2411 2411 2411
sh
Zhang G R, Pan F, Mao Y H, et al. Reaching Consensus in the Byzantine Empire: A Comprehensive Review of BFT Consensus Algorithms[J]. ACM COMPUTING SURVEYS, 2024,56(5).
出版时间: MAY 2024
索引时间(可被引用): 240412
被引: 9
'ACM COMPUTING SURVEYS'
卷56期5 DOI10.1145/3636553
出版商名称: ASSOC COMPUTING MACHINERY
期刊影响因子 ™
2023: 23.8
五年: 21.1
JCR 学科类别
COMPUTER SCIENCE, THEORY & METHODS
其中 SCIE 版本
类别排序 类别分区
1/144 Q1Toward More Efficient BFT Consensus
一、PBFT Practical Byzantine fault tolerance-1999
sh
Miguel Castro, Barbara Liskov, et al. 1999. Practical Byzantine fault tolerance. In OSDI, Vol. 99. 173--186.角色介绍:
客户端 Client :向区块链网络 发起交易或状态更新请求,等待共识结果。
主节点 Leader/Primary :负责 接收请求「交易排序」,协调共识。(轮换时同步状态)
副本节点 Replica :负责 备份请求,促进共识达成。「验证合法,维护一致」
故障节点 Byzantine Fault :负责 选择性响应,篡改数据。【何不直接剔除,因设计目标为容忍而非实时剔除】
正常流程:客户端请求 → 主节点排序广播 → 副本节点三阶段验证 → 客户端确认。
1.请求 I n v o k e Invoke Invoke
客户端 Client 向
Primary(ld)发送调用请求Req,并启动计时器Timer。【OP: 时间戳】
Client 收到来自不同的 Replicas 的仅 F+1个回复 Reply,即可判定操作完成,停止计时 Timer。
否则直到计时器到期,认为调用失败。【原因1:内部错误只能等待。原因2:链接不可靠未达Primary,广播】
2.协商(共识)
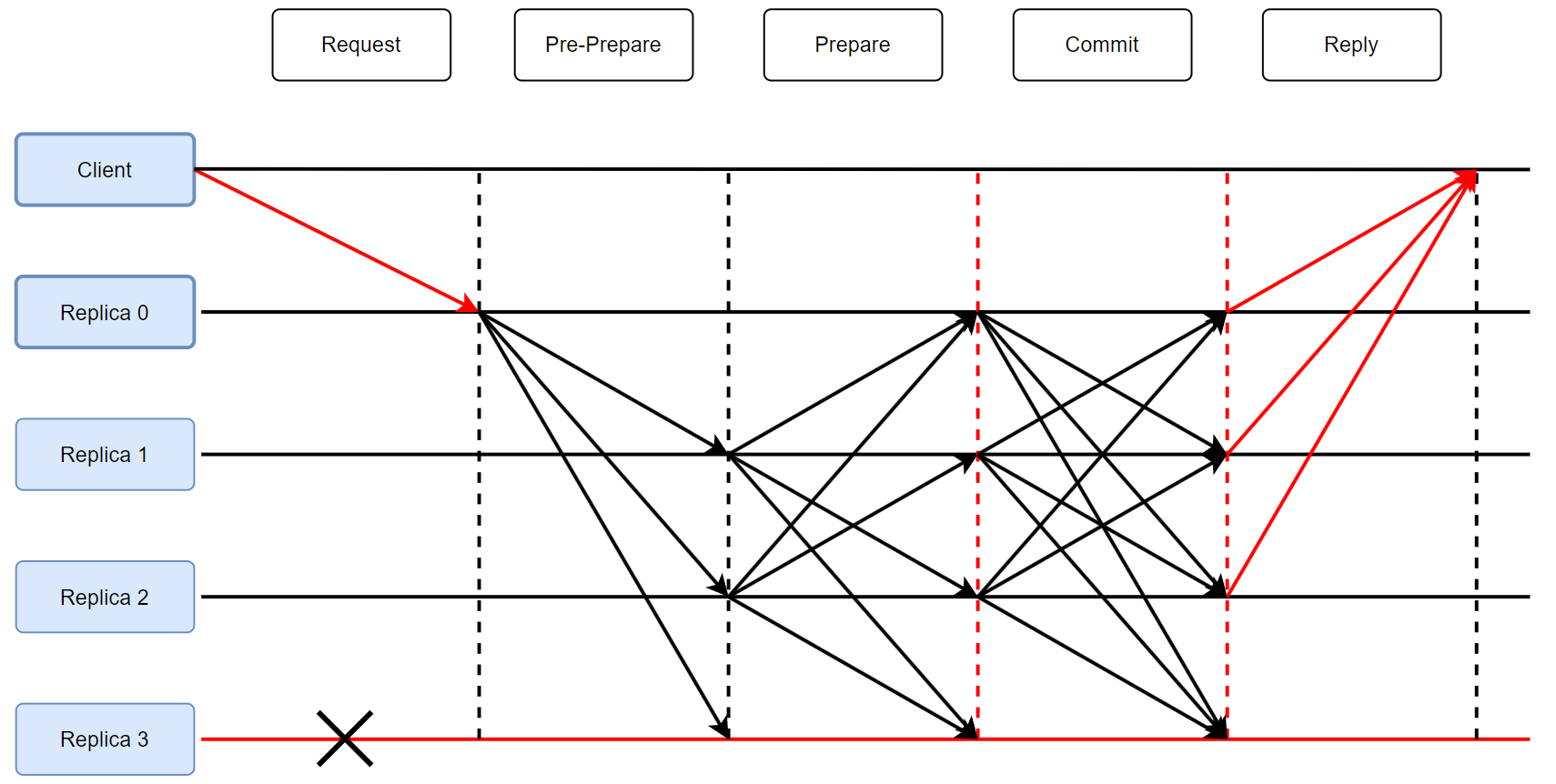 1.Pre-prepare阶段
1.Pre-prepare阶段
1> 分配唯一序列号 Sequence,范围[h, h+k](h为最后一个稳定检查点的 Seq,k为限增值)
2> ++将ViewNum、Seq、对请求Req的摘要hash组成PRE-PREPARE,然后签名Sig++。(搭载原生Req)
3> 发给所有 Backups==Replicas。
总结,指定一个编号Seq,把请求打包发送给所有节点。
2.Prepare阶段
1> 验证Sig。
2> 检查ViewNum是否处于同一视图。
3> 检查Seq未分配给其他Req。
4> 验证hash。
广播PREPARE消息,收集++满2F个消息后,造一个(都已准备)谓词++ Prepared Predicate。【共识基本达成】
总结,检验消息包后广播「没问题,我已准备提交」,满2F个后达成共识。
3.Commit阶段
1> 通过广播COMMIT消息,(广播谓词Prepared Predicate)。
2> 收集满2F个消息后,造另一个谓词committed-local predicate。【仲裁证书提供安全属性:正确副本执行方式相同】
总结,上阶段满2F个准备消息后,广播「我已提交」,再满2F个后达成共识。
4.Reply阶段
向Client发送REPLY消息 (resultOfOp=true)。
Weak Certificate 弱证书,仅需F+1个回复。
总结,上阶段满2F个提交消息后,向客户端回复调用完成。
检查点 C h e c k P o i n t CheckPoint CheckPoint
通过周期性状态同步,解决日志膨胀问题。【我理解为状态确认稳定后即可删除多余「过期」日志】
当
Req被Commit时的 execute 会更新节点的状态,该状态需要确保所有正确副本一致性,通过检查点机制。
O n c e a r e q u e s t i s c o m m i t t e d , t h e e x e c u t i o n o f t h e r e q u e s t r e f l e c t s t h e s t a t e o f a r e p l i c a . Once\ a\ request\ is\ committed,\ the\ execution\ of\ the\ request\ reflects\ the\ state\ of\ a\ replica. Once a request is committed, the execution of the request reflects the state of a replica.
算法定期对一系列 exe 生成证明,称为检查点。
同样的,在广播CHECKPOINT并收集2F个回复后,进化成稳定检查点 。【水位范围同上述Seq】
总结,节点「已提交」后会更新状态,通过CheckPoint消息将其状态广播,满2F个后确认状态稳定。
3.视图切换 V i e w C h a n g e ViewChange ViewChange
当
Primary故障或共识超时,启动切换协议。【确保故障时系统活性】
视图切换期间,节点处于异步状态(i.e., 没有完全同步)。协议来自论文[1](#1):但可能需要无限空间。
副本节点在收到 Req 后,启动一个 「节点
Timer」等待 Req 被提交 Commit。
Commit 完成,则 Timer 终止; R e s t a r t s t h e T i m e r i f t h e r e a r e o u t s t a n d i n g v a l i d r e q u e s t s t h a t h a v e n o t b e e n c o m m i t t e d . Restarts\ the\ Timer\ if\ there\ are\ outstanding\ valid\ requests\ that\ have\ not\ been\ committed. Restarts the Timer if there are outstanding valid requests that have not been committed.
++若 Timer 到期,则认为 Primary 故障++ ,广播VIEWCHANGE消息,引发视图切换。
该消息包含三个参数:++C P Q CPQ CPQ++.
选主公式:p = v mod |R| 。【R为节点总数】
各副本节点收到VIEWCHANGE后。
1> 验证:生成PQ的视图小于v。
2> 发送VIEWCHANGE-ACK消息给v+1的Primary(新主)「支持视图切换」。【包含节点ID、摘要及发送方ID】
3> Primary在收集 2F-1 条VIEWCHANGE 和*-ACK后,确认更改,将 VIEWCHANGE*加入集合++S S S++.【至少F+1条】
生成一个仲裁证书, view-change certificate。
总结:通过超时检测和多方认证,切换Ld「视图+1」。
Primary将 ID 与++S S S++ 中的 msg 配对后,加入集合++V V V++.
选择检查点最高值h。
提取[h, h+k]之间未提交的 Req,加入集合 ++X X X++ .【请求已在v或仲裁证书中准备好】
Backups 检查 ++V 、 X V、X V、X++ 中 msg 是否支持新主的【选择检查点和延续未提交请求】的决定。若不支持则切换视图至v+2.
终止 View-Change 协议。
视图切换期间异步处理请求。
总结,副本节点超时触发视图切换,新主节点基于最高检查点恢复未完成请求。
4.优缺点
开创异步网络中BFT的实用方案,启发高效BFT算法时代。
二次消息复杂性,阻碍其在大规模网络中的应用。
f a u l t y c l i e n t s u s e a n i n c o n s i s t e n t a u t h e n t i c a t o r o n r e q u e s t s . faulty\ clients\ use\ an\ inconsistent\ authenticator\ on\ requests. faulty clients use an inconsistent authenticator on requests. 会导致系统重复视图切换而卡死。
二、SBFT Scalable-2019
sh
Guy Golan Gueta, Ittai Abraham, Shelly Grossman, Dahlia Malkhi, Benny Pinkas, Michael Reiter, Dragos-Adrian Seredinschi, Orr Tamir, and Alin Tomescu. 2019. SBFT: a scalable and decentralized trust infrastructure. In 2019 49th Annual IEEE/IFIP international conference on dependable systems and networks (DSN). IEEE, 568--580.A s c a l a b l e a n d d e c e n t r a l i z e d t r u s t i n f r a s t r u c t u r e A\ scalable\ and\ decentralized\ trust\ infrastructure A scalable and decentralized trust infrastructure.
共3f + 2c + 1个 Servers。【f为拜占庭故障,c为崩溃或流浪】
拥有++Fast、Slow两种模式++ ,前者需要无故障节点、同步环境;后者就是线性PBFT。
利用门限签名 (阈值签名, t h r e s h o l d threshold threshold)解决了二次拜占庭广播问题。(其中阈值表示签名者数量)
1.快速通道 F a s t p a t h Fast\ path Fast path
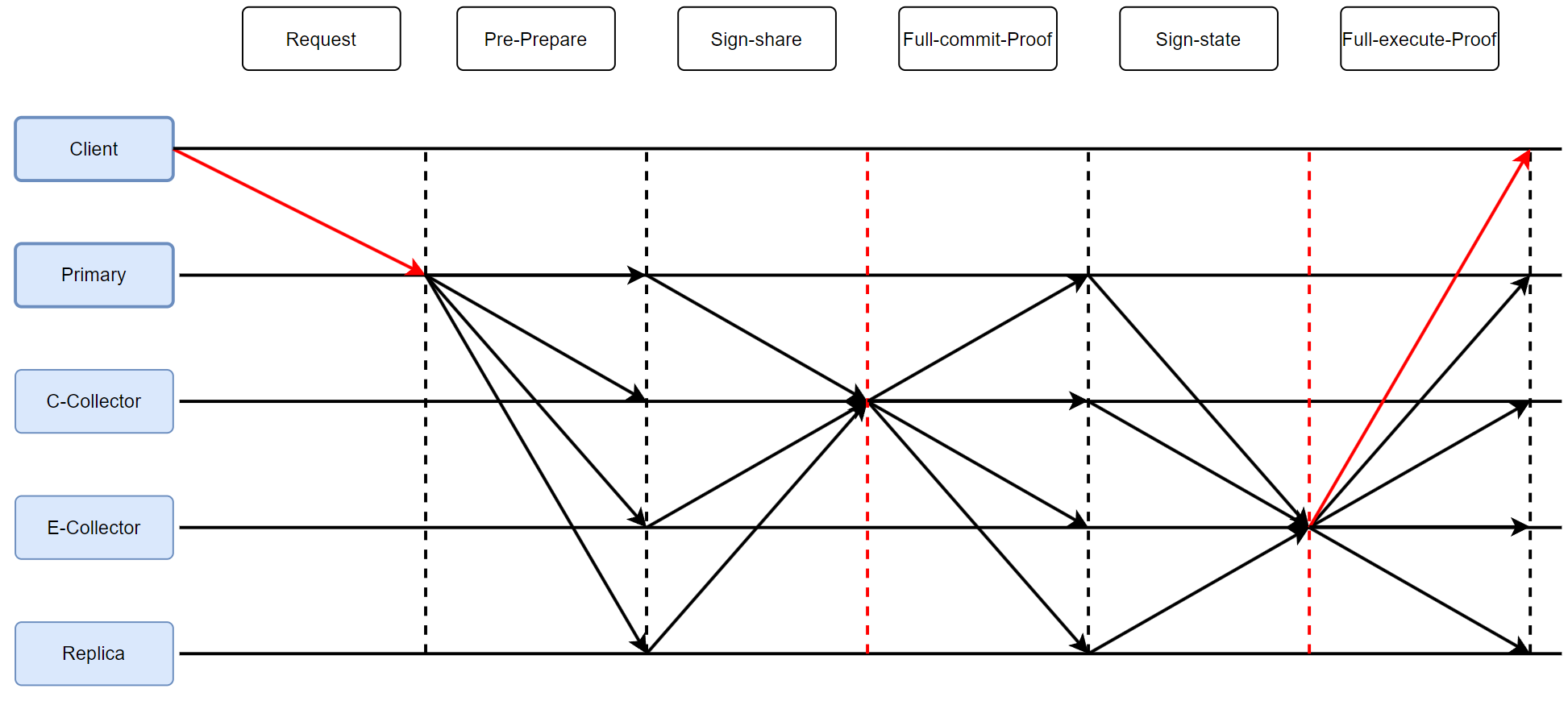 1.Pre-Prepare 阶段
1.Pre-Prepare 阶段
Primary 向所有 Servers 发送指令。
Servers 将回复发给 CommitCollector。
2.Full-commit-Proof 阶段
C-Collector 将收集到的 s i g n e d r e p l i e s signed\ replies signed replies 转换成一个++门限签名 msg++ ,并发给所有 Servers。
3.Full-execute-Proof 阶段
Servers 将回复发给 ExecutionCollector。
E-Collector 将收集到的 s i g n e d r e p l i e s signed\ replies signed replies 转换成一个++门限签名 msg++ ,并发给所有 Servers,包括 Client。【对比PBFT的F+1条确认】
2.线性PBFT l i n e a r − P B F T linear-PBFT linear−PBFT
将所有 Collector 聚合到 Primary。【权柄收回】
i f S B F T u s e s o n l y t h e p r i m a r y a s a l l " l o c a l " l e a d e r s i n e a c h p h a s e if\ SBFT\ uses\ only\ the\ primary\ as\ all\ "local"\ leaders\ in\ each\ phase if SBFT uses only the primary as all "local" leaders in each phase.
那么工作流就类似PBFT。
但是拥有++门限签名++。
给定视图
Primary 根据视图号选择。
Collectors 根据视图号和 Seq(commit state index)选择。
SBFT 建议随机选择二者。
线性PBFT模式下,
Primary总是选最后一个Collector。
当视图切换时,Servers 的角色更改。
3.视图切换 V i e w C h a n g e ViewChange ViewChange
View Change Trigger 阶段
两种情况会导致视图切换:
- Timeout.
- 收到 F+1 个节点的质疑(主有问题)。
View Change 阶段
++l s ls ls++ :最后稳定 Seq( l a s t s t a b l e s e q u e n c e last\ stable\ sequence last stable sequence)。【因部分同步可能不一致】
++w i n win win++ :用于限制未完成块数量,预定义值。【因此 Seq 在 l s ∼ l s + w i n ls\sim ls+win ls∼ls+win】
Seq 可以指明 Server 的状态。
触发 ViewChange 的 Server 会发送VIEWCHANGE消息给新主。【包含 l s ls ls和到 l s + w i n ls+win ls+win之间的状态摘要】
New View 阶段
收集满 2F+2C+1 后,启动新视图,并将其广播。
Accept a New-view 阶段
节点们接受 l s ∼ l s + w i n ls\sim ls+win ls∼ls+win间的Seq,或一个安全的、可用于未来交易的Seq。
4.优缺点
两种模式下均可实现线性消息传输,并且 Reply 阶段的通信为O(1)。
继承PBFT缺点,Client 完全可以只与F+1部分节点通信,触发不必要的视图切换。
关于实验
实验设置
- 部署规模:在真实世界规模的广域网(WAN)上部署了200个副本。每个区域使用至少一台机器,每台机器配置32个VCPUs,Intel Broadwell E5-2686v4处理器,时钟速度2.3 GHz,通过10 Gigabit网络连接。
- 故障容忍:所有实验都配置为能够承受
f=64个拜占庭故障。 - 客户端请求:使用公钥签名客户端请求和服务器消息。
实验方法
- 微基准测试:简单的Key-Value存储服务,每个客户端顺序发送1000个请求。
- 智能合约基准测试:使用以太坊的50万笔真实交易数据,副本通过运行EVM字节码执行每个合约,并将状态持久化到磁盘。
sh
- 无批处理模式:每个请求是一个单次put操作,写入随机值到随机键。
- 批处理模式:每个请求包含64个操作,模拟智能合约工作负载。
'客户端请求':客户端通过将交易分批成12KB的块(平均每批约50笔交易)发送操作。三、HotStuff-2019⭐️
sh
Maofan Yin, Dahlia Malkhi, Michael K Reiter, Guy Golan Gueta, and Ittai Abraham. 2019. HotStuff: BFT consensus with linearity and responsiveness. In Proceedings of the 2019 ACM Symposium on Principles of Distributed Computing. 347--356共3F+1个Servers。
达成活跃性、安全性无需同步假设 。乐观响应:++前2F+1++个消息即可进行共识决策。
采用轮换 Primary 保证链质量。
采用门限签名 达到共识线性。(最坏情况,连续Primaries故障,复杂度为f*n)
1.请求
Client向所有Servers发送
Req。
同PBFT,等待F+1个Reply,操作完成。
客户端请求失败处理部分,引用了文献:
sh
Alysson Bessani, Joao Sousa, and Eduardo EP Alchieri. 2014. State machine replication for the masses with BFT-SMART. In 2014 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks. IEEE, 355--362.
Miguel Castro, Barbara Liskov, et al. 1999. Practical Byzantine fault tolerance. In OSDI, Vol. 99. 173--186.2.共识
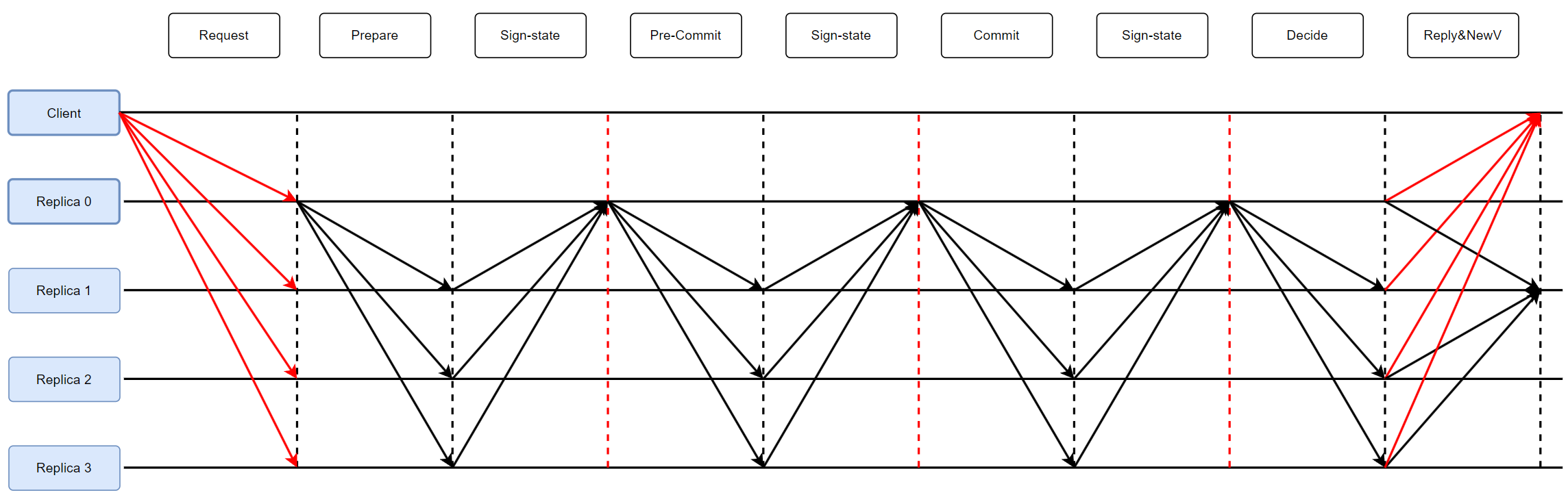 1.Prepare阶段
1.Prepare阶段
Primary在收到Req后,向节点(Replica)广播PREPARE消息。
节点验证消息:
- 为上次提交的msg的扩展(无间隔)
- 最高View(最新视图)
验证后,用部分签名对PREPARE-VOTE消息签名,并发给Primary。
Primary在等待2F+1后,生成++仲裁证书(Quorum Certificate,QC)++ ,记为 PrepareQC 。【可以理解为完成】
2.Pre-Commit 阶段
广播带有 PrepareQC 的msg,节点将其存储。
将COMMIT-VOTE消息签名后发给Primary。
Primary在集齐2F+1后,形成 Pre-CommitQC。
3.Commit 阶段
广播带有 Pre-CommitQC 的msg。
节点回复COMMIT给Primary,并且更新变量 lockedQC 。【保存QC计数/Req】
k e e p s c o u n t i n g t h e n u m b e r o f r e c e i v e d Q C s f o r a r e q u e s t keeps\ counting\ the\ number\ of\ received\ QCs\ for\ a\ request keeps counting the number of received QCs for a request.
4.Decide 阶段
Primary在收到2F+1后,广播DECIDE给Replicas。
节点认为共识达成,开始执行请求。
然后ViewNum++。【视图切换开始】
然后发送New-View给新主。
三个变量
-
++p r e p a r e Q C prepareQC prepareQC++ :当前节点已知的最高锁定 PREPARE msg(最新)。
-
++l o c k e d Q C lockedQC lockedQC++ :已知最高锁定 COMMIT msg(最新)。
-
++v i e w N u m viewNum viewNum++:节点当前所处视图。
新主收到2F+1个New-View后,在 p r e p a r e Q C prepareQC prepareQC基础上扩展。(理解为+1)
若未能及时收满2F+1,则触发超时,视图切换。
3.视图切换 V i e w C h a n g e ViewChange ViewChange
为了确保链质量,HotStuff可以++更频繁++的切换试图。
通过广播协调消息和收集门限签名进行共识。因此视图切换被包含于HotStuff的核心流程。
新主选择方式为 p = v m o d n p = v\mod n p=vmodn。
4.优缺点
使用门限签名,实现线性消息传递。
每个阶段的收集投票,构建门限签名,可以被++流水线化++ p i p e l i n e d pipelined pipelined。从而简化HotStuff协议的构建,例如Casper:(同时降低O(n))
sh
Vitalik Buterin and Virgil Griffith. 2017. Casper the friendly finality gadget. arXiv preprint arXiv:1710.09437 (2017).还可以用++延迟塔++ d e l a y t o w e r s delay\ towers delay towers扩展到公有链:
sh
Shashank Motepalli and Hans-Arno Jacobsen. 2022. Decentralizing Permissioned Blockchain with Delay Towers. (2022).
arXiv:2203.09714在
failures情况下,HotStuff吞吐量显著下降(不能达成共识)。
关于实验
- 使用Amazon EC2 c5.4xlarge实例,每个实例有16个vCPU,由Intel Xeon Platinum 8000处理器支持。
- 所有核心的Turbo CPU时钟速度高达3.4GHz。
- 每个副本运行在单个VM实例上。
网络配置:
- 测得的TCP最大带宽约为1.2 Gbps。(使用
iperf工具) - 网络延迟小于1毫秒。
实验设置:
- 实验中使用了4个副本,配置为容忍单个故障(即f = 1)。
- 使用了空操作请求和响应,没有触发视图更改。
- 实验中使用了不同的批次大小(100、400和800)和不同的有效负载大小(0/0、128/128和1024/1024字节)。
软件和工具:
- HotStuff的实现使用了++大约4K行C++代码,核心共识逻辑大约200行++。
- 使用secp256k1进行数字签名。
- 使用NetEm工具引入网络延迟。
使用BFT-SMaRt的ThroughputLatencyServer和ThroughputLatencyClient程序测量吞吐量和延迟。
四、ISS: Insanely Scalable State Machine Replication-2022
sh
Chrysoula Stathakopoulou, Matej Pavlovic, and Marko Vukolić. 2022. State machine replication scalability made simple. In Proceedings of the Seventeenth European Conference on Computer Systems. 17--33.
会议17th European Conference on Computer Systems (EuroSys)欧洲计算机系统会议,顶级学术会议
地点Rennes, FRANCE
日期APR 05-08, 2022
赞助方Assoc Comp Machinery; ACM SIGOPS; USENIX; Huawei; Stormshield; Microsoft; Protocol Labs Res; Red Hat; Amazon; Meta; Google; Intel; Cisco共3F+1节点。
是一个通用框架,
通过划分工作负载,并且关联 SB(Sequenced Broadcast) 实例与Leader,
将传统的单Leader的 TOB(Total Order Broadcast) 协议扩展为多Leader的协议。
达成PBFT的37倍,Raft的55倍,Chained HotStuff的56倍。
1.初始配置
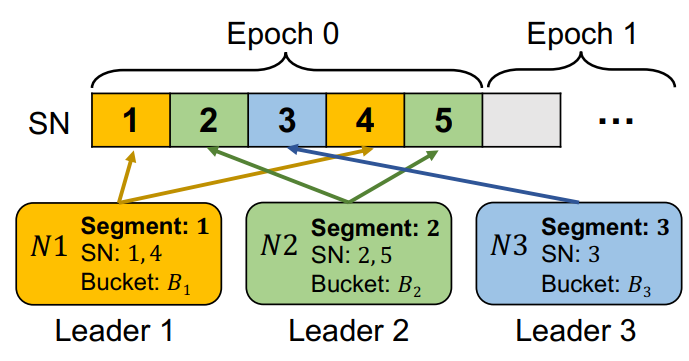
日志log :该节点接收的所有消息,由Req组成,被批处理以降低消息复杂性。
SN(Sequence Number)序列号:相对于日志开头的偏移量。
将日志分成epoch,按SN以轮询方式 分配给Leader,再将epoch分成segment,这样与Leader相对应。
所有Req基于modulo 哈希函数分类到桶bucket中,再将桶分配给Leader。
++段、Leader、桶++,一一对应。
2.复制协议 R e p l i c a t i o n P r o t o c o l Replication\ Protocol Replication Protocol
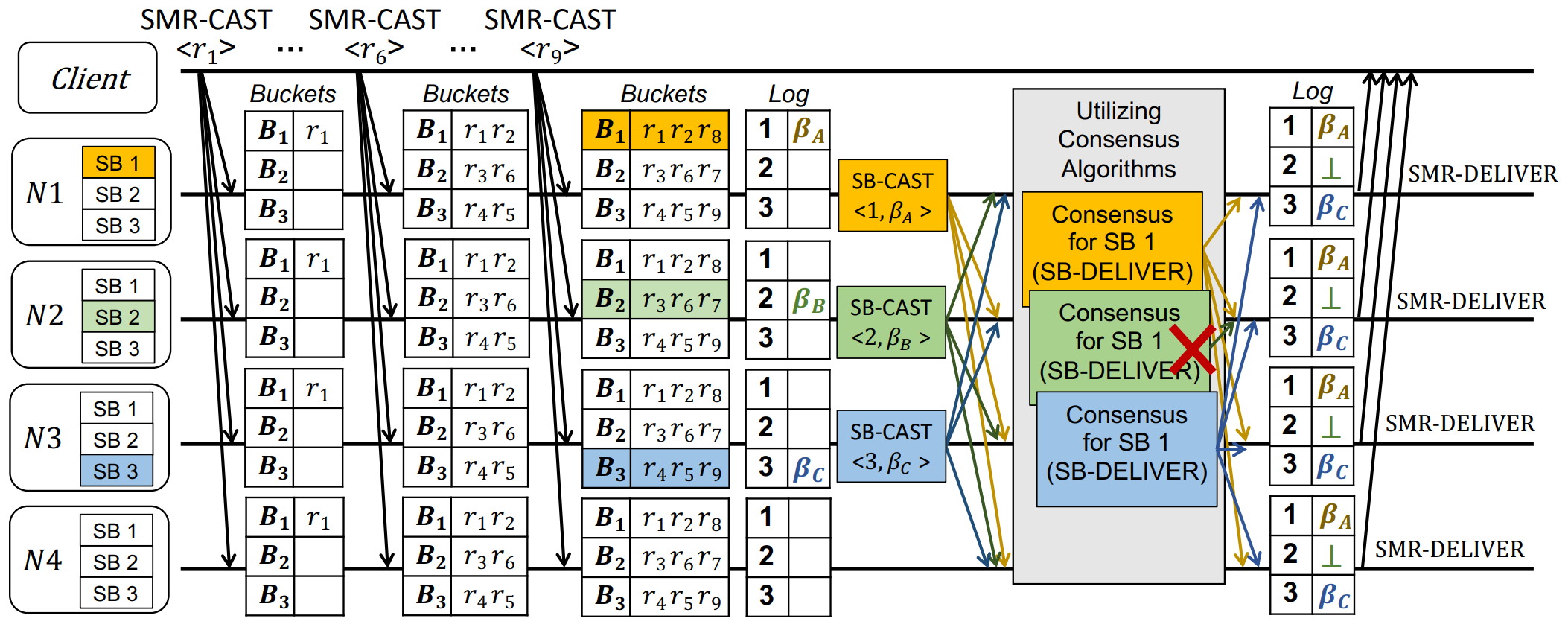 初始配置阶段
初始配置阶段
1> 选中N123三个节点为Leader。
2> 分别分配segment 1、2、3。
分别对应SN1 4,2 5,3。
3> 分桶给Leader,包含用于提出提议的Req批次 r e q u e s t b a t c h e s request\ batches request batches。
分别为B1、2、3。
等待
Req阶段
通过多SB实例(共识实例)达成共识。
++SB实例++ 与一个Leader及其Segment相关联。
等待客户端发送请求,记为 S M R − C A S T ∣ < r x > SMR-CAST|<r_x> SMR−CAST∣<rx>,散列到本地桶队列中。直到:
- 桶满(预定义大小)如 ∣ B i ∣ = 3 |B_i|=3 ∣Bi∣=3.
- 预定时间(距上次提案)。
++将桶里的Req请求打包为一批次 β i \beta_i βi++ 。然后广播 S B − C A S T < 1 , β A > SB-CAST<1,\beta_A> SB−CAST<1,βA>消息。
共识阶段
每个Leader运行底层包装的TOB协议,就其提议的SB实例达成共识。【可并行non-blocking】
- 共识成功 ,将SB中承载的一批
Req交付。 - 共识失败 ,
log中记录⊥。
TOB可以保证,++成功时++所有正确节点中的序列号与批次一致。
当一个epoch的所有SN号对应的log都被填满时,节点向Client发送 S M R − D E L I V E R E D SMR-DELIVERED SMR−DELIVERED,收满 a q u o r u m a\ quorum a quorum即完成。
3.多领导选择 M u l t i p l e L e a d e r S e l e c t i o n Multiple\ Leader\ Selection Multiple Leader Selection
L e a d e r S e l e c t i o n P o l i c y , L E Leader\ Selection\ Policy,LE Leader Selection Policy,LE选主策略可以自定义 ,只要能保证活性:each bucket will be assigned to a segment with a correct leader infinitely many times in an infinite execution将桶分配给正确Leader的段。
例如:保证足够多的正确Leader.
sh
Zarko Milosevic, Martin Biely, and André Schiper. 2013. Bounded delay in byzantine-tolerant state machine replication. In 2013 IEEE 32nd International Symposium on Reliable Distributed Systems. IEEE, 61--70Leader 故障检测
每个SB实例用== F a i l u r e D e t e c t o r Failure\ Detector Failure Detector==,用来检测quiet nodes。
ISS会从集合移除故障Leader,用LE再选个主。
4.优缺点
Pros
- 吞吐量,因为并行。
- 对客户端高响应,可立即执行
Req。 - 资源不浪费,
Req仅入一个桶。
Cons
- 共识延迟,引入额外开销。
- 故障时,SB实例高概率共识失败。(任何Leader故障,新主,并重新提出未提交的
Req) Req需要发到所有节点,以确保Req放入正确桶。
五、DAG-Rider-2021
sh
Idit Keidar, Eleftherios Kokoris-Kogias, Oded Naor, and Alexander Spiegelman. 2021. All you need is dag. In Proceedings of the 2021 ACM Symposium on Principles of Distributed Computing. 165--175.D i r e c t e d a c y c l i c g r a p h ( D A G ) Directed\ acyclic\ graph\ (DAG) Directed acyclic graph (DAG).有向无环图。
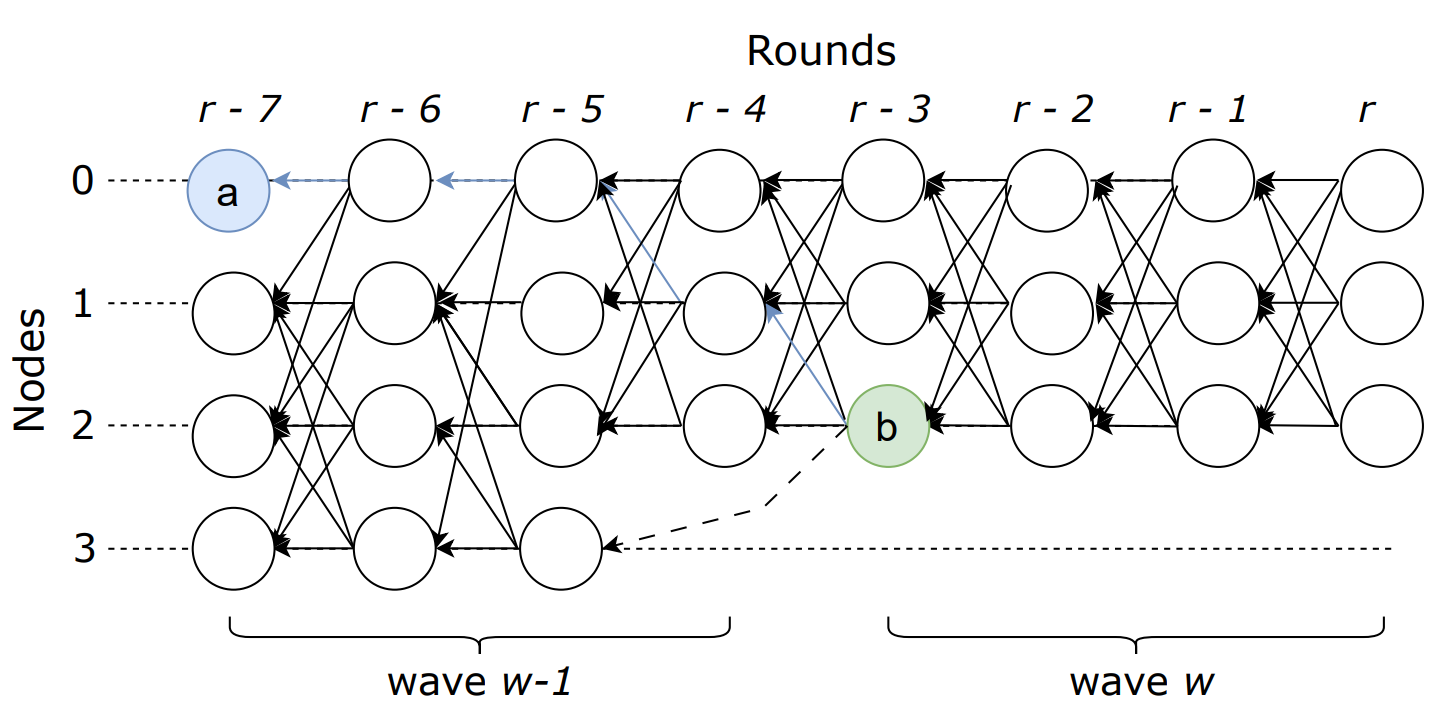
图中为完整的消息传播历史,包含:遍历的路径、因果关系 c a u s a l h i s t o r y causal\ history causal history.
传统的Leader服务器承担:
tx分发。 t r a n s a c t i o n d i s t r i b u t i o n transaction\ distribution transaction distribution- 达成共识。 c o n s e n s u s p h a s e consensus\ phase consensus phase
两项责任,巨大工作量导致++tx积压、系统瓶颈++。
而DAG-based算法将二者分离 ,在tx分发阶段无需Leader(吞吐量显著增加),在共识阶段每个实例都有一个Leader。
1.系统模型&服务属性 S y s t e m m o d e l a n d s e r v i c e p r o p e r t i e s . System\ model\ and\ service\ properties. System model and service properties.
DAG-Rider是一种异步拜占庭原子广播协议 ( a s y n c h r o n o u s B y z a n t i n e A t o m i c B r o a d c a s t , B A B asynchronous\ Byzantine\ Atomic\ Broadcast, BAB asynchronous Byzantine Atomic Broadcast,BAB)。
以最佳时间和消息复杂度实现了后量子安全。
分为两层:
- 基于轮的结构化DAG,分发
tx用。 - 零开销的共识协议,独立确定提交消息顺序。
使用
Bracha广播。
共3F+1个节点。
假设了一个全局完美硬币( g l o b a l p e r f e c t c o i n global\ perfect\ coin global perfect coin)来确保活性。允许在wave的实例上独立选择一个Leader.
2.DAG流水线 P i p e l i n i n g Pipelining Pipelining
节点独立维护自己的DAG,用一个数组[]存储。(所有节点间消息传播拓扑)
以轮++r o u n d round round++为单位。
强边 :分发相同的msg,直链(directly linked in the previous round)。
弱边:没有直链。
协议流程
验证器一直等待客户端发送交易(请求、顶点),存储于缓冲区buffer,并监视:
定期检查,若其++所有前导顶点都已成功接收++ ,则加入DAG[],并根据round组织起来。
当满2F+1个顶点时,进入下一轮r+1。(下一波?虽然首轮也是下轮)
生成新的顶点v:r+1,弱边,并广播。
因为网络部分同步,可能有不同的DAG出现,但BAB会保证最终收敛。
4.共识 C o n s e n s u s i n D A G s Consensus\ in\ DAGs Consensus in DAGs 「我也不知3跑哪了」
利用全局完美硬币,节点可以独立检查 DAG,推断需交付的区块及其提交顺序。(无需额外协调)
在DAG于节点中发送顶点完毕后,系统启动共识 旨在确保分发的tx完成提交aimed at deterministically finalizing the commit of the disseminated transactions.
在这个过程中,DAG被分为波waves,每波有4个轮次rounds。
利用完美硬币在第一轮中随机选择Leader(满2F+1强边)。
按照预先确定的顺序交付顶点块。交付区块时,会将其因果关系历史上的值也一并提交。
5.优缺点
Pros.
- 吞吐量显著提升。
- DAG达成消息分发和促进共识两种目的 d u a l p u r p o s e dual\ purpose dual purpose。
- 更稳定的提交。
Cons.
- 因为分离,延迟激增 𝑂 ( 𝑛 3 l o g ( 𝑛 ) + 𝑛 𝑀 ) 𝑂(𝑛 3 log(𝑛) + 𝑛𝑀) O(n3log(n)+nM) 。
六、Narwhal and Tusk-2022
sh
George Danezis, Lefteris Kokoris-Kogias, Alberto Sonnino, and Alexander Spiegelman. 2022. Narwhal and tusk: a dag-based mempool and efficient bft consensus. In Proceedings of the Seventeenth European Conference on Computer Systems. 34--50.将tx传播 与tx排序分离,实现高效共识。
Mempool负责可靠传播,少量元数据用来排序。
1.系统模型&服务属性
共3F+1节点。
Mempool是一个KV键值存储 ( d , b ) (d,b) (d,b)。
K:digest.
V:交易块block。
服务属性
- 完整性:(d,b)。
- 可用性:写入(d,b)后。
- 包含性 C o n t a i n m e n t Containment Containment:后块包含前块。
- 2 / 3 2/3 2/3因果性:后块包含至少 2 / 3 2/3 2/3前块。
- 1 / 2 1/2 1/2链质量:至少有一半
causal history是诚实者所写入。
2.复制协议
替换Bracha广播。
用固有++DAG++ +++证书++实现。
blocks包含
- hash sig。
txlist。- 证书
certificates of availability。
证书包含:hash、2F+1 sig、round。
原理
- 收集
tx------txlist 和 证书list。 r-1主收集2F+1证书 ------r,新块广播。- 验证sig、含2F+1、唯一块,签名(确认)。
- 满2F+1, 造一个证书并广播,此时停止广播新块。
3.Tusk共识
- 选主同DAG-Riders。
- 一波三轮。
- 一三🉑重叠,4.5rounds。
4.优缺点
Pros.
- 一个基于DAG的BFT算法的具体实现。
- 吞吐量优势。
Cons.
- 高延迟(提交区块前等待多轮)。
- 未满足标准的
tx需要等更多wave。
E n d . End. End.
- Miguel Castro and Barbara Liskov. 2002. Practical Byzantine fault tolerance and proactive recovery. ACM Transactions on Computer Systems (TOCS) 20, 4 (2002), 398--461. ↩︎