简介
UniK3D是一个用于单目3D几何估计的新框架,可以处理任何相机设置,从针孔到全景。它引入了一个完全球形的输出表示来建模3D场景,这允许更好地分离相机和场景几何。

论文地址
https://arxiv.org/abs/2503.16591![]() https://arxiv.org/abs/2503.16591
https://arxiv.org/abs/2503.16591
论文粗读
"单目3D估计对视觉感知至关重要。然而,当前的方法存在缺陷,因为它们依赖于过于简化的假设,如镜头相机模型或矫正图像。这些局限性严重限制了它们的普遍适用性,导致在现实世界场景中使用鱼眼或全景图像时表现不佳,并导致大量的上下文丢失。为了解决这个问题,我们提出了UniK3D1,这是第一个能够对任何相机进行建模的通用单目3D估计方法。我们的方法引入了球形3D表示,这允许更好地分离相机和场景几何,并能够实现对不受限制相机模型的精确的度量3D重建。我们的相机组件通过学习球谐波的叠加实现了一种新的、模型独立的光束的表示。我们还引入了一个角度损失,与相机模块设计一起,防止3D输出在宽视角相机的收缩。在13个不同的数据集上进行的全面零样本评估展示了UniK3D在3D、深度和相机指标上的最先进性能,在具有大视场和全景设置的挑战性场景中取得了显著的进步,同时在传统的小视场镜头相机领域保持了最高的准确性。代码和模型可在github.com/lpiccinelli-eth/unik3d上获得"
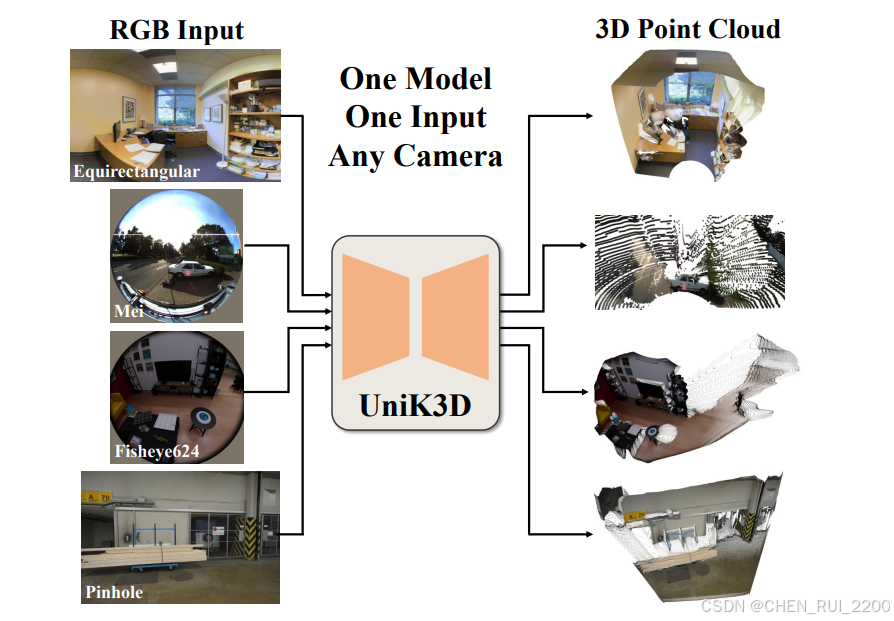
论文引入UniK3D,它是一种新颖且多功能的方法,可以从单张图像中,对任何类型的相机(从镜头到全景相机)提供精确的度量3D几何估计,无需任何相机信息。通过利用(i)一个灵活且通用的球面公式,既适用于3D空间的径向维度,也适用于两个相机模型相关的方向维度,以及(ii)先进的调节策略。UniK3D在不需要相机校准或领域特定调整的情况下,优于传统模型。
这是第一个可广泛适用于各种相机模型的单目测量3D场景几何估计框架,从镜头到鱼眼和全景配置,如图所示,论文提出了一种新的单目3D估计的公式,它在两个方面都是球形的。首先,UniK3D利用完全球形的3D空间输出,通过径向距离而不是垂直深度来建模范围维度。这种方法在远离光轴的大角度下特别有益,有效地解决了传统方法在极端视角下的ill-posed性质。其次,虽然基于最近提出的相机预测分解,UniK3D新提出了直接作为相机模块的直接输出空间的一般球谐函数基。预测显式的镜头相机参数,然后使用球基编码诱导的光线,移除了相机假设并直接建模光线。因此,UniK3D跨越了可能相机模型的无限空间,允许灵活且准确的深度预测,无论相机内参如何。无假设球形相机表示,凭借其灵活性,确保模型非常适合于实际部署,在那里捕捉非标准相机场景的情况很常见。
单目深度估计。通过首次展示的端到端神经网络用于单目深度估计(MDE),彻底改变了该领域,通过直接优化,利用尺度不变的对数损失(SIlog)实现深度预测。此后,该领域不断发展,模型越来越复杂,从卷积架构到最近使用ViT的进展。尽管这些方法在受控基准测试中推动了MDE性能的边界,但在面对零样本场景时,它们往往会失败,突显了一个持续的挑战:确保在不同相机和场景领域以及各种几何和视觉条件下的稳健泛化。 通用单目深度估计。为了解决领域特定模型的局限性,近期研究集中在开发通用和零样本MDE技术上。这些方法可以分为尺度无关方法32,63,73,81,82,旨在缓解尺度模糊并强调感知深度质量,以及度量深度模型7,9,24,28,60,61,85,优先考虑准确的几何重建。然而,大多数现有的MDE方法未能实现真正的零样本单目度量3D场景估计。特别是,尺度无关方法通常需要额外信息来解决尺度模糊,而大多数基于度量的模型则依赖已知相机或假设简单的针孔相机配置。即使是为零样本3D场景估计设计的少数几个模型9,60,85也受到限制:它们要么明确假设针孔相机模型,要么需要图像校正,实际上需要测试时的相机信息,从而限制了其零样本泛化能力,只适用于针孔相机。 相反,UniK3D通过提供一个可以处理任何逆投影问题的统一解决方案来解决这些局限性。模型可以从任何单张图像中恢复一个连贯的3D点云,不受相机内参的影响,无需任何校正或测试时的相机信息。这种普遍性使UniK3D脱颖而出。
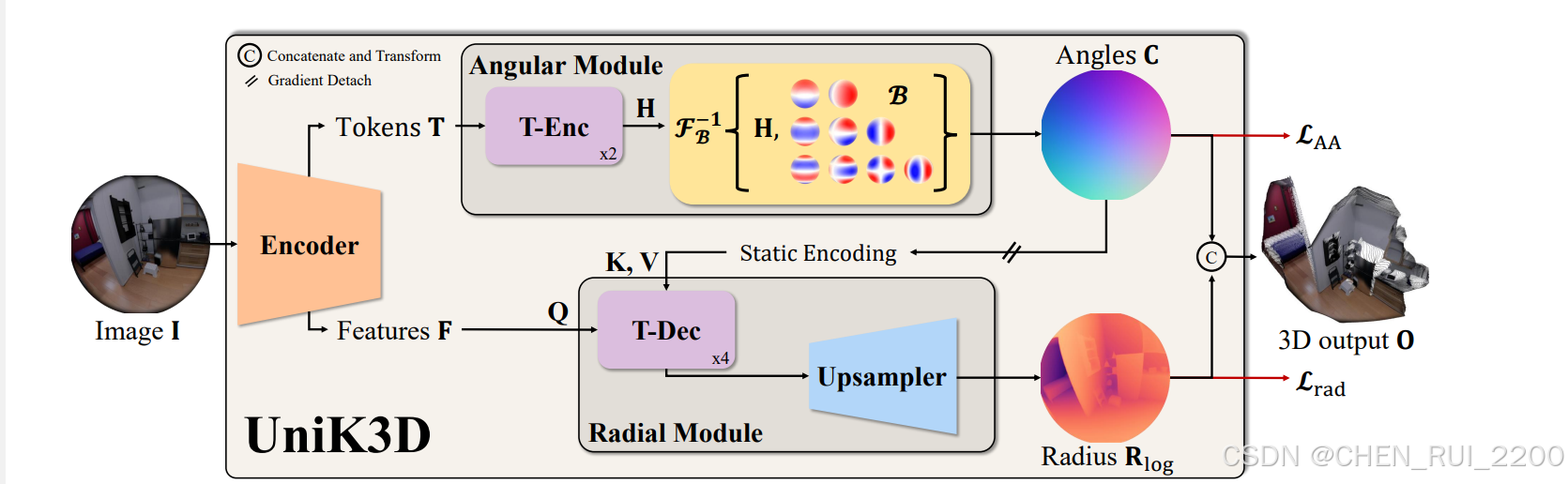
模型架构。UniK3D仅利用单一输入图像生成任意相机的3D输出点云(O)。相机的投影几何由角度模块预测。相机表示对应于单位球S3上的背投射光锥的方位角和极角(C)。编码器的类标记通过2个ViT编码器(T-Enc)层处理,以获得逆球面变换F−1B{H}的15个系数(H),该变换由球谐函数的有限基(B)定义,球谐函数的最高次为3,没有常数分量。对角度信息应用停梯度,以调节径向模块,模拟外部信息流。"静态编码"指与内部特征维度匹配的正弦编码。径向模块由每个输入分辨率的一个ViT解码器(T-Dec)块组成,用于将编码器特征条件于启动相机表示。这种调节注入了场景尺度和投影几何的先验知识。径向输出(Rlog)通过学习的上采样模块处理相机感知特征获得。最终输出是相机和径向张量的连接(C||Rlog)。应用闭合式坐标变换以获得笛卡尔3D输出,但直接对角度坐标和径向坐标进行监督,使用非对称角度损失LAA。
可泛化的深度或3D场景估计模型在适应不同相机配置时常常面临重大挑战。现有方法通常依赖于刚性和相机特定的假设,如镜头模型或等面球模型,或需要大量的预处理步骤如校正。这些限制使其在现实世界中应用于具有非标准相机投影几何的场景时受到限制。相比之下,模型UniK3D引入了一个全新的框架,可以实现任何场景和任何相机设置的单目3D几何估计。

首先在第3.1节中介绍了我们的3D输出空间设计和相机的内部表示。我们的表示是有意设计得尽可能通用,以处理所有逆投影问题。通过我们的初步研究,我们观察到一个一致的问题:即使在训练于包括大视场的多种相机类型的数据集上,网络预测也会收缩到一个较小的视场。简单的数据重新平衡策略证明无法解决这一现象。为了克服这一问题,我们在第3.2节中开发了一系列旨在防止反投影收缩的架构和设计干预措施。在第3.3节中,我们描述了我们的模型架构、优化策略以及我们的方法背后的具体设计和损失函数。图2展示了我们方法的概述。
数学表述
输出空间。UniK3D的输出表示旨在与任何场景和相机配置通用兼容,为每个输入图像提供直接的度量3D场景估计。借鉴了60中提出的分离策略,我们的方法将相机参数与场景几何分离。具体来说,我们使用密集张量C=θ||ϕ来表示相机,其中θ极角,ϕ是方位角,与标准的球坐标系一致。然而,我们在完全球形框架内使用欧几里得半径(相机中心到场景的距离)作为场景范围组件,而不是依赖于传统的垂直深度基表示法。这种设计选择确保了图像中投影物体的尺寸随着半径单调变化,这一属性并不特征深度表示,使得后者更难学习。此外,球形框架在处理靠近xy平面的点时增强了数值稳定性,这是前面的方法通常在大梯度区域面临挑战的地方。我们使用一个双射变换将球坐标表示转换为笛卡尔坐标,准确捕捉场景的3D几何作为输出的3D点云O。相机内部空间。在UniK3D中,表示各个像素的观察方向的密集光束通过基分解来表达,提供了一个灵活且全面的角度表示。如图2所示,我们的角度模块预测一个系数张量H,它是由编码器的类标记T衍生的。这些系数对应于一个预定义基:球谐函数(SH)基。使用以下公式下重构光束:
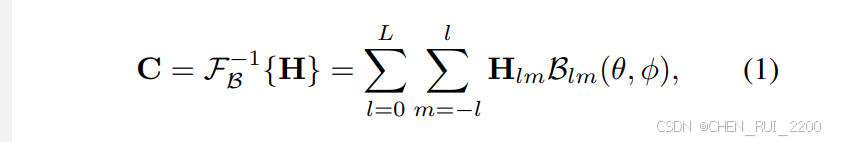
其中C代表重构的角度场,F−1B表示从系数空间到角度空间的逆变换,使用SH基B。Blm(θ, ϕ)是SH基函数,即Legendre多项式,Hl是预测的系数。这里,l和m分别指谐波的度和阶。这个逆变换被实现为一个内积,从Rn×S3映射到S3。SH基域由4个参数定义:参考框架的"主要点",即极点,以及水平和垂直的视场。这种表达方式能够紧凑且隐式地描述复杂的光线分布,同时确保输出的重要属性,如连续性和可微性。此外,SH基还提供高稀疏性,对于没有常数分量的3次基,只需要15个谐波,并且相同数量的系数就可以准确地代表大多数相机类型的内在特性。通过利用这种基于SH的表示并通过极点和视场参数定义域,UniK3D实现了一个强大且灵活的框架,只需19个参数就能处理几乎任何相机几何。
防止分销收缩
非对称角损失。神经网络往往会回归到训练数据中最常见的模式,通常忽视分布尾部。在我们的案例中,这种偏差会导致UniK3D在其输出中低估宽视场角度,因为大多数视觉数据集都倾向于小视场镜头相机。这会导致在需要准确的宽角预测的场景中表现不佳。为了克服这个问题,我们引入了基于分位数回归的非对称角度损失,灵感来自于鲁棒统计估计和决策理论原理,即一类和二类错误51。损失函数定义如下:
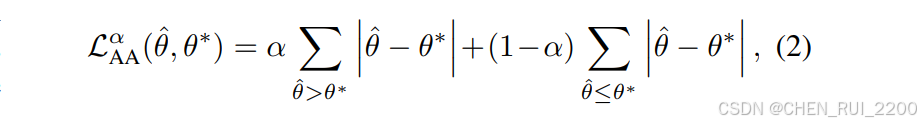
其中0≤α≤1是目标分位数,ˆθ是预测角度,θ∗是真实角度。这种公式调整了极角θ的过估计和低估计的加权。当α= 0.5时,损失函数退化为标准的平均绝对误差(MAE),但通过调整α,我们可以强调代表性不足的角度并更有效地平衡回归。与简单的数据集重新平衡不同------这会改变底层的3D场景多样性并引入显著的复杂性,特别是在多个数据集之间------我们的损失函数直接有效地解决了角度不平衡问题。通过使用量分位回归,我们将复杂性最小化到简单的α在0,1区间的搜索,使我们的方法非常适合于大规模和多样化的训练场景。这种基于量分位的策略使我们能够解决角度分布偏差问题,而不牺牲简单性和多样性,使其成为一种稳健且可扩展的解决方案。增强相机调节。在我们的初步实验中,我们观察到我们的模型在有效利用相机调节方面存在困难,尽管在之前的工作60中,我们在训练和测试期间都明确提供了真实相机光线。这个问题对于小视场(FoV)镜头相机来说是微妙的,但对于大视场配置来说却变得显著。问题的根源在于调节不足:模型未能将相机参数与几何特征分离,导致它将局部畸变反馈到编码器特征空间,而不是整合必要的视场信息。因此,即使在测试时提供了准确的相机参数,模型可能会忽略或被误导这些信息。为了解决这个问题,我们假设相机数据必须从训练开始就清晰且明确结构化。为此,我们在UniK3D中实现了相机光线的静态(非可学习)编码,并采用了逐步学习策略,逐渐从输入真实相机参数到预测的相机参数给径向模块。具体来说,真实相机以1−tanh(s105)的概率输入到径向模块,其中s是当前优化步骤。为了强化外部调节,我们将径向模块输入的相机输出的梯度分离,从而防止模型依赖可能破坏调节的反馈机制。此外,我们在径向模块的ViT解码器的交叉注意力层中禁用可学习的增益,如LayerScale 68,以避免条件的捷径。这些策略确保模型有效地利用相机信息来调整其编码器特征,提高3D预测的稳健性。

定性比较。每对连续行代表一个测试样本。每一行奇数行显示输入的RGB图像和2D误差图,根据绝对相对误差使用coolwarm颜色映射(对于全景图像,误差是基于距离而不是深度计算的)。为了确保公平比较,所有模型的误差都是基于GT基准的移位和缩放输出计算的。每一行偶数行显示3D点云的真实值和预测值。最后一列显示绝对相对误差的具体颜色映射范围。每对行的关键观察:(1)竞争方法仅限于正深度,并且在较大的视场(FoV)中严重扭曲场景;(2)在可表示但较大的视场(180°)的情况下,UniK3D输出是唯一一个不会出现明显视场收缩的;(3)对于中等视场但有强边界扭曲的图像,例如鱼眼,UniK3D可以保持平面性和整体场景结构;(4)我们的方法也能为标准镜头图像提供准确的3D估计。
模型设计
网络由编码器主干、角度模块和径向模块组成,如图2所示。我们的编码器是基于ViT的15,我们提取密集特征F∈Rh×w×C×4------其中(h, w) = (H14,W14) ------以及类标记T。角度模块处理这些类标记,将它们投影到512通道的表示上,这些表示被分成3个域参数和15
球面系数原型。这些标记通过一个具有8个头的ViT编码器(T-Enc)的两层,然后投影到标量值。3个域参数的值定义了主点(2)和水平视场(1),确定谐波的间隔。我们假设正方形像素,因此不学习额外的第四个参数来确定垂直视场,而是直接从水平视场计算这个第四个参数。15个球面系数根据(1)进行反向SH变换,使用3度的SH基。从角度模块到类标记的梯度乘以0.1,因为经验发现相机引起的梯度大小约为编码器权重的径向引起的梯度的10倍。
UniK3D代码
class UniK3D(
nn.Module,
PyTorchModelHubMixin,
library_name="UniK3D",
):
def __init__(
self,
config,
eps: float = 1e-6,
**kwargs,
):
super().__init__()
self.eps = eps
self.build(config)
self.build_losses(config)
def forward_train(self, inputs, image_metas):
losses = {"opt": {}, "stat": {}}
B, T = inputs["image"].shape[:2]
image_metas[0]["B"], image_metas[0]["T"] = B, T
inputs = self.pack_sequence(inputs) # move from B, T, ... -> B*T, ...
inputs, outputs = self.encode_decode(inputs, image_metas)
validity_mask = inputs["validity_mask"]
# be careful on possible NaNs in reconstruced 3D (unprojection out-of-bound)
pts_gt = inputs["camera"].reconstruct(inputs["depth"]) * validity_mask.float()
pts_gt = torch.where(pts_gt.isnan().any(dim=1, keepdim=True), 0.0, pts_gt)
mask_pts_gt_nan = ~pts_gt.isnan().any(dim=1, keepdim=True)
mask = (
inputs["depth_mask"].bool() & validity_mask.bool() & mask_pts_gt_nan.bool()
)
# compute loss!
inputs["distance"] = torch.norm(pts_gt, dim=1, keepdim=True)
inputs["points"] = pts_gt
inputs["depth_mask"] = mask
losses = self.compute_losses(outputs, inputs, image_metas)
outputs = self.unpack_sequence(outputs, B, T)
return (
outputs,
losses,
)-
UniK3D 是一个继承自 nn.Module 和 PyTorchModelHubMixin 的类,表明它是一个 PyTorch 模型,并且可以通过 PyTorch Hub 加载。它由 xAI 或相关团队开发,托管在 GitHub 上(https://github.com/lpiccinelli-eth/UniK3D),主要用于从单张 RGB 图像中估计 3D 点云、深度和其他几何信息。
-
主要功能 :
- 输入:RGB 图像和可选的相机参数(如内参、外参)。
- 输出:3D 点云(points)、深度(depth)、置信度(confidence)等。
- 应用场景:单目 3D 重建、场景理解等。
-
核心组件 :
- Pixel Encoder:从图像中提取特征。
- Pixel Decoder:将特征解码为 3D 几何信息。
- 损失函数:用于训练时优化模型。
-
输入处理 :
- pack_sequence:将输入从 (B, T, ...) 重塑为 (B*T, ...),便于批量处理。
- encode_decode:核心编码-解码过程,生成特征和 3D 输出。
-
3D 重建与掩码 :
- 使用相机参数和深度图重建 3D 点云(pts_gt)。
- 处理 NaN 值并生成有效性掩码(validity_mask)和深度掩码(depth_mask)。
损失计算:调用 compute_losses 计算深度、相机和置信度相关的损失。
编码-解码过程 (encode_decode)
def encode_decode(self, inputs, image_metas=[]):
features, tokens = self.pixel_encoder(inputs["image"])
inputs["features"] = [self.stacking_fn(features[i:j]) for i, j in self.slices_encoder_range]
outputs = self.pixel_decoder(inputs, image_metas)
pts_3d = outputs["rays"] * outputs["distance"]
outputs.update({"points": pts_3d, "depth": pts_3d[:, -1:]})
return inputs, outputs- 编码 :
- pixel_encoder:从图像提取多尺度特征(features)和标记(tokens)。
- stacking_fn:对特征进行堆叠处理。
- 解码 :
- pixel_decoder:将特征解码为光线(rays)、距离(distance)等。
- 计算 3D 点云(points = rays * distance)和深度(Z 坐标)。
模型构建 (build)
def build(self, config):
pixel_encoder = pixel_encoder_factory(pixel_encoder_config)
pixel_decoder = Decoder(config)
self.pixel_encoder = pixel_encoder
self.pixel_decoder = pixel_decoder- 从配置文件动态加载并构建编码器和解码器。
- 设置特征切片范围(slices_encoder_range)和形状约束(shape_constraints)。
计算损失
def compute_losses(self, outputs, inputs, image_metas):
B, _, H, W = inputs["image"].shape
losses = {"opt": {}, "stat": {}}
losses_to_be_computed = list(self.losses.keys())
# depth loss
si = torch.tensor(
[x.get("si", False) for x in image_metas], device=self.device
).reshape(B)
loss = self.losses["depth"]
depth_losses = loss(
outputs["distance"],
target=inputs["distance"],
mask=inputs["depth_mask"].clone(),
si=si,
)
losses["opt"][loss.name] = loss.weight * depth_losses.mean()
losses_to_be_computed.remove("depth")
loss = self.losses["camera"]
camera_losses = loss(
outputs["rays"], target=inputs["rays"], mask=inputs["validity_mask"].bool()
)
losses["opt"][loss.name] = loss.weight * camera_losses.mean()
losses_to_be_computed.remove("camera")
# remaining losses, we expect no more losses to be computed
loss = self.losses["confidence"]
conf_losses = loss(
outputs["confidence"],
target_gt=inputs["distance"],
target_pred=outputs["distance"],
mask=inputs["depth_mask"].clone(),
)
losses["opt"][loss.name + "_conf"] = loss.weight * conf_losses.mean()
losses_to_be_computed.remove("confidence")
assert (
not losses_to_be_computed
), f"Losses {losses_to_be_computed} not computed, revise `compute_loss` method"
return losses它计算了三种不同的损失:深度损失(depth loss)、相机损失(camera loss)和置信度损失(confidence loss)
B, _, H, W = inputs["image"].shape
losses = {"opt": {}, "stat": {}}
losses_to_be_computed = list(self.losses.keys())-
outputs:模型预测的结果(包括 distance、rays、confidence 等)。
-
inputs:输入数据(包括 ground truth,如 distance、rays、depth_mask 等)。
-
image_metas:图像的元数据,可能包含附加信息(如 si)。
si = torch.tensor(
[x.get("si", False) for x in image_metas], device=self.device
).reshape(B)
loss = self.losses["depth"]
depth_losses = loss(
outputs["distance"],
target=inputs["distance"],
mask=inputs["depth_mask"].clone(),
si=si,
)
losses["opt"][loss.name] = loss.weight * depth_losses.mean()
losses_to_be_computed.remove("depth") -
衡量模型预测的距离(outputs"distance")与真实距离(inputs"distance")之间的差异。
-
参数 :
- outputs"distance":模型预测的每个像素到相机中心的距离。
- target=inputs"distance":真实的距离(ground truth)。
- mask=inputs"depth_mask":一个布尔掩码,表示哪些像素的有效深度数据可用,避免无效区域影响损失。
- si:从 image_metas 中提取的一个参数(可能是尺度因子 scale-invariant 的标志),用于调整损失计算。
-
计算过程 :
- loss 是预定义的深度损失函数(从 self.losses"depth" 获取,可能是一个自定义类,如 L1 损失或尺度不变损失)。
- depth_losses 是逐像素的损失值。
- 最终损失是所有有效像素损失的平均值,乘以权重 loss.weight。
相机损失 (Camera Loss)
loss = self.losses["camera"]
camera_losses = loss(
outputs["rays"], target=inputs["rays"], mask=inputs["validity_mask"].bool()
)
losses["opt"][loss.name] = loss.weight * camera_losses.mean()
losses_to_be_computed.remove("camera")- 衡量模型预测的光线方向(outputs"rays")与真实光线方向(inputs"rays")之间的差异。
- 参数 :
- outputs"rays":模型预测的每个像素的光线方向向量(通常是单位向量)。
- target=inputs"rays":真实的相机光线方向(由相机参数生成)。
- mask=inputs"validity_mask":一个布尔掩码,表示哪些像素的光线数据是有效的。
- 计算过程 :
- loss 是预定义的相机损失函数(从 self.losses"camera" 获取,可能基于余弦相似度或角度差)。
- camera_losses 是逐像素的光线方向误差。
- 最终损失是所有有效像素损失的平均值,乘以权重 loss.weight。
置信度损失 (Confidence Loss)
loss = self.losses["confidence"]
conf_losses = loss(
outputs["confidence"],
target_gt=inputs["distance"],
target_pred=outputs["distance"],
mask=inputs["depth_mask"].clone(),
)
losses["opt"][loss.name + "_conf"] = loss.weight * conf_losses.mean()
losses_to_be_computed.remove("confidence")- 优化模型输出的置信度(outputs"confidence"),使其反映预测距离的可靠性。
- 参数 :
- outputs"confidence":模型预测的每个像素的置信度分数(通常在 0, 1 之间)。
- target_gt=inputs"distance":真实距离,作为置信度的参考。
- target_pred=outputs"distance":预测距离,用于比较真实值和预测值的误差。
- mask=inputs"depth_mask":布尔掩码,限定有效区域。
- 计算过程 :
- loss 是预定义的置信度损失函数(从 self.losses"confidence" 获取)。
- 置信度损失通常鼓励高置信度对应低误差,低置信度对应高误差,可能基于交叉熵或自定义公式。
- conf_losses 是逐像素的置信度损失值。
- 最终损失是平均值,乘以权重 loss.weight。
损失函数的作用
- 深度损失 :
- 确保模型预测的距离与真实距离一致,是 3D 重建的核心目标。
- 使用掩码避免无效区域干扰。
- 相机损失 :
- 保证光线方向的准确性,这对从深度生成 3D 点云至关重要(points = rays * distance)。
- 依赖相机参数的正确性。
- 置信度损失 :
- 使模型能够自我评估预测的可靠性,高置信度对应准确预测,低置信度对应不确定区域。
- 提高模型的鲁棒性和可解释性。
实现细节。UniK3D 在 Py-Torch 57 和 CUDA 52 中实现。在训练过程中,我们使用 AdamW 优化器(β1= 0.9,β2= 0.999),初始学习率为 5×10−5。对于每个实验的骨干网络权重,学习率会被除以10,权重衰减设置为0.1。我们利用余弦退火作为学习率调度器,从整个训练的30%开始,每隔十分之一。我们运行 250k 优化迭代,批量大小为 128。在 16 台 NVIDIA 4090 上,训练时间为 6 天。数据采样过程遵循加权采样器,其中每个数据集的权重为其场景数量。我们对每批次的图像比例随机采样,范围在 2:1 到 9:16 之间。我们的 ViT 15 骨干网络使用 DINO 预训练 53 模型的权重初始化。对于消融实验,我们使用 ViT-S 骨干网络,训练步骤为 100k。
推理方法 (infer)
def infer(self, rgb: torch.Tensor, camera=None, rays=None, normalize=True):
inputs = {"image": rgb}
if camera is not None:
inputs["camera"] = camera
_, model_outputs = self.encode_decode(inputs, image_metas={})
out = {
"points": _postprocess(model_outputs["points"], ...),
"depth": points[:, -1:],
"confidence": _postprocess(model_outputs["confidence"], ...),
}
return out- 输入预处理 :
- 对 RGB 图像进行填充(padding)、调整大小(resize)和标准化(normalize)。
- 处理相机参数和光线(rays)。
- 推理 :
- 通过 encode_decode 得到输出。
- 后处理(_postprocess)调整输出分辨率并返回结果。
和现有技术比较
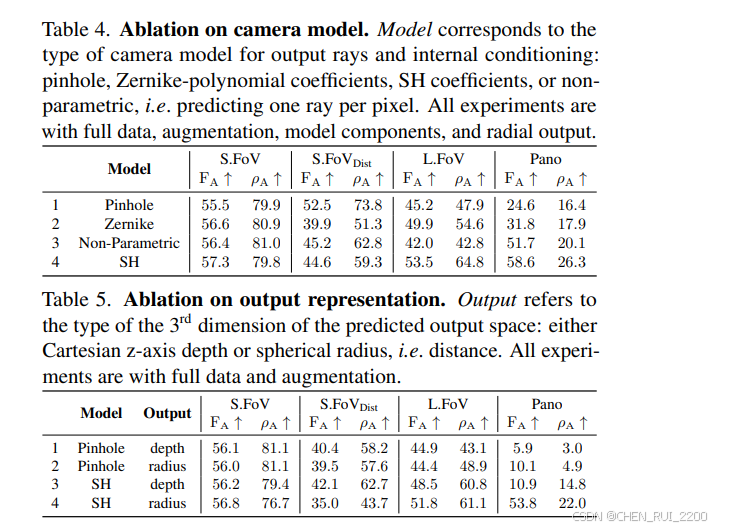
表上比较了UniK3D与现有的最先进方法在不同的视场(FoV)和图像类型上的表现。我们的模型在各个方面都表现优于先前的模型,尤其是在具有挑战性的大视场和全景场景中。例如,在L.FoV领域,UniK3D达到了一个显著的δ1SSI为91.2%和FA为71.6%,分别优于第二名方法超过20%和40%。这一巨大的提升凸显了我们统一球面框架在处理宽视场时的稳健性。在Pano类别中,我们模型的δ1SSI和FA分数为71.2%和66.1%,也树立了新的最先进水平,展示了它在极端摄像机设置下有效重建3D几何的能力。这些结果验证了我们的设计选择,包括基于球谐函数(SH)的摄像机模型和径向输出表示,对于在复杂和多样化的摄像机设置中保持高性能至关重要。
主要观点
- UniK3D是第一个可以对任何相机类型(从针孔到全景)进行单目3D估计的通用方法
- 它使用完全球面输出表示来更好地分离相机和场景几何
- UniK3D引入了一种新颖的、与模型无关的相机射线束球谐表示
- 这允许在测试时无需任何相机信息即可进行准确的度量3D重建
- UniK3D在具有挑战性的广角和全景设置中的表现优于传统模型,同时在常规针孔相机中保持最高精度
本地安装Unik3d依赖,跑一下gradio demo
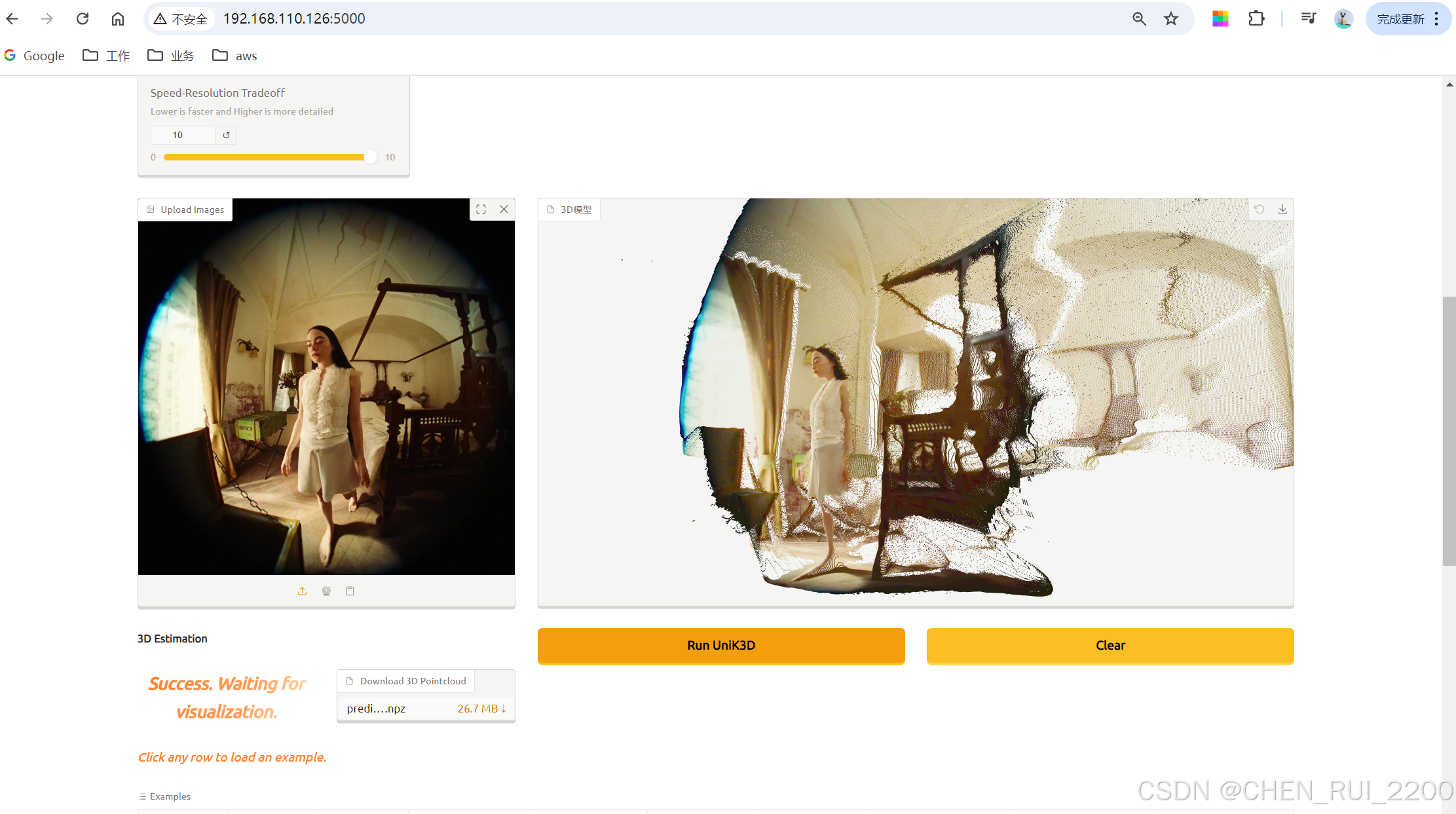
3d重建速度非常快只用了7秒
也可以在hugging-face上demo测试下

单目3D重建是很有用的技术, 后续尝试在Unik3d上做点应用