文章目录
- 引言:为何熔断不是高流量专属?
- 一、业务场景:两个血泪教训
- 二、核心需求:熔断机制的覆盖场景
- [三、Hystrix 设计思想解析](#三、Hystrix 设计思想解析)
- 四、关键注意事项
-
- [1. 数据一致性难题](#1. 数据一致性难题)
- [2. 超时降级陷阱](#2. 超时降级陷阱)
- [3. 用户体验设计](#3. 用户体验设计)
- [4. 熔断监控告警](#4. 熔断监控告警)
- 五、总结与最佳实践

引言:为何熔断不是高流量专属?
在微服务架构中,熔断机制常被误解为仅应对高流量场景。实际上,即使业务流量不大,服务间的依赖故障、第三方接口不稳定、数据库瞬时压力等问题都可能引发雪崩效应。
接下来我们将通过真实案例揭示熔断的核心价值,并深入剖析 Netflix Hystrix 的设计思想与实践要点。
一、业务场景:两个血泪教训
案例一:状态接口的慢请求灾难
调用链路 :
App -> User API -> BasicDataService -> 第三方位置接口
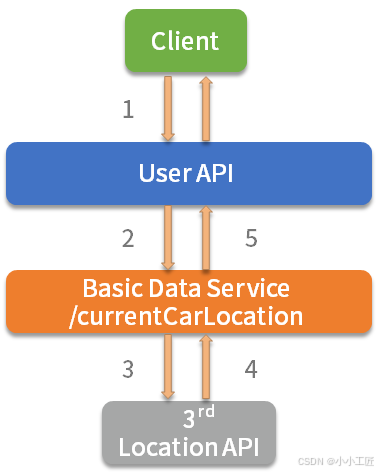
问题现象:
- 第三方接口响应慢(平均 2s+)
- 用户信息页面卡顿,最终导致 App 整体瘫痪
根因分析 :
所有线程被慢调用阻塞,连接池耗尽引发级联故障。
案例二:权限接口的缓存穿透风暴
调用链路 :
App -> User API -> BasicDataService -> Redis -> DB
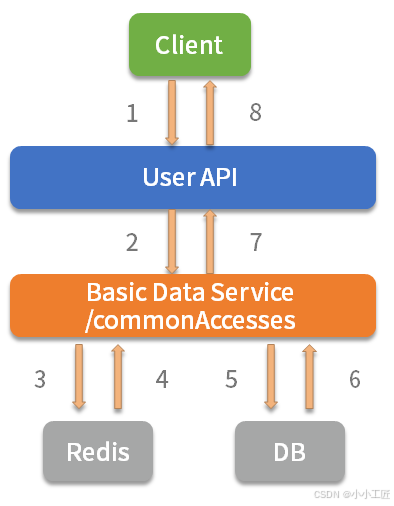
问题现象:
- Redis 缓存失效瞬间,DB 被击穿
- 数据库 CPU 100%,服务线程全阻塞
根因分析 :
瞬时高并发查询穿透缓存,数据库过载引发服务雪崩。
二、核心需求:熔断机制的覆盖场景
(1)线程隔离
针对第一个问题,我们希望比如 User API 中每个服务配置的最大连接数是 1000,每次 API 调用 BasicDataService#/currentCarLocation 的速度就会很慢。 希望控制 /currentCarLocation 的调用请求数,保证不超过 50 条,以此保证至少还有 950 条的连接可用来处理常规请求。如果 /currentCarLocation 的调用请求数超过 50 条,我们就设计一些备用逻辑进行处理,比如在界面上给用户进行提示。
(2)熔断
针对第二个问题,因那时 DB 没有死锁,流量洪峰缓存超时单纯是因为压力太大,此时我们可以使用 Basic Data Service 暂缓一点儿时间,让它不接受新的请求,这样 Redis 的数据会被补上,数据库的连接也会降下来,服务也就没事了。
因此,我们希望这个技术能实现以下两点需求:
-
发现近期某个接口的请求老出异常、有猫腻,先别访问接口的服务;
-
发现某个接口的请求老超时,先判断接口的服务是否不堪重负,如果不堪重负,先别访问它。
小结
| 场景 | 需求描述 |
|---|---|
| 线程隔离 | 限制慢接口并发线程数,避免资源耗尽 |
| 熔断降级 | 异常比例超标时拒绝请求,快速失败并启用备用逻辑 |
三、Hystrix 设计思想解析
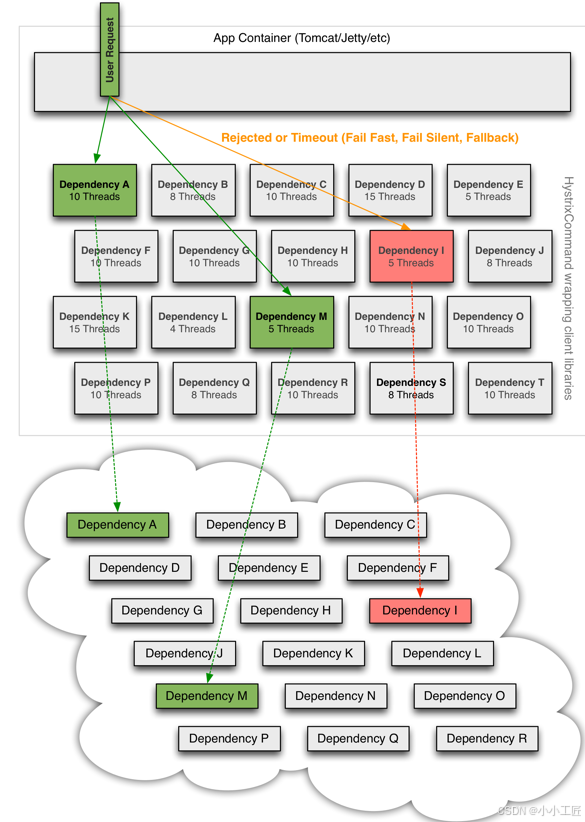
1. 线程隔离:资源保护的防火墙
Hystrix 提供两种隔离策略:
线程池隔离
-
每个依赖服务独享线程池(如:
/currentCarLocation限制 50 线程)
-
优点:支持超时中断,避免主线程阻塞
-
缺点:线程切换开销较高(约 1ms)
信号量隔离
- 通过计数器限制并发数(如:
semaphoresA最大 10):在信号量隔离的机制中,Hystix 并不使用 1 个 size 为 10 的线程池来隔离,而是使用一个信号 semaphoresA,每当调用接口 A 时 semaphoresA++,A 调用完后 semaphoresA--,semaphoresA 一旦超过 10,不再调用 - 优点:无线程切换开销,性能更高
- 缺点:无法中断正在执行的请求
当信号量超限(semaphoresA >10)时,新请求直接触发降级逻辑,不进入业务处理。
2. 熔断机制:动态故障防御
在哪种条件下会触发熔断?
熔断判断规则是某段时间内调用失败数超过特定的数量或比率时,就会触发熔断。那这个数据是如何统计出来的呢?
在 Hystrix 机制中,我们会配置一个不断滚动的统计时间窗口 metrics.rollingStats.timeInMilliseconds,在每个统计时间窗口中,当调用接口的总数量达到 circuitBreakerRequestVolumeThreshold,且接口调用超时或异常的调用次数与总调用次数的占比超过 circuitBreakerErrorThresholdPercentage,此时就会触发熔断。
熔断了会怎么样?
如果熔断被触发了,在 circuitBreakerSleepWindowInMilliseconds 的时间内,我们便不再对外调用接口,而是直接调用本地的一个降级方法,如下代码所示:
java
@HystrixCommand(fallbackMethod = "getCurrentCarLocationFallback")熔断后怎么恢复?
circuitBreakerSleepWindowInMilliseconds 到时间后,Hystrix 首先会放开对接口的限制(断路器状态 HALF-OPEN),然后尝试使用 1 个请求去调用接口,如果调用成功,则恢复正常(断路器状态 CLOSED),如果调用失败或出现超时等待,就需要再重新等待circuitBreakerSleepWindowInMilliseconds 的时间,之后再重试。
小结
熔断触发条件(可配置):
- 时间窗口内请求数 ≥
circuitBreakerRequestVolumeThreshold(默认 20) - 失败率 ≥
circuitBreakerErrorThresholdPercentage(默认 50%)
熔断状态流转:
- Closed:正常状态,请求放行。
- Open:熔断开启,所有请求直接降级。
- Half-Open :休眠期(
circuitBreakerSleepWindow)后,尝试放行单个请求探测恢复情况。
3. 滑动时间窗口:精准统计异常
比如我们把滑动事件的时间窗口设置为 10 秒,并不是说我们需要在 1 分 10 秒时统计一次,1 分 20 秒时再统计一次,而是我们需要统计每一个 10 秒的时间窗口。
因此,我们还需要设置一个 metrics.rollingStats.numBuckets,假设我们设置 metrics.rollingStats.numBuckets 为 10,表示时间窗口划分为 10 小份,每 1 份是 1 秒。然后我们就会 1 分 0 秒 - 1 分 10 秒统计 1 次、1 分 1 秒 - 1 分 11 秒统计 1 次、1 分 2 秒 - 1 分 12 秒统计 1 次......(即每隔 1 秒都有 1 个时间窗口。)
下图就是 1 个 10 秒时间窗口,我们把它分成了 10 个桶

每个桶中 Hystrix 首先会统计调用请求的成功数、失败数、超时数和拒绝数,再单独统计每 10 个桶的数据(到了第 11 个桶时就是统计第 2 个桶到第 11 个桶的合计数据)。
- 将时间窗口(如 10s)划分为多个桶(如 10 个 1s 桶)
- 每个桶统计成功、失败、超时次数
- 窗口随时间滑动,确保统计数据实时性
4. 请求处理流程
- 检查熔断器状态
- 校验线程池/信号量资源
- 执行实际调用或降级逻辑
- 上报结果更新熔断状态
1 次调用成功的流程

1 次调用失败的流程

四、关键注意事项
1. 数据一致性难题
- 场景:服务 A 更新 DB 后调用服务 B 触发熔断
- 解决方案 :
- 最终一致性:记录补偿日志,异步重试
- 同步回滚:结合分布式事务(性能损耗需权衡)
2. 超时降级陷阱
- 问题:服务 B 处理未中断,但服务 A 已降级
- 预防 :
- 服务 B 实现幂等性
- 异步通知结果或提供状态查询接口
3. 用户体验设计
| 场景 | 处理策略 |
|---|---|
| 读请求降级 | 显示缺省数据或"稍后再试"提示 |
| 写请求降级 | 明确提示用户或转异步处理 |
4. 熔断监控告警
- 监控指标:请求量、失败率、熔断状态
- 推荐工具:Hystrix Dashboard + Turbine
五、总结与最佳实践
熔断机制是微服务架构的安全气囊,其核心价值在于:
- 快速失败:防止局部故障扩散
- 优雅降级:保障核心链路可用性
- 自适应恢复:动态探测依赖服务状态
实践建议:
- 渐进式配置:先保守设置阈值,根据监控逐步调整
- 降级兜底:所有远程调用必须定义 fallback 方法
- 熔断分层:结合网关级熔断与服务级熔断
通过深入理解 Hystrix 的设计原理与实际场景中的陷阱,开发者能够构建出真正健壮的微服务系统。尽管 Hystrix 已停止更新,其思想仍被 Resilience4j、Sentinel 等新一代框架继承,持续为分布式系统保驾护航。
