嘿,各位爬虫爱好者和自动化达人们!是不是经常遇到这种情况:信心满满地写好爬虫,requests一把梭,结果抓下来的HTML里,想要的数据空空如也?定睛一看,原来数据是靠JavaScript动态加载出来的!比如:
- 电商评论: 滚动到底部才加载更多评论,或者点击按钮异步获取。
- 社交媒体: 无限滚动的信息流,不模拟滚动根本拿不到旧数据。
- 后台管理: 复杂的Web应用,按钮、表单交互后才显示内容。
传统基于HTTP请求的爬虫库(如 requests)面对这些"活"的页面,就像拿着一张静态照片去理解一个正在播放的电影,根本无从下手。我们拿到的只是最初始的HTML骨架,那些由JS在浏览器里"活生生"渲染出来的内容,requests 是看不到的。
这时候,很多同学可能会卡壳,甚至觉得Python爬虫是不是搞不定这种"高级货"了?别急,今天就给大家介绍一款"降维打击"的神器------Selenium!它能像真人一样操作浏览器,你看到啥,它就能"看到"啥,动态JS渲染?小菜一碟!
咱们的目标就是,让你彻底告别看到动态页面就头疼的窘境,轻松驾驭浏览器自动化,无论是数据采集还是自动化办公,都能得心应手!
⚠️ 重要声明:
本文旨在介绍和探讨 Selenium 自动化技术及其应用原理。所有示例和代码仅供学习和研究目的 。切勿用于非法爬取、侵犯隐私或任何可能损害他人利益的行为。
2. 技术原理图解:Selenium是如何"驯服"浏览器的?
那么,Selenium到底是怎么做到控制浏览器的呢?它不是直接和浏览器本身对话,而是通过一个叫做 WebDriver 的"翻译官",更准确地说,是一个实现了 W3C WebDriver 规范(或者旧版的 JSON Wire Protocol)的服务进程。
你可以把整个过程想象成一个多层翻译和执行的链条:
- 你的Python脚本 (客户端): 使用 Selenium 提供的 Python 库编写指令,比如
driver.find_element(By.ID, 'kw').send_keys('...')。 - Selenium Python库: 将这些高级的面向对象调用,转化为符合 W3C WebDriver 协议 的标准 HTTP 请求。这个协议本质上是一套 RESTful API 规范,定义了如何通过 HTTP 命令来与 WebDriver 服务交互(例如,一个
POST /session/{session id}/element请求可能用于查找元素)。 - WebDriver服务 (中间人/驱动程序): 这是一个独立的服务器进程(比如
chromedriver.exe,geckodriver.exe),它监听来自 Selenium 客户端库的 HTTP 请求。每个浏览器厂商(Google, Mozilla, Apple, Microsoft)都会提供自己的 WebDriver 实现。 - 解析与转换: WebDriver 服务接收到 HTTP 请求后,解析其中的命令(比如"查找 ID 为 'kw' 的元素"),然后将其翻译成浏览器自身能够理解的底层自动化指令或API调用(这部分是浏览器厂商的内部实现,可能涉及浏览器的调试协议、内部API或其他机制)。
- 浏览器 (执行者): 最终,浏览器执行这些底层指令,完成相应的操作(打开URL、查找DOM元素、模拟点击、执行JS代码等)。
- 结果反馈: 浏览器将操作结果返回给 WebDriver 服务,WebDriver 服务再将结果封装成 HTTP 响应,通过网络发送回 Selenium 客户端库,最终反映到你的 Python 脚本中(比如
find_element返回一个 WebElement 对象,或者抛出异常)。

这个 WebDriver 服务是核心!它充当了你的脚本和真实浏览器之间的桥梁。你需要下载与你目标浏览器版本精确匹配的 WebDriver 可执行文件,并让 Selenium 脚本能够找到并启动这个服务(通常通过指定其路径或将其放在系统 PATH 中)。
核心组件 (再细化):
- Selenium Client Libraries (Python绑定): 提供易于使用的API,隐藏了底层HTTP通信细节。
- W3C WebDriver Protocol: 定义了客户端与WebDriver服务之间通信的HTTP端点、请求/响应格式(通常是JSON)。这是实现跨浏览器兼容性的关键标准。
- Browser Drivers (WebDriver服务实现): 浏览器厂商提供的、遵循W3C协议的HTTP服务器。它们负责将标准化的WebDriver命令转换为特定浏览器的控制指令。
- Browsers: 具备被自动化控制能力的现代浏览器。
理解了这个基于标准协议的、分层的通信和执行流程,你就能更深刻地明白:
- 为什么需要特定版本的驱动? 因为浏览器内部的自动化接口会随着浏览器更新而变化,驱动必须适配这些变化才能正确翻译和执行命令。
- 为什么Selenium能执行JS? 因为它最终操作的是一个完整的、具有JS引擎的真实浏览器环境。
- 为什么Selenium相对较慢? 因为涉及了客户端库、WebDriver服务、浏览器之间的多层通信(通常是本地HTTP),以及真实浏览器的渲染和执行开销。
接下来,我们就看看如何在Python代码里具体使用这个强大的工具,与这些组件进行交互。
3. 实战代码教学:从环境搭建到元素交互
原理搞明白了,接下来就是上手实操了!我们一步步来看如何用Python代码来"指挥"浏览器。
3.1 环境准备:安装库与配置驱动
万事开头难,先把环境搭好。
-
安装Selenium库: 这个最简单,打开你的终端(命令行),直接pip:
bashpip install selenium建议使用虚拟环境,避免库版本冲突,这是个好习惯!
-
下载WebDriver: 这是关键一步,也是新手容易踩坑的地方。
- 确定浏览器和版本: 先看看你电脑上安装了哪个浏览器(推荐Chrome或Firefox),以及它的版本号。在浏览器地址栏输入
chrome://version(Chrome) 或about:support(Firefox) 就能看到。 - 下载对应驱动:
- ChromeDriver: https://chromedriver.chromium.org/downloads (注意!ChromeDriver的版本需要严格匹配 你的Chrome浏览器版本,或者至少是大版本号匹配,小版本号接近。官网通常会说明哪个驱动版本对应哪个浏览器版本范围)。 从 Chrome 115 版本开始,驱动下载地址变成了 Chrome for Testing availability,在这里找对应你浏览器版本的
chromedriver。 - GeckoDriver (Firefox): https://github.com/mozilla/geckodriver/releases
- ChromeDriver: https://chromedriver.chromium.org/downloads (注意!ChromeDriver的版本需要严格匹配 你的Chrome浏览器版本,或者至少是大版本号匹配,小版本号接近。官网通常会说明哪个驱动版本对应哪个浏览器版本范围)。 从 Chrome 115 版本开始,驱动下载地址变成了 Chrome for Testing availability,在这里找对应你浏览器版本的
- 放置WebDriver: 下载的是一个可执行文件(比如
chromedriver.exe或geckodriver)。你有两种方式让Selenium找到它:- 推荐: 将这个文件放到你的Python项目目录下,或者一个你知道路径的地方,然后在代码里明确指定它的路径。
- 或者: 将这个文件所在的目录添加到系统的环境变量
PATH中。这样Selenium会自动查找。但个人觉得不如第一种方法项目独立性强。
【避坑指南】版本不匹配! 90%的新手问题都出在WebDriver版本和浏览器版本不对应上。如果运行代码时报错,提示类似
SessionNotCreatedException或版本相关的错误,第一反应就是检查你的驱动版本和浏览器版本是否匹配!不匹配就去下载正确的驱动版本。 - 确定浏览器和版本: 先看看你电脑上安装了哪个浏览器(推荐Chrome或Firefox),以及它的版本号。在浏览器地址栏输入
3.2 基础操作:启动、访问与关闭
环境好了,咱们来写点简单的代码,让浏览器动起来。
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.firefox.service import Service as FirefoxService
# 如果你用的是比较新的 Selenium (4.x+), 推荐用 Service 对象指定驱动路径
# ChromeDriver 路径 (根据你的实际路径修改)
chrome_driver_path = '/path/to/your/chromedriver' # Linux/macOS
# chrome_driver_path = r'C:\\path\\to\\your\\chromedriver.exe' # Windows (注意路径转义)
# FirefoxDriver (GeckoDriver) 路径
# firefox_driver_path = '/path/to/your/geckodriver'
# --- 初始化 Chrome WebDriver ---
chrome_service = ChromeService(executable_path=chrome_driver_path)
driver = webdriver.Chrome(service=chrome_service)
# --- 或者 初始化 Firefox WebDriver ---
# firefox_service = FirefoxService(executable_path=firefox_driver_path)
# driver = webdriver.Firefox(service=firefox_service)
# 如果驱动已经在系统PATH中,可以简化为:
# driver = webdriver.Chrome()
# driver = webdriver.Firefox()
# 1. 打开网页 (示例:一个通用的搜索引擎首页)
target_url = "https://www.example-search-engine.com"
driver.get(target_url)
print(f"成功打开页面: {driver.title}") # 获取并打印页面标题
# 2. 浏览器导航
print("3秒后后退...")
import time
time.sleep(3)
driver.back() # 后退
print(f"后退后页面: {driver.title}")
time.sleep(2)
driver.forward() # 前进
print(f"前进后页面: {driver.title}")
time.sleep(2)
driver.refresh() # 刷新
print("页面已刷新")
# 3. 获取当前URL
print(f"当前页面URL: {driver.current_url}")
# 4. 关闭浏览器
print("关闭浏览器...")
# driver.close() # close() 只关闭当前窗口,如果只有一个窗口,效果等于quit()
# quit() 会关闭所有关联的窗口,并彻底退出WebDriver进程,推荐使用!
driver.quit()
print("浏览器已关闭")这段代码演示了最基本的操作:初始化驱动、打开网页、后退、前进、刷新、获取信息以及关闭浏览器。很简单吧?
【实用技巧】无头模式 (Headless Mode): 有时候我们跑自动化脚本,并不需要真的看到浏览器窗口弹出来,尤其是在服务器上运行爬虫时。可以使用无头模式:
python
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless") # 关键参数
chrome_options.add_argument("--disable-gpu") # 在某些系统或无头模式下需要加这个
chrome_service = ChromeService(executable_path=chrome_driver_path)
driver = webdriver.Chrome(service=chrome_service, options=chrome_options)
# 后面操作一样,只是你看不到浏览器界面了
driver.get("https://www.example-search-engine.com")
print(f"无头模式下获取标题: {driver.title}")
driver.quit()无头模式能节省一些系统资源,让你的脚本在后台默默运行。
3.3 元素定位:找到你要操作的那个它
打开网页只是第一步,我们最终目的是要和页面上的元素(按钮、输入框、链接、文本等)进行交互。要交互,就得先定位到这些元素。
Selenium提供了多种定位策略,就像给元素找地址一样,条条大路通罗马:
python
from selenium.webdriver.common.by import By
# 假设 driver 已经打开了目标网页
# 1. 通过 ID 定位 (最快、最推荐,前提是元素有唯一ID)
# <input type="text" id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
search_box_by_id = driver.find_element(By.ID, "kw")
# 2. 通过 Name 属性定位
search_box_by_name = driver.find_element(By.NAME, "wd")
# 3. 通过 Class Name 定位 (注意:如果class有多个,用这个方法只能匹配第一个)
# <input type="submit" id="su" value="百度一下" class="bg s_btn">
search_button_by_class = driver.find_element(By.CLASS_NAME, "s_btn")
# 4. 通过 Tag Name 定位 (通常返回多个,需要小心)
# 比如查找页面上所有的 <a> 标签 (链接)
links = driver.find_elements(By.TAG_NAME, "a") # 注意是 find_elements (复数)
print(f"页面上共有 {len(links)} 个链接")
# 5. 通过 Link Text 定位 (精确定位链接)
# <a href="http://news.baidu.com" target="_blank" class="mnav">新闻</a>
news_link = driver.find_element(By.LINK_TEXT, "新闻")
# 6. 通过 Partial Link Text 定位 (模糊定位链接)
# <a href="http://map.baidu.com" target="_blank" class="mnav">地图</a>
map_link = driver.find_element(By.PARTIAL_LINK_TEXT, "地")
# 7. 通过 CSS Selector 定位 (强大且常用)
# 定位ID为'kw'的元素: #kw
search_box_by_css_id = driver.find_element(By.CSS_SELECTOR, "#kw")
# 定位class为's_btn'的元素: .s_btn
search_button_by_css_class = driver.find_element(By.CSS_SELECTOR, ".s_btn")
# 定位标签名为'input'且type属性为'submit'的元素: input[type='submit']
search_button_by_css_attr = driver.find_element(By.CSS_SELECTOR, "input[type='submit']")
# 组合定位:ID为'head'下的class为'mnav'的第一个<a>元素: #head .mnav:nth-child(1)
first_nav_link = driver.find_element(By.CSS_SELECTOR, "#head .mnav:nth-child(1)")
# 8. 通过 XPath 定位 (功能最强大,语法稍复杂)
# 定位ID为'kw'的元素: //*[@id='kw']
search_box_by_xpath_id = driver.find_element(By.XPATH, "//*[@id='kw']")
# 定位文本内容为'新闻'的<a>元素: //a[text()='新闻']
news_link_by_xpath_text = driver.find_element(By.XPATH, "//a[text()='新闻']")
# 定位包含文本'地图'的<a>元素: //a[contains(text(), '地')]
map_link_by_xpath_contains = driver.find_element(By.XPATH, "//a[contains(text(), '地')]")
# 定位class包含's_btn'的<input>元素: //input[contains(@class, 's_btn')]
search_button_by_xpath_class = driver.find_element(By.XPATH, "//input[contains(@class, 's_btn')]")选择哪种定位方式?
- 优先ID: 如果元素有唯一且稳定的ID,这是最好的选择,速度快且准确。
- 次选CSS Selector: 非常灵活,语法相对XPath简洁,性能通常比XPath好。前端开发者很熟悉它。
- 再选XPath: 功能最强大,可以处理各种复杂的层级关系、属性、文本内容定位。但语法相对复杂,性能可能稍差。
- Name/Class/Tag/Link Text: 适用于特定场景,但不如ID、CSS、XPath通用。
find_element vs find_elements
find_element(...): 只查找第一个 匹配的元素。如果找不到,会抛出NoSuchElementException异常。find_elements(...): 查找所有 匹配的元素,返回一个列表。如果一个都找不到,返回一个空列表,不会抛异常。

熟练掌握元素定位是Selenium自动化的基础,建议多用浏览器开发者工具(按F12)练习,右键点击元素选择"检查"(Inspect),可以方便地看到元素的HTML结构和属性,甚至直接复制CSS Selector或XPath。
3.4 元素交互:模拟用户的真实操作
找到元素后,就可以模拟用户操作了:
python
# 假设已经定位到元素:search_box, search_button, news_link
# 1. 输入文本 (用于输入框、文本域)
search_box.send_keys("Python Selenium教程")
print("已在搜索框输入文字")
time.sleep(1)
# 2. 清空输入框
search_box.clear()
print("已清空搜索框")
time.sleep(1)
search_box.send_keys("CSDN 博客")
# 3. 点击元素 (按钮、链接等)
search_button.click()
print("已点击搜索按钮")
time.sleep(3) # 等待搜索结果加载
# 4. 获取元素属性
# 假设搜索结果页第一个链接是 <a ... href="some_url" ...>
first_result_link = driver.find_element(By.CSS_SELECTOR, "#content_left .result h3 a") # 示例选择器
href = first_result_link.get_attribute("href")
print(f"第一个搜索结果链接: {href}")
# 5. 获取元素文本内容
link_text = first_result_link.text
print(f"第一个搜索结果标题: {link_text}")
# 6. 判断元素状态 (返回布尔值)
# is_displayed(): 是否可见 (不一定可交互)
# is_enabled(): 是否可用 (比如按钮是否是灰色不可点的)
# is_selected(): 是否被选中 (用于单选框、复选框)
search_button_again = driver.find_element(By.ID, "su") # 重新定位,因为页面刷新了
if search_button_again.is_displayed() and search_button_again.is_enabled():
print("搜索按钮可见且可用")
# 7. 提交表单 (可以对表单内的任意元素调用submit)
# search_box.submit() # 对搜索框调用submit,效果通常等同于点击搜索按钮
# driver.quit() # 最后别忘了关闭这些交互方法覆盖了大部分常见的用户操作。
3.5 等待机制:应对动态加载的"杀手锏"
这是Selenium中最重要,也是最容易出问题的地方!为什么需要等待?
现代网页大量使用JavaScript和AJAX技术,很多内容不是页面一打开就有的,而是需要一点时间去加载、渲染。你的 Python 脚本执行速度通常远快于浏览器渲染速度和网络请求速度。如果代码跑得太快,在元素还没出现在DOM里、或者虽然出现了但还不可见、或者可见但还不可交互(比如被遮挡、还在加载动画中)时就去操作它,必然会报错(常见的有 NoSuchElementException - 找不到元素,ElementNotVisibleException - 元素不可见,ElementNotInteractableException - 元素不可交互等)。
想象一下,你让机器人去按一个按钮,但那个按钮要等3秒钟才会从屏幕下面平滑地弹出来,或者弹出来后还要等网络请求返回数据才能变成可点击状态。机器人不等,在第1秒就伸手去按,结果按了个空(找不到元素),或者按到了但按钮还没准备好(不可交互),肯定失败。
Selenium提供了几种等待策略来解决这个时序同步问题:
-
强制等待 (
time.sleep(秒数)) - 强烈不推荐!- 原理: 简单粗暴,让你的Python脚本线程暂停执行指定的秒数,不管浏览器那边发生了什么。
- 缺点: 纯粹是"死等",无法感知浏览器状态。时间设长了,在元素早就准备好的情况下干等,浪费大量时间,脚本效率极低;时间设短了,元素可能还没准备好,导致脚本失败,非常不稳定。这是最原始、最不可靠的方式,应该极力避免在实际项目中使用。
-
隐式等待 (
driver.implicitly_wait(秒数))- 原理: 设置一个全局 的超时时间(比如10秒)。它只作用于
find_element和find_elements这两个查找元素的方法。当调用这些方法时,如果在DOM中 没有立即找到元素,WebDriver 不会立刻抛出NoSuchElementException,而是在后台以一定的频率(通常是几百毫秒)反复轮询检查DOM,直到找到元素或者超过设定的全局超时时间。如果超时仍未找到,才抛出异常。 - 优点: 设置一次,全局生效,代码相对简洁。
- 缺点:
- 作用范围有限: 只管"找没找到",不管元素是否可见、是否可点击。找到一个隐藏的元素,它也立刻返回,后续操作这个隐藏元素可能依然报错。
- 不够灵活: 无法针对特定元素设置不同的等待时间或更复杂的等待条件。
- 可能掩盖问题: 有时元素确实加载很慢,隐式等待能解决;但有时是定位器写错了,隐式等待也会傻傻地等到超时,反而延迟了发现错误。
- 全局性陷阱: 如果设置了较长的隐式等待,可能会拖慢整个脚本的执行速度,因为每次查找不存在的元素都要等待很久。
pythondriver.implicitly_wait(10) # 设置全局隐式等待10秒 # 后续调用 driver.find_element(By.ID, "maybe_late_element") 时: # - 如果元素立刻在DOM中找到,则立即返回。 # - 如果没找到,WebDriver会在后台轮询DOM最多10秒。 # - 如果10秒内元素出现在DOM中,则返回该元素。 # - 如果10秒后元素仍未在DOM中出现,则抛出 NoSuchElementException。 - 原理: 设置一个全局 的超时时间(比如10秒)。它只作用于
-
显式等待 (
WebDriverWait+expected_conditions) - 强烈推荐!-
原理: 这是针对特定条件 的主动等待。你创建一个
WebDriverWait对象,指定一个最长等待时间(timeout)和一个轮询检查频率(poll_frequency,默认0.5秒)。然后调用其until()或until_not()方法,传入一个期望条件 (Expected Condition) 。WebDriver 会在最长等待时间内,按照指定的频率反复调用这个期望条件 进行检查,直到条件满足(返回True或非None、非False的值),until()方法会返回检查结果(通常是定位到的元素或True);如果超时后条件仍未满足,则抛出TimeoutException。 -
最可靠、最灵活的方式。你可以精确地等待某个元素出现、可见、可点击,或者等待某个元素的文本符合预期、页面标题改变、Alert框出现等等。
-
需要导入:
pythonfrom selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.common.exceptions import TimeoutException -
常用姿势:
python# 等待ID为'dynamic_button'的元素出现并可点击,最多等10秒 try: wait = WebDriverWait(driver, 10, poll_frequency=0.2) # 创建等待器,最多等10秒,每0.2秒检查一次 # until() 方法会反复调用 EC.element_to_be_clickable(...) 这个函数 # 该函数接收 driver 作为参数,内部会先找元素,再判断是否可见和可用 clickable_button = wait.until( EC.element_to_be_clickable((By.ID, "dynamic_button")) # 传入定位器元组 ) # 如果在10秒内条件满足(按钮可点击),clickable_button 就是定位到的WebElement对象 print("按钮已可点击,执行点击操作") clickable_button.click() except TimeoutException: # 如果10秒后 EC.element_to_be_clickable() 仍然返回False或抛出异常 print("等待超时!按钮在10秒内未能变为可点击状态") -
expected_conditions(EC) 模块提供了大量预定义的、非常实用的条件函数:presence_of_element_located(locator): 等待元素存在于DOM中。不保证可见或可交互。visibility_of_element_located(locator): 等待元素存在于DOM中且可见 (display不是none,宽高大于0)。element_to_be_clickable(locator): 等待元素可见且可用(enabled)。这是进行点击操作前最常用的等待条件。text_to_be_present_in_element(locator, text_): 等待指定元素的textContent包含特定文本。invisibility_of_element_located(locator): 等待元素从DOM中消失或变为不可见。alert_is_present(): 等待页面上出现 JavaScriptalert,confirm, 或prompt弹窗。staleness_of(element): 等待一个之前定位到的元素不再附加到DOM上(常用于判断页面是否已刷新或发生变化)。- ...还有很多,强烈建议查阅 Selenium Python 客户端的
expected_conditions文档。
-
你甚至可以自定义等待条件:
until()方法可以接受任何可调用的对象(函数、lambda表达式、实现了__call__方法的类实例),只要它接收driver作为参数并返回期望的结果(True/对象表示成功,False/None表示继续等待)。
-
为什么显式等待最好?
- 目标明确: 只等待你关心的特定状态,而不是盲目等待时间。
- 高效: 条件一旦满足立刻继续执行,最大限度减少不必要的等待。
- 可靠: 能精确处理各种复杂的异步加载场景,大大提高脚本的健壮性。
- 可读性强: 代码意图清晰,明确表达了"我在等待什么条件发生"。
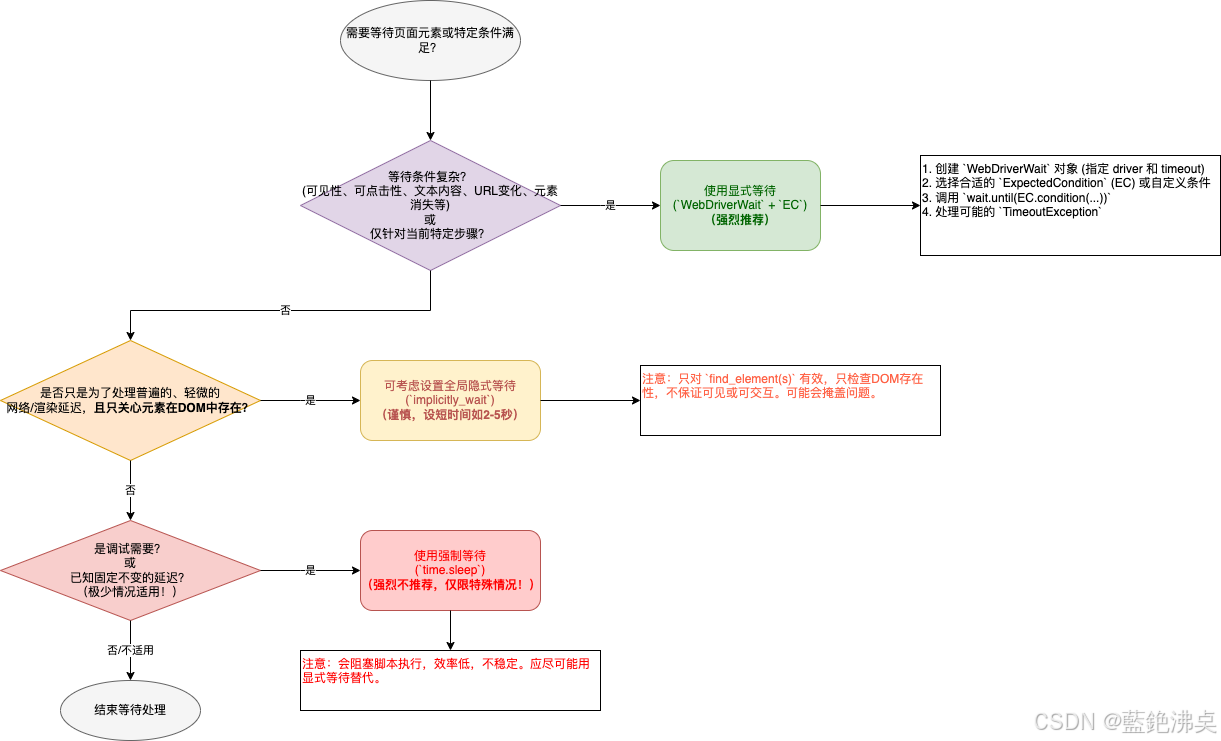
经验之谈: 在实际项目中,通常会混用隐式等待和显式等待。
- 设置一个较短的全局隐式等待(比如 2-5 秒),用于处理那些普遍存在的、轻微的网络延迟或DOM渲染延迟,简化一部分
find_element调用。 - 在需要进行关键交互(如点击、输入)之前,或者需要等待特定状态(如元素消失、文本出现)时,必须使用显式等待 ,并选择最贴切的
expected_conditions,设置合理的超时时间。 - 绝对避免使用
time.sleep()来同步状态!
4. 实战案例:爬取动态加载的电商评论
理论说了这么多,不如来个实战练练手!咱们就挑一个常见的场景:爬取某个大型电商平台的商品评论。这些评论往往不是一次性加载完的,需要你向下滚动或者点击"加载更多"才能看到后面的内容。
案例背景与应用场景:
想象一下,你想分析某款热门手机的用户评价,看看大家都在吐槽什么、点赞什么,或者你想监控竞品的口碑。手动一条条复制粘贴?那不得累死!用 requests 抓?抓不到动态加载的评论。这时候,就轮到 Selenium 大显身手了!我们可以用它模拟用户浏览、滚动、点击的操作,把所有评论都"刷"出来,然后一网打尽。
目标: 爬取指定商品页面的所有评论信息(用户昵称、评论内容、评论时间等)。
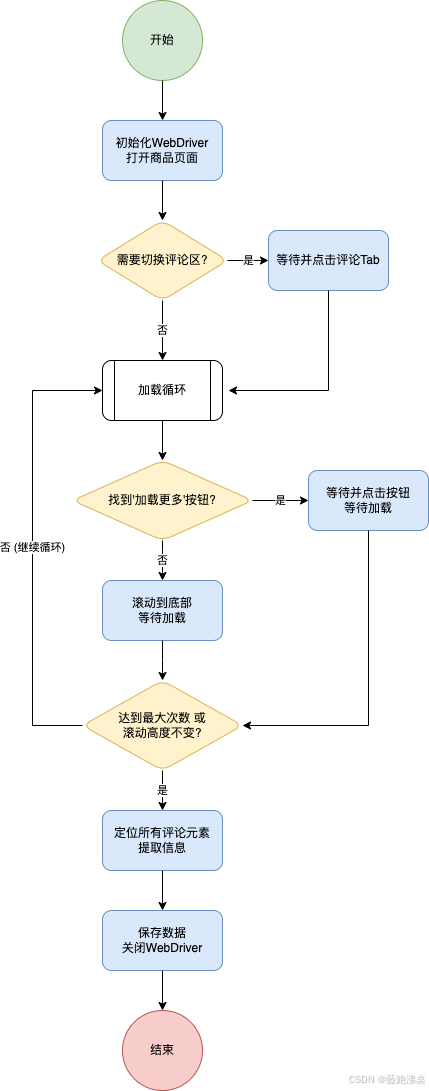
核心思路:
- 启动浏览器,打开商品页。
- (可选)如果评论不在默认标签页,先点击切换到评论区。
- 循环执行:向下滚动页面 / 点击"加载更多"按钮。
- 判断是否已加载完所有评论(比如滚动到底部且高度不再增加,或"加载更多"按钮消失/变灰)。
- 所有评论加载完毕后,定位所有评论元素,并提取所需信息。
- 保存数据,关闭浏览器。
代码实现 (关键步骤拆解):
(完整代码请参考 codes/dynamic_comment_scraper.py 文件,并务必阅读其中的 README.md 进行配置和修改!)
步骤1:初始化WebDriver并打开目标页面
python
# (导入必要的库...)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException
import time
# 配置项 (需要根据实际情况修改)
chrome_driver_path = '/path/to/your/chromedriver' # 驱动路径
# 使用通用示例 URL,实际使用时需替换
product_url = "https://www.example-ecommerce.com/product/123/reviews"
# (初始化 WebDriver, 设置 options 等...)
# ... driver = webdriver.Chrome(...) ...
try:
driver.get(product_url)
print(f"成功打开页面: {driver.title}")
except Exception as e:
print(f"打开页面失败: {e}")
# ... 错误处理 ...- 关键点:正确配置
chrome_driver_path和product_url。
步骤2:定位并点击"评论"标签页(如果需要)
python
# !! 定位器需要根据实际网站修改 !!
comment_tab_locator = (By.XPATH, '//a[contains(text(), "商品评论")] | //li[contains(text(), "累计评价")]')
try:
comment_tab = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable(comment_tab_locator)
)
driver.execute_script("arguments[0].click();", comment_tab) # 尝试JS点击
print("已点击评论标签页")
time.sleep(2) # 等待评论区加载
except TimeoutException:
print("未找到或无法点击评论标签页, 可能评论默认显示")
# ... 更多异常处理 ...- 关键点:使用
WebDriverWait和EC.element_to_be_clickable确保标签页可点击;定位器comment_tab_locator必须根据目标网站的HTML结构调整。
步骤3:模拟滚动或点击"加载更多"
python
MAX_SCROLLS = 15 # 设置最大尝试次数,防止死循环
scroll_count = 0
last_height = driver.execute_script("return document.body.scrollHeight")
while scroll_count < MAX_SCROLLS:
try:
# 优先找"加载更多"按钮
# !! 定位器需要根据实际网站修改 !!
load_more_locator = (By.XPATH, '//button[contains(text(), "加载更多")] | //div[contains(@class, "load-more")] | //a[contains(text(), "下一页")]')
load_more_button = WebDriverWait(driver, 5).until(
EC.element_to_be_clickable(load_more_locator)
)
print("找到'加载更多'按钮,点击加载...")
driver.execute_script("arguments[0].scrollIntoView(true);"); time.sleep(0.5)
driver.execute_script("arguments[0].click();", load_more_button)
scroll_count += 1
time.sleep(3) # 等待加载
except TimeoutException:
# 没找到按钮,尝试滚动
print("未找到'加载更多'按钮,尝试向下滚动页面...")
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);");
time.sleep(3)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
print("滚动到底部,没有更多评论加载。")
break
last_height = new_height
scroll_count += 1
# ... 更多异常处理 ...
if scroll_count == MAX_SCROLLS:
print(f"达到最大尝试次数 ({MAX_SCROLLS})。")- 关键点:循环结构;优先尝试点击"加载更多"按钮,失败则尝试滚动;通过比较滚动前后页面高度判断是否已滚动到底部;设置
MAX_SCROLLS防止无限循环;同样,load_more_locator需要根据实际情况修改。
步骤4:定位并提取所有已加载的评论信息
python
comments_data = []
try:
# !! 定位器需要根据实际网站修改 !!
comment_item_locator = (By.CSS_SELECTOR, 'div.comment-item, li.rate-item, .ReviewCard')
# 等待至少一个评论元素出现
WebDriverWait(driver, 15).until(
EC.presence_of_all_elements_located(comment_item_locator)
)
comment_elements = driver.find_elements(*comment_item_locator)
print(f"找到 {len(comment_elements)} 条评论,开始提取...")
for comment_element in comment_elements:
try:
# !! 内部元素的定位器也需要修改 !!
user_name = comment_element.find_element(By.CSS_SELECTOR, 'span.user-name, .name, .userName').text.strip()
comment_text = comment_element.find_element(By.CSS_SELECTOR, 'p.comment-content, .content, .review-content, .J_brief-cont').text.strip()
comment_date = comment_element.find_element(By.CSS_SELECTOR, 'span.comment-date, .time, .review-date').text.strip()
comments_data.append({
'user': user_name,
'content': comment_text,
'date': comment_date
})
except NoSuchElementException:
print("某个评论元素结构不完整或定位器错误,跳过")
except Exception as e:
print(f"提取单个评论时出错: {e}")
except TimeoutException:
print("等待评论元素加载超时。")
# ... 更多异常处理 ...
finally:
if driver:
driver.quit()
print(f"\n提取完成,共获取 {len(comments_data)} 条评论数据。")
# 可以将 comments_data 保存到文件 (如JSON)
# import json
# with open('comments.json', 'w', encoding='utf-8') as f:
# json.dump(comments_data, f, ensure_ascii=False, indent=4)- 关键点:等待所有评论加载完后,使用
find_elements定位所有评论项;遍历每个评论项,再使用find_element定位内部的具体信息(用户名、内容、日期等);处理NoSuchElementException等异常,防止因单个评论结构问题导致整个脚本崩溃;最后记得driver.quit()。 - 最重要的:
comment_item_locator以及内部的user_name,comment_text,comment_date的定位器必须根据你实际爬取的网站进行调整!这是决定成败的关键。
案例总结与关键点强调:
这个实战案例完美体现了Selenium处理动态网页的核心价值:
- 模拟交互: 成功模拟了点击标签页、滚动页面、点击"加载更多"等用户行为,触发了数据加载。
- 显式等待: 大量运用
WebDriverWait和expected_conditions来确保在操作元素前,元素已经加载完成并处于正确的状态(如可点击)。这是保证脚本稳定性的核心。 - 动态定位: 演示了如何定位动态加载出来的元素,并从中提取数据。
- 错误处理: 加入了基本的
try...except结构来应对可能出现的超时、元素找不到等问题。

掌握了这个案例的流程和技巧,你就基本具备了使用Selenium爬取大部分动态加载网页的能力。记住,定位器的准确性 和等待策略的合理运用是成功的两大基石!
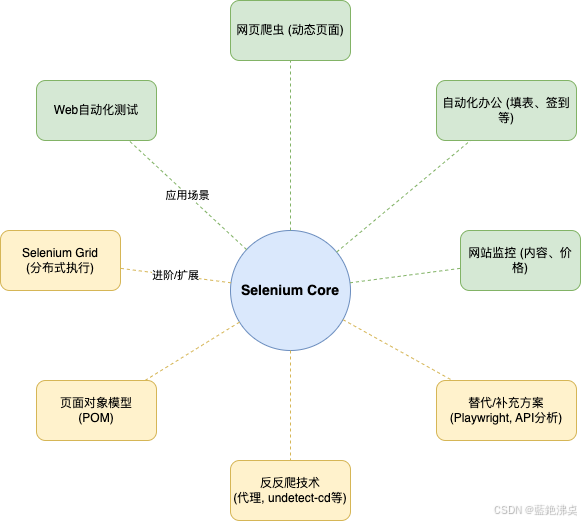
5. 扩展应用与进阶:Selenium还能玩出什么花样?
掌握了Selenium的基础和动态页面处理,你就打开了一扇通往自动化世界的大门!除了爬虫,Selenium还能在很多场景发光发热:
- Web自动化测试: 这是Selenium的老本行,可以模拟用户操作流程,验证网站功能是否正常。
- 自动化办公: 自动填报表、自动登录系统签到、批量处理网页数据录入... 解放双手,告别重复劳动!想想每天帮你自动打卡的脚本,是不是很香?
- 监控任务: 定期检查网站内容变化、价格变动、服务状态等。
- 与其它库结合:
- Selenium + Scrapy: 在Scrapy的下载中间件中使用Selenium处理需要JS渲染的请求,结合Scrapy强大的爬虫框架能力。
- Selenium + Pandas/Excel: 爬取数据后直接用Pandas进行分析处理,或写入Excel文件。
- Selenium + PyAutoGUI: 对于某些Selenium无法直接操作的浏览器插件、弹窗或需要与桌面交互的场景,可以结合PyAutoGUI模拟键盘鼠标操作。
进阶学习路径推荐:
- Selenium Grid深入: 想并行跑多个任务,跨不同浏览器和系统?学学Grid分布式执行。
- 处理反爬: 道高一尺魔高一丈,研究更高级的反爬机制(JS混淆、验证码、行为检测)和应对策略(代理IP、
undetected-chromedriver、验证码识别等)。 - 页面对象模型 (POM): 代码写多了,得考虑维护性。POM模式能让你的代码结构更清晰、更易维护,是大型自动化项目的标配。
- 探索替代方案: Selenium虽好,但也有缺点(慢、资源消耗大)。了解下更现代的自动化库,比如 Playwright,它通常更快、API更友好,尤其是在异步处理方面有优势(我们后续文章可能会聊到)。或者,如果能分析出网站的AJAX接口,直接模拟API请求通常是最高效的方式(但难度也更大)。
6. 互动引导:聊聊你的Selenium奇遇记
看到这里,相信你对Selenium已经有了不错的认识。不知道你在学习或使用Selenium的过程中,遇到过哪些印象深刻的"坑"?或者你用Selenium实现了哪些有趣、实用的自动化小工具?
欢迎在评论区分享你的故事、经验或者疑问!
- 你在哪个环节卡壳最久?(是环境配置?元素定位?还是等待超时?)
- 你觉得Selenium最大的优点和缺点是什么?
- 需要本文完整的实战代码和WebDriver配置指南吗?评论区告诉我!
**后续我会持续分享更多Python实用工具、数据采集和AI应用相关的干货!