#作者:张桐瑞
文章目录
在Kafka的世界里,主题(Topic)是数据存储的逻辑容器,而在主题之下,还细分了若干个分区,这种三级结构(主题 - 分区 - 消息)构成了Kafka独特的数据组织方式。主题下的每条消息仅会保存在某一个分区中,而非多个分区重复存储。下面这张图直观地展示了Kafka的三级结构:
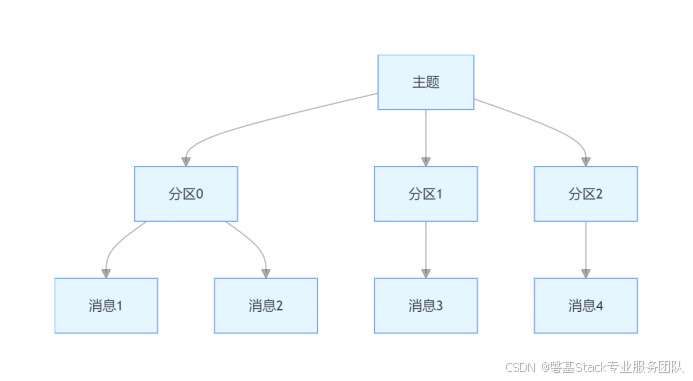
可以看到,在这个结构中,消息被有序地存储在各个分区里。此时,我们不禁会思考:为什么Kafka要采用这样的设计?为何使用分区,而不是简单地利用多个主题呢?
一、分区的作用
分区的核心作用在于提供负载均衡能力,助力实现系统的高伸缩性(Scalability)。不同的分区能够分布在不同节点的机器上,数据的读写操作都以分区为粒度进行。这意味着每个节点的机器都能独立处理各自分区的读写请求,极大地提升了系统的处理效率。并且,通过添加新的节点机器,还能进一步增加整体系统的吞吐量。
实际上,分区的概念和分区数据库早在1980年就已出现,例如当时的Teradata数据库就引入了分区概念。值得注意的是,在不同的分布式系统中,分区的叫法有所不同。Kafka中称之为分区,MongoDB和Elasticsearch中叫分片(Shard),HBase中是Region,Cassandra里则被称作vnode。虽然它们的实现原理存在差异,但底层分区(Partitioning)的核心思想是一致的。
除了负载均衡,分区还能满足一些业务级别的需求,比如实现业务级别的消息顺序控制,后续会通过具体案例详细说明。
二、分区策略
Kafka生产者的分区策略决定了消息会被发送到哪个分区,它既有默认策略,也支持用户自定义。若要自定义分区策略,需显式配置生产者端的partitioner.class参数。在编写生产者程序时,创建一个实现org.apache.kafka.clients.producer.Partitioner接口的类即可。该接口定义了partition()和close()两个方法,通常只需实现关键的partition方法,其方法签名如下:
int partition(String topic, Object key, byte\[\] keyBytes, Object value, byte\[\] valueBytes, Cluster cluster);
其中,topic、key、keyBytes、value和valueBytes属于消息数据,cluster包含集群信息(如主题数量、Broker数量等)。利用这些信息,就能确定消息应被发送到的分区。下面介绍几种常见的分区策略。
(一)轮询策略
轮询策略,也叫Round - robin策略,即顺序分配。假设一个主题有3个分区,那么第一条消息会被发送到分区0,第二条到分区1,第三条到分区2,依此类推。当发送第4条消息时,又会重新从分区0开始分配。具体如下:
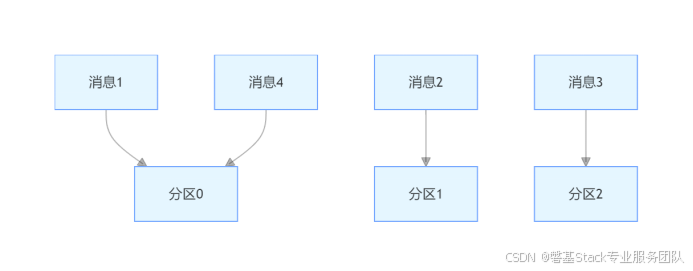
这一策略是Kafka Java生产者API的默认分区策略。在未指定partitioner.class参数时,生产者程序会按照轮询方式,将消息均匀地分配到主题的所有分区间。轮询策略具备出色的负载均衡能力,能确保消息尽可能平均地分布到各个分区,是常用的分区策略之一。
(二)随机策略
随机策略(Randomness策略)是将消息随机放置到任意一个分区。实现该策略的partition方法代码如下:
List partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
先获取主题的总分区数,然后随机返回一个小于该数的正整数。虽然随机策略也试图将数据均匀分散到各个分区,但实际效果不如轮询策略,在新版本Kafka中,默认分区策略已从随机改为轮询。
(三)按消息键保序策略
Kafka允许为每条消息定义消息键(Key),这个Key用途广泛,可以是具有业务含义的字符串,如客户代码、部门编号,也能用来表示消息元数据。在Kafka不支持时间戳时,有些工程师会将消息创建时间封装在Key中。当消息定义了Key后,能保证相同Key的所有消息都进入同一个分区。由于每个分区内的消息处理是有序的,因此该策略被称为按消息键保序策略。实现代码如下:
List partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();
Kafka的默认分区策略实际上融合了这两种策略:有Key时,采用按消息键保序策略;无Key时,则使用轮询策略。
三、实际案例:消息顺序问题的解决
某企业发送的Kafka消息存在因果关系,处理时必须保证有序性,否则先处理"果"后处理"因"会导致业务混乱。起初,企业的做法是将Kafka主题设置为单分区,所有消息都在这一个分区内读写,虽然保证了全局顺序性,但牺牲了Kafka多分区带来的高吞吐量和负载均衡优势。
经过调研发现,这些具有因果关系的消息在消息体中都封装了固定的标志位。于是建议企业针对该标志位设定专门的分区策略,确保同一标志位的所有消息都发送到同一分区。这样既能保证分区内的消息顺序,又能享受多分区的性能优势。这种基于个别字段的分区策略,本质上就是按消息键保序的思想,更合适的做法是将标志位数据提取出来统一放到Key中,这样更契合Kafka的设计理念。改造后,企业的消息处理吞吐量提升了40多倍,充分体现了自定义分区策略的强大作用。
四、其他分区策略:基于地理位置的分区策略
在大规模的Kafka集群中,尤其是跨城市、跨国家甚至跨大洲的集群,基于地理位置的分区策略较为常见。假设其原本所有服务都部署在北京的一个机房,现在计划在广州新建一个机房,并从两个机房选取部分机器组成一个大的Kafka集群。
若用Kafka实现,创建一个双分区主题,再编写两个消费者程序分别处理南北方注册用户逻辑即可。但问题在于,要确保南北方注册用户的消息准确发送到对应的机房,因为处理消息的消费者程序仅在特定机房启动。此时,可以根据Broker所在的IP地址实现定制化的分区策略.
Kafka的分区机制及其分区策略在提升系统性能、满足业务需求方面发挥着重要作用。理解并合理运用这些知识,能让我们在使用Kafka构建分布式系统时更加得心应手。