 编辑
编辑
AI agent 可以干什么:
- 执行操作并从其环境中获取反馈
- 思考并基于反馈改进其行动
- 努力完成目标,而不是等待进一步的提示(除非有明确要求)
- 与其他代理合作工作
一个Agent可以建立在大型语言模型(LLM)或其他神经网络之上,并且可以使用强化学习(RL)或基于规则的系统等。
我们用什么构建Agent
我们开始使用CrewAI构建我们的AI代理。它是一个开源的Python框架,帮助我们使用单个或多个代理构建AI系统,这些代理可以协同工作以解决复杂任务。
你可能已经看过很多关于构建代理的LangChain教程,但我们在这个教程中使用CrewAI,因为LangChain的语法非常特殊,,很快就会变得难以理解。
CrewAI 使用起来更加简单,发展迅速,拥有一个活跃且乐于助人的社区,并且拥有令人惊叹的文档(令人惊讶的是,这些文档是由基于 CrewAI 构建的代理编写的)。
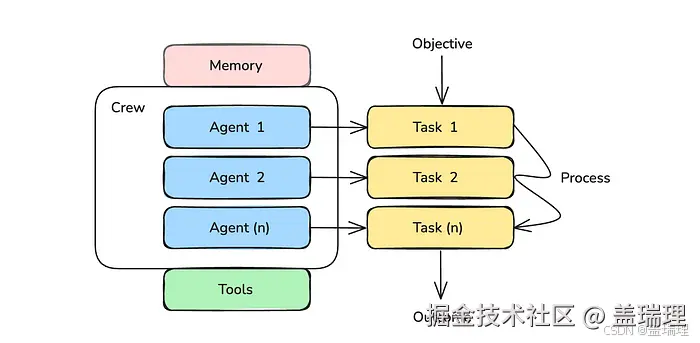
首先,我们需要了解以下六个术语:
1. Crew
这是管理AI代理并帮助他们协作以产生预期输出的顶级组织。
- Agents
这些是基于LLM的自主实体,具有特定的角色。它们可以做出自主决策,使用工具,并与其他代理一起解决问题。
- Tasks
这些是人工智能代理正在工作的子目标。
- Tools
这些是使代理能够执行各种任务的组件,例如网络搜索、网络抓取、文件管理等等。
- Memory
这是一个系统,它让AI代理记住他们的短期和长期过去互动,以改善他们的解决问题的能力。
- Process
这是工作流管理系统,它定义了代理如何互动和协作以高效工作。
 编辑
编辑
让我们开始第一个Agent
基于"做中学"的理念,以ArXiv为例构建一个研究团队
你将拥有一个多代理系统,该系统将致力于实现以下目标:
- 在给定日期搜索 ArXiv 上所有关于人工智能的研究论文。
- 从这些论文中选出最重要的 10 篇。
- 以格式良好的 HTML 文件返回结果。
- 在步骤之间请向我们反馈,以便其功能能够得到良好的监控,并在需要时进行调整。
步骤1:安装软件包
pip install crewai crewai_tools arxiv步骤2:设置环境变量
创建一个OpenAI API密钥,并将其设置为环境变量,如下所示,与openai api使用方式兼容的方式也是可以的。
CrewAI 默认使用 gpt-4o-mini 来构建代理。我在下面的代码中明确展示了这一点,如果你愿意,可以使用比它更小、更便宜或更强大的模型。
lua
# Set up environment variables
import os
openai_api_key = "YOUR_API_KEY"
os.environ["OPENAI_API_BASE"] = 'https://api.openai.com/v1'
os.environ["OPENAI_API_KEY"] = openai_api_key
os.environ["OPENAI_MODEL_NAME"] = "gpt-4o-mini"步骤3:构建自定义ArXiv搜索工具
CrewAI 附带 多种工具,您可以直接使用。这些工具可以轻松地从我们之前安装的crewai_tools包中导入和使用,如下所示。
ini
# Importing crewAI tools
from crewai_tools import (
DirectoryReadTool,
FileReadTool,
SerperDevTool,
WebsiteSearchTool
)
# Set up API keys for Serper
os.environ["SERPER_API_KEY"] = "Your Key" # serper.dev API key
# Instantiate tools
docs_tool = DirectoryReadTool(directory='./your-directory') # Tool for reading documents from a specified directory
file_tool = FileReadTool() # Tool for reading individual files
search_tool = SerperDevTool() # Tool for performing web searches using the Serper API
web_rag_tool = WebsiteSearchTool() # Tool for searching and extracting information from websites您还可以轻松地将LangChain的工具与CrewAI集成并使用。
要创建自定义工具,我们需要继承自BaseTool类,并定义必要的属性,包括用于输入验证的args_schema和_run方法。
Pydantic 用于定义我们工具的输入模式。
python
from typing import Type, List
from pydantic import BaseModel, Field
from crewai.tools import BaseTool
import arxiv
import time
import datetime
class FetchArxivPapersInput(BaseModel):
"""Input schema for FetchArxivPapersTool."""
target_date: datetime.date = Field(..., description="Target date to fetch papers for.")
class FetchArxivPapersTool(BaseTool):
name: str = "fetch_arxiv_papers"
description: str = "Fetches all ArXiv papers from selected categories submitted on the target date."
args_schema: Type[BaseModel] = FetchArxivPapersInput
def _run(self, target_date: datetime.date) -> List[dict]:
# List of AI-related categories.
# You can also include ["cs.AI", "cs.LG", "cs.CV", "cs.MA", "cs.RO"]
AI_CATEGORIES = ["cs.CL"]
# Define the date range for the target date
start_date = target_date.strftime('%Y%m%d%H%M')
end_date = (target_date + datetime.timedelta(days=1)).strftime('%Y%m%d%H%M')
# Initialize the ArXiv client
client = arxiv.Client(
page_size=100, # Fetch 100 results per page
delay_seconds=3 # Delay between requests to respect rate limits
)
all_papers = []
for category in AI_CATEGORIES:
print(f"Fetching papers for category: {category}")
search_query = f"cat:{category} AND submittedDate:[{start_date} TO {end_date}]"
search = arxiv.Search(
query=search_query,
sort_by=arxiv.SortCriterion.SubmittedDate,
max_results=None # Fetch all results
)
# Collect results for the category
category_papers = []
for result in client.results(search):
category_papers.append({
'title': result.title,
'authors': [author.name for author in result.authors],
'summary': result.summary,
'published': result.published,
'url': result.entry_id
})
# Delay between requests to respect rate limits
time.sleep(3)
print(f"Fetched {len(category_papers)} papers from {category}")
all_papers.extend(category_papers)
return all_papers我们初始化此工具如下:
ini
arxiv_search_tool = FetchArxivPapersTool()步骤4:创建代理
当要求代理人扮演一个角色时,他们工作得更好。基于这一事实,每个代理都初始化为:
- Role
- Goal
- Backstory
我们定义了两个代理来工作于我们的目标:
1. ArXiv Researcher
ini
# Agent 1: ArXiv Researcher
researcher = Agent(
role = "Senior Researcher",
goal = "Find the top 10 papers from the search results from ArXiv on {date}."
"Rank them appropirately.",
backstory = "You are a senior researcher with a deep understanding of all topics in AI and AI research."
"You are able to identify the best research papers based on the title and abstract.",
verbose = True,
tools = [arxiv_search_tool],
)参数 verbose 设置为 True,以查看有关代理执行的详细日志。参数 tools 指定了人工智能代理在执行过程中可以使用哪些工具。
- Frontend Engineer
ini
# Agent 2: Frontend Engineer
frontend_engineer = Agent(
role = "Senior Frontend & AI Engineer",
goal = "Compile the results into a HTML file.",
backstory = "You are a competent frontend engineer writing HTML and CSS with decades of experience."
"You have also been working with AI for decades and understand it well.",
verbose = True,
)Agent 类还包含一个可选参数 llm,如果您愿意,可以为此类不同的代理选择不同的 LLM。
步骤5:创建任务
你一定在想,为什么我们不使用一个单一的LLM作为代理,并给它所有完成目标所需的工具。原因在于,将一个目标分解为子目标或任务 ,并让每个AI代理专注于一个任务,能够带来更好的结果。每个任务都指定了一个描述和一个预期输出。参数 agent 指定了执行特定任务所需的代理。
我们将目标分解为两个任务,如下所示:
- 'ArXiv Researcher' 代理的研究任务
ini
# Task for ArXiv Researcher
research_task = Task(
description = (" Find the top 10 research papers from the search results from ArXiv on {date}."),
expected_output = (
"A list of top 10 research papers with the following information in the following format:"
"- Title"
"- Authors"
"- Abstract"
"- Link to the paper"
),
agent = researcher,
human_input = True,
)参数 human_input 被设置为 True,以确保代理在完成任务后能够接收我们对结果的反馈。
'Frontend Engineer' 代理的报告任务
ini
# Task for Frontend Engineer
reporting_task = Task(
description = ("Compile the results into a detailed report in a HTML file."),
expected_output = (
"An HTML file with the results in the following format:"
"Top 10 AI Research Papers published on {date}"
"- Title (which on clicking opens the paper in a new tab)"
"- Authors"
"- Short summary of the abstract (2-4 sentences)"
),
agent = frontend_engineer,
context = [research_task],
output_file = "./ai_research_report.html",
human_input = True,
)参数 context 确保此任务依赖于 research_task 的输出,并将其用作上下文。参数 output_file 指定了任务结果必须保存的位置(输出文件的名称和位置)。
步骤6:创建Crew
在这一步中,我们使用初始化的代理和任务创建一个团队。
ini
arxiv_research_crew = Crew(
agents = [researcher, frontend_engineer],
tasks = [research_task, reporting_task],
verbose = True,
)请注意,Crew 有一个名为 Process 的可选参数,其默认值为 sequential。
这确保每个代理依次运行。但是我们可以将其值设置为分层,并定义另一个代理,该代理充当管理者,根据其他代理的能力、审查输出并评估任务完成情况来监督和分配任务。
以下是我们的团队Crew整体情况:
 编辑
编辑
步骤7:运行团队并对其结果进行反馈
在定义代理和任务时,我们使用了占位符"date"。我们可以通过使用kickoff方法运行crew时传递此占位符的值,如下所示。
ini
crew_inputs = {
"date" : "2025-03-12"
}
result = arxiv_research_crew.kickoff(inputs = crew_inputs)And there we go!
 编辑
编辑
步骤8:改进crew
您应该意识到,由于在过程中使用了大量标记,使用 LLM 作为代理可能会很昂贵。
以下是一些关于如何改进这一多代理系统的建议:
- 使用开源模型替代 GPT-4o-mini:可以使用 Ollama 等开源模型来替代 GPT-4o-mini,从而降低成本。
- 不同角色使用不同 LLM:可以根据不同角色的需求,使用不同大小的 LLM。例如,使用更大的模型进行研究,使用更小的模型进行结果报告。
- 建立分层团队:可以建立一个分层团队,其中不同角色负责搜索不同的 ArXiv 发表类别。
- 改进搜索和检索工具:可以改进搜索和检索工具,以从研究论文中提取最相关的数据字段,从而节省 LLM 令牌。
- 标准化输出文件布局:可以标准化输出文件的布局,例如统一标题格式、段落间距等。
关注公众号:智汇说 学习交流