简介
- 什么是进程同步
指多个进程之间在执行顺序上的协调,以确保它们按照特定的顺序和时间间隔进行操作,从而使系统能够正确、有序地运行。
操作系统的并发性带来了异步性,有时候进程之间需要互相配合完成工作,它们之间需要遵循一定的先后顺序。而异步性则会让先后顺序失效,所以需要进程同步来解决异步的问题。
进程的异步性是指:并发执行的进程以不可预知的速度向前推进。
-
什么是进程互斥
指多个进程在同一时刻只能有一个进程访问某个共享临界资源,以防止资源被破坏或数据不一致。
-
两者的统一
同步与互斥是互相关联的,
互斥是实现同步的一种手段,通过确保共享资源的互斥性,来保证进程之间的操作顺序一致性。同步是互斥的目的,通过协调进程的执行顺序,使得系统按照预期方式运行,避免出现错误。
进程互斥
为实现对临界资源的互斥访问,同时又保证系统整体性能。需要遵循以下四个原则
- 空闲让进
当临界区空闲时,可以允许一个请求进入的进程立刻进入临界区 - 忙则等待
当已经有进程进入临界区时,其它进程试图进入则需要等待 - 有限等待
对于在等待的进程,应该保证在有限的时间内进入临界区。 - 让权等待
当进程不能进入临界区时,应该立刻释放CPU时间,防止浪费CPU资源。
系统临界区
先来解释什么是临界资源?
一个时间段内只允许一个进程使用的资源,叫做临界资源。
什么是临界区?
访问临界资源的那段代码
对临界资源的互斥访问,可以在逻辑上分为如下四个部分:
do{
entry section; //进入区
critical section; //临界区,是进程中访问临界资源的代码段
exit section; //退出区,与进入区一起组成了实现互斥的代码段
remainder section; //剩余区
}while(true)软件实现进程互斥的方式
单标志检查法
int turn=0;//标识当前允许进入临界区的进程号
//P0进程
while(turn!=0){ //在进入区只检查,不上锁
critcal section //临界区
turn=1 //在退出区讲临界区的使用权转让给另一个进程
remainder section; //剩余区
}
//P1进程
while(turn!=1) //在进入区只检查,不上锁
critcal section //临界区
turn=0 //在退出区讲临界区的使用权转让给另一个进程
remainder section; //剩余区通过此逻辑,虽然实现了P0=>P1=>P0=>P1的互斥访问,但违背了空闲让进的原则。
原因:假如P0进入了临界区,但实际上压根不想访问。那么虽然此时临界区空闲,但P1依旧不允许访问,需要等待P0退出临界区。
双标志先检查法
//设置一个数组,数组中的元素来标记进程想进入临界区的意愿,比如flag[0]=ture,说明0号进程想进入临界区
bool flag[2];
flag[0]=false;
flag[1]=false;
//P0进程
while(flag[1]); //在进入区,检查有没有其它进程想进入
flag[0]=true; //标记P0想使用临界区
critcal section //临界区
flag[0]=false; //标记P0不想使用临界区
remainder section; //剩余区
//P1进程
while(flae[0]); //在进入区,检查有没有其它进程想进入
flag[1]=true; //标记P1想使用临界区
critcal section //临界区
flag[1]=false; //标记P1不想使用临界区
remainder section; //剩余区通过在每个进程进入临界区之前先检查,有没有其它进程想进入,如果没有就把自身标记为想访问。实现了空闲让进原则。
但在并发的情况下,P0和P1会同时访问临界区,违反了忙则等待原则
双标志后检查法
bool flag[2];
flag[0]=false;
flag[1]=false;
//P0进程
flag[0]=true; //标记P0想使用临界区
while(flag[1]); //在进入区,检查有没有其它进程想进入
critcal section //临界区
flag[0]=false //标记P0不想使用临界区
remainder section; //剩余区
//P1进程
flag[1]=true; //标记P1想使用临界区
while(flag[0]); //在进入区,检查有没有其它进程想进入
critcal section //临界区
flag[1]=false //标记P1不想使用临界区
remainder section; //剩余区双标志先检查法的问题在于,先检查,后上锁。但这两个操作又无法原子操作。因此导致了并发情况下的同时访问临界区问题。
因此, 双标志后检查法先上锁,后检查。来规避忙则等待问题。
因为先上锁的操作,在并发情况下又会造成死锁。所以又违背了空闲让进和有限等待原则,各个进程长期无法访问临界资源而产生饥饿现象。
Peterson算法
bool flag[2];
int turn=0;
//P0进程
flag[0]=true; //标记P0想使用临界区
turn=1; //可以"谦让"对方先进入临界区
while(flag[1]&&turn==1); //进入区,自己主动争取,但也同意对方先使用
critcal section; //临界区
flag[0]=true; //标记P0不想使用临界区
remainder section; //剩余区
//P1进程
flag[1]=true; //标记P1想使用临界区
turn=0; //可以"谦让"对方先进入临界区
while(flag[0]&&turn==0); //进入区,自己主动争取,但也同意对方先使用
critcal section; //临界区
flag[1]=true; //标记P1不想使用临界区
remainder section; //剩余区Peterson算法结合了双标志后检查法与单标志检查法。在并发情况下,进程尝试孔融让梨,来实现空闲让进,忙则等待,有限等待原则。但未实现让权等待。
硬件实现进程互斥的方式
中断屏蔽方式
关闭中断
entry section; //进入区
critical section; //临界区
exit section; //退出区
打开中断
remainder section; //剩余区与原语的实现相同,通过开/关中断指令,使得进程开始访问临界区时,不允许中断。
因为不允许中断,所以也不可能发生进程切换。因此也不可能发生两个进程同时访问的情况。
优点:简单,高效
缺点: 只适合单核处理器
TestAndSet指令
//lock代表当前临界区是否加锁
//true表示加锁,false表示为加锁
bool TestAndSet(bool *lock){
bool old;
old=*lock; //存放lock的旧值
*lock=true; //设置加锁
return old; //返回旧值
}
//P0进程
while(TestAndSet(&lock)); //进入区,检查的同时并上锁,实现原子操作。
critical section; //临界区
lock=false; //退出区, 解锁当前资源。
remainder section; //剩余区
//P1进程
while(TestAndSet(&lock)); //进入区,检查的同时并上锁,实现原子操作。
critical section; //临界区
lock=false; //退出区, 解锁当前资源。
remainder section; //剩余区该指令也称为TSL指令,它是一条原子指令。其基本思想是通过一个布尔型变量来表示临界资源的状态,如true表示资源正在被占用,false表示资源可用。
相比软件实现的方法,TSL指令把上锁与检查用硬件的方式变成了原子操作。
优点:实现简单,适用于多核环境
缺点:依旧不满足让权等待,因为暂时无法进入的进程会循环执行TSL指令,从而浪费CPU资源。
Swap指令
Swap(bool *a,bool *b){
return (*a,*b)=(*b,*a);
}
//P0进程
bool lock=?; //lock表示当前临界区是否被加锁
bool old=true;
while(old==true) //进入区
Swap(&lock,&old)
critical section; //临界区
lock=false; //退出区, 解锁当前资源。
remainder section; //剩余区该指令也称为Exchange指令,非常常用的一个交换指令,同样使用硬件实现,具备原子性。
它与TSL指令在思路上没有区别,所以优点跟缺点都是一模一样。
以下是几种进程互斥算法的优缺点对比,以Markdown表格形式呈现:
互斥算法优缺点对比
| 算法名称 | 优点 | 缺点 |
|---|---|---|
| 单标志检查法 | 1. 实现简单,仅需一个共享标志变量turn; 2. 严格保证互斥,强制轮流访问临界区。 |
1. 强制轮流访问,可能导致资源利用率低(如进程0退出后,进程1需等待turn切换才能进入); 2. 不满足"空闲让进"原则,可能造成饥饿。 |
| 双标志前检查法 | 1. 允许进程主动声明进入临界区的意愿(设置自身标志); 2. 无需强制轮流,更灵活。 | 1. 检查与设置标志非原子操作,可能因并发执行导致两个进程同时进入临界区(不满足互斥条件); 2. 存在竞态条件,可靠性差。 |
| 双标志后检查法 | 1. 先声明进入意愿(设置自身标志),再检查对方标志,逻辑更合理。 | 1. 可能导致死锁:若两个进程同时设置自身标志为true,再检查对方标志时均发现对方想进入,从而互相等待; 2. 不满足"无死锁"条件。 |
| Peterson算法 | 1. 解决双标志法的死锁问题,同时保证互斥; 2. 实现公平性(通过turn变量); 3. 无忙等待以外的额外开销。 |
1. 仅适用于双进程场景 ,无法扩展到多进程; 2. 仍需忙等待(循环检测对方标志和turn),消耗CPU资源。 |
| 中断屏蔽方式 | 1. 实现简单,通过关闭/打开中断确保临界区原子执行; 2. 适用于单核处理器,完全避免进程切换。 | 1. 仅在内核态 有效,用户态无法使用; 2. 多核处理器中失效(仅关闭当前CPU中断,其他CPU仍可运行进程); 3. 长时间关闭中断会严重影响系统响应速度,风险高。 |
| TestAndSet(TSL)指令 | 1. 基于硬件原子指令实现,保证操作原子性; 2. 适用于多进程/多线程,支持忙等待; 3. 无死锁问题。 | 1. 忙等待(循环检测)导致CPU资源浪费; 2. 可能导致低优先级进程饥饿(高优先级进程频繁抢占CPU,低优先级无法获取标志)。 |
| Swap(Exchange)指令 | 1. 与TSL类似,利用硬件原子交换操作实现互斥; 2. 跨平台兼容性较好(不同架构可能有类似指令)。 | 1. 同样依赖忙等待,CPU利用率低; 2. 未解决饥饿问题,且实现复杂度略高于TSL(需临时变量)。 |
-
软件算法:
- 优点:无需硬件支持,适用于简单场景(如双进程)。
- 缺点:可靠性低(双标志法可能互斥失效或死锁)、扩展性差(Peterson仅双进程)、忙等待或效率问题。
-
硬件指令:
- 优点:原子操作保证互斥,适用于多处理机。
- 缺点:忙等待导致CPU浪费,可能饥饿,依赖硬件支持。
-
中断屏蔽:
- 仅适用于单核内核态,现代多核系统中实用性极低,仅作为理论方案。
究极进化,信号量
在上面介绍的几种实现互斥的方案中,都无法达到完美,都存在两种问题。
- 双标志检查法,进入区的"检查"和"上锁"无法保证原子性。
- 所有的解决方案都无法实现"让权等待"。
因此,要想实现一个比较完美的互斥算法,就要从这两点开始入手。第一点可以由硬件指令帮你实现原语,我们专注点就在于第二点,如何实现"让权等待"?信号量就此应运而生。
信号量的本质就是一个变量,来表示系统中某种资源的数量。比如系统中有1台打印机,那信号量初始值就是1,如果有3台,那初始值就是3.
通过原子操作(P操作和V操作,分别对应 "等待" 和 "释放")实现对共享资源的互斥访问,
1965年,由荷兰学者Dijkstra提出,因此P/V操作来自于荷兰语proberen/verhogen。
struct Semaphore{
int value; //剩余资源数
struct process *L; //等待队列
}
void wait(Semaphore s){
s.value--;
if(s.value<0){
block(S.L); //如果剩余资源不够,使用block原语将进程变为阻塞态
}
}
void signal(Semaphore s){
s.value++;
if(s.value<=0){
wakeup(S.L); //资源释放后,唤醒某个阻塞进程。
}
}
// 进程P0
wait(S);//进入区
critical section; //临界区
signal(S); //退出区
remainder section; //剩余区信号量实现进程互斥
从信号量的原理中可以看到,信号量就是记录了资源的剩余数量。
P:申请一个资源,如果资源不够就阻塞等待。
V:释放一个资源,如果有进程等待就唤醒。
由于互斥操作,只需要将信号量初始化为1。因此操作系统对信号量稍微封装,变成了mutex,其本质还是semaphore。
semahpore mutex=1; //初始化信号量
P0(){
P(mutex); //进入区
critical section; //临界区
V(mutex); // 退出区
remainder section; //剩余区
}
P1(){
P(mutex); //进入区
critical section; //临界区
V(mutex); // 退出区
remainder section; //剩余区
}为方便理解,加入一个C#版本。
public class huchi
{
private Mutex mutex = new Mutex(false);//相当于初始化为1,临界资源没有被持有。
public void Run()
{
var t1 = new Thread(Work);
var t2 = new Thread(Work);
t1.Start();
t2.Start();
t1.Join();
t2.Join();
Console.WriteLine("所有线程执行完毕");
}
private void Work()
{
//进入区
mutex.WaitOne();
Console.WriteLine($"{Thread.CurrentThread.ManagedThreadId}进入区");
try
{
//临界区
Thread.Sleep(2000);
}
finally
{
//退出区
mutex.ReleaseMutex();
}
//剩余区
Console.WriteLine($"{Thread.CurrentThread.ManagedThreadId}执行完毕,退出");
}
}实现进程互斥,主要有四步:
- 确定临界区
- 设置互斥信号量,初始值为1
- 在临界区之前对信号量执行P操作
- 在临界区之后对信号量执行V操作
进程同步
文章开头说到,操作系统的并发性带来了异步性。因此,当你想以顺序执行代码时,因为进程切换的缘故,很有可能导致执行顺序从1=>2=>3=>4=>5=>6=>7=>8=>9=>10变成1=>4=>5=>2=>3=>6......
P0进程(){
代码1;
代码2;
代码3;
}
//因为进程切换,执行顺序不固定
P1进程(){
代码4;
代码5;
代码6;
}而文章开头又说到,互斥是实现同步的一种手段。因此实现进程同步,底层还是依靠信号量。
-
分析哪里需要同步关系
保证一前一后执行两个操作 -
设置同步信号量,初始值为0
-
在"前操作"之后执行V操作
-
在"后操作"之前执行P操作
semaphore S=0;
semaphore S2=0;
semaphore S3=0;P0进程(){
代码1;
代码2;
代码3;
V(S); //释放资源P(S2);
代码7;
代码8;
V(S3);
}P1进程(){
P(S); //请求/等待资源
代码4;
代码5;
代码6;
V(S2);P(S3);
代码9;
代码10;
}
与互斥不同的是,同步信号量的初始值取决于资源的多少
C#版本
public class tongbu
{
private Semaphore _semaphore = new Semaphore(1, 1);
private int _i;
public void Run()
{
var t1 = new Thread(Work);
var t2 = new Thread(Work);
t1.Start();
t2.Start();
t1.Join();
t2.Join();
Console.WriteLine("所有线程执行完毕");
Console.WriteLine($"i={_i}");
}
public void Work()
{
//进入区
_semaphore.WaitOne();
try
{
//临界区
for (int i = 0; i < 10000; i++)
{
_i++;
}
}
finally
{
//退出区
_semaphore.Release();
}
//剩余区
Console.WriteLine($"{Thread.CurrentThread.ManagedThreadId}循环完毕");
}
}信号量机制实现前驱关系
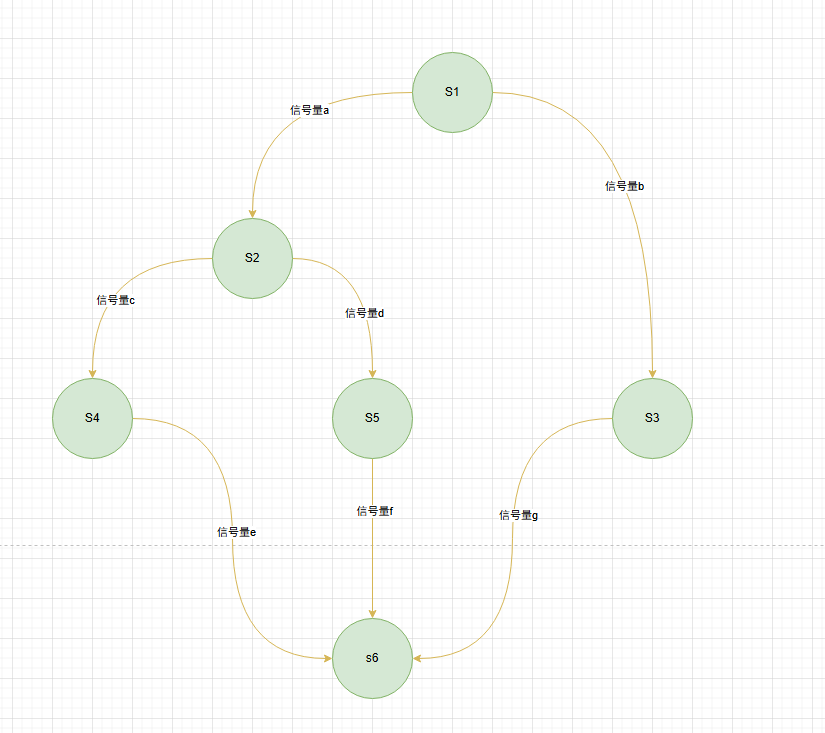
如图所示,6个进程需要按照代码顺序执行,从上面可以得到一个规律:每一对代码都是一对前驱关系,而每一对前驱关系都是一个进程同步问题(需要保证一前一后的操作)。
因此,该图看似很复杂,就是思路很简单。
-
为每一对前驱关系设置一个同步信号量
不可省略,必须是一对前驱关系对应一个独立的信号量,注意上面的例子,123与456是一对前驱,456与78同样也是一堆前驱,78与9/10也是一堆前驱,不要忽略了。否则同步关系成立不起来。 -
在"前操作"之前执行V操作
-
在"后操作"之后执行P操作
S1(){
V(a);
V(b);
......
}S2(){
P(a);
......
V(c);
V(d);S3(){
P(b);
......
V(g);
}S4(){
P(c);
......
V(e);
}S5(){
P(d);
......
V(f);
}S6(){
P(e);
P(f);
P(g);
......
}
}
一个口诀:进程互斥前P后V初始1,进程同步前V后P初始0
管程(Monitor)
- 什么是管程?
简单来说,就是对信号量(semaphore)的封装。 - 为什么要引入管程?
从上面的代码中可以看到,PV操作处理起来很麻烦,且容易出错。复杂条件下非常容易出现死锁,孤儿锁现象。
主要目的为了简化操作流程。 - 管程实现
JAVA中的synchronized,C#中的lock都是优秀的管程实现
管程的主动劣化,自旋
前面说到,当进程执行P操作获取资源时,如果获取不到会被阻塞,主动放弃CPU时间片。从而满足'让权等待'原则。
进程阻塞涉及到状态切换,进程上下文切换。从运行态=>阻塞态=>就绪态=>运行态,这期间消耗的时间是
毫秒级。
而有时候,当进程获取不到资源时,该资源有可能会在纳秒级的时间内被释放。此时如果完全遵守'让权等待'就显得很蠢了。
因此当代计算机语言都选择了折中的做法,先等待特定时间,等待期间就可以避免切换上下文,时间一到再进入阻塞状态。
注意,在单核处理器上不适用。就一个核心,自旋就是浪费。只有多核心才有意义。