一、注意力提示
随意:跟随主观意识,也就是指有意识。
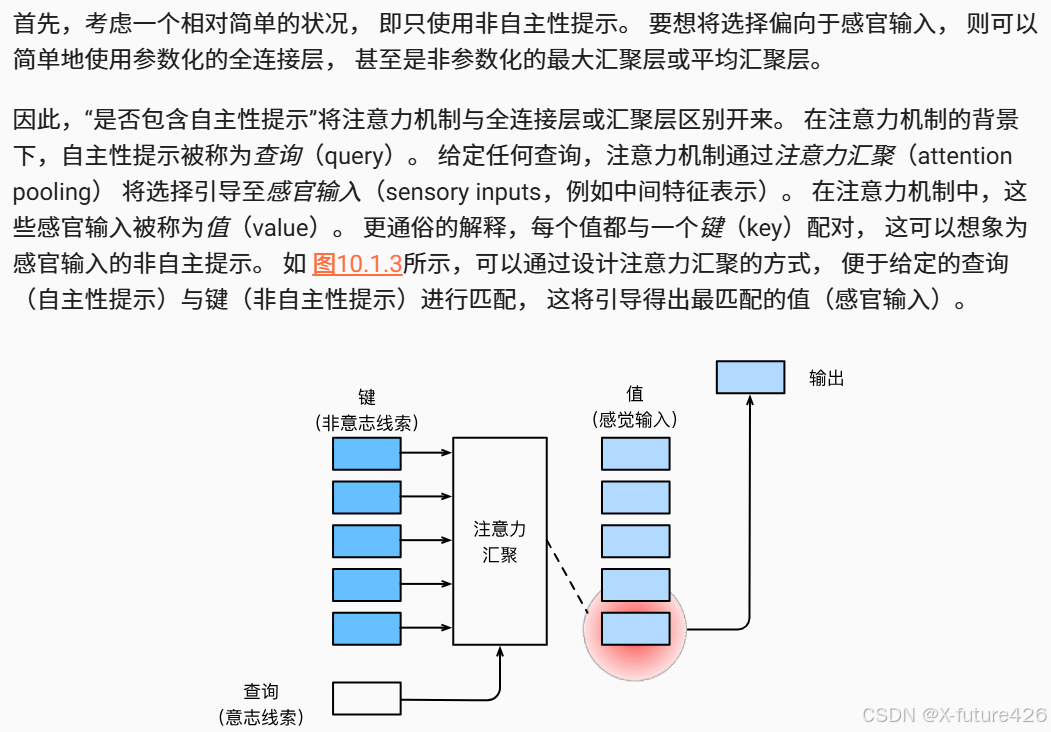
注意力机制:考虑"随意线索",有一个注意力池化层,将会最终选择考虑到"随意线索"的那个值
二、注意力汇聚
这一部分也就是讲第一大点中"注意力汇聚"那个池化层如何实现池化操作。
1.非参注意力池化层
为什么叫"非参"呢?因为这里定义的池化层函数,函数中所用到的数据均来源于之前的变量,不需要学习任何参数,K是一个函数。
 这里的query、key、value不懂是什么意思,好像和理解的函数对应不上,李沐没讲
这里的query、key、value不懂是什么意思,好像和理解的函数对应不上,李沐没讲
1.1平均池化
这是最简单的池化方案,就是求解平均值,然后映射到value(值)上。
1.2NW核回归
就是K这个函数选取高斯核K(u),然后入代到上面的池化函数中。

2.参数注意力池化层
就是引入了一个可以学习的w作为参数,每次进行迭代。

二、注意力分数
1.基本介绍
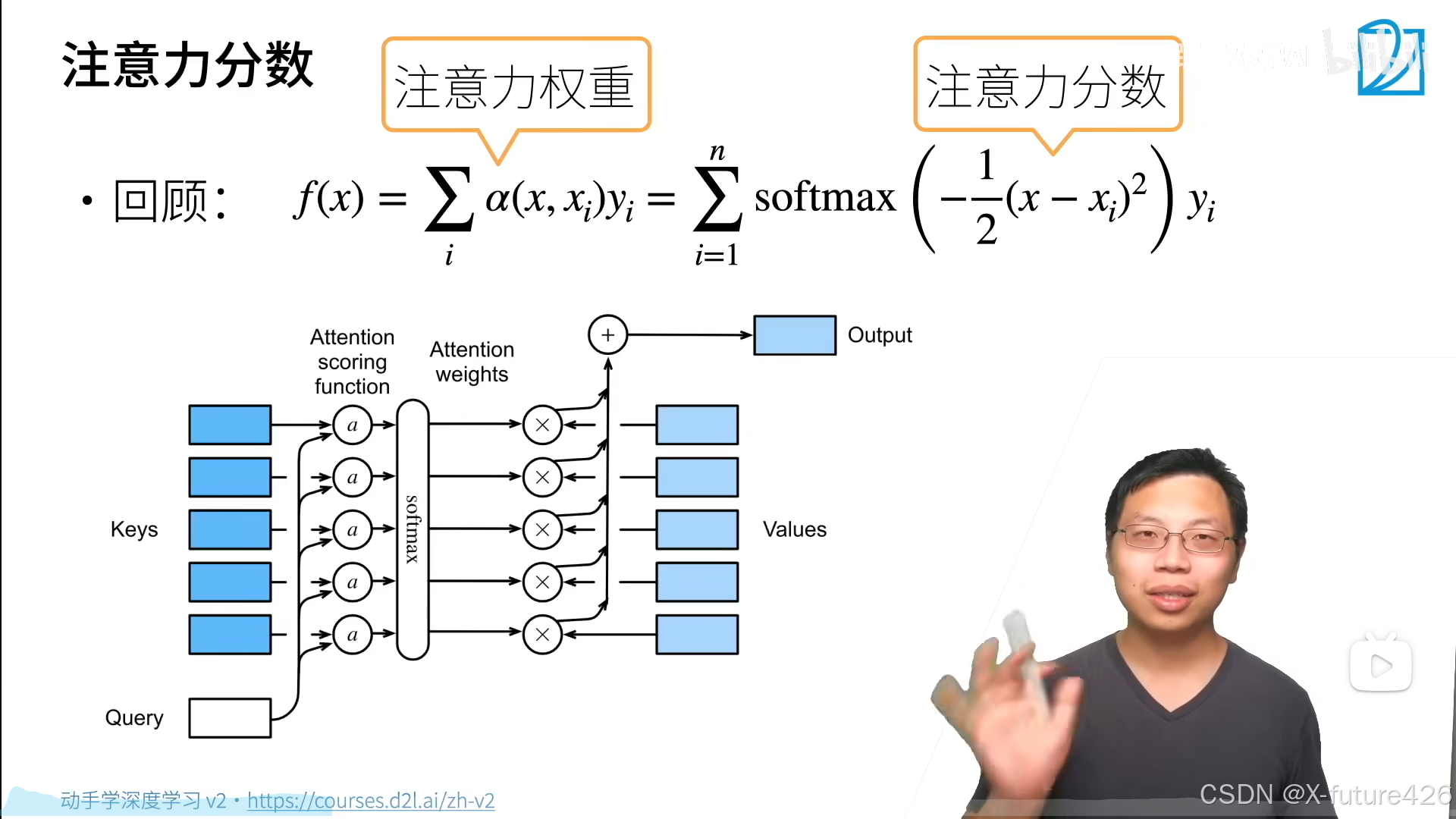

就是说池化层的池化函数关键在于如何定义函数a,函数a就是注意力分数,softmax其实就是将其转换到0-1上,都弄成正的小数。
2.函数a的定义方式
2.1可加性的注意力

可加性的注意力,将函数a定义为上面所示的样子,其实就是将key和value合并起来,具体怎么个意思没太懂。
2.2Scaled Dot-Production Attention


三、自注意力
1.基本含义
将Xi当作key,value,query来提取序列特征。
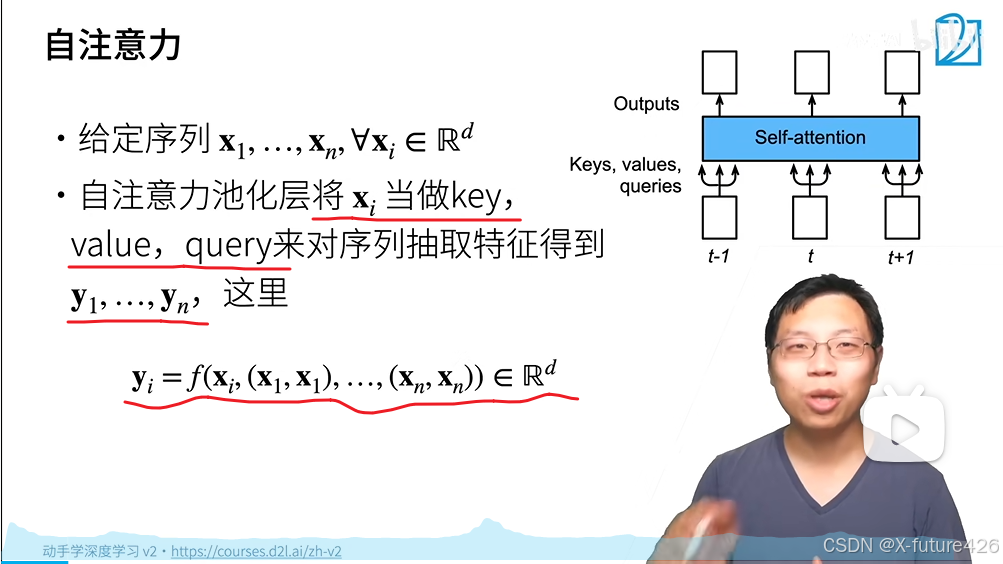
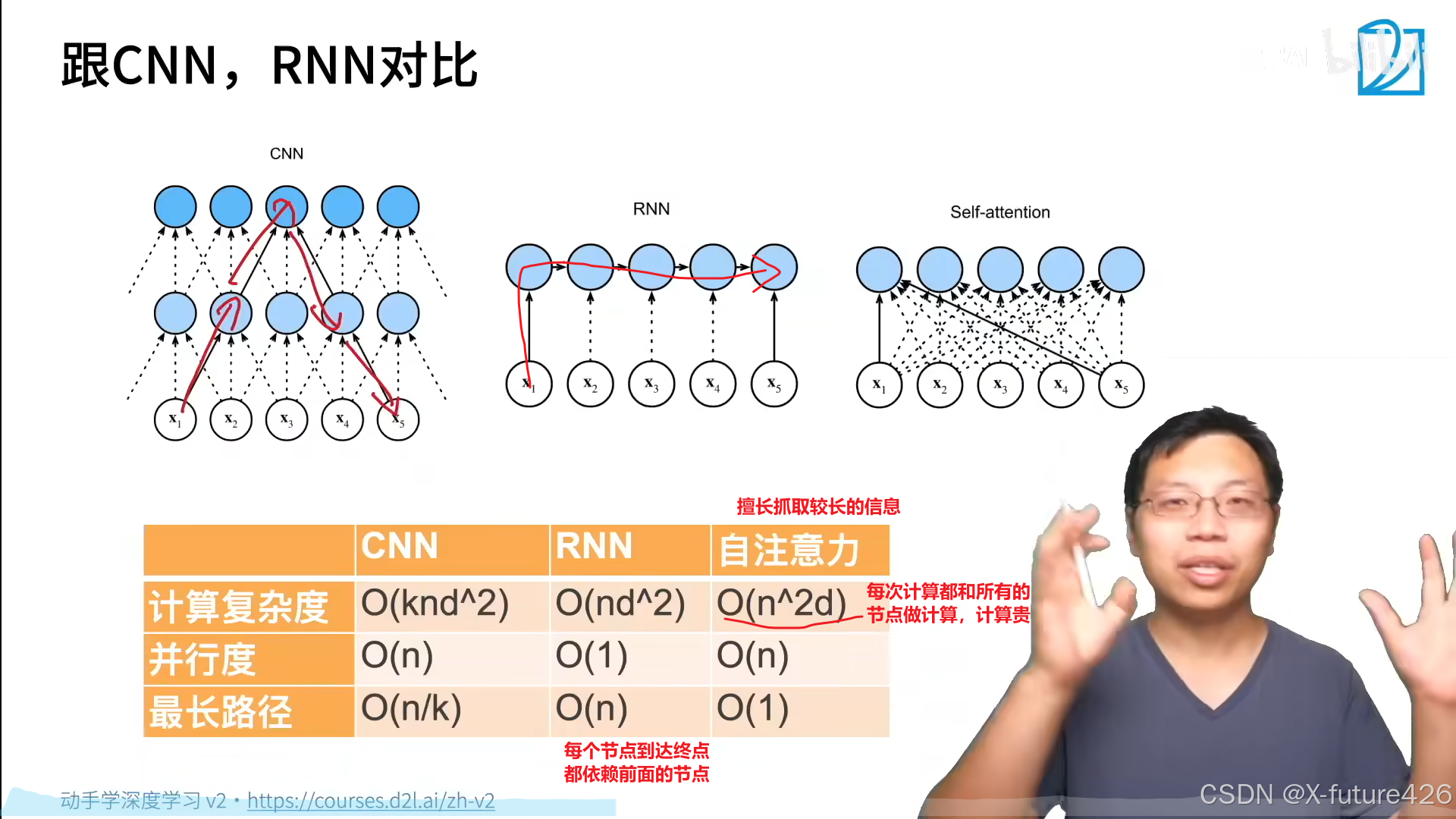 2.位置编码
2.位置编码
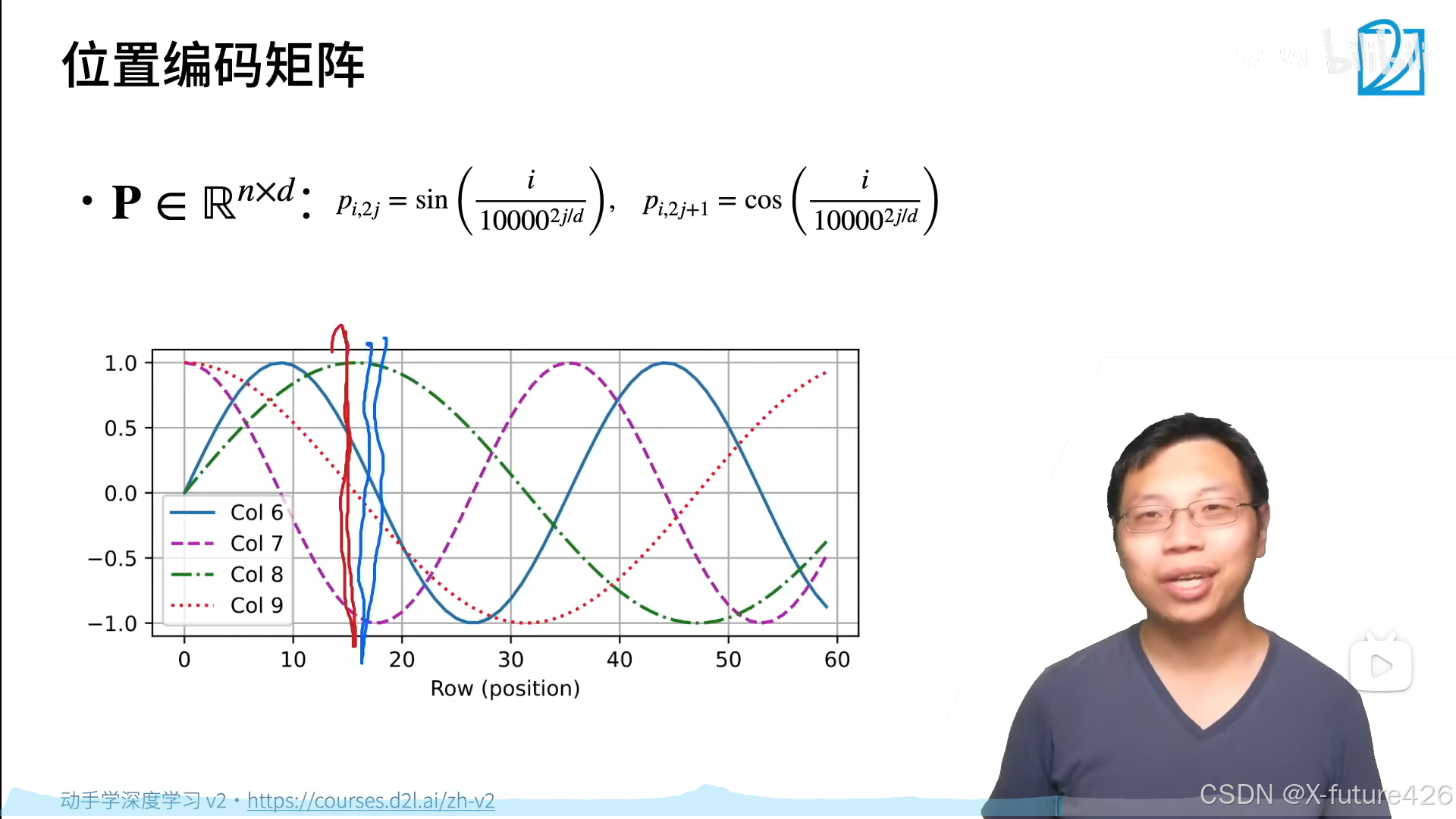
3.位置编码矩阵
这个矩阵P就是计算的出的矩阵X的位置信息编码矩阵。从图中可以看出,其实就是将位置信息加到了矩阵X输入上去。
4.绝对位置信息
对每个样本都给一个独一无二的位置信息,将这个位置信息加到原矩阵信息上去。
 5.相对位置信息
5.相对位置信息

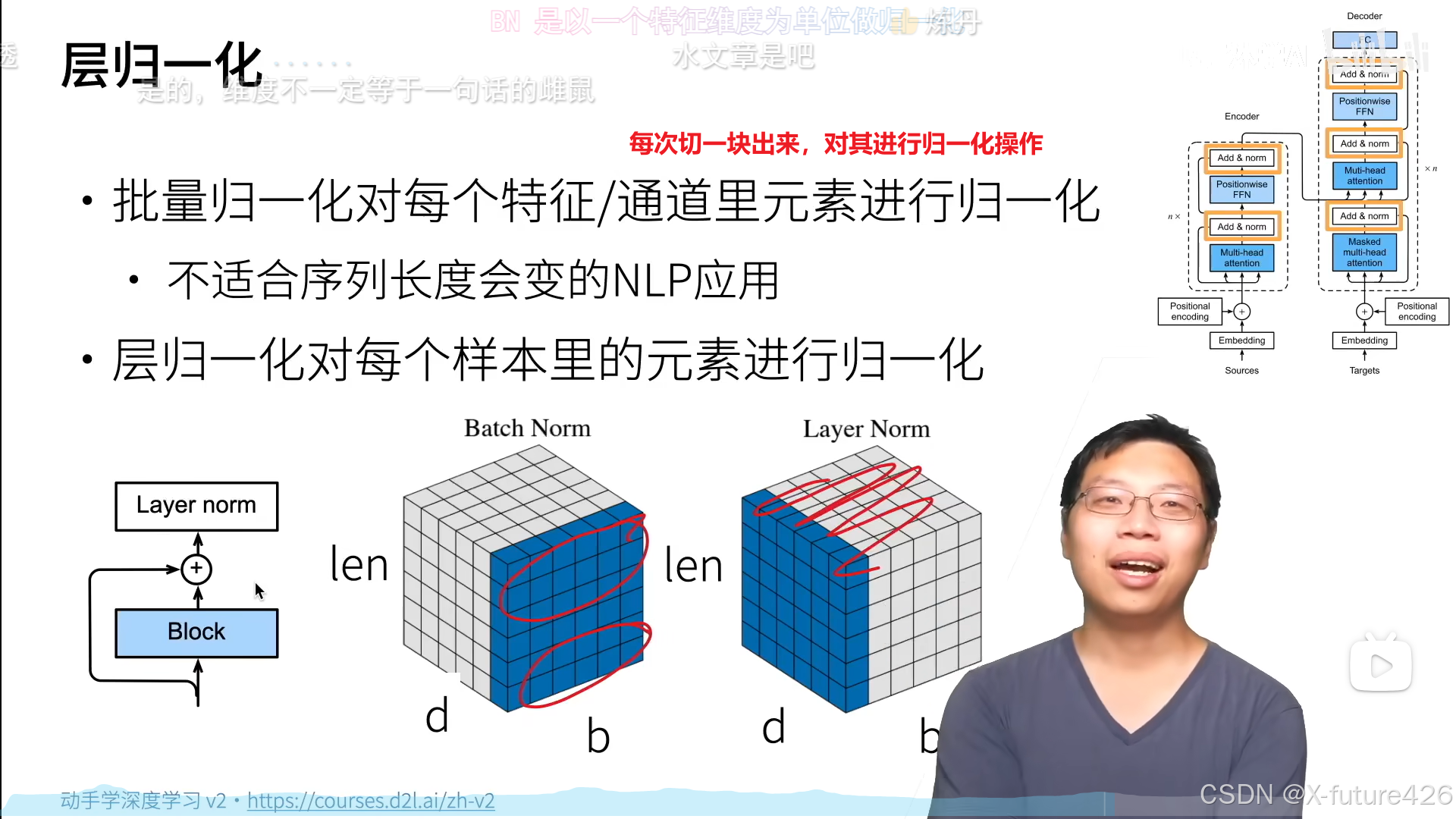
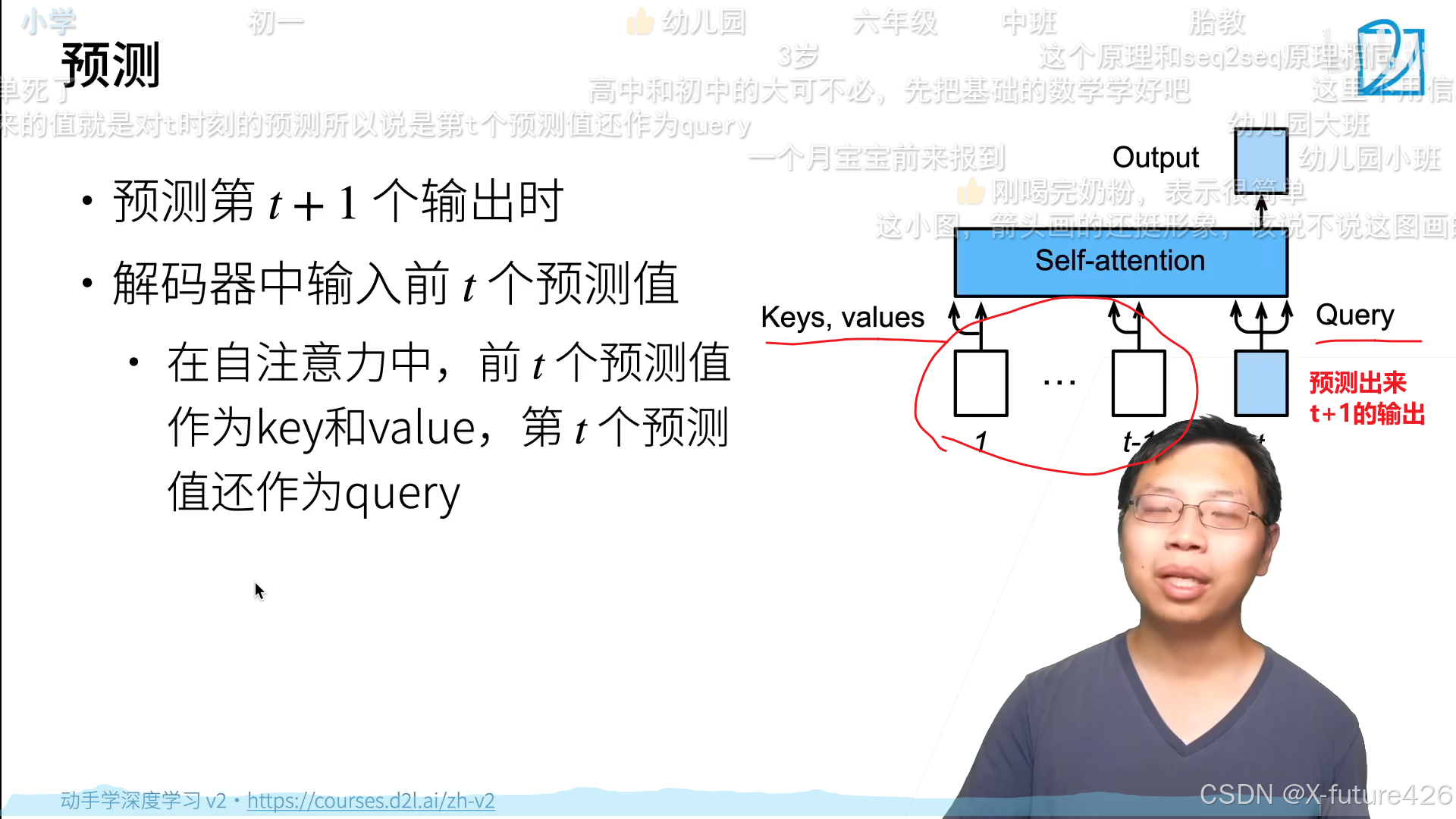
四、Transformer
沐神说:老大的小孩过来看到BERT说,欸这不是芝麻街......
1.架构
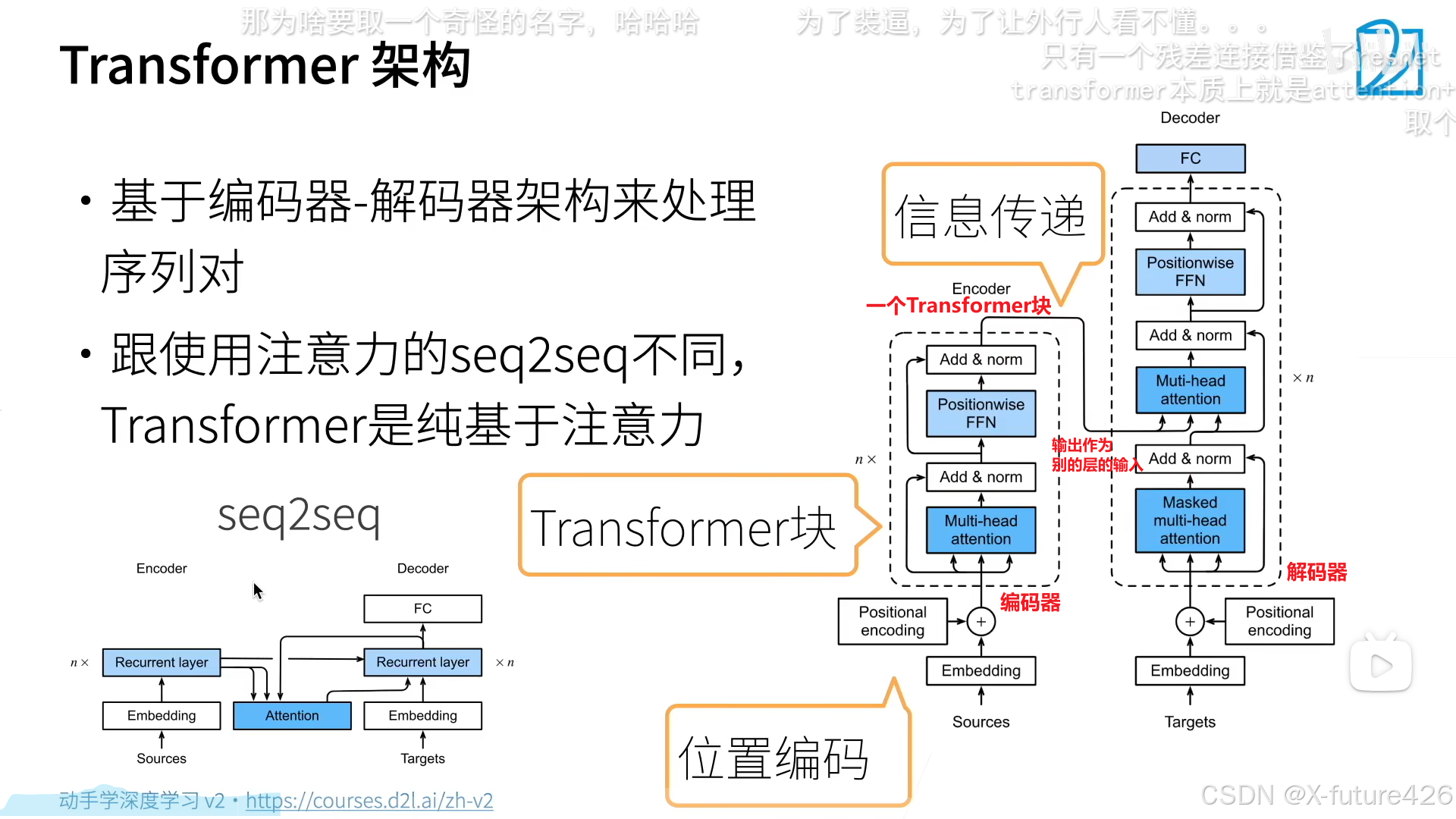
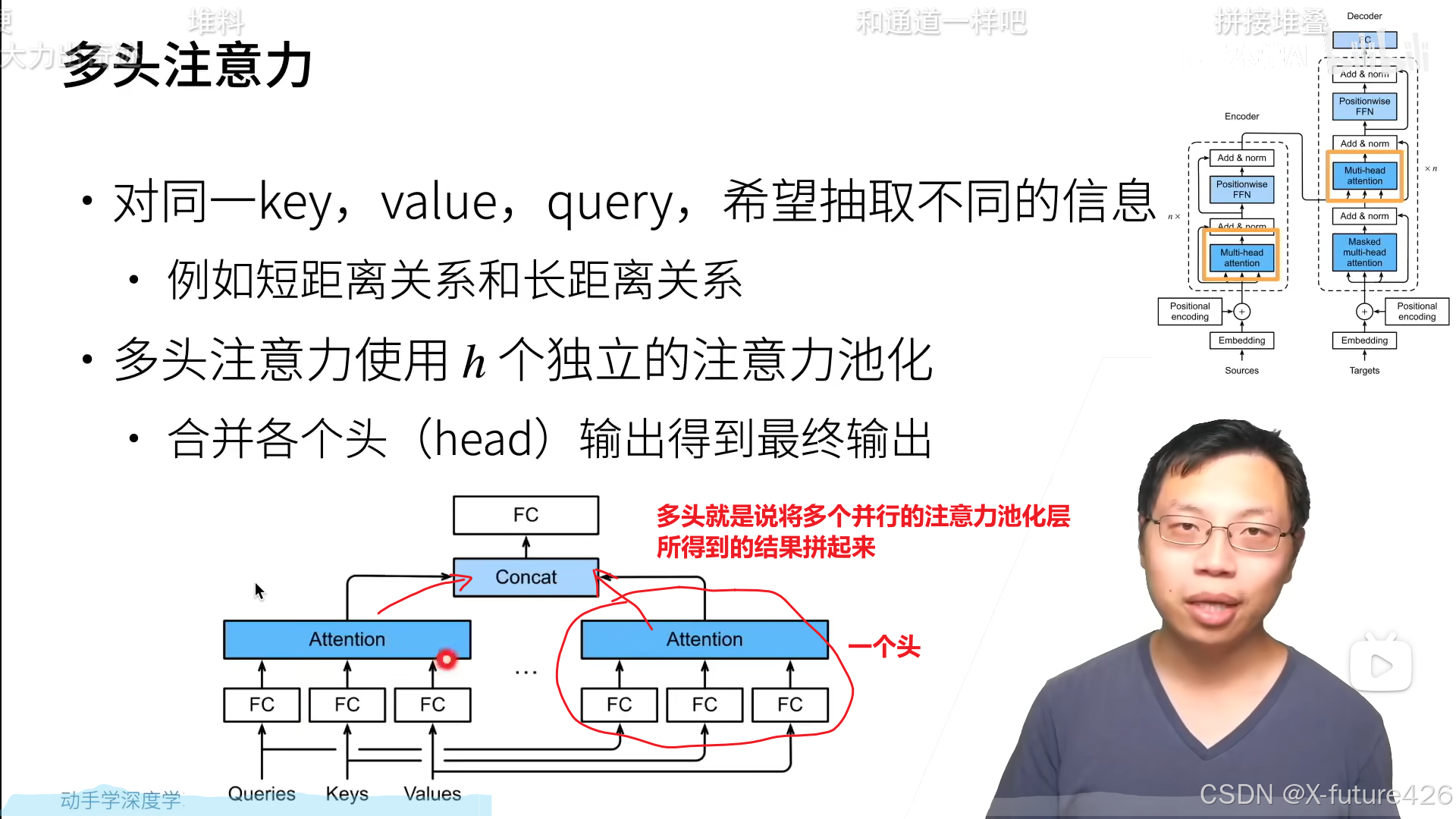
2.多头注意力