一、ReLU(Rectified Linear Unit,修正线性单元)
梯度是深度学习中最常用的激活函数之一,因其简单、高效且能有效缓解梯度消失问题而被广泛使用。
1. 数学定义
- 函数表达式:
\\text{ReLU}(x) = \\max(0, x) = \\begin{cases} x \& \\text{if } x \\geq 0 \\ 0 \& \\text{if } x \< 0 \\end{cases}
- 导数(梯度):
\\frac{d}{dx}\\text{ReLU}(x) = \\begin{cases} 1 \& \\text{if } x \\geq 0 \\ 0 \& \\text{if } x \< 0 \\end{cases}
2. 核心特性
- 非线性:虽然形式简单,但ReLU的非线性特性使神经网络能够学习复杂函数(多个ReLU组合可逼近任意连续函数)。
- 稀疏激活:对负输入输出0,可让网络中的部分神经元"关闭",产生稀疏性,提升计算效率。
- 缓解梯度消失:对于正输入,梯度恒为1,避免了传统Sigmoid/Tanh函数在反向传播时因梯度连乘导致的梯度消失问题(尤其在深层网络中)。
3. 优缺点
- 优点 :
- 计算高效:仅需比较和取最大值操作,比Sigmoid/Tanh的指数运算快得多。
- 生物学合理性:类似神经元的"全有或全无"激活模式。
- 实际效果优异:在CNN、MLP等结构中表现良好,加速模型收敛。
- 缺点 :
- 死亡ReLU问题(Dying ReLU):若输入始终为负(如初始化不当或学习率过高),梯度为0,神经元永久失效。
- 非零中心化:输出均值大于0,可能影响梯度更新效率(但影响通常较小)。
4. ReLU的变体
为解决死亡ReLU问题,研究者提出了多种改进版本:
| 变体名称 | 公式 | 特性 |
|---|---|---|
| Leaky ReLU | max ( 0.01 x , x ) \max(0.01x, x) max(0.01x,x) | 负区间引入微小斜率(如0.01),避免神经元死亡。 |
| Parametric ReLU (PReLU) | max ( α x , x ) \max(\alpha x, x) max(αx,x) | 斜率 α \alpha α作为可学习参数,更灵活。 |
| ELU | ||
| $$ | ||
| \begin{cases} x & \text{if } x \geq 0 \ \alpha(e^x - 1) & \text{if } x < 0 \end{cases} | ||
| $$ | ||
| 负区间平滑过渡至负值,缓解死亡问题且接近零均值。 | ||
| Swish | x ⋅ σ ( β x ) x \cdot \sigma(\beta x) x⋅σ(βx) | 谷歌提出的平滑激活函数( σ \sigma σ为Sigmoid),可能优于ReLU。 |
5. 代码示例(PyTorch/TensorFlow)
1:在简单全连接网络中使用ReLU(PyTorch)
python
import torch
import torch.nn as nn
# 定义一个包含ReLU的三层全连接网络
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(784, 256) # 输入层→隐藏层1
self.relu = nn.ReLU(inplace=True) # inplace=True可节省内存
self.fc2 = nn.Linear(256, 64) # 隐藏层1→隐藏层2
self.fc3 = nn.Linear(64, 10) # 隐藏层2→输出层
def forward(self, x):
x = self.fc1(x)
x = self.relu(x) # 在隐藏层1后使用ReLU
x = self.fc2(x)
x = self.relu(x) # 在隐藏层2后再次使用ReLU
x = self.fc3(x)
return x
# 使用示例
model = SimpleNet()
input_data = torch.randn(32, 784) # 模拟批量数据(32样本,每个784维)
output = model(input_data)
print(output.shape) # 输出形状:torch.Size([32, 10])2:在卷积神经网络中使用ReLU(TensorFlow/Keras)
python
import tensorflow as tf
from tensorflow.keras import layers
# 定义一个CNN模型,包含ReLU激活函数
model = tf.keras.Sequential([
layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)), # 卷积层+ReLU
layers.MaxPooling2D((2,2)),
layers.Conv2D(64, (3,3), activation='relu'), # 第二个卷积层+ReLU
layers.Flatten(),
layers.Dense(64, activation='relu'), # 全连接层+ReLU
layers.Dense(10, activation='softmax') # 输出层(分类任务用softmax)
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 打印模型结构
model.summary()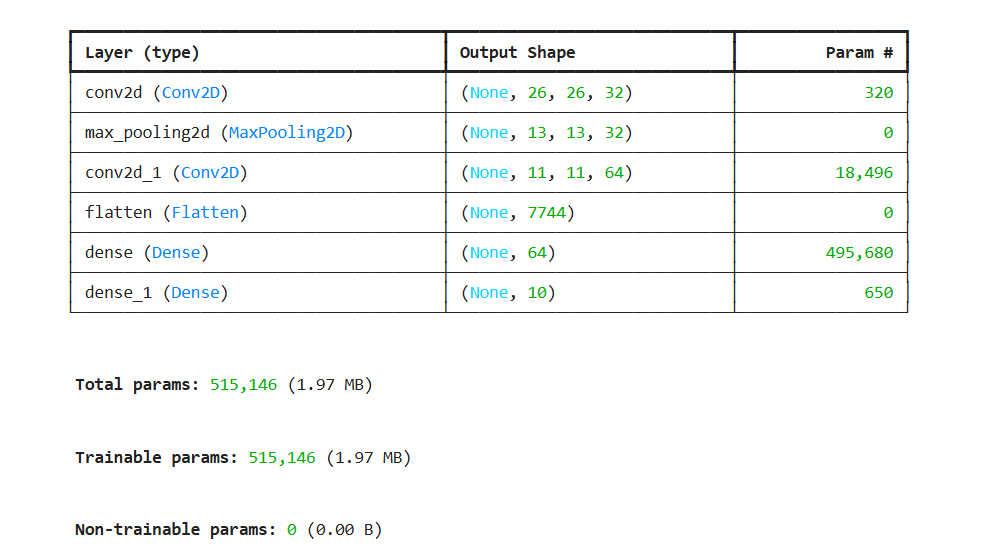
二、梯度(Gradient)简介
1. 什么是梯度?
梯度是多元函数在某一点处变化率最大的方向及其大小,是导数的多维推广。
- 数学定义 :对函数 f ( x 1 , x 2 , . . . , x n ) f(x_1, x_2, ..., x_n) f(x1,x2,...,xn),其梯度为向量:
∇ f = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x n ) \nabla f = \left( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n} \right) ∇f=(∂x1∂f,∂x2∂f,...,∂xn∂f) - 物理意义:梯度指向函数值增长最快的方向,梯度大小表示变化速率。
2. 梯度在深度学习中的作用
在神经网络中,梯度用于优化模型参数(如权重和偏置),是反向传播(Backpropagation)的核心。
关键流程
- 前向传播:输入数据通过网络计算输出。
- 计算损失:输出与真实标签的差异(如交叉熵、均方误差)。
- 反向传播:从输出层向输入层逐层计算损失对每个参数的梯度。
- 参数更新:使用优化器(如SGD、Adam)沿梯度反方向更新参数,降低损失。
3. 梯度消失与梯度爆炸
问题定义
- 梯度消失 :深层网络中,梯度在反向传播时逐层减小,导致底层参数几乎不更新。
- 常见原因:使用Sigmoid/Tanh激活函数(导数小于1,连乘后梯度指数级衰减)。
- 梯度爆炸 :梯度在反向传播时逐层增大,导致参数更新幅度过大,模型无法收敛。
- 常见原因:权重初始化过大或网络过深。
解决方案
| 问题 | 解决方案 |
|---|---|
| 梯度消失 | - 使用ReLU及其变体(LeakyReLU、PReLU) - 残差连接(ResNet) - 批归一化(BatchNorm) |
| 梯度爆炸 | - 梯度裁剪(Gradient Clipping) - 权重正则化(L2正则化) - 合理的权重初始化(如Xavier/He初始化) |
4. 代码示例:梯度计算与监控
PyTorch中手动计算梯度
python
import torch
# 定义模型和输入
x = torch.tensor([2.0], requires_grad=True)
y = x ** 2 + 3 * x + 1 # 函数 y = x² + 3x + 1
# 计算梯度
y.backward() # 自动计算y关于所有requires_grad=True的变量的梯度
print(x.grad) # 输出: tensor([7.])