文章目录
-
- 一、DAX概述
-
- [1.1 DAX公式语法](#1.1 DAX公式语法)
-
- [1.1.1 DAX公式语法](#1.1.1 DAX公式语法)
- [1.1.2 DAX公式格式](#1.1.2 DAX公式格式)
- [1.2 DAX编辑器快捷键](#1.2 DAX编辑器快捷键)
- [1.3 DAX函数简介](#1.3 DAX函数简介)
-
- [1.3.1 DAX函数特性(DAX上下文)](#1.3.1 DAX函数特性(DAX上下文))
- [1.3.2 计算列](#1.3.2 计算列)
- [1.3.3 计算表](#1.3.3 计算表)
- [1.3.4 常见错误](#1.3.4 常见错误)
- [1.4 运算符及其优先级](#1.4 运算符及其优先级)
-
- [1.4.1 运算符简介](#1.4.1 运算符简介)
- [1.4.2 IN运算符详解](#1.4.2 IN运算符详解)
- [1.5 DAX Queries](#1.5 DAX Queries)
- [二、 逻辑函数](#二、 逻辑函数)
-
- [2.1 AND、OR、NOT函数](#2.1 AND、OR、NOT函数)
- [2.2 IF、IFERROR](#2.2 IF、IFERROR)
- [2.3 SWITCH 函数](#2.3 SWITCH 函数)
- 三、DAX语句
-
- [3.1 VAR关键字](#3.1 VAR关键字)
-
- [3.1.1 简化计算](#3.1.1 简化计算)
- [3.1.2 替代EARLIER函数](#3.1.2 替代EARLIER函数)
- [3.2 EVALUATE(待补)](#3.2 EVALUATE(待补))
- 四、筛选函数
-
- [4.1 CALCULATE 与 CALCULATETABLE](#4.1 CALCULATE 与 CALCULATETABLE)
-
- [4.1.1 筛选条件为空,只使用外部上下文](#4.1.1 筛选条件为空,只使用外部上下文)
- [4.1.2 使用筛选器,缩小上下文](#4.1.2 使用筛选器,缩小上下文)
- [4.1.3 ALL函数,扩大上下文](#4.1.3 ALL函数,扩大上下文)
- [4.1.4 重置上下文](#4.1.4 重置上下文)
- [4.1.5 相似函数:CALCULATETABLE](#4.1.5 相似函数:CALCULATETABLE)
- [4.1.6 扩展表](#4.1.6 扩展表)
- [4.2 FILTER(复杂筛选)](#4.2 FILTER(复杂筛选))
-
- [4.2.1 语法](#4.2.1 语法)
- [4.2.2 使用`FILTER`函数新建表](#4.2.2 使用
FILTER函数新建表) - [4.2.3 作为筛选参数](#4.2.3 作为筛选参数)
- [4.2.4 分组](#4.2.4 分组)
- [4.3 EARLIER 与 EARLIEST](#4.3 EARLIER 与 EARLIEST)
-
- [4.3.1 示例1:计算排名](#4.3.1 示例1:计算排名)
- [4.3.2 示例2:计算订单日期间隔](#4.3.2 示例2:计算订单日期间隔)
- [4.3.3 示例2:计算每日累计销售额](#4.3.3 示例2:计算每日累计销售额)
- [4.3.4 示例2:计算每种产品累计销量(可用WINDOW函数)](#4.3.4 示例2:计算每种产品累计销量(可用WINDOW函数))
- [4.3.5 分类计数](#4.3.5 分类计数)
- [4.3.6 EARLIEST](#4.3.6 EARLIEST)
- [4.4 ALL vs ALLEXCEPT vs ALLSELECTED](#4.4 ALL vs ALLEXCEPT vs ALLSELECTED)
-
- [4.4.1 ALL函数(计算总体占比和分类占比)](#4.4.1 ALL函数(计算总体占比和分类占比))
- [4.4.2 ALLSELECTED函数(按筛选上下文计算占比)](#4.4.2 ALLSELECTED函数(按筛选上下文计算占比))
- [4.4.3 使用ISINSCOPE计算层级占比](#4.4.3 使用ISINSCOPE计算层级占比)
- [4.4.4 ALLEXCEPT 函数(分组)](#4.4.4 ALLEXCEPT 函数(分组))
-
- [4.4.4.1 计算累计求和与累计占比](#4.4.4.1 计算累计求和与累计占比)
- [4.4.4.2 计算客户最后下单日期(计算列与度量值)](#4.4.4.2 计算客户最后下单日期(计算列与度量值))
- [4.4.5 总结](#4.4.5 总结)
- [4.5 SELECTEDVALUE(动态分析)](#4.5 SELECTEDVALUE(动态分析))
-
- [4.5.1 语法](#4.5.1 语法)
- [4.5.2 动态分析](#4.5.2 动态分析)
- [4.5.3 使用SELECTEDVALUE优化动态计算](#4.5.3 使用SELECTEDVALUE优化动态计算)
- [4.6 LASTNONBLANK 与 LASTNONBLANKVALUE](#4.6 LASTNONBLANK 与 LASTNONBLANKVALUE)
-
- [4.6.1 语法](#4.6.1 语法)
- [4.6.2 库存余额统计](#4.6.2 库存余额统计)
一、DAX概述
分析查询(analytic-queries) 是指向语义模型(即数据模型)进行查询获取结果。在 Power BI 中,用户通过创建各种视觉对象(如表格、柱状图、折线图等)来展示数据,这些视觉对象在后台会向 Power BI 提交分析查询,以从数据模型中获取所需的数据。
分析查询是通过 数据分析表达式(DAX,Data Analysis Expressions) 编写的查询语句,用户只需要通过界面操作,将语义模型中的字段映射到报表的视觉对象中,系统会自动生成对应的 DAX 查询语句。分析查询的执行分为三个阶段:
- 筛选(Filtering)
在这个阶段,系统会根据用户设置的筛选条件(如日期范围、特定类别等),从数据模型中筛选出符合要求的数据。筛选是确保只处理相关数据的关键步骤,可以提高查询效率。 - 分组(Grouping)
筛选后的数据会被分组。分组通常是根据用户在视觉对象中设置的维度字段(如地区、产品类别等)进行的。分组的目的是将数据组织成更易于汇总和分析的形式。 - 汇总(Aggregation)
最后,系统会对分组后的数据进行汇总计算(如求和、平均值、计数等)。汇总结果将被返回到视觉对象中,以展示最终的分析结果。

1.1 DAX公式语法
参考《语法》
1.1.1 DAX公式语法
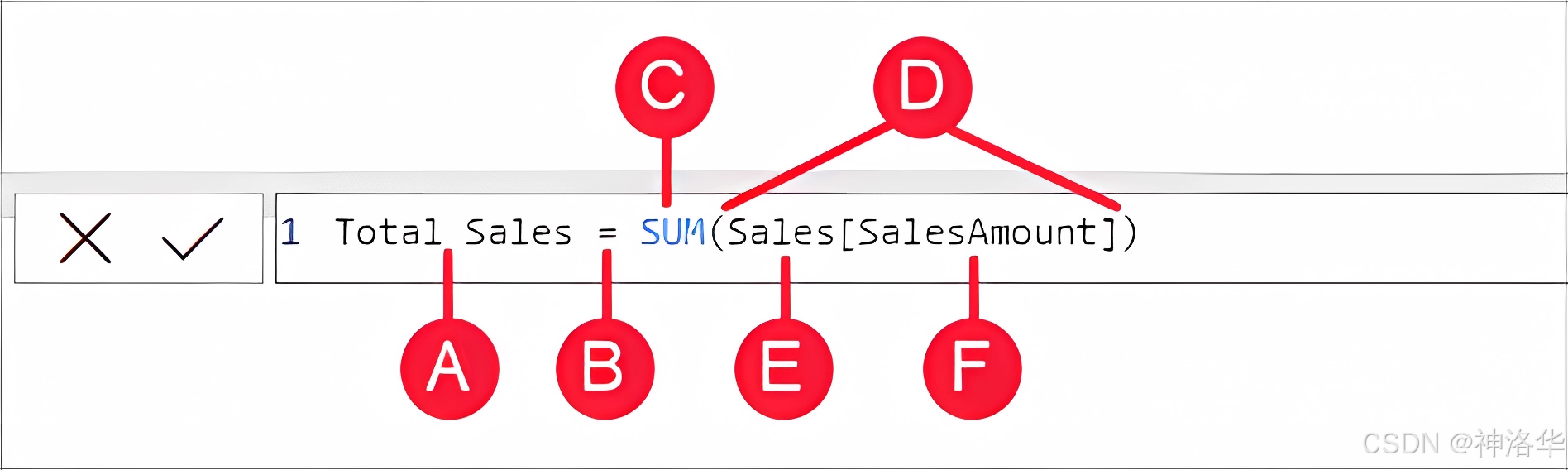
- 公式元素 :
- A:度量值名称
Total Sales。 - B:等号
=,表示公式的开始,计算后将返回结果。 - C:DAX 函数
SUM,用于将Sales[SalesAmount]列中的所有数字相加。 - D:括号
(),包含一个或多个参数的表达式,大多数函数至少需要一个参数。 - E:引用的表
Sales。 - F:
Sales表中引用的列[SalesAmount],这个参数告诉 SUM 函数在哪一列上进行聚合求和。
- A:度量值名称
- 如果表名包含空格、保留字、特殊字符,或者包含非ANSI字符,则必须使用单引号将表名括起来,如 'Sales Data'。字段和度量值用中括号括起来,如 日期 或 度量值。
- 完全限定列名称 :列名称前加上所属的表名,如
Sales[SalesAmount],就是所谓的完全限定列名称,这有助于明确指出列的来源,也有助于和度量值做区分。
同一个表中引用的列不需要在公式中包含表名,这可以使引用多个列的长公式更短且更易于阅读。 但是,最好能够在你的度量值公式中包含表名,即使在同一表中亦然。
公式创建步骤:
- 每个公式必须以等号 (=) 开头,公式可以是DAX函数,或者
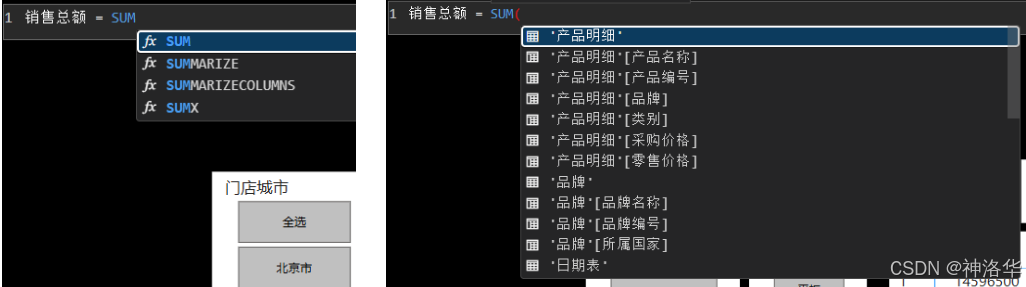
[Column1] + [Column2]这种表达式 - AutoComplete 功能:
- AutoComplete 是一种智能提示功能,它会在你开始输入公式时自动出现,为你提供与当前输入内容相关的选项列表。这些选项包括函数名称、列名、表名等,在复杂的嵌套函数中尤其有用;你还可以单击
Fx按钮显示可用函数的列表 - 使用↑和↓进行选择,按 下Tab 键或鼠标点击所选项,选项将自动添加到公式中。
- 代码补全不会自动添加函数的结束符号
),也不会检查或自动匹配括号是否成对。
- AutoComplete 是一种智能提示功能,它会在你开始输入公式时自动出现,为你提供与当前输入内容相关的选项列表。这些选项包括函数名称、列名、表名等,在复杂的嵌套函数中尤其有用;你还可以单击
- 如果公式过长,通过按
Alt + Enter换行,或按Tab添加制表符,分隔公式的各个部分 。
1.1.2 DAX公式格式
DAX 格式化规则:为了可读性和规范性,DAX代码有一些约定的习惯和规则:
- 如果函数只有一个参数,则和函数放在同一行
- 如果函数具有2个或更多参数,则将每一个参数
都另起一行, 分隔两个参数的逗号位于前一个参数的同一行 - 如果函数及其参数写在多行上:
- 左括号"("与函数在同一行
- 参数是新行,从该函数对齐位开始缩进4字符
- 右括号")"与函数开头对齐
- 如果必须将表达式拆分为更多行,则运算符作为新行中的首字符
通过以上规则,很容易就能分辨出 DAX 代码中每一个函数的参数、起止位置,嵌套的层数等。除了换行和缩进,还有一些其它细则,比如函数名都用大写字母、等号之后留个空格等。
如果你对上述规则感到困惑,或者想快速格式化代码,可在在网站daxformatter上进行在线格式化。
1.2 DAX编辑器快捷键

1.3 DAX函数简介
参考《函数》
1.3.1 DAX函数特性(DAX上下文)
- DAX 函数特性始终引用完整的列或表。 如果您想要仅使用表或列中的特定值,则可以向公式中添加筛选器。许多 DAX 函数返回表而不是单个值,这些表不直接显示,但可以作为其他函数的参数输入。
- 时间智能:DAX 包含多种时间智能函数,可以定义或选择日期范围,并基于这些范围执行动态计算。
- 行级计算 :DAX 提供迭代函数 ,允许使用当前行的值或相关值作为参数,基于上下文进行更细粒度的控制和更复杂的计算。例如:
SUMX(TableName, Expression)。这里的 TableName 是要迭代的表,而 Expression 是应用于该表每一行的表达式。 - 上下文 :**DAX是动态计算公式,其结果会根据上下文(如筛选条件)而变化,**这包括(参考《上下文》):
- 行上下文(Row Context) :即在计算度量值时,对数据表中的每一行进行迭代计算的环境,可简单理解为当前行。 例如,使用
SUMX函数计算销售额时,公式会逐行计算"数量 × 单价",然后再对结果进行汇总。这种逐行计算的过程就需要行上下文。 - 多行上下文(Multiple Row Context) :DAX中一些在表上迭代计算的函数可以有多个当前行,每个都有自己的行上下文,允许创建在内外循环间递归操作的公式。 例如包含Products和Sales的模型中,若要找出每个产品在任何一笔交易中的最大订购数量,可使用公式
= MAXX(FILTER(Sales,[ProdKey] = EARLIER([ProdKey])),Sales[OrderQty]),其中EARLIER函数用于存储前一个操作的行上下文,使公式能跨越内外循环获取正确的值。 - 筛选器上下文(Filter Context) :筛选上下文是指在计算度量值时,应用的一个或多个筛选条件,它通常来源于报表中的过滤器、切片器、可视化对象的交互筛选(行/列区域中的字段),以及DAX公式中的筛选函数(如
ALL,RELATED,FILTER,CALCULATE等) - 查询上下文(Query Context) :指公式隐式检索的数据子集,其结果随公式放置位置和模型关系而发生变化。
- 例如,
= SUM('Sales'[Profit])在销售表的计算列中使用时,查询上下文为整个销售表数据集,结果为所有区域、产品和年份的总利润;但在报表中使用时,上下文会因筛选、添加或删除字段、使用筛选器等操作而改变,公式在每个单元格中以不同的查询上下文进行评估,从而得到不同结果。 - 又比如,一个新表未与其他表关联且未应用筛选器,当前上下文是该表中的所有数据;如果该表通过关系与其他表连接,上下文会扩展到相关表;如果将表中的列添加到带有切片器和报表筛选器的报表中,上下文则变为报表每个单元格中的数据子集。
- 例如,
- 行上下文(Row Context) :即在计算度量值时,对数据表中的每一行进行迭代计算的环境,可简单理解为当前行。 例如,使用
也有将DAX上下文又分为外部上下文和内部上下文,外部上下文就是外部可以看得见的筛选:标签和切片器,而内部上下文就是创建度量值的DAX公式,它的查询筛选函数可以扩大、限制或者重置外部上下文。
1.3.2 计算列
DAX 可以在 Power BI Desktop 的数据建模和 Power Pivot 中使用。除了创建度量值,DAX 还可以用来创建计算列(报表试图、表视图、模型视图中均可以)。计算列是添加到现有表中的列,并使用 DAX 公式定义列的值。
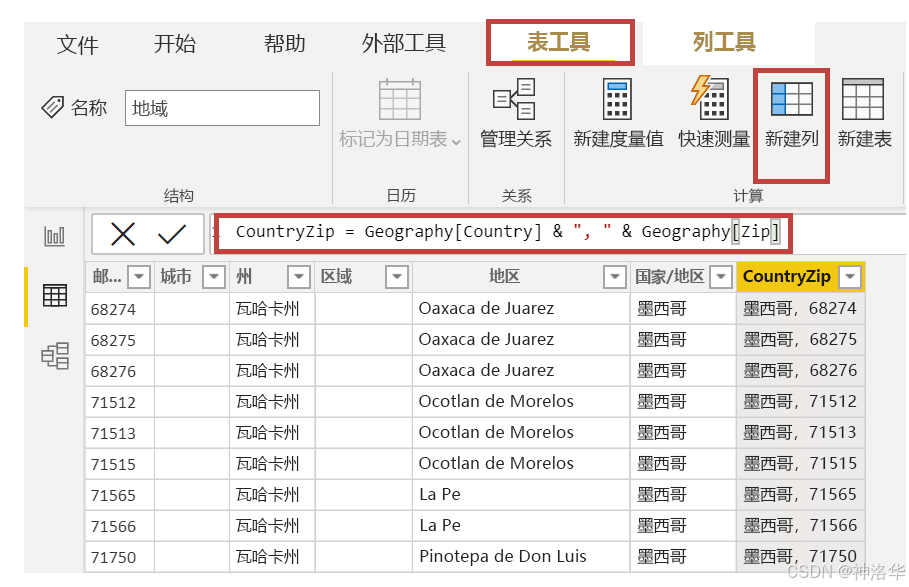
计算列一般用于在表之间建立关系:当不存在唯一字段时,可以创建计算列作为唯一键,例如,在 Geography 表和 Sales 表中通过组合 Country 和 Zip 列中的值来创建新的计算列 CountryZip,,它们可以用作唯一键来在两个表之间建立关系。
1.3.3 计算表
计算表不是从数据源中直接加载的,而是使用DAX 公式动态生成的。计算表允许你基于已经加载到模型中的数据来添加新表,即使用数据分析表达式(DAX)公式来定义表的值,这在某些情况下很有用,尤其当你需要进行中间计算或者想要将数据作为模型的一部分存储起来时(计算表存储为模型的一部分 ),例如,计算表可以用来交叉联接两个表。
计算表与其他表一样完全可操作,比如与其它表建立关系,将其字段可添加到报告可视化中。计算表中的列具有数据类型、格式,并可以属于数据类别。计算表可以命名,并且可以像任何其他表一样显示或隐藏。
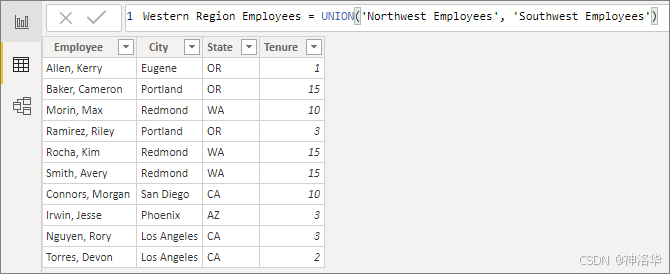
假设你是一个人事经理,并且有一个"西北部员工"表和一个"西南部员工"表 。 你想要将这两个表合并为一个名为"西部地区员工"的表。
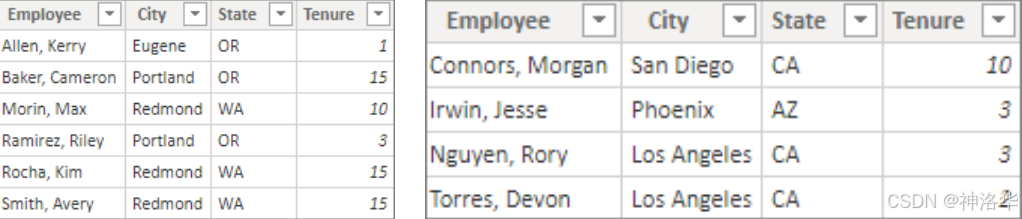
- 新建表 :在 Power BI Desktop 的报表视图、表视图或模型视图中,在"计算" 组中,选择"新建表"。
- 创建计算表 :在公式栏中输入以下公式,即创建了名为"西部地区员工"的新表。
计算表在角色扮演维度中很有帮助,例如日期表,可以作为订单日期、发货日期或到期日期,取决于外键关系。创建明确的计算表(如发货日期)可以得到一个独立的表,可用于查询。
同计算列一样,如果有关数据被刷新或更新,计算表将重新计算。通过任何会返回表(包括对另一个表的简单引用)的 DAX 表达式都可以定义计算表。 例如:
python
New Western Region Employees = 'Western Region Employees'1.3.4 常见错误
- 语法错误:包括使用了非英文字符标点,括号没有匹配等等
- 函数或函数参数使用错误
有些DAX函数返回的是表,若用于新建度量值,肯定出错,比如:

有些函数返回的是值,若用于建表,也会报错,比如CALCULATE函数返回的是一个值,不能用于建表:

不过如果你确实想建一个只有一个值的表,也是可以做到的,可以在这个表达式外层套一个大括号{},生成只有一个数值的表,即可在数据视图下,查看度量值的返回结果。 - 作图出错 。
比如这个度量值,用于计算哪个客户的单笔购买金额最高。用个卡片图来展示,可结果却是报错:

点击详情显示:
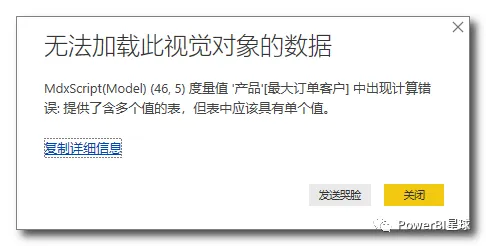
即DAX代码本身并没有错误,但是逻辑上有bug。假如有多个客户的订单额都同时是最大订单额,那么这个度量值无法返回唯一值,也就不能正常显示出结果。解决的办法有很多,主要看你想要什么结果,比如选取最早达到最大订单额的是哪个客户等等。 - 显示结果不符合预期
写度量值时没有任何错误提示,把它拖入到图表中也没有错误,可是显示的数据却很奇怪,完全不是想象中的结果。这个问题一般都是维度表和事实表没有建立关系,或者没有建立正确的关系,因此度量值没有按照外部下上文正确计算。遇到这种情况去建模视图下,更改一下关系就可以了。
1.4 运算符及其优先级
1.4.1 运算符简介
DAX支持四种类型的运算符:
| 运算符种类 | 运算符 | 功能 | 示例 |
|---|---|---|---|
| 算术运算符 | +,-,*,/ |
加减乘除法运算,前两者也做亿元运算符,分别表示正数和负数 | |
^ |
乘方运算(幂运算) | 16^4 |
|
| 比较运算符 | >,=,<,>=,<= |
大于、等于、小于、大于等于,小于等于 | |
== |
严格等于(不将BLANK视为等于0或其他默认值) | [Region] == "USA" |
|
<> |
不等于 | [Region] <> "USA" |
|
| 文本连接运算符 | & |
连接两个文本字符串(中间的字符串必须使用双引号!!!) | [区域] & "、" & [城市] |
| 逻辑运算符 | && |
创建两个表达式之间的AND条件 | ([Region] = "France") && ([BikeBuyer] = "yes")) |
| 双竖线符号ll | 创建两个逻辑表达式之间的OR条件 | ((Region = "France") ll (BikeBuyer = "yes")) | |
IN |
判断元素是否在列表内 | 'Product'[Color] IN { "Red", "Blue", "Black" } |
DAX 公式中的运算符优先顺序与 Microsoft Excel 使用的顺序基本相同,但不支持某些 Excel 运算符,如百分比运算符、 范围运算符。可以通过括号来改变运算顺序。
^:乘方。-:一元运算符,如-1、+1。*和/:乘法和除法。+和-:加法和减法。&:连接两个文本字符串。=, ==, <, >, <=, >=, <>, IN:比较。NOT:一元运算符。
DAX的底层计算引擎基于SQL Server Analysis Services,它提供了关系型数据存储的高级功能,在某些情况下,DAX的计算结果或函数行为可能与Excel不同。例如,在DAX中,运算符两边的运算数通常应该是相同的数据类型,但某些情况下,DAX会将不同的数据类型强制转换为更通用数据类型,以便于进行计算。
例如,假设你有两个数字需要相乘,一个数字是通过公式计算得出的,例如[Price] * 0.20,结果为浮点数;另一个是字符串表示的整数,例如"5"。此时,DAX会将两个数字都转换为浮点数进行计算。
比较运算不支持以上强制类型转换,DAX只支持数值与数值、布尔值与布尔值、字符串与字符串之间的比较。其中,整数、实数、货币值、DateTime和空白值( Blank,视为0)用于比较目的时,会视为数值。其他混合数据类型比较将返回错误。
1.4.2 IN运算符详解
IN运算符用于检查表达式是否属于值列表,可以使DAX的书写更加简洁,比如需要计算U盘、耳机和硬盘这三个产品的销售额,可以写作:
销售额 U盘耳机硬盘=
cpp
CALCULATE(
[销售额],
'产品表'[产品名称]="U盘" ||
'产品表'[产品名称]="耳机" ||
'产品表'[产品名称]="硬盘"
)如果用IN来表达:
cpp
销售额 U盘耳机硬盘=
CALCULATE(
[销售额],
'产品表'[产品名称] IN { "U盘", "耳机" ,"硬盘" }
)因为IN的后面必须是一个表,所以可以用{ }括起来,将值强制构造为表
IN还可以与NOT一起使用,用来表示不在这个列表内的数据集合,比如计算除U盘、耳机和硬盘之外的,其他产品的销售额:
销售额 除U盘耳机硬盘 =
cpp
CALCULATE(
[销售额],
NOT '产品表'[产品名称] IN { "U盘", "耳机" ,"硬盘" }
)除了检索用{ }构造的值列表,IN更多的用于检索虚拟表,比如:
cpp
是否为共同客户 =
VAR customers = VALUES('订单表'[客户姓名]) // 本期客户列表
VAR customers_py = // 上年同期客户列表
CALCULATETABLE(
VALUES('订单表'[客户姓名]),
SAMEPERIODLASTYEAR('日期表'[日期])
)
VAR customers_same = INTERSECT(customers, customers_py) // 共同客户列表
RETURN IF(
SELECTEDVALUE('客户表'[客户姓名]) IN customers_same, // 检查当前用户是否在虚拟表customers_same中
"是"
)IN不仅用于一列,还可以用于多列。只有一列时,{ }中可以直接输入文本,但对于两列,同一行的两列需要用括号()括起来,每个括号代表一行。下面这个例子中,IN 后面的表就是两行两列的表。
cpp
销售额 U盘南京 =
CALCULATE(
[销售额],
('订单表'[产品名称],'订单表'[客户城市])
IN { ("U盘","南京市") }
)1.5 DAX Queries
DAX计算公式通常只能在表格数据模型中创建(比如Power BI中的数据模型)。但DAX查询不仅可以在表格数据模型中运行,还可以在Analysis Services多维模型中运行,这使得它的适用范围更广。与多维数据表达式 (MDX) 查询相比,DAX 查询通常更易于编写,而且效率更高。
DAX查询是一种类似于SQL中SELECT语句,用于从数据模型中检索数据。它可以直接在SQL Server Management Studio(SSMS)或开源工具(如DAX Studio)中运行,而不需要在Power BI或Analysis Services的数据模型中创建。
DAX查询的基本形式是EVALUATE语句,类似于SQL中的SELECT语句。它可以从数据模型中返回一个表格结果,例如:
python
EVALUATE
(FILTER('DimProduct', [SafetyStockLevel] < 200))
ORDER BY [EnglishProductName] ASCEVALUATE:这是DAX查询的关键词,表示开始一个查询。FILTER:筛选函数。这里的意思是从DimProduct表中筛选出SafetyStockLevel小于200的产品。ORDER BY:用于对结果进行排序,这里是按照EnglishProductName(产品名称)升序排列。
DAX查询还可以在查询中创建临时的度量值(measures)。这些度量值只在查询执行期间存在,不会保存到数据模型中。这使得DAX查询非常灵活,可以根据需要动态计算结果,详见《DAX 查询》。
二、 逻辑函数
2.1 AND、OR、NOT函数
| 函数名称 | 语法 | 说明 | 示例 |
|---|---|---|---|
| AND | AND(<logical1>, <logical2>) |
判断两个逻辑条件是否同时为真。 | AND([Sales] > 1000, [Profit] > 100) |
| OR | OR(<logical1>, <logical2>) |
判断两个逻辑条件中是否至少有一个为真。 | OR([Sales] > 1000, [Profit] > 100) |
| NOT | NOT(<logical>) |
对一个逻辑值取反。 | NOT([Sales] > 1000) |
AND 和 OR 函数可以嵌套使用,以实现更复杂的逻辑判断。 这些函数在DAX中通常与IF函数结合使用,以实现条件分支逻辑。
2.2 IF、IFERROR
| 函数名称 | 语法 | 说明 | 示例 |
|---|---|---|---|
| IF | IF(<logical_test>, <value_if_true>, [<value_if_false>]) |
根据条件返回不同的值 | Price Group =IF('Product'[List Price] < 500, "Low", "High") |
| IFERROR | IFERROR(<value>, <value_if_error>) |
如果表达式计算结果为错误(如除以零、引用无效的列等),则返回一个指定的值;否则返回表达式的正常结果。 | Safe = IFERROR([A]/[B],"Error") |
IF 函数用于实现简单的逻辑分支,但也可以嵌套实现,例如:
cpp
Price Group =
IF(
'Product'[List Price] < 500,
"Low",
IF(
'Product'[List Price] < 1500,
"Medium",
"High"
)
)如果需要嵌套多个 IF 函数,建议使用SWITCH 函数。
2.3 SWITCH 函数
SWITCH 函数用于根据指定的表达式返回不同的值,类似于编程中的 switch-case 语句。一般有两种使用形式
-
简单 SWITCH:将表达式与一系列值进行比较,返回对应的结果。
cppSWITCH( expression, value1, result1, value2, result2, ... [default] )示例1:根据产品 ID 判断产品类别,若 ID 为 1 则为"Electronics",以此类推,若不在列表中则为"Other"。
cppProductCategory = SWITCH( Product[ProductID], 1, "Electronics", 2, "Clothing", 3, "Furniture", "Other" ) -
表达式 SWITCH:通过一系列条件表达式来判断,返回满足条件的结果。
cppSWITCH( TRUE(), condition1, result1, condition2, result2, ... [default] )示例2:根据销售额判断销售表现,销售额大于 100000 为"Excellent",以此类推,若都不满足则为"Poor"。
cppSalesPerformance = SWITCH( TRUE(), Sales[TotalSales] > 100000, "Excellent", Sales[TotalSales] > 50000, "Good", Sales[TotalSales] > 10000, "Average", "Poor" ) -
结合其他函数使用: 根据月份对销售数据进行季节性调整,1 月乘以 1.2,2 月乘以 1.1,12 月乘以 1.3,其他月份保持原值。
cppSeasonalAdjustment = SWITCH( MONTH('Date'[Date]), 1, Sales[SalesAmount] * 1.2, 2, Sales[SalesAmount] * 1.1, 12, Sales[SalesAmount] * 1.3, Sales[SalesAmount] )
其它场景:
- 与 CALCULATE 函数结合:在计算销售额时,根据不同的条件进行筛选和计算。
- 与 RELATED 函数结合:在不同表之间进行数据关联,根据关联字段的值进行判断和计算。
- 与 TIMEINTEL 函数结合:在时间智能分析中,根据不同的时间粒度(如年、季度、月)进行数据的聚合和计算。
注意事项:
- 默认值的设置:在 SWITCH 函数中,最后的默认值是可选的,但建议设置,以避免返回 BLANK 值。
- 条件的顺序:在表达式 SWITCH 中,条件的顺序很重要,因为一旦某个条件满足,就会返回对应的结果,后续的条件将不再判断。
- 性能优化:在处理大量数据时,SWITCH 函数可能会对性能产生影响,因此需要合理设计条件和表达式,避免不必要的计算。
三、DAX语句
3.1 VAR关键字
VAR是VARIABLE的缩写,意思为变量,其语法如下所示。其中,变量名不能和模型中现有的表名、字段名相同,也不能使用数字作为第1个字符,不能使用空格等。
cpp
VAR <name> = <expression>3.1.1 简化计算
VAR可以简化度量值的书写,并便于理解。比如,计算一个产品销售数据表中的同比增长率,常规方式为:
cpp
[Sales] = SUM(销售表[销售额])
[Saleslastyear] = CALCULATE([Sales],SAMEPERIODLASTYEAR(日期表[日期]) // 去年销售额
[YoY%] = DIVIDE([Sales]-[Saleslastyear],[Saleslastyear]) // 同比增长率而使用VAR,新建一个度量值就可以搞定:
cpp
[YoY% 1]=
VAR Sales = SUM('订单'[销售额])
VAR Saleslastyear =
CALCULATE(
SUM('订单'[销售额]),
SAMEPERIODLASTYEAR('日期表'[日期]))
RETURN DIVIDE(Sales-Saleslastyear,Saleslastyear)要注意的是,上述代码中,VAR定义的变量语句不能引用之前定义的变量值,所有变量需要根据独立的上下文进行计算,即不能写成:
cpp
[YoY% 2]=
VAR Sales = SUM('订单'[销售额])
VAR Saleslastyear =
CALCULATE(
Sales,
SAMEPERIODLASTYEAR('日期表'[日期]))
RETURN DIVIDE(Sales-Saleslastyear,Saleslastyear) 这是因为VAR一旦定义变量完成,在当前的计算中就变成了一个固定值,不会再发生变化。将这两个度量值放进矩阵中可以看到:
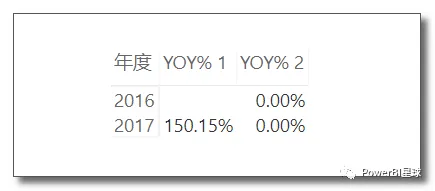
2016年没有上年数据,所以YOY%1 2016年的结果为空,但是YOY%2 的每个值都是零。这是因为在计算Saleslastyear时,无论处于什么上下文(SAMEPERIODLASTYEAR),它都会等于sales,因此导致结果都等于0。
3.1.2 替代EARLIER函数
比如在3.3.4章节中,使用EARLIER函数计算产品累计销量:
cpp
产品累计销量= SUMX(FILTER(
'订单表','订单表'[序号]<=EARLIER('订单表'[序号])
&&'订单表'[产品名称]=EARLIER('订单表'[产品名称])),
'订单表'[销售数量])使用VAR同样可以实现,且更易于理解。
cpp
VAR Index=[序号]
VAR ProductID=[产品名称]
RETURN
CALCULATE(SUM([销售数量]),filter('订单表',
[序号]<=Index && [产品名称]=ProductID))3.2 EVALUATE(待补)
参考《DAX 查询》
EVALUATE 是 DAX中的一个关键字,用于执行 DAX 查询并返回结果(从模型中检索数据),它类似于 SQL 中的 SELECT 语句。
四、筛选函数
4.1 CALCULATE 与 CALCULATETABLE
CALCULATE 函数是 DAX中最强大的工具之一,其核心逻辑是通过一系列筛选条件(filters)得到一个数据子集,更改筛选器上下文(也称为上下文转换),然后再执行聚合运算。这正是 DAX 的核心功能:提取有用数据并执行聚合运算。其函数语法为:
cpp
CALCULATE(<expression>[, <filter1> [, <filter2> [, ...]]])<expression>: 要计算的表达式,通常是一个聚合函数,实质上等同于度量值。<filter1>, <filter2>...:可选,表示一系列筛选器,可以是布尔表达式、表表达式(返回表),或是其它筛选函数(例如ALL、KEEPFILTERS) 。- 当有多个筛选器时,可以使用AND(&&)、OR(||)来进行逻辑组合。
- 为了获得最佳性能,建议尽量使用布尔表达式作为筛选器参数。只有在需要时才使用 FILTER 函数,例如执行筛选器的复杂列比较(下文会讲)
4.1.1 筛选条件为空,只使用外部上下文
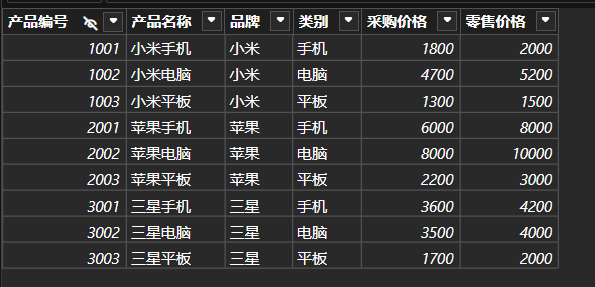
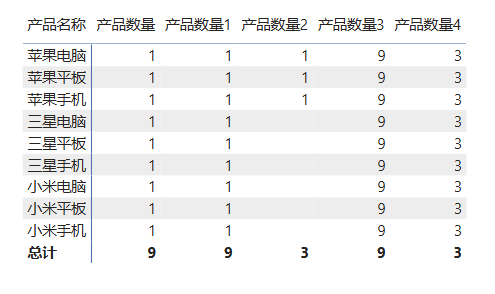
上图是本文1.1章节导入的产品明细表,新建一个度量值求每种产品的数量。
cpp
//因为每种产品的只有1行,所以求产品明细表的行数就相当于求各种产品的数量
产品数量 = COUNTROWS('产品明细')把产品名称和该度量值拖拽入矩阵表,此时外部上下文就是表格每行的行标签(行上下文),每种产品数量都为1。
使用CALCULATE函数新建一个度量值,筛选条件为空,此时完全依赖外部上下文。
cpp
产品数量1 = CALCULATE([产品数量])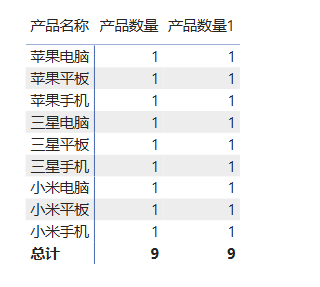
可以看到计算结果和度量值 产品数量 的结果一致,因为度量值 产品数量 本身就是一个聚合函数运算,将其运算逻辑代入,度量值 产品数量1 等同于:
cpp
产品数量1 = CALCULATE(COUNTROWS('产品明细'))DAX函数可以直接引用已经创建好的度量值,可以使DAX函数看起来更简洁、更具可读性,这也是建议从最简单的度量值开始建的原因。
4.1.2 使用筛选器,缩小上下文
新建度量值 产品数量2:
cpp
产品数量2 = CALCULATE([产品数量],'产品明细'[品牌]="苹果")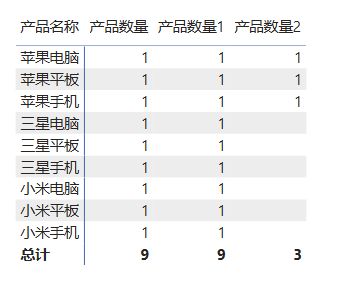
可以发现只有品牌为苹果的产品参与了计算,而其他品牌的数据没有了,这是因为CALCULATE的第二个参数的限制,只筛选品牌为"苹果"的产品,限制了外部的上下文。
4.1.3 ALL函数,扩大上下文
新建度量值 产品数量3:
cpp
产品数量3 = CALCULATE([产品数量],ALL('产品明细'))
// 也可写作:产品数量3 = CALCULATE([产品数量],ALL('产品明细'[产品名称]))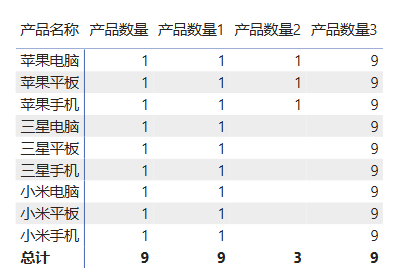
所有产品的数量居然都是9!这是因为ALL函数清除产品明细表里所有的筛选,包括行上下文,让计算在整个表的数据范围内进行,所以每行统计的都是该表中的所有产品。
每行的数据都是9,你可能觉得这个ALL函数没什么用,专门误导人。但是这个数据使用的地方非常多。比如当我们想计算每种产品的占比时,可以引用它,这就是统计总数的一个功能。
cpp
产品占比=[产品数量]/[产品数量3]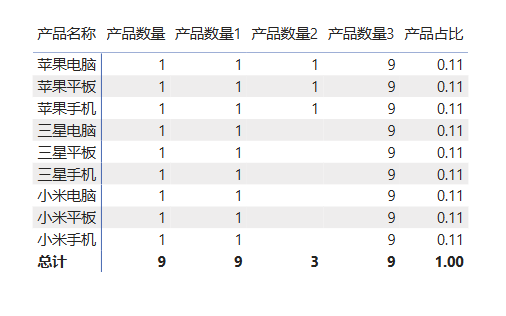
4.1.4 重置上下文
新建度量值 产品数量4:
cpp
产品数量4 = CALCULATE([产品数量],
all('产品明细'[产品名称]), //也可写作ALL('产品明细')
'产品明细'[类别]="手机")- ALL('产品明细'产品名称):这个函数移除对"产品名称"列的所有筛选器,在这里就是清除行上下文
- '产品明细'类别="手机":只考虑类别为"手机"的产品
因此,度量值 产品数量4 的计算结果将是 3,表示在给定的筛选上下文中(即类别为"手机"的所有产品),共有 3 种手机产品。
4.1.5 相似函数:CALCULATETABLE
cpp
CALCULATETABLE(<expression>[, <filter1> [, <filter2> [, ...]]])| 特性 | CALCULATE | CALCULATETABLE |
|---|---|---|
| expression参数 | 通常是一个聚合函数 | 通常是一个返回表的函数,如 FILTER、VALUES 等 |
| 返回值类型 | 标量值 | 表,可以是一行或者一列 |
| 用途 | 通常用于计算度量值,如总和、平均值、最大值、最小值等聚合计算 | 通常用于创建计算表,这在需要基于特定条件生成新的表时非常有用。 |
| 筛选器 | 可以是布尔表达式、表表达式或筛选器函数 | 同 CALCULATE |
-
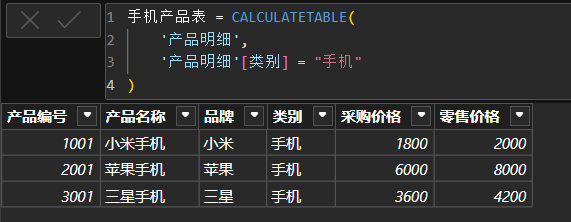
新建"手机"类别产品的新表:新建表,输入以下公式:
-
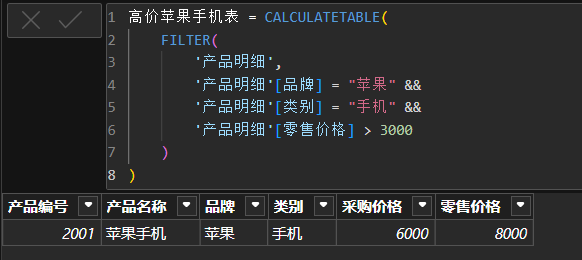
使用
FILTER函数结合CALCULATETABLE:创建一个包含特定品牌的手机产品表,并且这些手机的零售价格超过 3000 :
4.1.6 扩展表
参考《扩展表》
先来看一个简单的示例,以PowerBI星球案例模型来说明,模型图是这样的:
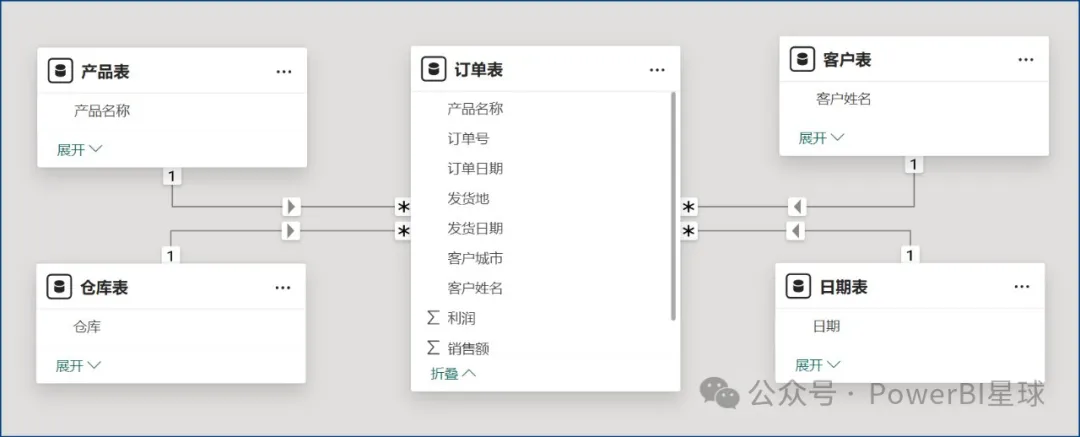
如果想找出每个产品对应的客户是多少,直接写客户数量 = COUNTROWS('客户表'),由于产品表并不能直接筛选客户表,所以这个度量值的结果都是相同的,都是全部客户的计数。但是如果我们改一下度量值:客户数量 = CALCULATE(COUNTROWS('客户表'),'订单表'),就可以正确计算出结果了:
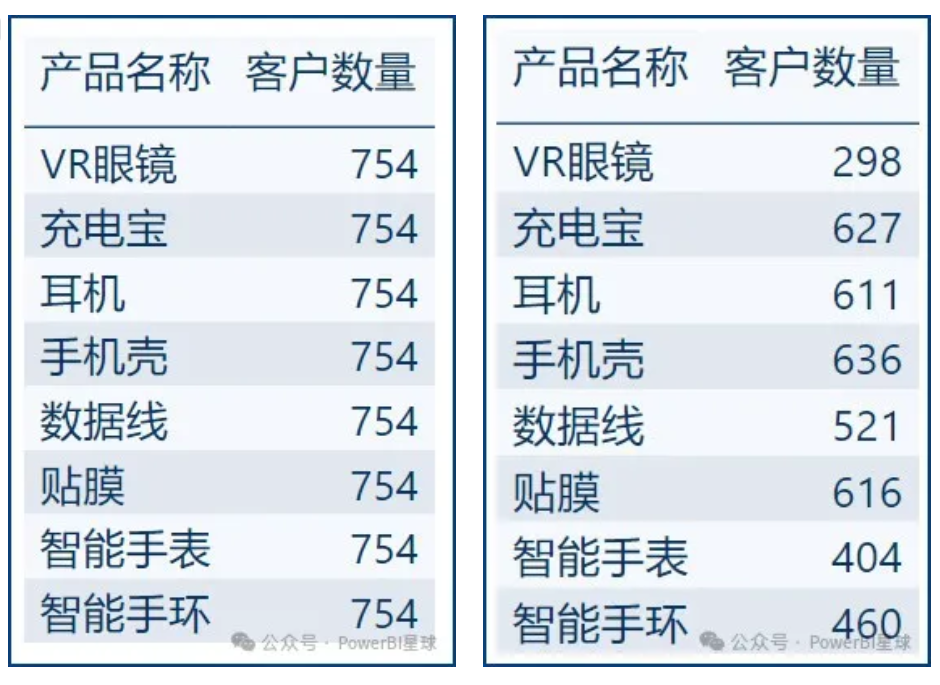
从模型上来看,产品表依然不能筛选客户表,为什么在CALCULATE中添加个订单表作为参数就可以筛选了呢?要理解这个计算原理,就需要先理解扩展表。
扩展表是Power BI模型中一个重要的概念。每个表的扩展表不仅包括它自身,还包括与它建立一对多关系的"一端"表。
- 单向扩展 :如果表A与表B是一对多关系(A是"一端",B是"多端"),那么表B的扩展表会包含表A,但表A的扩展表不会包括表B,因为扩展表的筛选逻辑是基于"多端"向"一端"传递的。
- 动态扩展:扩展表并不是静态的,而是动态的。它会随着模型关系的变化而实时更新
- 关系传递:扩展表是可以根据一对多关系进行传递
在星型模型中,事实表的扩展表通常包括所有与之关联的维度表。下图中,假如还有个产品类别表,与产品表建立一对多的关系。
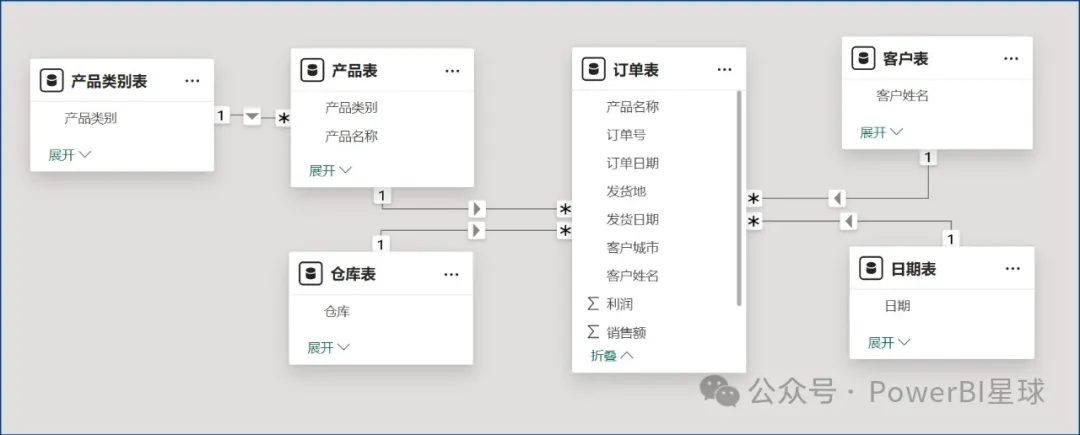
- 4个直接与订单表建立一对多关系的维度表都是订单表的扩展表,或者说,订单表的扩展表就是整个模型的所有表。
- 产品表是订单表的扩展表,而产品类别表是产品表的扩展表,那么产品类别表也是订单表的扩展表。
- 其他表的扩展表只有它们自身
扩展表在DAX计算中起着关键作用,它影响了数据的筛选逻辑:
- 关系筛选:筛选扩展表时,视同筛选本表 :当筛选一个表的扩展表时,相当于同时筛选了该表本身。
以筛选产品表为例,由于产品表是订单表的扩展表,则筛选产品表的产品名称,比如耳机,则视同筛选订单表,将订单表中所有耳机的订单筛选出来,这就是我们通常理解的按模型关系来筛选。 - CALCULATE修改上下文:筛选本表时,视同筛选所有扩展表 :当对一个表进行筛选时,实际上也筛选了它的所有扩展表。
由于产品表和客户表之间没有模型关系,产品表不能筛选客户表,但是当度量值写成客户数量 = CALCULATE(COUNTROWS('客户表'),'订单表')时,CALCULATE 函数会将这个筛选上下文('订单表',包含其所有扩展表)应用到客户表,所以它能正常计算出每个产品的客户数量。
总结来说,CALCULATE 函数通过修改筛选上下文,并利用扩展表的特性,使得可以在没有直接模型关系的情况下,实现跨表筛选和计算。这种能力极大地增强了DAX表达式的灵活性和强大性。
4.2 FILTER(复杂筛选)
4.2.1 语法
FILTER 函数用于根据指定的条件筛选表中的行,并返回满足这些条件的行的子集(创建动态子集),所以FILTER 是一个表函数,其语法为:
cpp
FILTER(<table>,<filter>) FILTER 一般不单独使用,而是作为其它DAX函数中的表函数参数进行引用,比如常常与CALCULATE 或CALCULATETABLE 函数结合使用,作为表筛选器,以实现更复杂的筛选逻辑。在《避免使用 FILTER 作为筛选器参数》一文中,介绍了FILTER函数的使用准则。对于CALCULATE 和 CALCULATETABLE函数:
- 尽量使用布尔筛选器,因为布尔表达式可以高效筛选列(直接在数据模型中应用筛选条件,而不是先创建一个子表)。
- 布尔表达式作为筛选器参数使用时,存在一些限制,包括不能引用多个表中的列、不能引用度量值、不能使用嵌套 CALCULATE 函数、不能使用扫描或返回表的函数。
- 表表达式可以满足更复杂的筛选要求,所以建议在必要时才使用
FILTER函数。
比如对于之前的度量值:
cpp
产品数量2 = CALCULATE([产品数量],'产品明细'[品牌]="苹果")使用FILTER 可以实现同样的效果:先使用ALL获取整个表,再进行条件筛选得到子表,最后作为表筛选器传递给CALCULATE函数。
cpp
产品数量2 = CALCULATE([产品数量],
FILTER(ALL('产品明细'[品牌]),
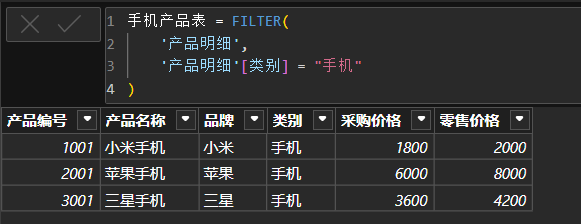
'产品明细'[品牌]="苹果"))4.2.2 使用FILTER函数新建表
我们可以使用FILTER函数新建表。点击新建表,输入:
4.2.3 作为筛选参数
比如对于1.1中的数据模型:
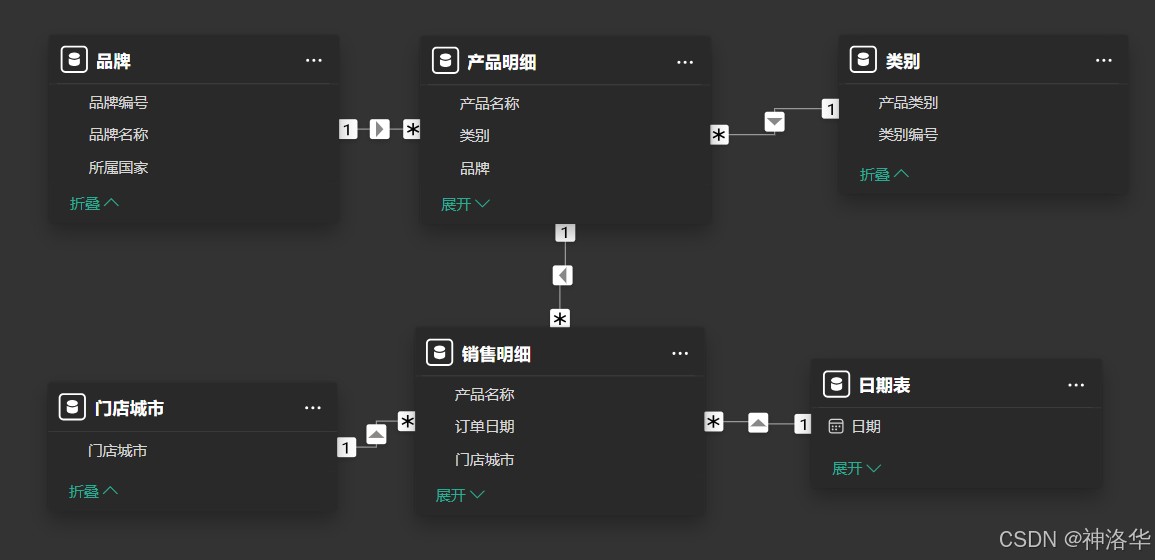
计算年销售额超过2000万的城市的销售额:
cpp
销售总额 = sum('销售明细'[销售额])
门店销售 = CALCULATE([销售总额],FILTER(ALL('销售明细'[门店城市]),[销售总额]>20000000))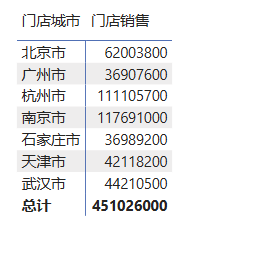
4.2.4 分组
-
使用数学函数进行固定数值区间分组
当需要对于数值字段进行固定长度的分组时,可以使用
ROUNDUP,ROUNDDOWN,CEILING,FLOOR等数学函数。例如,如果想将销售额每200元就划分一个组,即[0-200元),[200-400元),[400-600元)......,可以新建计算列:cpp分组 = VAR X=ROUNDDOWN([销售额]/200,0) // 将销售额除以200并向下取整 VAR Y=ROUNDUP([销售额]/200,0) // 将销售额除以200并向上取整 RETURN IF( X=Y, X*200&"-"&(X+1)*200, X*200&"-"&Y*200 )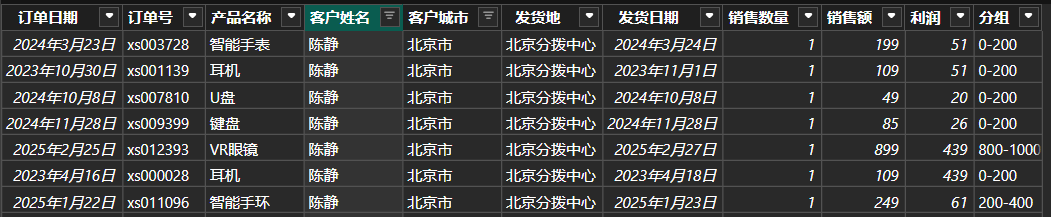
-
使用条件函数,进行非固定数值区间分组
对于数值不规律的区间划分,可以利用IF、SWITCH等逻辑判断函数,进行条件判断。比如如果想让销售额不超过100的订单返回"低于100"、销售额在100和300之间的返回"100-300"、300和600之间的返回"300-600、其他的销售额返回"600以上",可以写作:
cpp分组 = SWITCH( TRUE(), [销售额] <= 100, "低于100", [销售额] <= 300, "100-300", [销售额] <= 600, "300-600", [销售额] > 600, "600以上" )
-
使用辅助表进行复杂分组
但是当分组条件较多时,公式可能会变得较长,难以维护,更通用的方法是使用分组表和CALCULATE+FILTER函数。
-
构造分组表:按需求构造分组表,分组表不需要与其他表建立关系。

-
添加计算列,结果与上面是一样的
cpp分组 = CALCULATE( MAX('分组表'[分组]), // 使用其它聚合函数也可以 FILTER( '分组表', '分组表'[最小值]<[销售额]&&'分组表'[最大值]>=[销售额] // 定位到对应分组区间 ) )
虽然这种方式相对复杂一些,但是它更适合各种情况,特别是数据字段分组较多、无特定规律的情况,并且便于后期的维护。
-
-
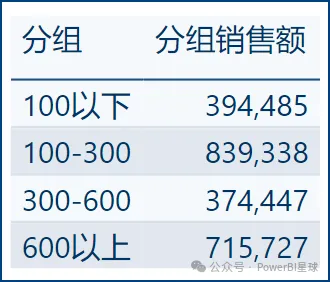
使用度量值:大多数情况下,分组的目的是为了分组统计,这种情况更适合用度量值来解决。另外,其实对于数据量大的情况,也不建议用计算列。对于上述辅助表,使用以下度量值公式:
cpp分组销售额 = CALCULATE( SUM('订单表'[销售额]), FILTER( ALL('订单表'), '订单表'[销售额]>MAX('分组表'[最小值])&&'订单表'[销售额]<=MAX('分组表'[最大值]) ) )用分组表的分组作为上下文,这个度量值就可以计算出每个分组的销售额合计。度量值的计算结果可能总计会有"错误",参考总计解决方案修正一下就可以。
4.3 EARLIER 与 EARLIEST
假设你有一个嵌套的行上下文,比如在计算列中使用了多个嵌套的 FILTER 函数或其他迭代函数,每个嵌套的函数都会创建一个新的行上下文。EARLIER 函数允许你从当前行上下文回溯到外部的某个特定层级的行上下文(可选参数n),默认回溯1层。而EARLIEST 函数作用是直接引用最外层的行上下文值,无论嵌套了多少层。
cpp
EARLIER(<column>, [<n>])<column>:要引用的列。<n>:可选参数,表示要回溯的上下文层级数,默认值为 1。
4.3.1 示例1:计算排名
对于下面这张Product表,我们可以通过计算表中比当前值更大的行数,来计算其销售额排名。
cpp
Ranking =
COUNTROWS(
FILTER(
'Products',
EARLIER(Products[Sales]) < Products[Sales]
)
) + 1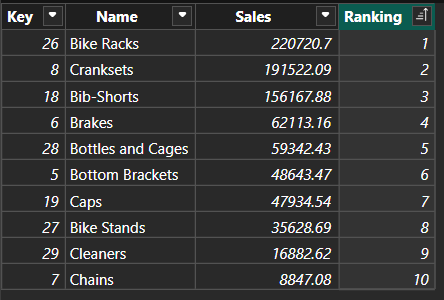
- 使用
EARLIER函数获取当前行的值,在第一次计算时,它会获取表中的第一行值。 - 使用
FILTER函数筛选数据,找出所有比当前行值更大的行。 COUNTROWS函数计算FILTER函数返回的表中的行数,加1防止最高值的排名为零或空白。- 计算公式会逐行移动,重复上述步骤1-3,直到处理完表中的所有行。
EARLIER 函数的作用是在当前表操作之前获取当前行的值,防止在后续计算中被覆盖,即引用/锁定外层循环(即当前行)的值。
这里使用
EARLIER函数实现排名逻辑,只是为了演示EARLIER函数的作用,实际上这种排名实现方式效率很低,其复杂度为 O ( n 2 ) O(n^2) O(n2)。DAX有排名函数RANKX,其性能更好。
如果是使用Pyhton进行处理,代码如下:
python
# 获取销售数据的数量
n = len(data)
# 双层循环计算排名
for i in range(n): //外层循环,即EARLIER(Products[Sales])
count = 0 # 初始化比当前 Sales 大的行数
for j in range(i): // 内层循环,即Products[Sales]
if data[j]["Sales"] > data[i]["Sales"]:
count += 1
# 排名 = 比当前 Sales 大的行数 + 1
data[i]["Ranking"] = count + 1
# 打印结果
for row in data:
print(row)
cpp
{'Key': 26, 'Name': 'Bike Racks', 'Sales': 220720.7, 'Ranking': 1}
{'Key': 8, 'Name': 'Cranksets', 'Sales': 191522.09, 'Ranking': 2}
{'Key': 18, 'Name': 'Bib-Shorts', 'Sales': 156167.88, 'Ranking': 3}
{'Key': 6, 'Name': 'Brakes', 'Sales': 62113.16, 'Ranking': 4}
{'Key': 28, 'Name': 'Bottles and Cages', 'Sales': 59342.43, 'Ranking': 5}
{'Key': 5, 'Name': 'Bottom Brackets', 'Sales': 48643.47, 'Ranking': 6}
{'Key': 19, 'Name': 'Caps', 'Sales': 47934.54, 'Ranking': 7}
{'Key': 27, 'Name': 'Bike Stands', 'Sales': 35628.69, 'Ranking': 8}
{'Key': 29, 'Name': 'Cleaners', 'Sales': 16882.62, 'Ranking': 9}
{'Key': 7, 'Name': 'Chains', 'Sales': 8847.08, 'Ranking': 10}4.3.2 示例2:计算订单日期间隔
对于一张包含订单日期的订单表,求两个订单的时间间隔,相当于用下一个订单的日期减去当前订单的日期。为了相减方便,新建列先求下个订单日期:
cpp
下个订单日期 = SUMX(FILTER('订单表','订单表'[序号]=
EARLIER('订单表'[序号])+1),
'订单表'[订单日期])EARLIER函数 :用于获取当前行的"序号"值。FILTER函数:筛选出"订单表"中序号比当前行的序号大1的行,即下一个订单的行。SUMX(..., '订单表'[订单日期]):SUMX 函数用于对表中的每一行执行一个表达式,并返回结果的总和。这里对每一行执行表达式 '订单表'订单日期,即提取这些行的"订单日期"值。
计算订单间隔,结果改为整数类型:
cpp
订单间隔 = IF([下个订单日期]=BLANK(),
BLANK(),
[下个订单日期]-[订单日期])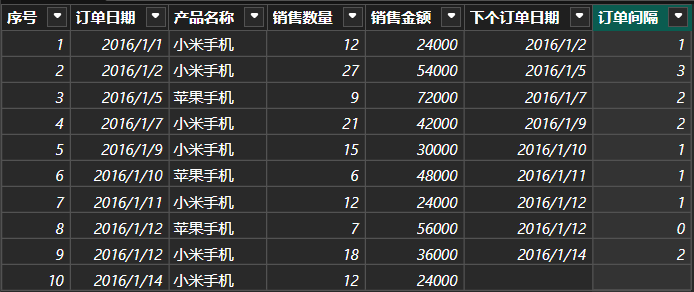
4.3.3 示例2:计算每日累计销售额
cpp
// 利用EARLIER求当前行的序号,然后把小于等于当前序号的所有行的销售额累加。
每日累计销售额 = SUMX(FILTER('订单表','订单表'[序号]<=
EARLIER('订单表'[序号])),
'订单表'[销售金额])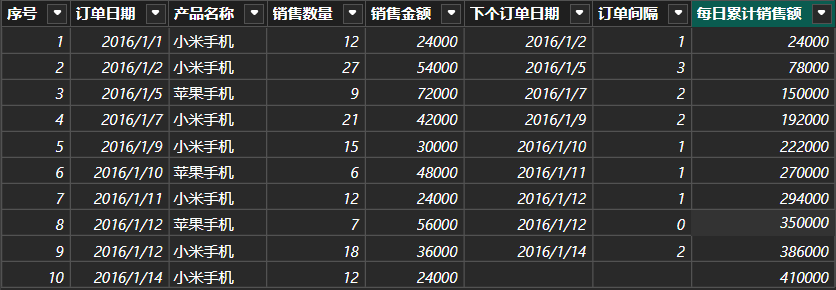
4.3.4 示例2:计算每种产品累计销量(可用WINDOW函数)
cpp
产品累计销量 = CALCULATE(
SUM('订单表'[销售数量]),
'订单表'[序号]<=EARLIER('订单表'[序号]),
ALLEXCEPT('订单表','订单表'[产品名称])
)或者是:
cpp
产品累计销量= SUMX(FILTER(
'订单表','订单表'[序号]<=EARLIER('订单表'[序号])
&&'订单表'[产品名称]=EARLIER('订单表'[产品名称])),
'订单表'[销售数量])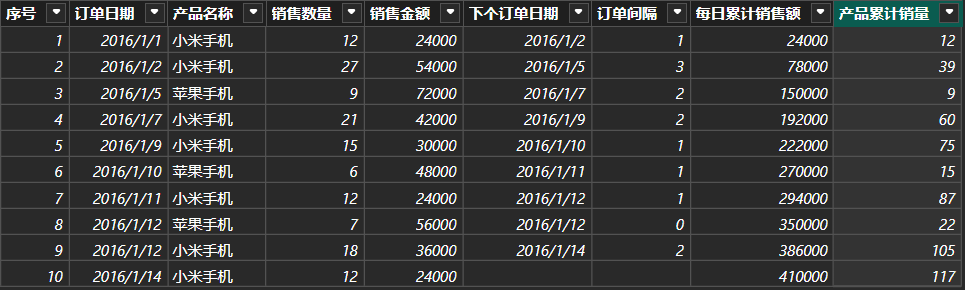
4.3.5 分类计数
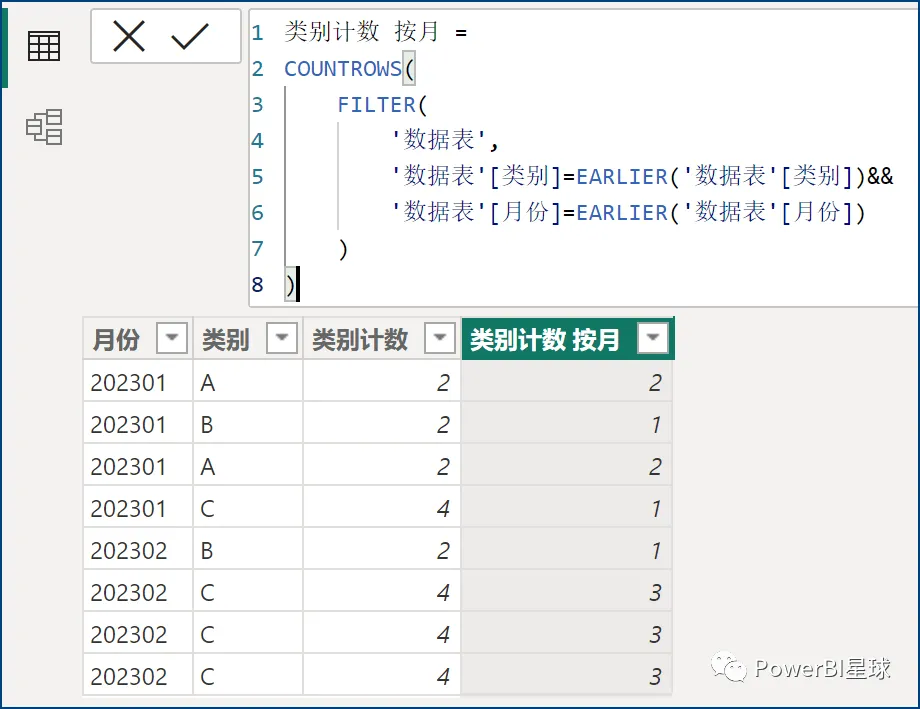
4.3.6 EARLIEST
cpp
EARLIEST(<column>)以下公式将得到相同的结果:
cpp
Ranking = COUNTROWS(FILTER( 'Products', EARLIEST(Products[Sales]) < Products[Sales])) + 14.4 ALL vs ALLEXCEPT vs ALLSELECTED
4.4.1 ALL函数(计算总体占比和分类占比)
ALL 函数用于完全清除指定表或列的所有筛选器,使得计算基于整个表或列的所有数据。其语法为:
cpp
ALL( [<table> | <column1>[, <column2>[, <column>[,...]]]] )其中,<table>为需要清除筛选器的表;<column>为可选参数,表示要清除筛选器的列。
- ALL 函数的参数必须是对基表的引用或对基列的引用,不能对 ALL 函数使用表表达式或列表达式。
- 当您使用 DirectQuery 模式连接到数据源时,某些函数(如 KEEPFILTERS、ALL 和 ALLEXCEPT 等),不被支持用于计算列或定义行级别安全性(RLS)规则。
-
计算每种产品的总销售额占比:以销售明细表为例,先创建一个矩阵视觉对象,行标签为产品明细表中的类别和品牌,列标签为日期表中的年度字段,值为以下新建度量值。
cpp总销售占比 = sumx('销售明细','销售明细'[销售额])/sumx(ALL('销售明细'),'销售明细'[销售额]) // 也可写成:总销售占比 = [销售总额]/CALCULATE([销售总额],ALL('销售明细'))
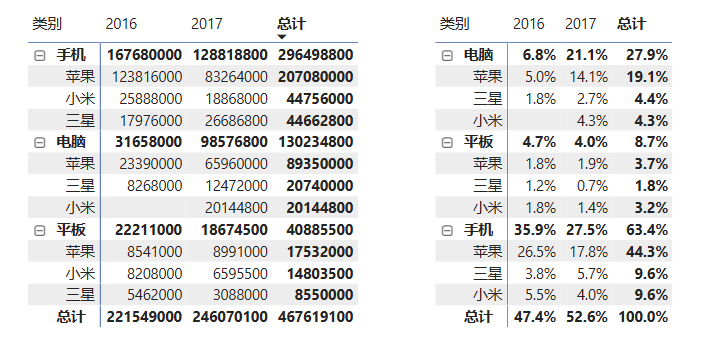
分子计算当前上下文(表格中的行和列)下的 销售额总和,分母是计算清除所有筛选器后的销售额总和(不考虑任何筛选器的"总计"或"基准"值)。
-
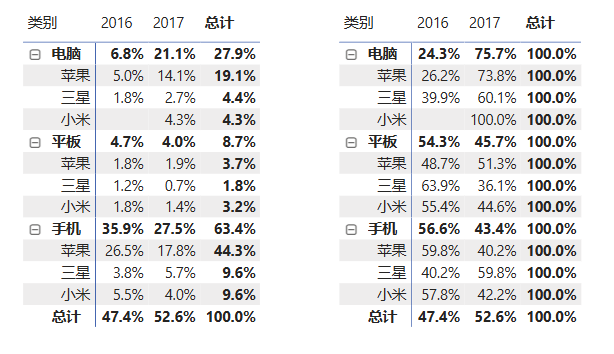
计算分类占比 :可以计算日期维度的分类占比。
cpp每年各产品销售占比 = SUMX('销售明细','销售明细'[销售额])/CALCULATE(SUMX('销售明细','销售明细'[销售额]),ALL('日期表'[年度]))
还可以计算产品维度的占比,品牌维度的计算方式也是一样的。
cpp
各产品每年销售占比 = SUMX('销售明细','销售明细'[销售额])/CALCULATE(SUMX('销售明细','销售明细'[销售额]),ALL('产品明细'))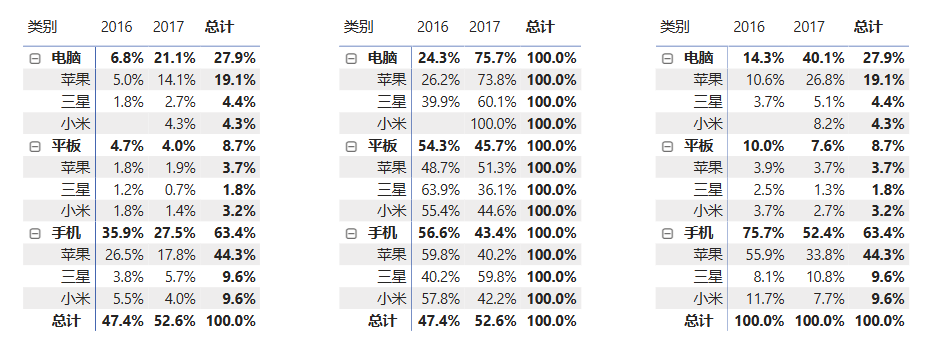
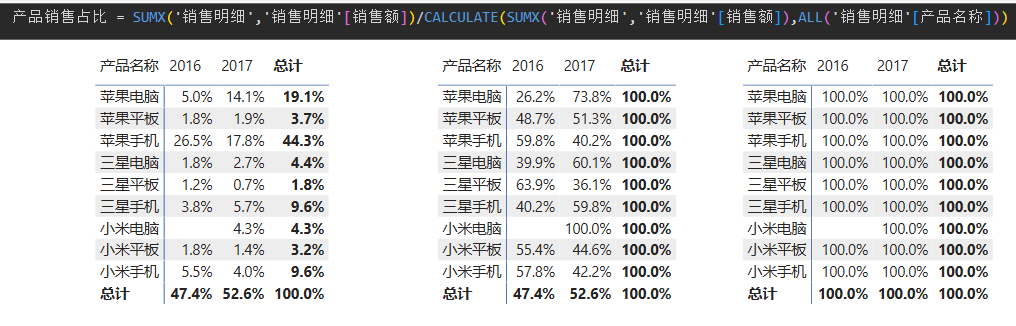
如果矩阵对象的行和列使用的字段分别是'日期表'年度,和'产品明细'产品名称,
每年各类产品销售占比 = [销售总额]/CALCULATE([销售总额],ALL('产品明细'[产品名称]))可以得到一样的结果。但如果ALL函数中使用 '销售明细'产品名称 ,虽然值是一样的,但是结果却全是1,这表明ALL完全没起到作用。
这是因为,在矩阵视觉对象中,既然使用 '产品明细'产品名称 作为行字段,那么矩阵中的数据就会受到 '产品明细'产品名称 的筛选,而不是 '销售明细'产品名称 的筛选,即使二者是一对多的关系。
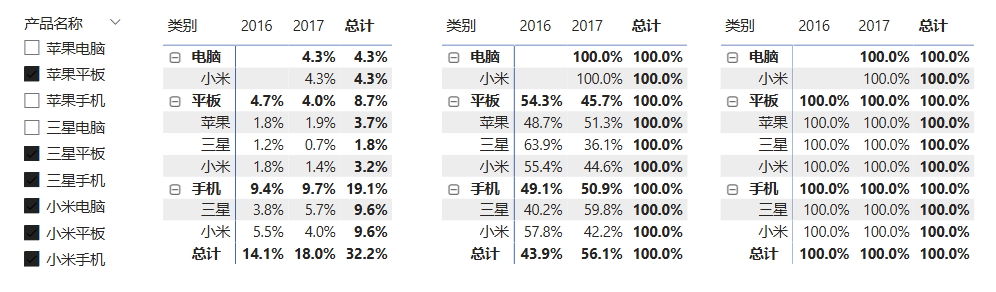
4.4.2 ALLSELECTED函数(按筛选上下文计算占比)
上一章节介绍了累计占比和分类占比的计算方式。现在,我们想计算某几个产品的数据(用切片器进行选择),可以看到,除了年度维度的占比,其它涉及产品的维度,显示都不正确(其实是切片器的筛选没有清除)。这时,就需要使用ALLSELECTED函数了。
简单的说,ALLSELECTED函数用于清除表中指定列的所有筛选器,包括报表级别、页面级别或视觉对象级别的切片器过滤器。其语法和ALL函数一样:
cpp
ALLSELECTED(<table> [, <column1> [, <column2>, ...]])接下来,按筛选上下文计算总体占比或者按筛选上下文计算类别占比,都只需要将原公式中的ALL函数替换为ALLSELECTED函数就行。
cpp
总销售占比 = [销售总额]/CALCULATE([销售总额],ALLSELECTED('销售明细'))
各品牌每年销售占比 = [销售总额]/CALCULATE([销售总额],ALLSELECTED('产品明细'[品牌]))
各产品每年销售占比 = [销售总额]/CALCULATE([销售总额],ALLSELECTED('产品明细'))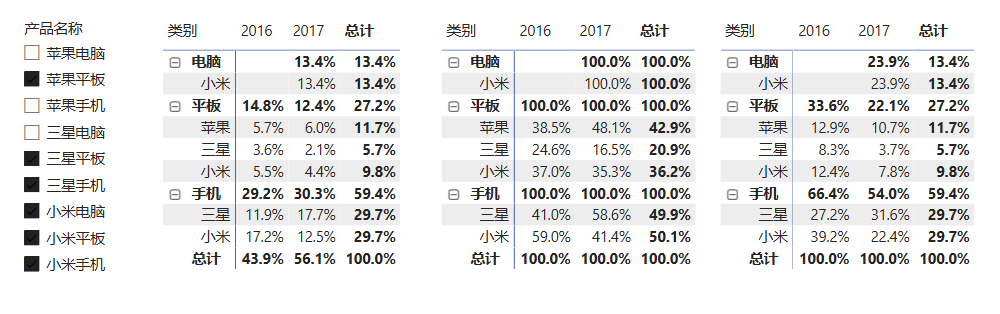
4.4.3 使用ISINSCOPE计算层级占比
2.5.1章节中,使用ALL函数实现了总体占比、品牌类别占比和产品占比。现在要实现的效果是:当处于品牌类别层级,显示类别在总体的占比;当打开品牌类别时,显示产品在类别的占比,类似于将1和2的效果合起来。此时就需要使用一个函数:ISINSCOPE。ISINSCOPE用于判断指定列是否是级别层次结构中的级别,如果是,返回True,其语法为:
cpp
ISINSCOPE(<columnName>) 对于上述产品层级结构,包括品牌类别和产品名称,可以使用 ISINSCOPE 函数来判断当前上下文是在品牌类别层级还是产品名称层级,分别计算不同的占比,并利用SWITCH函数在不同的情况下返回对应的数据。
cpp
层级占比 = SWITCH(
TRUE(),
ISINSCOPE('产品明细'[产品名称]),[销售总额]/CALCULATE([销售总额],ALLSELECTED('产品明细')),
ISINSCOPE('产品明细'[品牌]),[销售总额]/CALCULATE([销售总额],ALLSELECTED('产品明细'[品牌])),
[销售总额]/CALCULATE([销售总额],ALLSELECTED('产品明细')) //条件都不满足时的默认值
)
4.4.4 ALLEXCEPT 函数(分组)
ALLEXCEPT 函数用于从指定表的所有列中移除筛选器,除了你明确指定想要保留的那些列。其语法为:
cpp
ALLEXCEPT(<table>, <column1> [, <column2>, ...])<table>:需要移除过滤器的表。<column1>,<column2>, ...:需要保留其过滤器的列,其它列的过滤器全部清除。如果没有指定列,则表中的所有过滤器都将被清除。
4.4.4.1 计算累计求和与累计占比
-
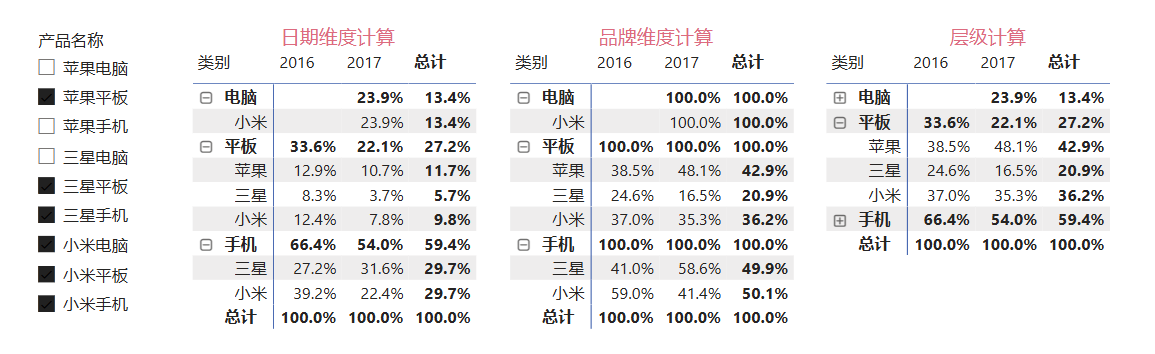
示例1:计算累计占比,保留单列筛选器
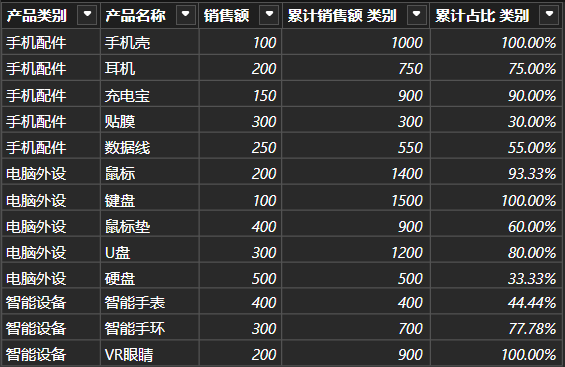
假设有以下表格,现在需要在每一个产品类别内部进行累计求和,进而计算出类别内的累计占比。首选新建列,输入:cpp累计销售额 类别 = CALCULATE( SUM('产品表'[销售额]), '产品表'[销售额]>=EARLIER('产品表'[销售额]), // 统计所有销售额大于当前销售额的行 ALLEXCEPT('产品表','产品表'[产品类别]) // 确保只在产品类别内进行统计 )
这里分类累计销售额的实现,主要是使用了ALLEXCEPT函数,删除其他所有的过滤器,而只保留它的参数列的过滤器,达到类似分组的效果。在这个例子中就是删除"产品类别"之外的其他所有的过滤器,因此可以正确计算出期望的结果。
接着计算累计占比,这样就可以轻松进行产品类别内部的20/80分类或者ABC分类了。
cpp
累计占比 类别 =
DIVIDE(
[累计销售额 类别],
CALCULATE(
SUM('产品表'[销售额]),
ALLEXCEPT('产品表','产品表'[产品类别])
)
)
-
计算员工累计工资(保留多列筛选器)
假设有一张工资表,我们要计算出每名员工截至当月,本年累计的工资数。这里是按照员工和年度来求累计,所以ALLEXCEPT函数需要保留两个过滤器:
cpp累计工资 = CALCULATE( SUM('工资表'[每月工资]), '工资表'[年度月份]<=EARLIER('工资表'[年度月份]), ALLEXCEPT('工资表','工资表'[年度],'工资表'[姓名]) )
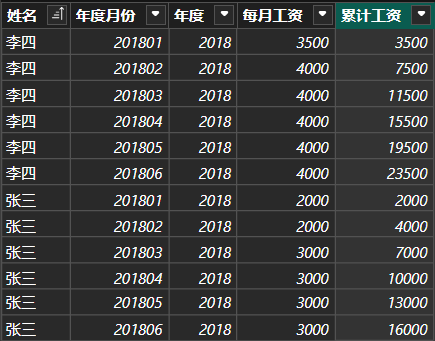
累计工资对每名员工分别求累计,并在新的一年重新开始计算,正是需要的结果。
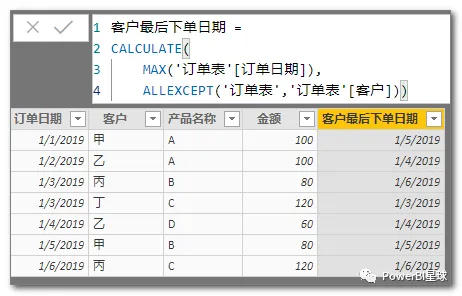
4.4.4.2 计算客户最后下单日期(计算列与度量值)
如果要返回当前客户的最后下单日期,需要使用ALLEXCEPT,只保留客户列的筛选。
还可以用DAX新建表,一次性把最后下单记录提取出来:
cpp
表 =
VAR table_ =
ADDCOLUMNS( // 使用 ADDCOLUMNS 函数向 '订单表1' 添加一个新列 "最后下单记录"
'订单表1',
"最后下单记录",
VAR lastdealdate =
CALCULATE(
MAX('订单表1'[日期]),
ALLEXCEPT('订单表1', '订单表1'[客户])
)
RETURN
IF([日期] = lastdealdate, "是") // 如果当前订单日期等于该客户的最后下单日期,则返回"是"。
)
RETURN
FILTER(table_, [最后下单记录] = "是") // 从添加了新列的表中筛选出标记为"是"的记录,即每个客户的最后下单记录。4.4.5 总结
| 函数 | 描述 | 语法 |
|---|---|---|
| ALL | 清除数据模型中,指定列上的所有过滤器,包括上下文和页面级别的过滤器。 | ALL(<table>[, <column>...]) |
| ALLSELECTED | 清除数据模型、报表级别和视觉对象(如切片器) 上指定列的筛选器。 | ALLSELECTED(<table>[, <column>...]) |
| ALLEXCEPT | 清除除指定列之外的所有列上的过滤器。 | ALLEXCEPT(<table>[, <except_column>...]) |
4.5 SELECTEDVALUE(动态分析)
4.5.1 语法
SELECTEDVALUE函数用于从指定列中提取单一值,它在处理数据筛选和上下文计算时非常有用,其语法为:
cpp
SELECTEDVALUE(<columnName>, [<alternateResult>])columnName: 使用标准DAX语法的现有列的名称,不能是表达式。alternateResult:可选。当指定列中没有值或有一个以上值时返回的结果,默认为空值(BLANK)。
4.5.2 动态分析
在 Power BI Desktop 中,通过创建参数,可以为报告引入变量,以实现交互式分析和可视化,例如通过一个切片器,随意选择销售折扣(0.5-1),得到计算折扣后的销售额。

-
新建参数 :在"建模"选项卡中,点击"新建参数"按钮,此时会弹出一个对话框,有"字段"或"数值范围"两种类型的参数可供配置。
-
配置参数 :按下图配置参数,选择"将切片器添加到此页"复选框,创建之后,会在报表页面创建一个参数切片器,同时在数据窗格中,创建了一个度量值。
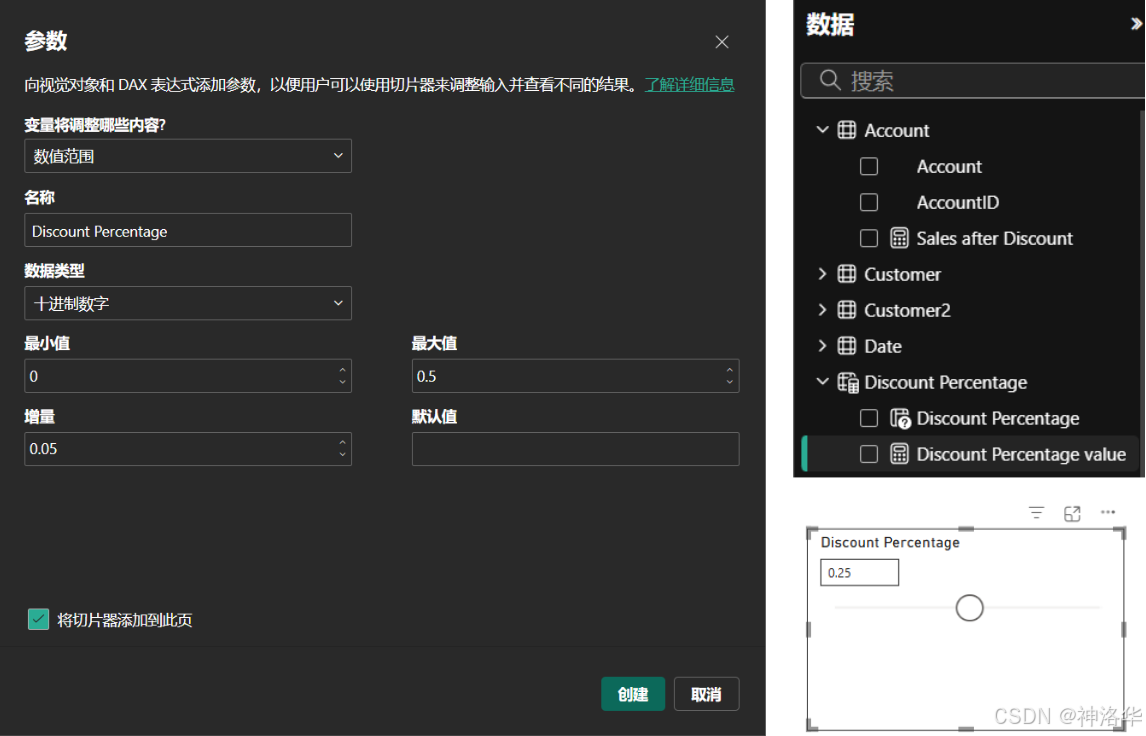
创建参数后,参数和其关联的度量值将成为数据模型的一部分。这意味着它们不仅可以在当前报告页面上使用,还可以在其他报告页面上使用。
- 创建度量值:新建度量值,表示折扣后的销售额。
cpp
Sales after Discount = SUM(Sales[Sales Amount]) - (SUM(Sales[Sales Amount]) * 'Discount percentage' [Discount percentage Value])- 创建柱状图 :以OrderDate字段为X轴,
Sales Amount和Sales after Discount作为值。这样,柱状图将同时显示原始销售额和折扣后的销售额。当移动筛选器中的滑块时,折扣值会对应调整,Sales after Discount列也会对应变化。
4.5.3 使用SELECTEDVALUE优化动态计算
在动态的计算中,如果切片器没有选择任何值或者选择了多个值时,可能会导致错误 。为了避免这种情况,可以使用函数进行处理。在以前的版本,通常使用 IF,HASONEVALUE,VALUES 这三个函数的组合来测试列是否按特定值进行筛选,比如:
cpp
Australian Sales Tax =
IF(
HASONEVALUE(Customer[Country-Region]),
IF(
VALUES(Customer[Country-Region]) = "Australia",
[Sales] * 0.10
)
)HASONEVALUE:检查当前筛选器上下文中是否只有一个值,避免VALUES对多值列进行操作返回一个表(这样下一步与标量比较就会报错)。VALUES:如果只有一个值,使用 VALUES 检查这个值是否为"Australia";IF:如果值为"Australia",则计算销售税为销售额的 10%;否则,返回空白。
SELECTEDVALUE 函数会自动检查某个列是否是单个值,如果是,则返回该值;否则返回空白(默认),所以SELECTEDVALUE函数等价于:
cpp
IF(HASONEVALUE(<columnName>), VALUES(<columnName>), <alternateResult>)使用SELECTEDVALUE可以更简洁更高效地处理这个问题:
cpp
Australian Sales Tax =
IF(
SELECTEDVALUE(Customer[Country-Region]) = "Australia",
SUM(Sales[SalesAmount]) * 0.10
)注意事项:
- 参数最多只能有 1,000 个唯一值,如果超过1000,Power BI 将对参数值进行均匀采样。此时,参数的值可能无法完全覆盖所有可能的选项,但通常足以满足大多数分析需求。
- 参数主要用于视觉对象中的度量值计算。当在维度计算中使用参数时,可能会出现计算不准确的情况。
4.6 LASTNONBLANK 与 LASTNONBLANKVALUE
4.6.1 语法
LASTNONBLANK函数和LASTNONBLANKVALUE函数,都用于在指定的列中,根据列的排序逻辑找到最后一个非空值(比如获取最新的销售数据、库存数据等),二者语法相同:
cpp
LASTNONBLANK(<column>, <expression>)
LASTNONBLANKVALUE(<column>, <expression>)column:可以是表中的列,或者返回列的表达式expression:表达式,用于判断非空条件,其结果会受到当前上下文的影响,包括筛选上下文和行上下文。
二者在返回值和功能性上存在差异:
| 函数 | 返回值类型 | 应用场景 | 示例 |
|---|---|---|---|
| LASTNONBLANK | 表函数(返回单行单列的表) | 将结果用于表操作(如FILTER、CALCULATE) |
|
| LASTNONBLANKVALUE | 标量函数(返回单个值) | 直接返回数值结果(如显示在度量中) |
cpp
LASTNONBLANK(Sales[Date], SUM(Sales[Amount])) // 返回一个单行表,例如2023-12-31
LASTNONBLANKVALUE(Sales[Date], SUM(Sales[Amount])) // 最后一个非空SUM(Sales[Amount])的具体数值(如5000)。4.6.2 库存余额统计
假设每日库存余额的数据如下:
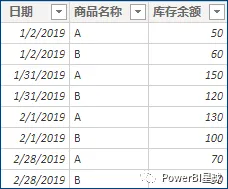
计算每月期末库存:
cpp
期末库存余额 = CALCULATE(SUM('库存表'[库存余额]),LASTDATE('日期表'[日期]))
3月份竟然返回了空值,这是因为LASTDATE只返回的当前月份的最后一天,如果最后一行记录不是月末,就不会返回数据。可以改为:
cpp
期末库存余额 优化 =
CALCULATE (
SUM ('库存表'[库存余额]),
FILTER (
ALL ('日期表'),
'日期表'[日期] = MAX ('库存表'[日期])
)
)
也可以利用LASTNONBLANK函数,找到最后一个有余额的日期,再进行计算,结果是一样的。
cpp
期末库存余额 优化2 =
CALCULATE (
SUM ( '库存表'[库存余额] ),
LASTNONBLANK (
'日期表'[日期],
[库存]
)
)