimpleBody', { body: 'bar', anotherAttr: 'another bar' })
const simpleBody3 = model.create('props:SimpleBody', { body: 'baz', anotherAttr: 'another baz' })
const colAttr1 = model.create('props:Attributes', { name: 'integerValue', value: 10 })
const colAttr2 = model.create('props:Attributes', { name: 'booleanValue', value: true })
const complexAttrsCol = model.create('props:ComplexAttrsCol', {
attrs: [colAttr1, colAttr2]
})
colAttr1.$parent = colAttr2.$parent = complexAttrsCol
const root = model.create('props:Root', {
any: [simpleBody1, simpleBody2, simpleBody3, containedCollection, attributeReferenceCollection, complexAttrsCol],
otherAttr: 'other root',
anotherAttr: 'another root'
})
simpleBody1.$parent = simpleBody2.$parent = simpleBody3.$parent = root
containedCollection.$parent = attributeReferenceCollection.$parent = complexAttrsCol.$parent = root会得到这样一个对象:

需要设置每个子对象的
$parent指向,保证树的正确层级。为了测试所有的方法,增加了otherAttr,anotherAttr两个未定义属性。
1) 进入 parseGenericNsAttributes/parseNsAttributes 阶段。
顾名思义,这两个方法是用来 根据命名空间对象解析对象属性 的,并且两个方法都是通过 parseNsAttribute 来处理单个属性的,只是 parseGenericNsAttributes 会提取 element 元素上的 非 $ 符号开头的所有可枚举属性 ,通过 parseNsAttribute 进行判断和处理之后再组合成一个 [{ name: key, value: value }] 格式的对象;而 parseNsAttributes 则是 遍历 element.$attrs ,通过 parseNsAttribute 处理之后的返回值直接组合成一个数组(格式也是 [{ name: key, value: value }])。
那么
root对象中,$attrs就有我们自定义的两个属性,这时就会进入parseNsAttribute(element, name, value)方法。
该方法会通过 Moddle 提供的 parseNameNS 来将属性名 name 转换为一个 nameNs 对象,然后判断 nameNs.prefix 前缀或者 nameNs.localName 属性原名是否是 xmlns,如果是的话会将 value 作为 uri 属性创建一个 { uri: value } 的对象作为 ns 变量。
如果最后 ns 变量不存在的话,则返回 { name, value },否则会根据 value 的值(也就是 ns.uri)从 model.getPackages() 方法中读取该命名空间对应的属性描述对象是否存在,存在则调用 logNamespace 将其记录到 serializer.namespaces(wellknown 此时为 true) 中;如果不是已注册的,则会通过 logNamespaceUsed 创建一个新的命名控件对象再记录到 serializer.namespaces(wellknown 此时为 false)。
当然,我们注册的这两个属性并不会进入后面这部分逻辑之中,而是直接返回原属性名与属性值对象。
2) 然后进入下一步 this.ns = this.propertyDescriptor ? this.nsPropertyTagName(this.propertyDescriptor) : this.nsTagName(this.elementDescriptor)
这一步会区分 当前 serializer 的描述对象存在情况 ,来判断调用哪个方法。而 propertyDescriptor 属性的赋值只有在 new ElementSerializer 创建实例时才会发生,所以 首个标签的解析 ,propertyDescriptor 属性值都是 undefined;只有在后续的 parseContainments 阶段,才会有进入 nsPropertyTagName() 的情况。
而两个方法的逻辑也很简单:
nsTagName:根据 当前元素对应的描述对象elementDescriptor,返回一个prefix, uri, localName组成的命名空间对象ns并绑定到当前serializer,localName对应当前解析元素的定义名称nsPropertyTagName:根据 上级元素定义中该属性的配置propertyDescriptor,返回一个prefix, uri, localName组成的命名空间对象ns并绑定到当前serializer,localName对应propertyDescriptor中指定的属性名称
3) 然后生成标签名
上一步已经得到一个 ns 对象,这一步就是根据 ns 对象,生成一个 ${prefix}:${localName} 格式的标签名 tagName,绑定到 serializer。
4) 然后,开始解析对象的属性
这一步,首先需要 找到需要序列化处理的属性 properties 定义数组,即 getSerializableProperties(element)。
然后,根据 properties 中对每一项属性的定义,按照 isAttr 字段进行区分:
- 如果
isAttr === true,则是 标签的行内属性 ,通过parseAttributes处理 - 反之,则是标签内部的字标签或者
body文本,通过parseContainments处理
parseAttributes 方法在处理数据时,又分为几种情况:
isReference引用类型标识为true且isMany是false,则直接设置属性值为该引用实例的id属性值isReference引用类型标识为true且isMany是true,则需要遍历该属性,分别将所有引用实例的id读取出来,组成一个 由空格分开的 字符串isReference为false时,则不做特殊处理,后面运算时会调用toString自动转为字符串(这也是为什么有些自定义属性设置成数组时,显示在xml上会变成[object Object])
最后,会通过 serializer.addAttribute 将 属性名与属性值(属性值还会调用 escapeAttr 进行转码)组成 { name, value } 格式记录到 serializer.attrs 数组中,以供后续生成 xml 时使用。
而 parseContainments 方法,则是生成过程中 最核心的方法。
由于这个方法处理的是 标签内部的内容 ,包含 文本(也就是 body)、子标签 两种情况;内部可以存放其他元素的引用,子标签也可能有 自定义的序列化类型 ,所以 在处理每一个属性时,都需要进行不同情况的判断,我们可以结合它的源码来分析:
js
ElementSerializer.prototype.parseContainments = function (properties) {
var self = this,
body = this.body,
element = this.element
forEach(properties, function (p) {
var value = element.get(p.name),
isReference = p.isReference,
isMany = p.isMany
if (!isMany) {
value = [value]
}
if (p.isBody) {
body.push(new BodySerializer().build(p, value[0]))
}
else if (isSimpleType(p.type)) {
forEach(value, function (v) {
body.push(new ValueSerializer(self.addTagName(self.nsPropertyTagName(p))).build(p, v))
})
}
else if (isReference) {
forEach(value, function (v) {
body.push(new ReferenceSerializer(self.addTagName(self.nsPropertyTagName(p))).build(v))
})
}
else {
var serialization = getSerialization(p)
forEach(value, function (v) {
var serializer
if (serialization) {
if (serialization === SERIALIZE_PROPERTY) {
serializer = new ElementSerializer(self, p)
} else {
serializer = new TypeSerializer(self, p, serialization)
}
} else {
serializer = new ElementSerializer(self)
}
body.push(serializer.build(v))
})
}
})
}进入 parseContainments 方法,由上文可以知道 properties 参数是 当前元素对应的描述对象中,所有 isAttr 不等于 true 的属性组合成的数组 。以上文的根节点 root 为例,这里的 properties 就是:
js
[{
"name": "any",
"type": "props:Base",
"isMany": true,
"ns": { "name": "props:any", "prefix": "props", "localName": "any" },
"inherited": true
}]然后,开始遍历这个数组,依次读取当前实例中的所有对应属性值(获取方式参见上节 Moddle);并且,这里会对获取到的值进行 标准化处理,都转换为对象数组形式。
下一步则是区分不同情况,分别进行属性值的解析:
isBody == true:这种情况说明 这个属性需要显示在标签的内容;此时这部分内容通常会是字符串或者数字,那么直接创建一个BodySerializer将属性描述与属性值传递进build方法,并且将该实例插入到当前serializer的body数组中。isSimpleType(p.type) == true:isSimpleType方法在Moddle一节中有说过,即验证这个属性定义的类型是不是字符串、数字(整数或小数)、布尔值;如果是这种情况,则需要针对该属性值的每一项分别创建一个ValueSerializer实例并添加到当前serializer的body数组中;还会调用每个ValueSerializer实例的build方法。isReference == true:即该属性是引用其他实例的id属性,在xml显示为一个字符串;一样会初始化一个ReferenceSerializer实例,调用其build方法然后插入到serializer的body数组中。- 剩余情况,则是验证这个属性对应的描述对象
property有没有定义xml.serialize属性(结果赋值给变量serialization),根据这个属性的不同,又会分为以下三种情况:serialization === 'property':表示需要作为一个新的标签来处理属性,这种情况下会对当前属性,根据当前serializer实例与当前属性对应的描述对象,作为参数重新创建一个ElementSerializer实例,然后执行新实例的build方法。serialization != null:即存在xml.serialize配置,但是值不是property;这种情况下,与上一种情况比较类型,是创建一个TypeSerializer实例,然后调用其build方法;但是TypeSerializer也是继承自ElementSerializer,只是增加了serialization的自定义序列化规则。- 最后,则是没有定义序列化的情况,这种情况下,一样会创建一个
ElementSerializer实例然后执行build方法,只是此时只需要传入当前的serializer实例作为父级元素即可,然后按照该元素自己的定义进行解析。
最后,我们会得到一个 与原来的 root 实例结构类似的一个树形结构对象实例 serializer,大致结构如下:

最后,调用 serializeTo 将其转化为 字符串结果。
至于 serializeTo,其核心也是 借助 writer 实例创建一个标签头,然后通过 serializeAttributes 方法将当前实例的属性紧接着标签头进行写入,然后遍历 serializer 实例的 body 数组属性,依次执行为 body 中的每个 Serializer 执行 serializeTo 方法,直到解析完所有的 serializer 实例;原理上,就是一个 深度递归 的方式遍历对象树结构。
8. 不同 Serializer 序列化器及属性定义之间的区别
根据 6. Serializer 序列化处理程序 这部分的继承关系,可以知道 Body 与 Value、Element 与 Type 互相有继承关系;除了 ElementSerializer 比较复杂之外,其他几个都比较简单。
ReferenceSerializer:生成一个 与属性定义中该属性名称对应的一个标签,并将该实例数组值对应的实例的id插入到这个标签内部作为纯文本。BodySerializer:将属性值转码后插入到结果中ValueSerializer:与BodySerializer不同的是,ValueSerializer实例化时需要传递一个tagName,转字符串时会根据该tagName生成一个新的完整标签,并在标签内部插入转码后的结果ElementSerializer:这种情况一般适用于非简单类型,也就是一个对象或者数组(当然数组最终解析时也会遍历内部的内容,最终始终是按对象的定义来执行);通常,都会根据这个对象的描述对象中定义的name字段来生成一个新的标签,然后再依次遍历其属性定义,如果某个属性也是对象或者数组的话,则会进行针对属性的序列化处理,直到所有属性解析处理完成TypeSerializer:这个序列化器则是针对具有自定义序列化标识的属性,会按照其标识创建不同的Serializer,并修改属性结果;通常这种情况下,会修改原属性对应的对象的标签名或者新建一个新的标签名;大部分情况下,描述对象中设置的自定义序列化标识只有两个值:property和xsi:type。
为了更好的体现不同的属性定义与解析结果之间的区别,我对上文的 property.json 进行一下修改,将其中的 WithProperty 和 ComplexAttrs 改为以下形式:
json
{
"name": "ComplexAttrs",
"superClass": [ "Complex" ],
"properties": [
{ "name": "attrs", "type": "Attributes" }
]
},{
"name": "WithProperty",
"superClass": [ "Base" ],
"properties": [
{ "name": "propertyName", "type": "Base", "xml": { "serialize" : "property" } },
{ "name": "typeName", "type": "Base", "xml": { "serialize" : "xsi:type" } },
{ "name": "defineName", "type": "Base", "xml": { "serialize" : "props:attributes" } }
]
}然后,创建不同情况下的实例树:
js
const complex1 = model.create('props:Complex', { id: 'C_1', body: 'this is complex c_1' })
const complex2 = model.create('props:Complex', { id: 'C_2', body: 'this is complex c_2' })
const complex3 = model.create('props:Complex', { id: 'C_3', body: 'this is complex c_3' })
const containedCollection = model.create('props:ContainedCollection', {
id: 'C_5',
children: [complex1, complex2, complex3]
})
complex1.$parent = complex2.$parent = complex3.$parent = containedCollection
const attributeReferenceCollection = model.create('props:AttributeReferenceCollection', {
id: 'C_4',
refs: [complex1, complex2, complex3]
})
const complexCount = model.create('props:ComplexCount', { id: 'ComplexCount_1' })
const complexNesting = model.create('props:ComplexNesting', { id: 'ComplexNesting_1' })
const referencingCollection = model.create('props:ReferencingCollection', {
references: [complexCount, complexNesting]
})
complexCount.$parent = complexNesting.$parent = referencingCollection
const simpleBody1 = model.create('props:SimpleBody', { body: 'foo', otherAttr: 'other foo' })
const simpleBody2 = model.create('props:SimpleBody', { body: 'bar', anotherAttr: 'another bar' })
const simpleBody3 = model.create('props:SimpleBody', { body: 'baz', anotherAttr: 'another baz' })
const colAttr1 = model.create('props:Attributes', { name: 'integerValue', value: 10, arr: [1, 2, 3] })
const colAttr2 = model.create('props:Attributes', { name: 'booleanValue', value: true, obj: { a: 1, b: 2, c: 3 } })
const complexAttrsCol = model.create('props:ComplexAttrsCol', {
attrs: [colAttr1, colAttr2]
})
colAttr1.$parent = colAttr2.$parent = complexAttrsCol
const colAttr3 = model.create('props:Attributes', { name: 'integerValue', value: 10 })
const complexAttrs = model.create('props:ComplexAttrs', {
attrs: colAttr3
})
colAttr3.$parent = complexAttrs
const propertyValue = model.create('props:BaseWithId', { id: 'PropertyValue' })
const typeValue = model.create('props:BaseWithId', { id: 'PropertyValue' })
const defineValue = model.create('props:BaseWithId', { id: 'PropertyValue' })
const withProperty = model.create('props:WithProperty', { propertyName: propertyValue, typeName: typeValue, defineName: defineValue })
const root = model.create('props:Root', {
any: [simpleBody1, simpleBody2, simpleBody3, containedCollection, attributeReferenceCollection, referencingCollection, complexAttrs, complexAttrsCol, withProperty],
otherAttr: 'other root',
anotherAttr: 'another root'
})
simpleBody1.$parent = simpleBody2.$parent = simpleBody3.$parent = withProperty.$parent = root
containedCollection.$parent = attributeReferenceCollection.$parent = referencingCollection.$parent = complexAttrsCol.$parent = root
const xml1 = writer.toXML(root)最终我们会得到这样一个结果:
xml
<?xml version="1.0" encoding="UTF-8"?>
<props:root xmlns:props="http://properties" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" otherAttr="other root" anotherAttr="another root">
<props:simpleBody otherAttr="other foo">foo</props:simpleBody>
<props:simpleBody anotherAttr="another bar">bar</props:simpleBody>
<props:simpleBody anotherAttr="another baz">baz</props:simpleBody>
<props:containedCollection id="C_5">
<props:complex id="C_1">this is complex c_1</props:complex>
<props:complex id="C_2">this is complex c_2</props:complex>
<props:complex id="C_3">this is complex c_3</props:complex>
</props:containedCollection>
<props:attributeReferenceCollection id="C_4" refs="C_1 C_2 C_3" />
<props:referencingCollection>
<props:references>ComplexCount_1</props:references>
<props:references>ComplexNesting_1</props:references>
</props:referencingCollection>
<props:complexAttrs>
<props:attributes name="integerValue" value="10" />
</props:complexAttrs>
<props:complexAttrsCol>
<props:attrs name="integerValue" value="10" arr="1,2,3" />
<props:attrs name="booleanValue" value="true" obj="[object Object]" />
</props:complexAttrsCol>
<props:withProperty>
<props:propertyName id="PropertyValue" />
<props:typeName xsi:type="props:BaseWithId" id="PropertyValue" />
<props:defineName attributes="props:BaseWithId" id="PropertyValue" />
</props:withProperty>
</props:root>其中:
<props:referencingCollection>标签中的两个引用属性与<props:attributeReferenceCollection>标签中的引用属性有区别:

因为 referencingCollection 中未指定 isAttr,所以默认需要解析到 referencingCollection 标签内部;而为了区分 isBody 内容,需要创建属性名对应的标签来处理,所有有了 <props:references> 标签,这部分内容对应 ReferenceSerializer。
<props:attributes>与<props:attrs>标签,这两个标签对应 父元素 的属性类型定义,其实都指向props:Attrubutes声明:

但是,ComplexAttrsCol 中对其属性进行了序列化的指定,所以最终生成的标签名变成了 <props:attrs>,而 ComplexAttrs 没有处理,所以依然是 Attributes 对应的标签名 <props:attributes>
<props:withProperty>中三种不同的序列化结果:

针对 withProperty,我们定义了三种对象类型都是 Base 的属性,但是分别有不同的序列化标识。这几种情况下都会按照配置的属性名生成一个新的子标签,但是,子标签的内容都有区别。
其中,propertyName 指定了作为 property 属性进行序列化,所以生成了一个新标签 <props:propertyName> 并且对应 id 属性为 propertyValue 设置在标签中;而 typeName 则指定为另一个常用序列化标识 xsi:type,这种情况与第三种情况一样,会执行 TypeSerializer 部分的逻辑,但是,xsi:type 并没有在我们已定义的所有命名空间中,所以,会生成一个新的属性 xsi:type 来指定我们的序列化方式,并设置其属性值为这个元素该属性对应的属性描述对象中的 name 字段,也就是 Props:BaseWithId;最后指定序列化为 props:Attributes 时,一样会生成一个属性来指定序列化方式,但是该属性对应的命令空间已经注册的,所以生成的属性名会自动去除对应的命名空间前缀,得到另外一个结果。
- 未定义属性的处理
在创建不同的实例的组成 root 的时候,我们定义了一些 没有在 descriptor json 描述对象中定义的属性 ,例如 root 上的 otherAttr、anotherAttr,attributes 上的 arr、obj 等。但在之前的 序列化过程 中,有解释过未声明的自定义属性,在解析时,会调用 toString 方法将其转为字符串,然后插入到标签中。
所以 otherAttr、otherAttr 这种字符串属性,在转换成 xml 后依然显示的一样的内容,而 arr 数组则转换为了以逗号分割的字符串形式,obj 则变成了 [object Object]。这种情况下,对于普通的字符串或者数字还比较好处理,遇到数组或者对象时,则很难再从 xml 转换为原来的格式了,所以这里建议 对所有的需要处理的 xml 上的属性,都需要通过 descriptor json 进行描述,并注册到 Moddle 之中。
bpmn-moddle
在理解了 Moddle 和 moddle-xml 之后,再回到 bpmn-moddle 就很简单了。
bpmn-moddle 内部除了入口文件 index.js 之外,只有一个 simple.js 与一个 bpmn-moddle.js。其中,bpmn-moddle.js 导出了一个 继承自 Moddle 的构造函数 ,并且提供了 toXML 和 fromXML 两个方法。很明显,这两个方法来自于 moddle-xml。
js
function BpmnModdle(packages, options) {
Moddle.call(this, packages, options);
}
BpmnModdle.prototype = Object.create(Moddle.prototype);
BpmnModdle.prototype.fromXML = function(xmlStr, typeName, options) {
if (!isString(typeName)) {
options = typeName;
typeName = 'bpmn:Definitions';
}
var reader = new Reader(assign({ model: this, lax: true }, options));
var rootHandler = reader.handler(typeName);
return reader.fromXML(xmlStr, rootHandler);
};
BpmnModdle.prototype.toXML = function(element, options) {
var writer = new Writer(options);
return new Promise(function(resolve, reject) {
try {
var result = writer.toXML(element);
return resolve({
xml: result
});
} catch (err) {
return reject(err);
}
});
};在这两个方法中,核心就是 校验参数,调用 moddle-xml 的 Reader 和 Writer,封装返回结果。
而 simple.js,则是 引入 BPMN 2.0 规范对应的所有 descriptor json 文件,并创建一个默认注册所有描述文件的 Moddle 实例。
js
import {
assign
} from 'min-dash';
import BpmnModdle from './bpmn-moddle.js';
import BpmnPackage from '../resources/bpmn/json/bpmn.json' assert { type: 'json' };
import BpmnDiPackage from '../resources/bpmn/json/bpmndi.json' assert { type: 'json' };
import DcPackage from '../resources/bpmn/json/dc.json' assert { type: 'json' };
import DiPackage from '../resources/bpmn/json/di.json' assert { type: 'json' };
import BiocPackage from '../resources/bpmn-io/json/bioc.json' assert { type: 'json' };
import BpmnInColorPackage from 'bpmn-in-color-moddle/resources/bpmn-in-color.json' assert { type: 'json' };
var packages = {
bpmn: BpmnPackage,
bpmndi: BpmnDiPackage,
dc: DcPackage,
di: DiPackage,
bioc: BiocPackage,
color: BpmnInColorPackage
};
export default function(additionalPackages, options) {
var pks = assign({}, packages, additionalPackages);
return new BpmnModdle(pks, options);
}其中,dc.json 声明的是 文本样式与四个基础数据类型,以及坐标点、边界对象两个对象实例的数值类型 ,di.json 则对应 所有的可见的图形元素实例对应的控制属性,例如连线类属性的路径 waypoint 等 ;bpmndi.json 则是 di.json 的扩展,定义 BPMN 元素的相关显示元素类型;bpmn-in-color.json 则是最近新增的一个用来合理化处理 setColor 方法导致标签多余样式属性的文件,控制哪些颜色属性可以在指定类型的元素上显示。
bpmn.json 则是 根据 BPMN 2.0 规范,按照规范中的元素以及属性定义,得到的完整的元素描述对象。