从递归入手一维动态规划

1. 509. 斐波那契数
1.1 思路
递归

F(i) = F(i-1) + F(i-2)
每个点都往下展开两个分支,时间复杂度为 O(2n) 。
在上图中我们可以看到 F(6) = F(5) + F(4)。
计算 F(6) 的时候已经展开计算过 F(5)了。而在计算 F(7)的时候,还需要再一次展开计算 F(5)。
记忆化搜索

我们可以使用一张缓存表记录已经展开计算的结果。
上图右侧就是缓存表。
仔细看,我们主要是沿着这棵树的左边一直计算,计算好后将结果记录缓存表中。轮到计算右边的时候就可以直接返回。
例如我们一直沿着左边计算 F(i-3)。
F(i-3) = F(i-4) + F(i-5)。这个过程计算完后就会把每个函数各自的结果记录到缓存表中。
将F(i-3)的结果返回给F(i-2)。
F(i-2) = F(i-3) + F(i-4)。F(i-3)的结果已经返回,接着计算F(i-4)。因为F(i-4)之前计算过,我们直接从缓存表查F(i-4)的结果,返回给F(i-3)即可。
这种做法时间复杂度为O(n)。
自底向上动态规划
java
[0 1 1 2 3 ]
0 1 2 3 4 5 6 7初始情况:arr0 = 0,arr1 = 1
arr2 = arr1 + arr0 = 1 + 0 = 1
arr3 = arr2 + arr1 = 1 + 1 = 2
这样从底部不断向上推,时间复杂度也为O(n)。
滚动数组
java
[0 1 ]
lastLast last 设置两个变量,lastLast = 0,last = 1。
cur = lastLast + last = 0 + 1 = 1。
之后分别向后移动lastLast 、 last。
lastLast = last
last = cur
java
[0 1 1 ]
lastLast last 这样就节省了额外空间复杂度O(n)
1.2 代码
java
import java.util.Arrays;
/**
* @Title: Fib
* @Author Wood
* @Package leetcode.DynamicProgramming.class66.lc509
* @Date 2025/4/8 18:58
* @description: https://leetcode.cn/problems/fibonacci-number/
*/
public class Fib {
// 递归
public int fib1(int n) {
return f1(n);
}
// 递归
private int f1(int n) {
if (n == 0){
return 0;
}
if (n == 1){
return 1;
}
return f1(n-1) + f1(n-2);
}
// 记忆化
public int fib2(int n) {
int[] dp = new int[n+1];
Arrays.fill(dp,-1);
return f2(dp,n);
}
// 记忆化
private int f2(int[] dp, int n) {
if (n == 0){
return 0;
}
if (n == 1){
return 1;
}
if (dp[n] != -1){
return dp[n];
}
int ans = f2(dp,n-1) + f2(dp,n-2);
dp[n] = ans;
return ans;
}
// 自底向上动态规划
public int fib3(int n) {
if (n == 0){
return 0;
}
if (n == 1){
return 1;
}
int[] dp = new int[n+1];
dp[1] = 1;
for (int i = 2; i <= n ; i++) {
dp[i] = dp[i-1] + dp[i-2];
}
return dp[n];
}
// 滚动数组
public int fib4(int n) {
if (n == 0){
return 0;
}
if (n == 1){
return 1;
}
int lastLast = 0;
int last = 1;
int cur = 0;
for (int i = 2; i <= n; i++) {
cur = last + lastLast;
lastLast = last;
last = cur;
}
return cur;
}
}2. 983. 最低票价
2.1 思路
递归
java
days [3 4 9 20 50 ... ]
0 1 2 3 4
costs [a b c]
0 1 2递归函数 f(days,costs,i) 。该函数返回的是从days数组 索引i 的日期开始旅行,所需的最小花费。(days 和 costs 是不变的,以下用 f(i) 代指递归函数)
i = 0,daysi = 3。从第三天开始旅行,有下面三种方案。
1. 买为期 1 天的通行证(a元) + f(1)
1. 买为期 7 天的通行证(b元) + f(3)
1. 买为期 30 天的通行证(c元) + f(4)如果选择方案1,f(0) = a + f(1)。f(1) 又可以选择三种方案,就这样递归遍历下去了。不断记录递归过程中的最小值即可。
如果选择方案2,f(0) = b + f(3)。f(3) 继续递归。
如果选择方案3,f(0) = c + f(4)。f(4) 继续递归。
记忆化搜索
java
days [3 4 9 20 50 ... ]
0 1 2 3 4
costs [a b c]
0 1 2上面的递归方法会存在重复计算。
days0、days1、days2、days3 都买1天车票,价格 = 4a + f(4)。
days0 买7天车票,days3 买1天车票,价格 = b + a + f(4)。
days0 买30天车票,价格 = c + f(4)。
以上三种情况都重复计算了 f(4)。
用缓存数组记录结果即可。
自底向顶的动态规划
我们想知道从 days0 出发的最低费用,需要依赖后面days索引的返回值。
如果要从简单状态填到复杂状态,应该是从后向前的顺序。
days数组的长度为n。
f(n) = 0。因为n索引越界,没有旅行,也就没有费用,直接返回0。即dpn = 0。
dpn-1 依赖 dpn,dpn-2 依赖 dpn-1 和 dpn。
由此,不断向前推,能推到dp0。而dp0 就是从days0 出发的最低费用。
2.2 代码
java
import java.util.Arrays;
/**
* @Title: MincostTickets
* @Author Wood
* @Package leetcode.DynamicProgramming.class66.lc983
* @Date 2025/4/8 19:14
* @description: https://leetcode.cn/problems/minimum-cost-for-tickets/
*/
public class MincostTickets {
// 每种方案能管几天
public static int[] durations = {1,7,30};
//递归
public static int mincostTickets1(int[] days, int[] costs) {
return f1(days,costs,0);
}
//递归
private static int f1(int[] days, int[] costs, int i) {
if (i == days.length){
// 后续没有旅行了,也就没有花费
return 0;
}
int ans = Integer.MAX_VALUE;
// k 是方案编号
for (int k = 0, j = i; k < 3; k++) {
// j是你当前选了方案之后,方案能管到的下一天的days索引
// days[i] 是出发旅行的日期
// durations[k] 表示你选中的该方案的车票能管几天
// days[i] + durations[k] 表示车票能管到第几天
// days[j] 是车票能管到的最后一天的下一天
// 下一次递归遍历从索引j开始,即f1(days,costs,j)
while (j < days.length && days[i] + durations[k] > days[j]){
j++;
}
ans = Math.min(ans,costs[k] + f1(days,costs,j));
}
return ans;
}
// 记忆化
public static int mincostTickets2(int[] days, int[] costs) {
int[] dp = new int[days.length];
Arrays.fill(dp, Integer.MAX_VALUE);
return f2(days,costs,0,dp);
}
// 记忆化
private static int f2(int[] days, int[] costs, int i,int[] dp) {
if (i == days.length){
// 后续没有旅行了,也就没有花费
return 0;
}
if (dp[i] != Integer.MAX_VALUE){
return dp[i];
}
int ans = Integer.MAX_VALUE;
// k 是方案编号
for (int k = 0, j = i; k < 3; k++) {
while (j < days.length && days[i] + durations[k] > days[j]){
j++;
}
ans = Math.min(ans,costs[k] + f2(days,costs,j,dp));
}
dp[i] = ans;
return ans;
}
public static int MAXN = 366;
public static int[] dp = new int[MAXN];
// 自底向顶的动态规划
public static int mincostTickets3(int[] days, int[] costs){
int n = days.length;
Arrays.fill(dp,0,n+1,Integer.MAX_VALUE);
dp[n] = 0;
for (int i = n - 1; i >= 0; i--) {
for (int k = 0,j = i; k < 3; k++) {
while (j < days.length && days[i] + durations[k] > days[j]){
j++;
}
dp[i] = Math.min(dp[i], costs[k] + dp[j]);
}
}
return dp[0];
}
}3. 91. 解码方法
3.1 思路
递归
java
"1 1 0 6"
i 递归函数 f(char\[\] s,int i) ,s是字符串转换后得到的数组(不会变),该函数的返回结果是从索引i位置开始,i 及其它之后的位置能够返回多少种解码方式。以下直接用 f(i) 表示递归函数。
一共有三种情况:
- 索引i 的元素是0,没有办法转换,直接返回0。
- 将索引i 上的数字转换为字母,再调用 f(i+1)
以上面的字符串为例,1 -> A,f(i+1)
-
将索引 i 与 i + 1 上的数字转换为字母(前提是 i 与 i+1 所组成的数字 <=26),再调用 f(i+2)
11 -> k,f(i+2)
记忆化搜索
i 的变化范围是 0 ~ n。(n 是字符串长度)
那我们的dp数组就准备 n + 1 大小的。
记录每次的返回结果。
自底向顶的动态规划
i 从 0开始,i位置的结果依赖于 i +1 与 i+2 的结果。
那我们先填n位置的结果,也就是 1。再填 n-1、n-2,从右往左推断。
滚动数组
求 i 位置 依赖 i +1 和 i+2 。
求 i -1 位置 依赖 i 和 i+1 。
这样的话每必要整一张表,直接两个变量滚动更新即可。
next 记录 i + 1 的结果。
nextNext记录 i + 2 的结果。
i 的 结果就是 next + nextNext。
下一步 nextNext 记录 i + 1 的结果。next 记录 i 的结果。就能得出 i - 1 的结果。
3.2 代码
java
import java.util.Arrays;
/**
* @Title: NumDecodings
* @Author Wood
* @Package leetcode.DynamicProgramming.class66.lc91
* @Date 2025/4/9 13:55
* @description: https://leetcode.cn/problems/decode-ways/
*/
public class NumDecodings {
// 递归
public static int numDecodings1(String s) {
return f1(s.toCharArray(),0);
}
// 递归
private static int f1(char[] s, int i) {
if (i == s.length){
// 证明之前所选的方案可以形成一种有效编码
return 1;
}
int ans;
if (s[i] == '0'){
ans = 0;
}else {
// 索引i上的数字自己转
ans = f1(s,i+1);
// i 和 i+1 一起转
// 以 '11' 为例
// (s[i] - '0') * 10 = ('1' - '0') * 10 = 1 * 10 = 10
// (s[i+1] - '0') = ('1' - '0') = 1
// 10 + 1 = 11
if (i + 1 < s.length && (s[i] - '0') * 10 + (s[i+1] - '0') <= 26){
ans += f1(s,i+2);
}
}
return ans;
}
// 记忆化搜索
public static int numDecodings2(String s){
int[] dp = new int[s.length()];
Arrays.fill(dp,-1);
return f2(s.toCharArray(),0,dp);
}
// 记忆化搜索
private static int f2(char[] s, int i, int[] dp) {
if (i == s.length){
return 1;
}
if (dp[i] != -1){
return dp[i];
}
int ans;
if (s[i] == '0'){
ans = 0;
}else {
ans = f2(s,i+1,dp);
if (i+1 < s.length && (s[i] - '0') * 10 + (s[i+1] - '0') <= 26){
ans += f2(s,i+2,dp);
}
}
dp[i] = ans;
return ans;
}
// 自底向顶的动态规划
public static int numDecodings3(String str){
char[] s = str.toCharArray();
int n = s.length;
int[] dp = new int[n + 1];
Arrays.fill(dp,-1);
dp[n] = 1;
for (int i = n-1; i >= 0; i--) {
if (s[i] == '0'){
dp[i] = 0;
}else {
dp[i] = dp[i+1];
if (i+1 < s.length && (s[i] - '0') * 10 + (s[i+1] - '0') <= 26){
dp[i] += dp[i+2];
}
}
}
return dp[0];
}
// 滚动数组
public static int numDecodings4(String s){
// dp[n] = 1
int next = 1;
// dp[n+1]不存在
int nextNext = 0;
for (int i = s.length(),cur; i >= 0; i--) {
if (s.charAt(i) == '0'){
cur = 0;
}else {
cur = next;
if (i+1 < s.length() && (s.charAt(i) - '0') * 10 + (s.charAt(i+1) - '0') <= 26){
cur += nextNext;
}
}
nextNext = next;
next = cur;
}
return next;
}
}4. 639. 解码方法 II
4.1 思路
递归
- 如果 i 位置是0,没办法转,直接返回0。
- i 位置 不是0 (i 位置的字符单独转,f(i+1)后续能有多少种转换情况)
- i 位置不是 '*' ,那么 i 上的数字就是 1 ~ 9 ,继续递归调用 f(i+1)
- i 位置是 '*' ,而 '*' 可以转换 1 ~ 9,那结果就是 9 * f(i+1)
- i 和 i +1 一起转 (f(i + 2) 后续有多少种转换情况)
- i 和 i +1 都是数字
- 如果它们合起来的数字<= 26,继续调用f(i + 2) 。否则返回0
- i 是数字, i +1 是 '*'
- i 是 1, i +1 是 '*' ,结果 9 * f(i + 2)。(从11到19,总共是9种情况)
- i 是 2, i +1 是 '*' ,结果 6 * f(i + 2)。(从21到26,总共是6种情况)
- i位置的数字 > 2,直接返回0。
- i 是**'*'**, i +1 是 数字
- i 是**'', i +1 是 6,结果 2 * f(i + 2)。(''** 只能是1,2)
- i 是**'', i +1 > 6,结果 1 * f(i + 2)。(''** 只能是1)
- i 是 '*' , i +1 是 '*'
- 结果 15 * f(i + 2)。(从11 ~ 19,以及 21 ~ 26 ,总共15种情况)
- i 和 i +1 都是数字
4.2 代码
java
import java.util.Arrays;
/**
* @Title: NumDecodingsII
* @Author Wood
* @Package leetcode.DynamicProgramming.class66.lc639
* @Date 2025/4/9 15:38
* @description: https://leetcode.cn/problems/decode-ways-ii/
*/
public class NumDecodingsII {
public static int MOD = 1000000007;
// 递归
public static int numDecodings1(String s) {
return f1(s.toCharArray(),0);
}
// 递归
private static int f1(char[] s, int i) {
if (i == s.length){
return 1;
}
if (s[i] == '0'){
return 0;
}
// s[i] != '0'
// 2) i想单独转
int ans = f1(s,i+1) * (s[i] == '*' ? 9 : 1);
// 3) i i+1 一起转
if (i + 1 < s.length){
if (s[i] != '*'){
if (s[i+1] != '*'){
// num num
// i i+1
if ((s[i] - '0') * 10 + (s[i+1] - '0') <= 26){
ans += f1(s,i+2);
}
}else {
// num *
// i i+1
if (s[i] == '1'){
ans += f1(s,i+2) * 9;
}
if (s[i] == '2'){
ans += f1(s,i+2) * 6;
}
}
}else {
if (s[i+1] != '*'){
// * num
// i i+1
if (s[i+1] <= '6'){
ans += f1(s,i+2) * 2;
}else {
ans += f1(s,i+2);
}
}else {
// * *
// i i+1
ans += f1(s,i+2) * 15;
}
}
}
return ans % MOD;
}
// 记忆化
public static int numDecodings2(String str){
char[] s = str.toCharArray();
long[] dp = new long[s.length];
Arrays.fill(dp,-1);
return (int) f2(s,0,dp);
}
// 记忆化
private static long f2(char[] s, int i, long[] dp) {
if (i == s.length){
return 1;
}
if (s[i] == '0'){
return 0;
}
if (dp[i] != -1){
return (int) dp[i];
}
long ans = f2(s,i+1,dp) * (s[i] == '*' ? 9 : 1);
// 3) i i+1 一起转
if (i + 1 < s.length){
if (s[i] != '*'){
if (s[i+1] != '*'){
// num num
// i i+1
if ((s[i] - '0') * 10 + (s[i+1] - '0') <= 26){
ans += f2(s,i+2,dp);
}
}else {
// num *
// i i+1
if (s[i] == '1'){
ans += f2(s,i+2,dp) * 9;
}
if (s[i] == '2'){
ans += f2(s,i+2,dp) * 6;
}
}
}else {
if (s[i+1] != '*'){
// * num
// i i+1
if (s[i+1] <= '6'){
ans += f2(s,i+2,dp) * 2;
}else {
ans += f2(s,i+2,dp);
}
}else {
// * *
// i i+1
ans += f2(s,i+2,dp) * 15;
}
}
}
ans %= MOD;
dp[i] = ans;
return ans;
}
// 自底向顶的动态规划
public static int numDecodings3(String str){
char[] s = str.toCharArray();
int n = s.length;
long[] dp = new long[n+1];
dp[n] = 1;
for (int i = n-1; i >= 0; i--) {
if (s[i] != '0'){
dp[i] = dp[i+1] * (s[i] == '*' ? 9 : 1);
if (i + 1 < n) {
if (s[i] != '*') {
if (s[i + 1] != '*') {
// num num
// i i+1
if ((s[i] - '0') * 10 + (s[i + 1] - '0') <= 26) {
dp[i] += dp[i + 2];
}
} else {
// num *
// i i+1
if (s[i] == '1') {
dp[i] += dp[i + 2] * 9;
}
if (s[i] == '2') {
dp[i] += dp[i + 2] * 6;
}
}
} else {
if (s[i + 1] != '*') {
// * num
// i i+1
if (s[i + 1] <= '6') {
dp[i] += dp[i + 2] * 2;
} else {
dp[i] += dp[i + 2];
}
} else {
// * *
// i i+1
dp[i] += dp[i + 2] * 15;
}
}
}
dp[i] %= MOD;
}
}
return (int) dp[0];
}
// 空间压缩
public static int numDecodings4(String str){
char[] s = str.toCharArray();
int n = s.length;
long cur = 0, next = 1, nextNext = 0;
for (int i = n-1; i >= 0 ; i--) {
if (s[i] != '0') {
cur = next * (s[i] == '*' ? 9 : 1);
if (i + 1 < n) {
if (s[i] != '*') {
if (s[i + 1] != '*') {
// num num
// i i+1
if ((s[i] - '0') * 10 + (s[i + 1] - '0') <= 26) {
cur += nextNext;
}
} else {
// num *
// i i+1
if (s[i] == '1') {
cur += nextNext * 9;
}
if (s[i] == '2') {
cur += nextNext * 6;
}
}
} else {
if (s[i + 1] != '*') {
// * num
// i i+1
if (s[i + 1] <= '6') {
cur += nextNext * 2;
} else {
cur += nextNext;
}
} else {
// * *
// i i+1
cur += nextNext * 15;
}
}
}
cur %= MOD;
}
nextNext = next;
next = cur;
cur = 0;
}
return (int) next;
}
}5. 264. 丑数 II
5.1 思路
最暴力直接的方法就是从1开始,对每一个数字判断其的质因子是否是2、3、5。
对于遍历每一个数字,我们可以尝试求出下一个丑数是多少。
从1开始,分别乘以2、3、5,得2、3、5,其中最小的是2。则下一个丑数是2。
2 分别乘以2、3、5,得4、6、10,包括之前的乘法得出的结果,最小的是3。
3 分别乘以2、3、5,得6、9、15,包括之前的乘法得出的结果,最小的是4。
在此基础上我们可以改进。
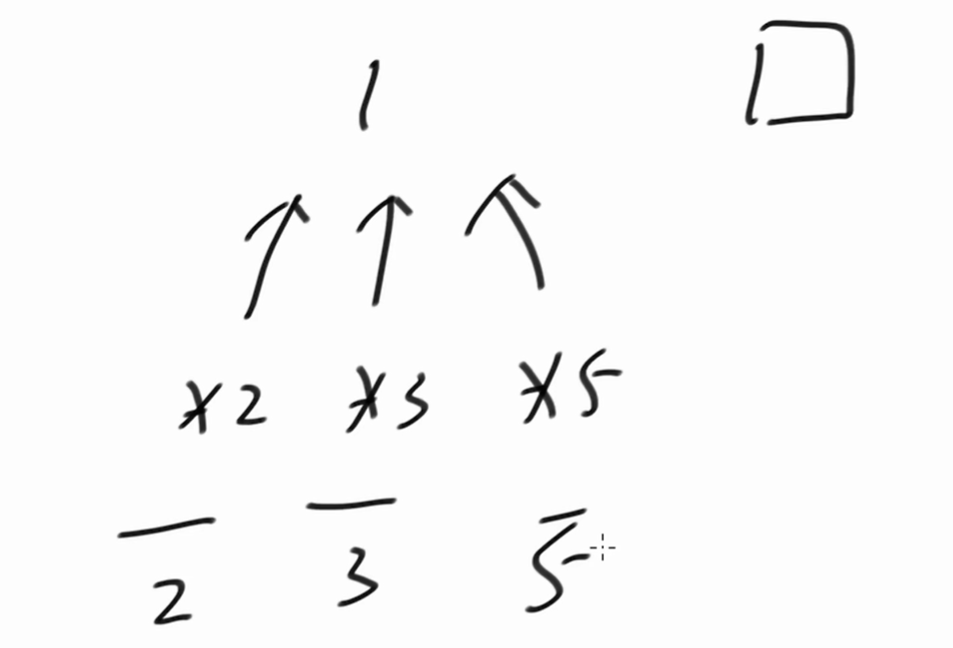
准备三个指针,* 2、* 3、 * 5。它们最初都指向1。
1* 2 = 2、1 * 3 = 3、1 * 5 = 5。
2 最小,因此下一个丑数是2。然后 * 2指针向后移动。
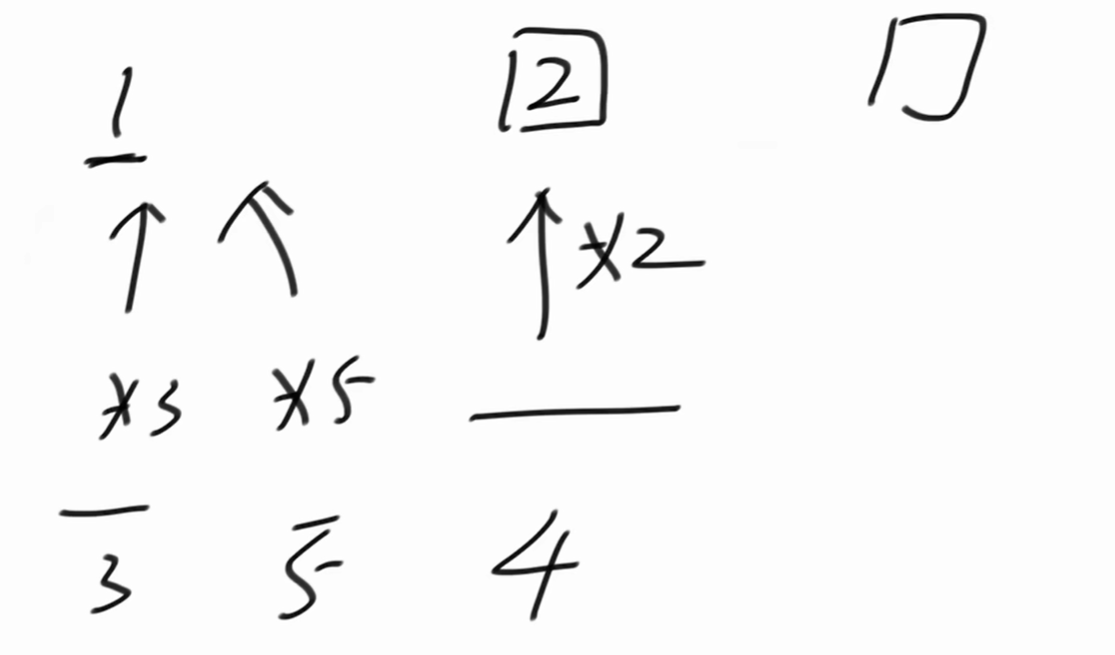
上面三个指针所计算出来的数字,3最小,下一个丑数是3。* 3指针向后移动。
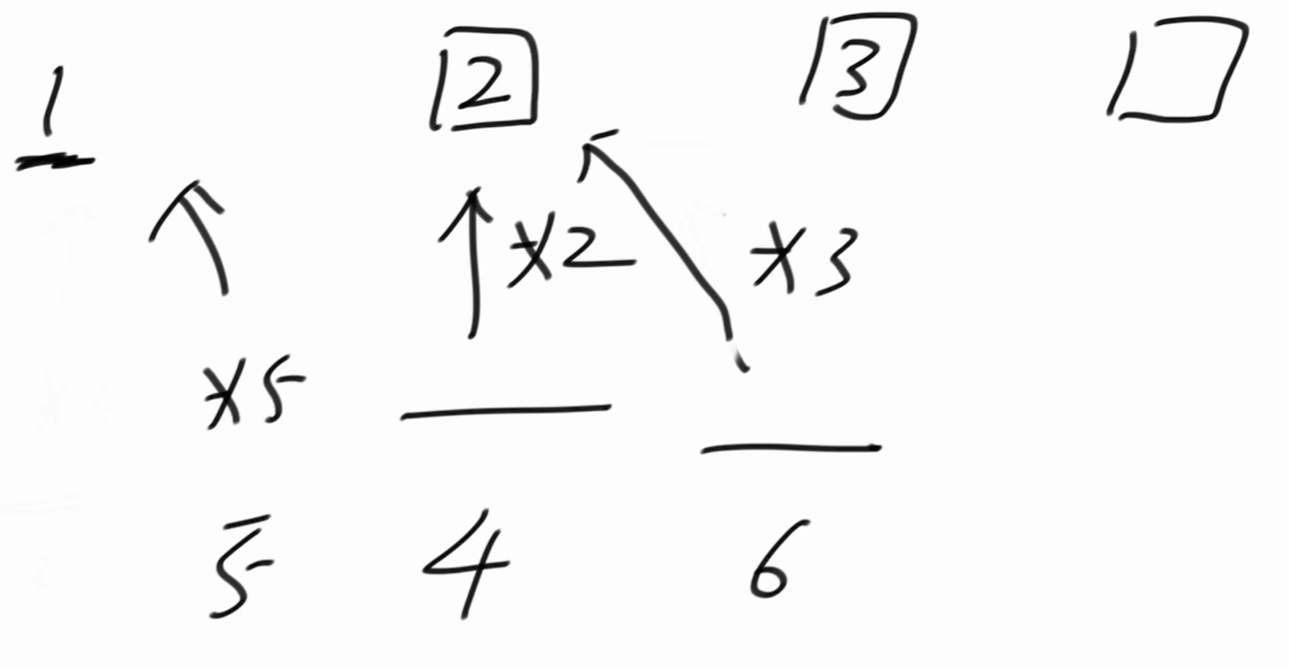
下一个丑数是4,* 2指针向后移动。
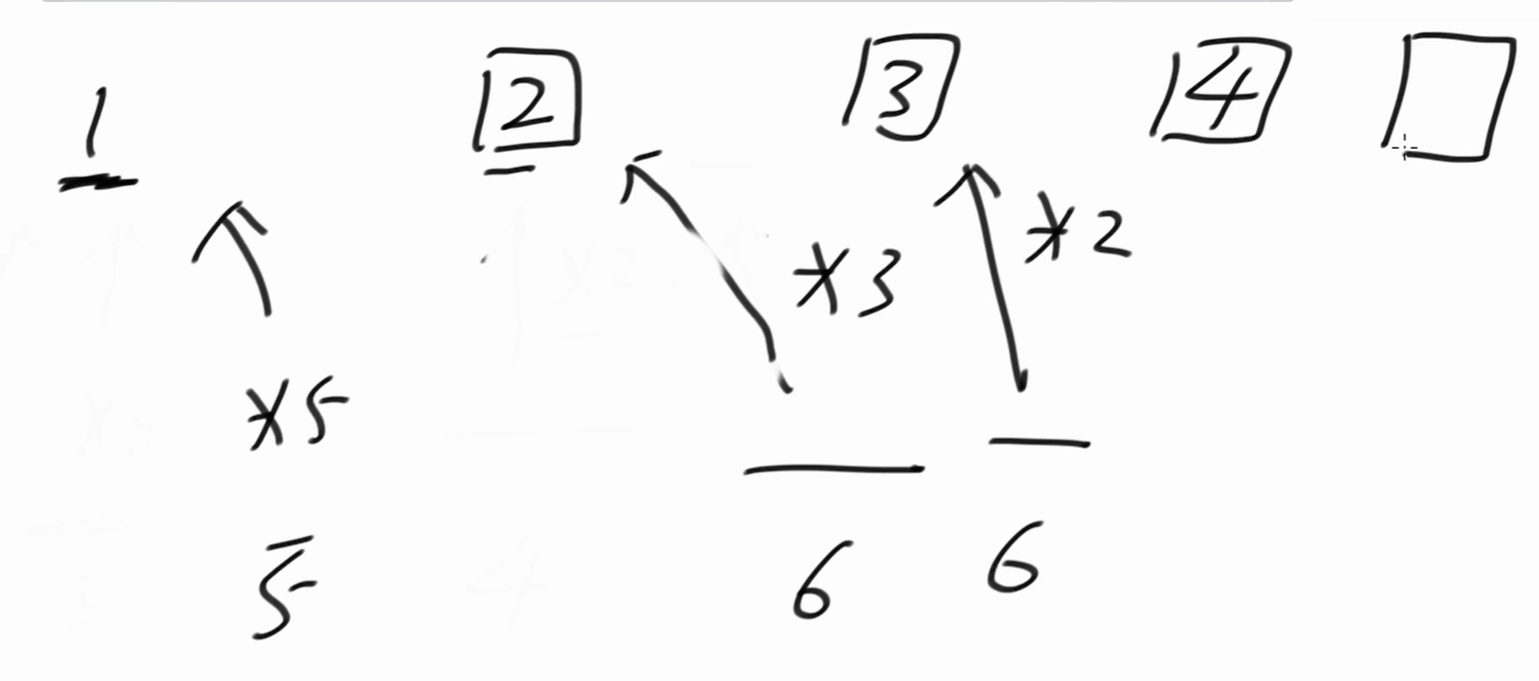
下一个丑数是5,* 5指针向后移动。
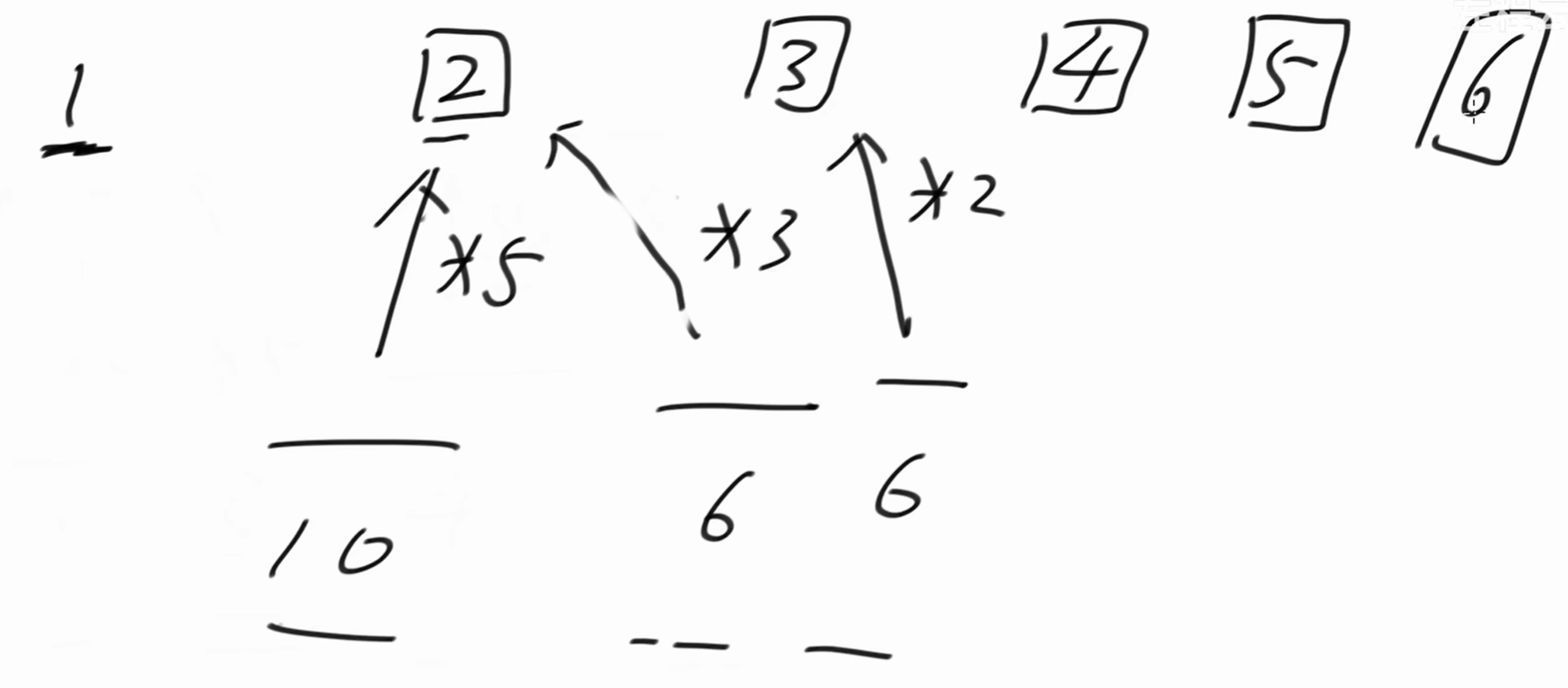
下一个丑数是6,* 2、* 3指针都向后移动。

5.2 代码
java
/**
* @Title: NthUglyNumber
* @Author Wood
* @Package leetcode.DynamicProgramming.class66.lc264
* @Date 2025/4/9 17:14
* @description: https://leetcode.cn/problems/ugly-number-ii/
*/
public class NthUglyNumber {
public int nthUglyNumber(int n) {
int[] dp = new int[n+1];
dp[1] = 1;
for (int i = 2,i2 = 1,i3 = 1, i5 = 1; i <= n; i++) {
int a = dp[i2] * 2;
int b = dp[i3] * 3;
int c = dp[i5] * 5;
int cur = Math.min(a,Math.min(b,c));
if (cur == a){
i2++;
}
if (cur == b){
i3++;
}
if (cur == c){
i5++;
}
dp[i] = cur;
}
return dp[n];
}
}6. 32. 最长有效括号
6.1 思路
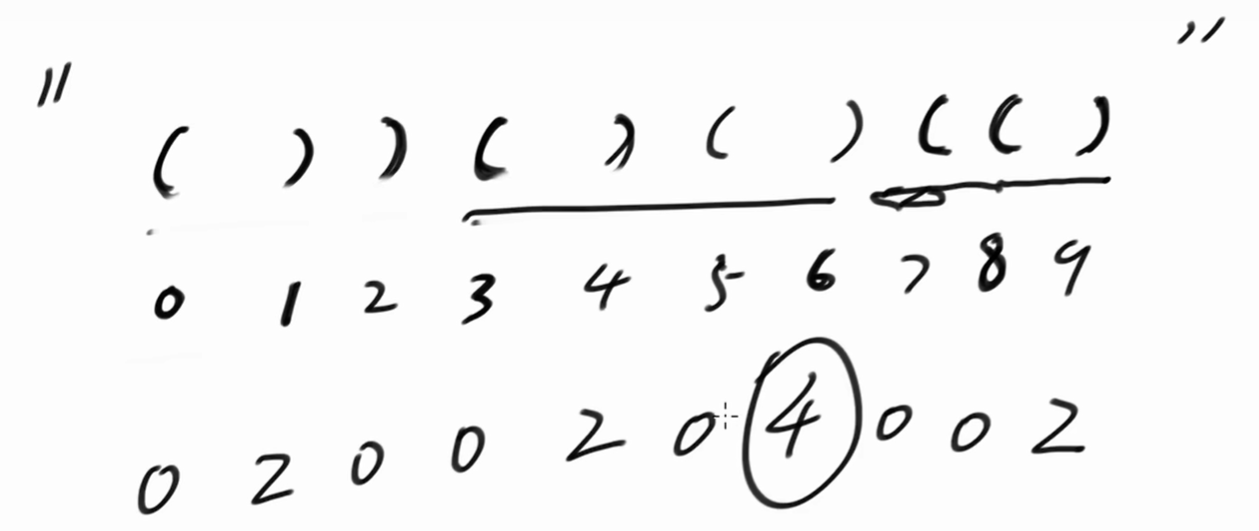
i 从字符串的索引0开始,从 i 位置 往左看,其有效的括号长度。
i = 0,是左括号,长度为0。
i = 1,是右括号,向左看能形成一个有效括号,长度为2。
i = 2,是右括号,但其左边还是个右括号,长度为0。
i = 3,是左括号,长度为0。
i = 4,是右括号,向左看能形成一个有效括号,长度为2。
i = 5,是左括号,长度为0。
i = 6,是右括号,向左看能形成两个有效括号,长度为4。
以此类推,返回最长长度4。
动态规划的含义也就出来了,dpi 代表子串以 i 位置结尾,往左最多推多远能整体有效。
我们按照上面的流程求出dp表中每个位置的答案,然后再求dp表中的max,这个就是结果。
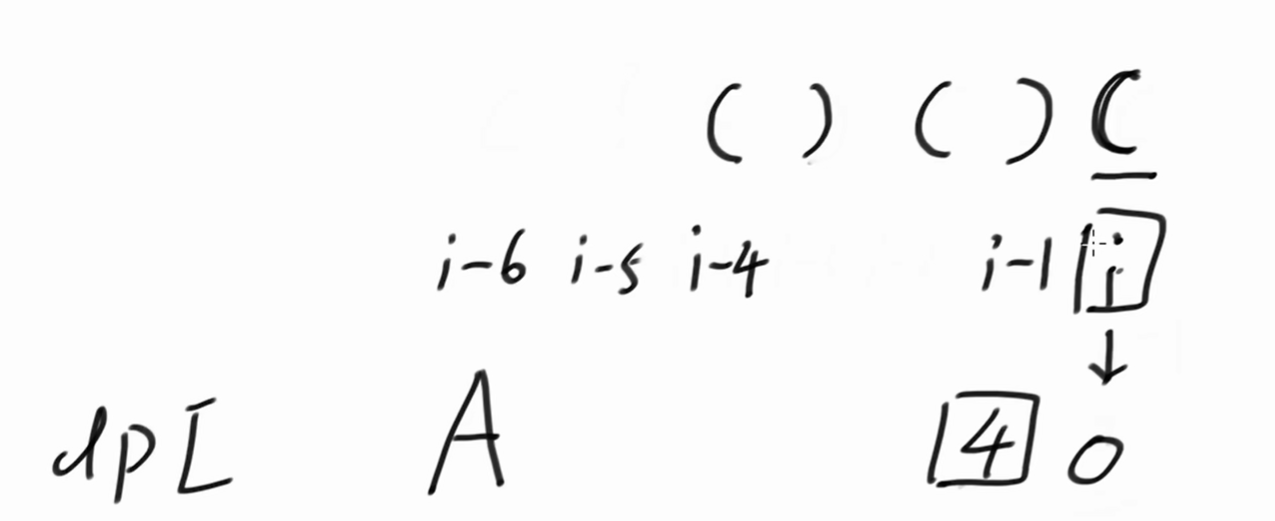
我们求 dpi 的时候,证明 i 之前的位置,都得出结果了。
如果 i 位置是左括号,直接返回0即可。dpi 之前的数值有跟没有都无所。
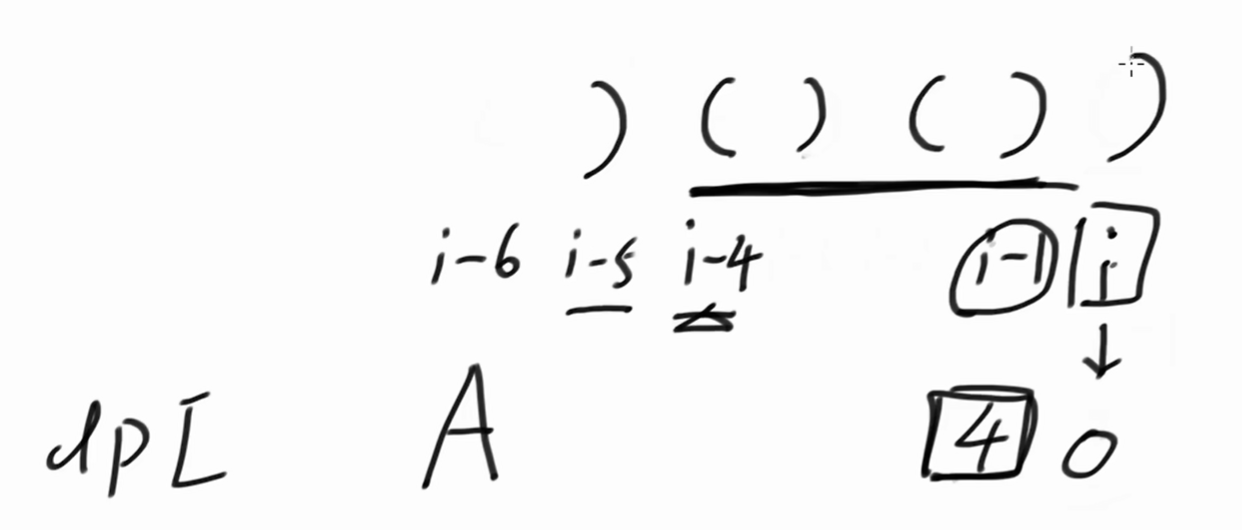
i 位置是右括号的话,看 dpi-1 = 4。证明 i - 4 到 i - 1 都是有效括号。
看 i - 5 位置,如果 i - 5 上是右括号,说明不能配对,dpi = 0。
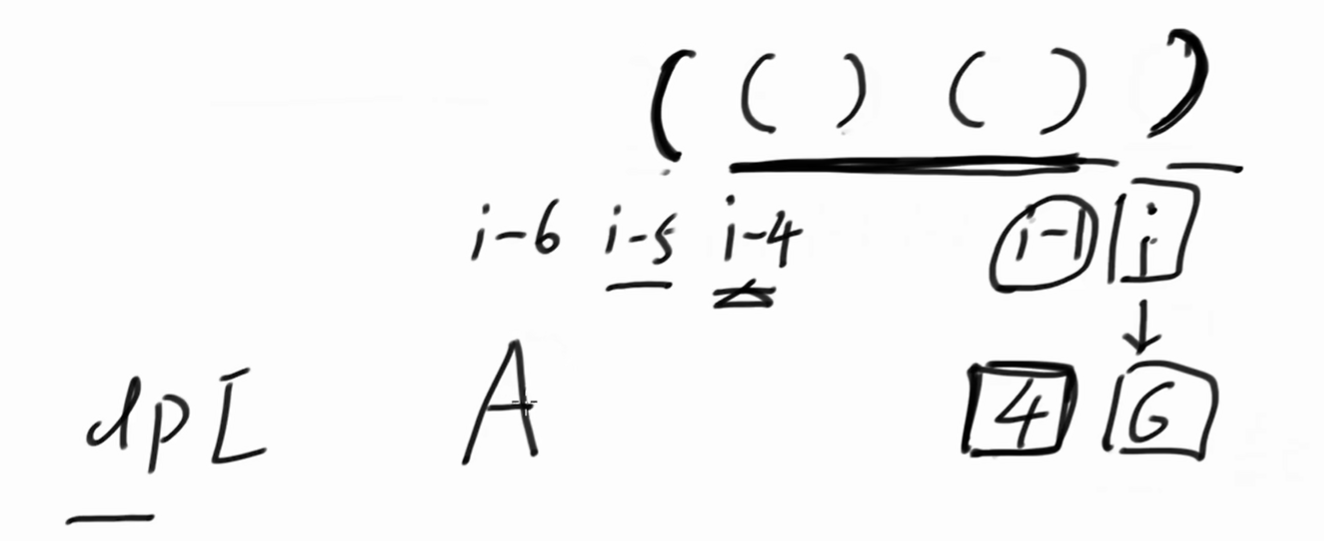
如果 i - 5 上是右括号,说明可以配对,dpi 至少是 6。即dpi-1 + 2 = 4 + 2 = 6。
为什么说至少是6?因为我们目前并不清楚 dpi-6 是多少。
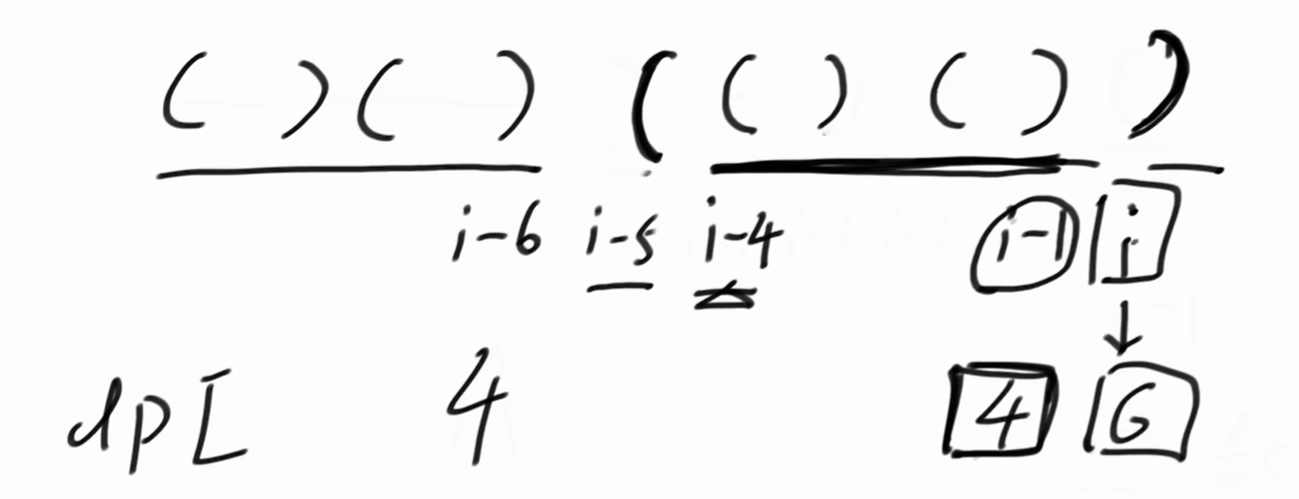
如果dpi - 6 = 4,那么dpi = 10。
这个时候不用再往i - 9前看了,因为dpi-6 就是 i - 6 往左最多推多远能整体有效的数值。
过程详解

索引0 与 索引 1都是左括号,dp0 = 0,dp1 = 0。
i = 2时,是右括号。dpi-1 = 0。那么p位置就是 i位置往前跳0个,再跳1个,即 p = 1。而p位置是左括号,相当于中了图上 2 -> b分支。
那么dpi = dp2 = dpi-1 + 2 + dpp-1 = 0 + 2 + 0 = 2。

i = 3,是左括号,dp3 = 0。
i = 4,是右括号,dpi-1 = dp3 = 0,p位置 是 i位置往前跳0个,再跳1个,即 p = 3。
p 位置是 左括号,满足2 -> b分支。
dp4 = dpi-1 + 2 + dpp-1 = 0 + 2 + 2 = 4。

i = 5,是右括号。
dpi-1 = 4,p = 0。p 是 左括号,满足 2 -> b分支。
dp5 = dpi-1 + 2 + dpp-1 = dp4 + 2 + dp-1 = 4 + 2 + 0 = 6。
p - 1 = -1 不存在,所以dp-1 直接返回0。







6.2 代码
java
/**
* @Title: LongestValidParentheses
* @Author Wood
* @Package leetcode.DynamicProgramming.class66.lc32
* @Date 2025/4/9 19:30
* @description: https://leetcode.cn/problems/longest-valid-parentheses/
*/
public class LongestValidParentheses {
public int longestValidParentheses(String str) {
char[] s = str.toCharArray();
int[] dp = new int[s.length];
int ans = 0;
for (int i = 1,p; i < s.length; i++) {
if (s[i] == ')'){
p = i - dp[i-1] - 1;
if (p >= 0 && s[p] == '('){
dp[i] = dp[i-1] + 2 + (p-1>=0 ? dp[p-1] : 0);
}
}
ans = Math.max(ans,dp[i]);
}
return ans;
}
}7. 467. 环绕字符串中唯一的子字符串
7.1 思路
java
s: "zabpxyzab"
base: "ab...xyzabcd" 以 'a' 结尾的 s 的子串,在base中出现的最长子串:'xyza' ,长度为4。(不用再看 'za' 了,长度长的一定包含长度短的)
以 'b' 结尾:'xyzab' 长度为5
以 'p' 结尾:'p' 长度为1
以 'z' 结尾:'xyz' 长度为3
以 'y' 结尾:'xy' 长度为2
以 'x' 结尾:'x' 长度为1
最大长度是用来去重的。每个长度累加的结果就是返回值。
具体操作
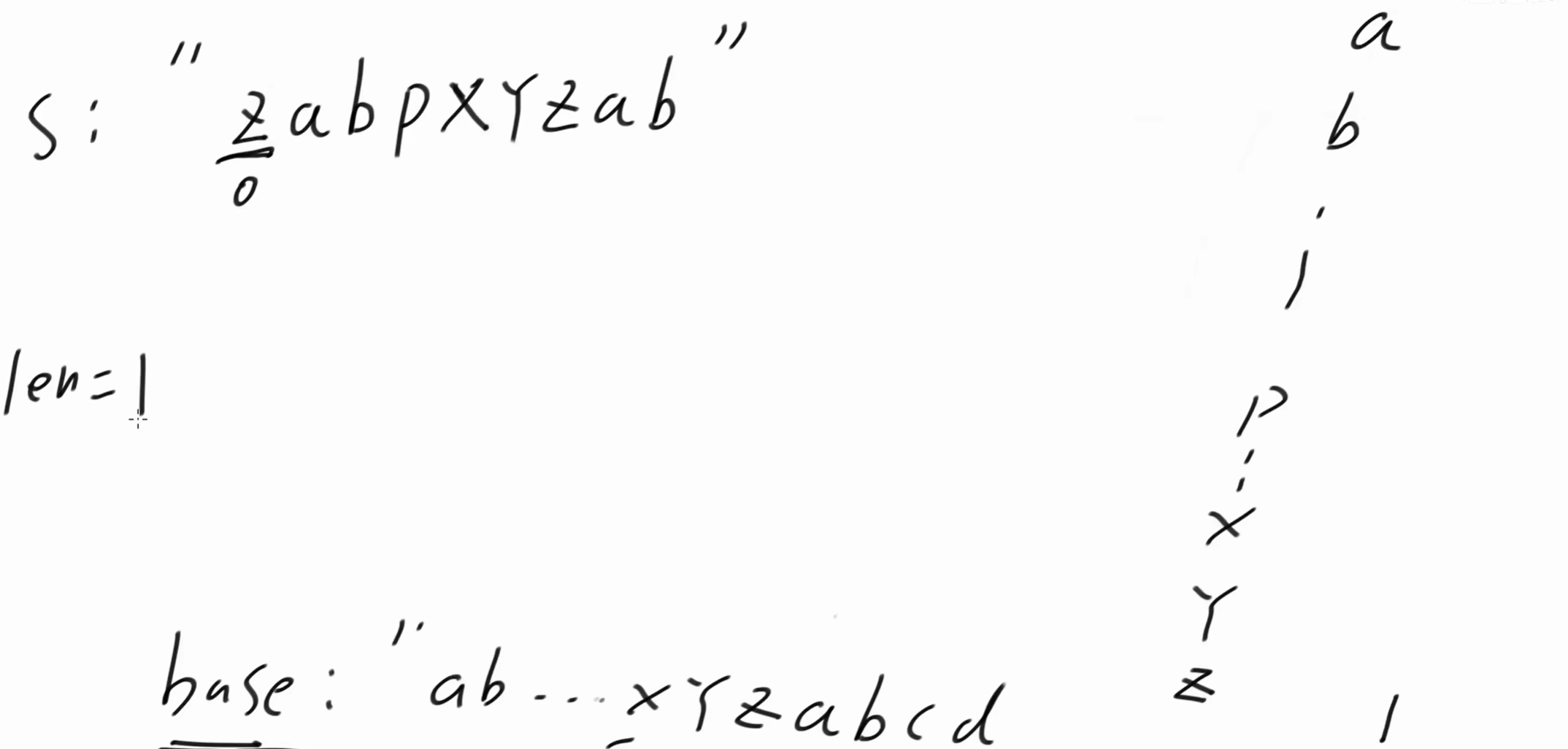
s 的 0位置 是 'z' , z 向左不能延伸,len = 1 。dp'z' = 1。
len代表当前字符能向左延伸的最长长度,dp记录的是每个字符向左延伸的最长长度。
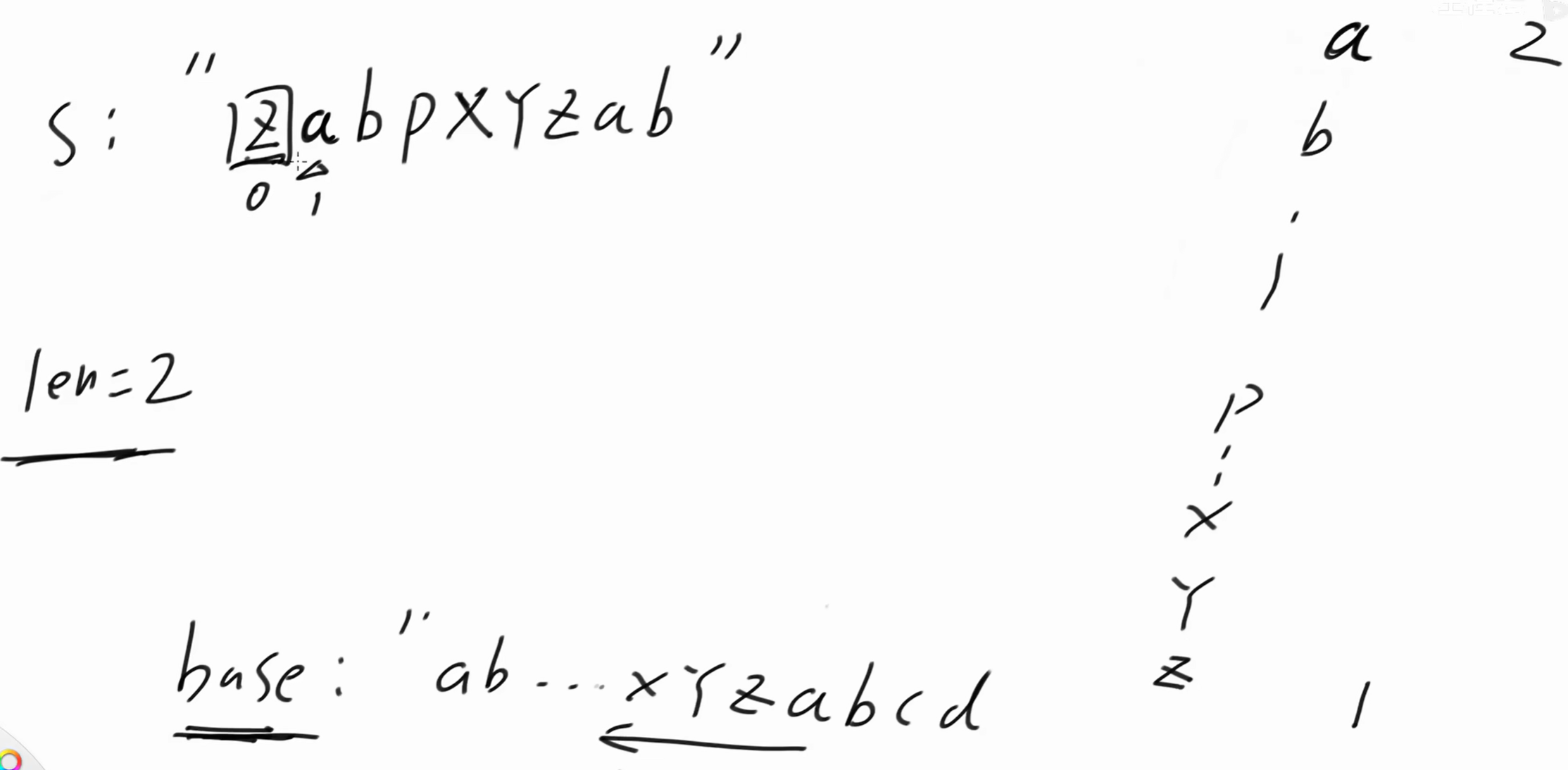
1位置是 'a' ,a 前面是 z ,以 a 结尾子串向左延伸的最长长度为2,len = 2,dp'a' = 2。
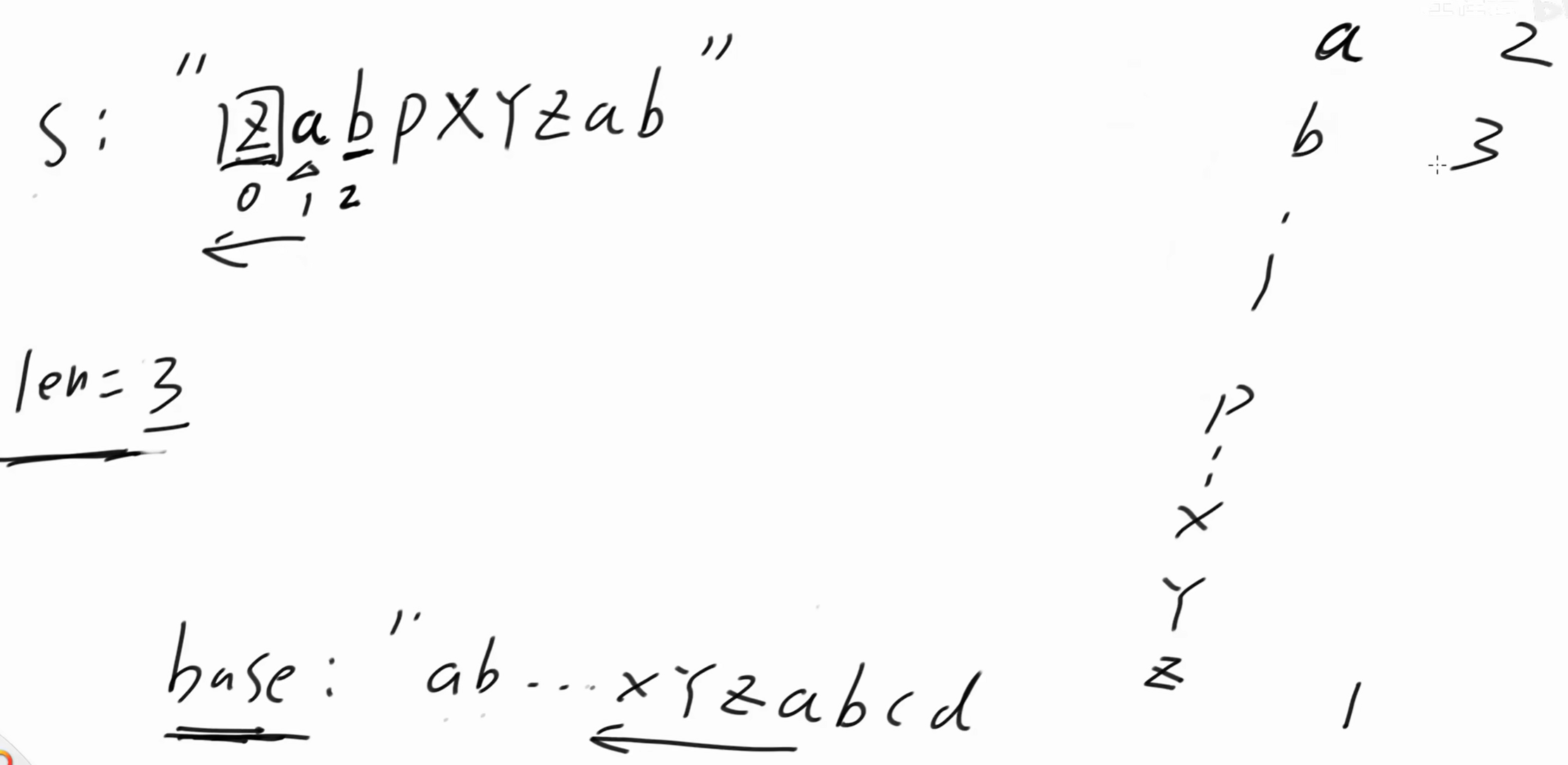
2位置是 'b' ,b 前面是 a ,以 b 结尾子串向左延伸的最长长度为3,len = 3,dp'b' = 3。
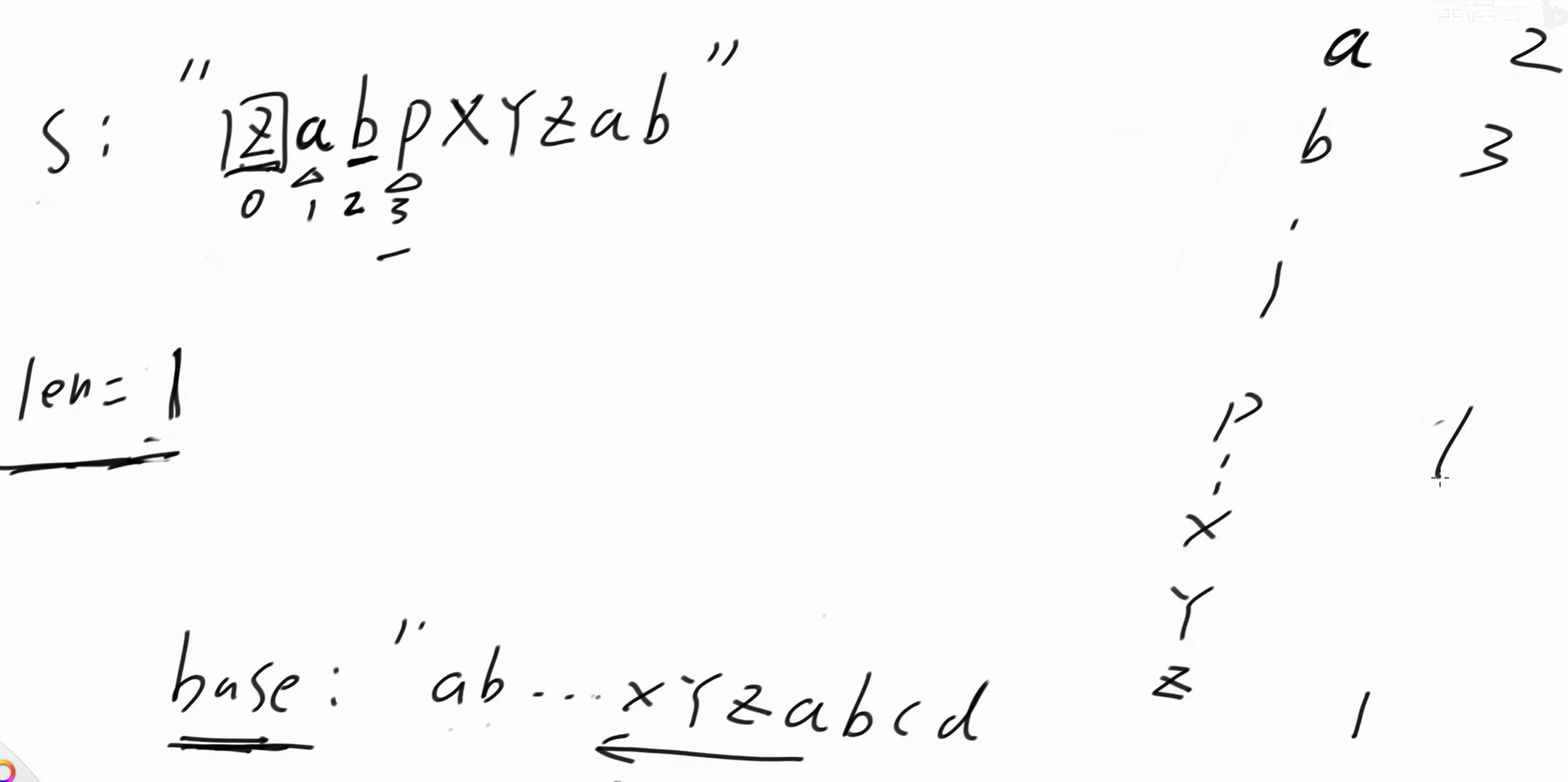
3位置是 'p' ,p 前面是 b ,而在base串中p 前面不应该是 b 。以 p 结尾子串向左延伸的最长长度为1,len = 1,dp'p' = 1。

4 位置是 'x',len = 1,dp'p' = 1。
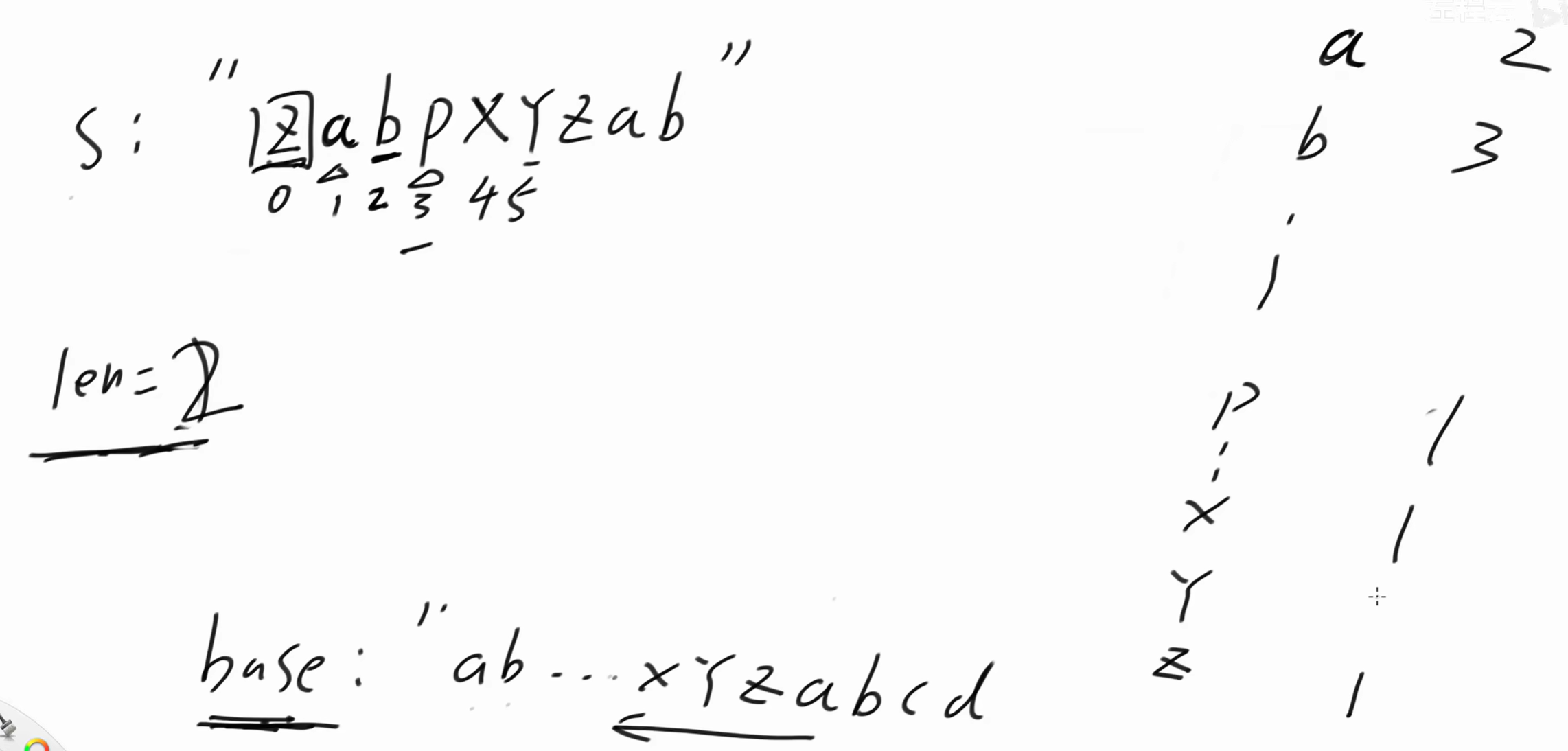
5 位置是 'y',len = 2,dp'y' = 2。
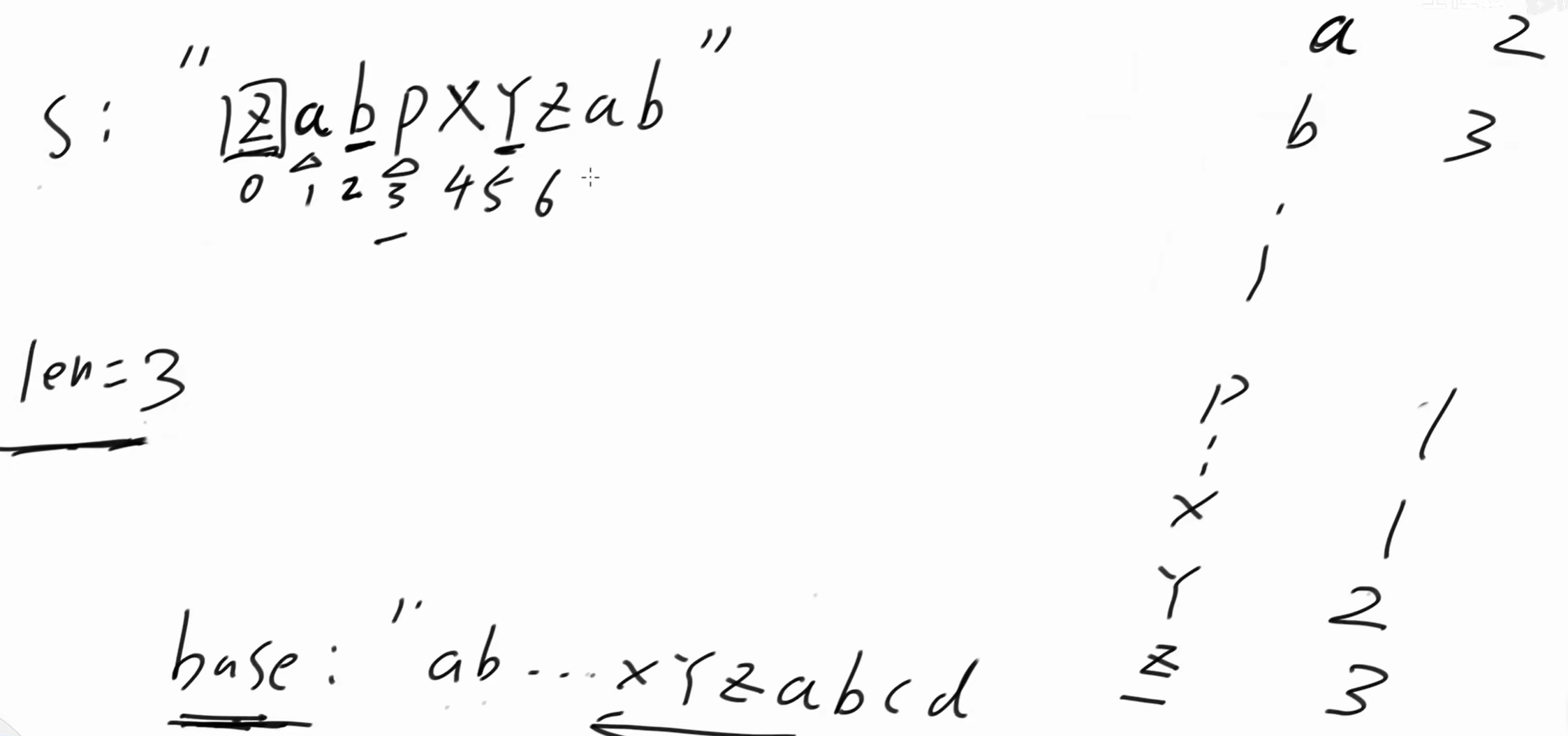
6 位置是 'z' , 'z' 前面是**'y'**,我们可以复用dp'y'的结论。len =dp'y' + 1 = 2 + 1 = 3,dp'z' = 3。

7 位置是 'a' , 'a' 前面是**'z'**,我们可以复用dp'z'的结论。len =dp'z' + 1 = 3 + 1 = 4,dp'a' = 4。
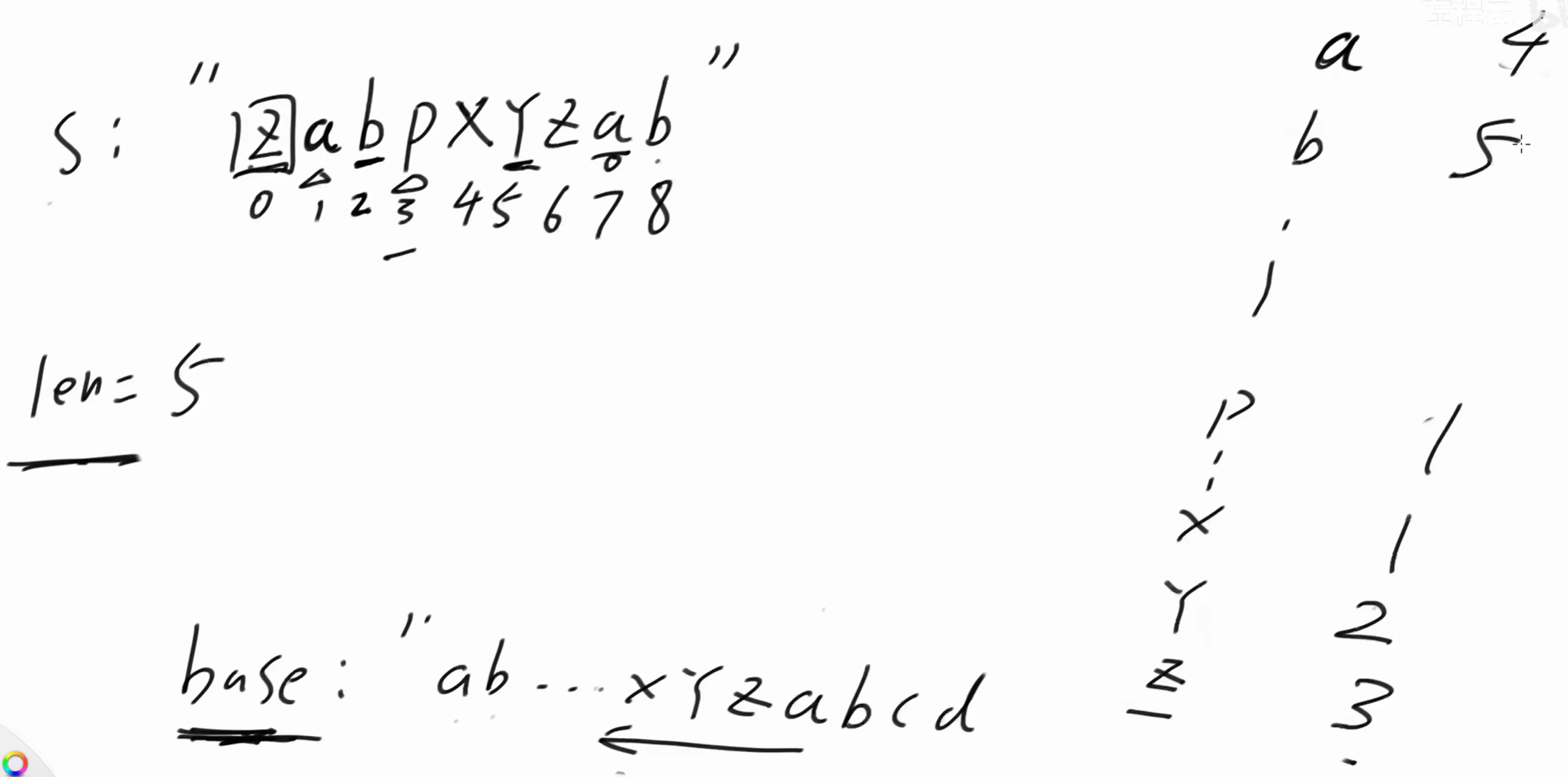
8 位置是 'b' , 'b' 前面是**'a'**,我们可以复用dp'a'的结论。len =dp'a' + 1 = 4 + 1 = 5,dp'b' = 5。
7.2 代码
java
public int findSubstringInWraproundString(String str) {
int n = str.length();
int[] s = new int[n];
for (int i = 0; i < n; i++) {
s[i] = str.charAt(i) - 'a'; // 将字符转换成数字
}
// 记录26个字母中以每个字符作结尾延伸的最长长度
int[] dp = new int[26];
// 第一个字符的长度初始值一定为1
dp[s[0]] = 1;
for (int i = 1,cur,pre,len = 1; i < n; i++) {
cur = s[i];
pre = s[i-1];
if ((pre == 25 && cur == 0) || pre + 1 == cur){
len++;
}else {
len = 1;
}
dp[cur] = Math.max(dp[cur],len);
}
int ans = 0;
for (int i = 0; i < 26; i++) {
ans += dp[i];
}
return ans;
}8. 940. 不同的子序列 II
8.1 思路
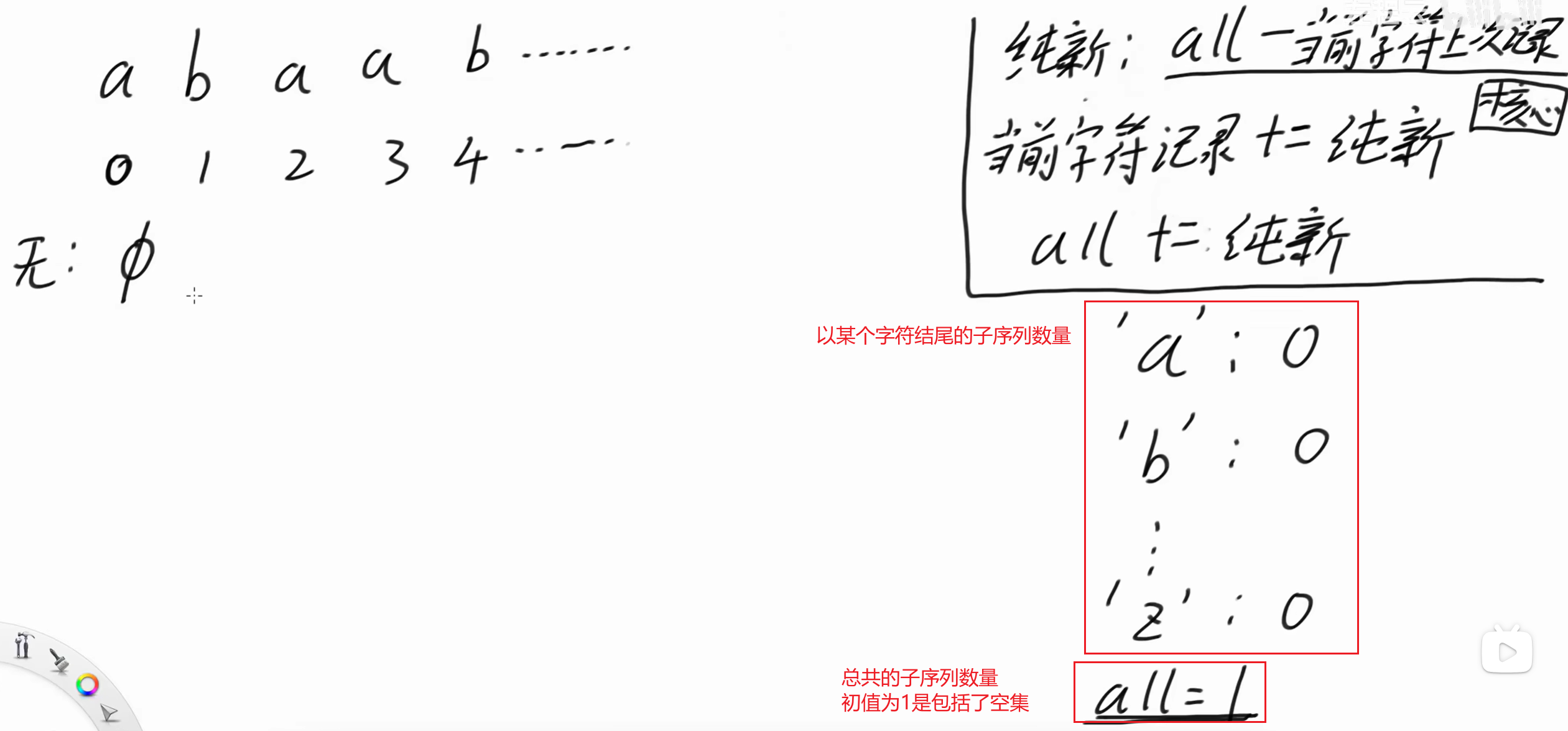

0位置是a,我们的操作是 保留之前的子序列,并将 a 加到之前的子序列后面。
之前的子序列是空集,所以 0 位置的子序列为 {}、{a}
以 'a' 为结尾的子序列数量 = 1。
all = 2( {}、{a})

1位置是b,保留之前的子序列,并将 b 加到之前的子序列后面。
所以 1 位置的子序列为 {}、{a}、{b}、{a,b}
以 'b' 为结尾的子序列数量 = 2。
all = 4
解释一下右上角的规则(看本次修改前的记录):
纯新增的字符 = all - 当前字符('b') 上次的记录 = 2 - 0 = 2。(纯新增的字符是**{b}、{a,b}**)
当前字符的记录(也就是b的记录) = 之前的记录 + 纯新增的字符 = 0 + 2 = 2
all 之前是2,加上新增字符个数,all = 2 + 2 = 4

2位置是'a',按照之前的操作,我们可以看到{a} 重复了。
按照右上角的规则:
纯新增的字符 = all - 当前字符上次的记录(a) = 4 - 1 = 3
所以新增了3个
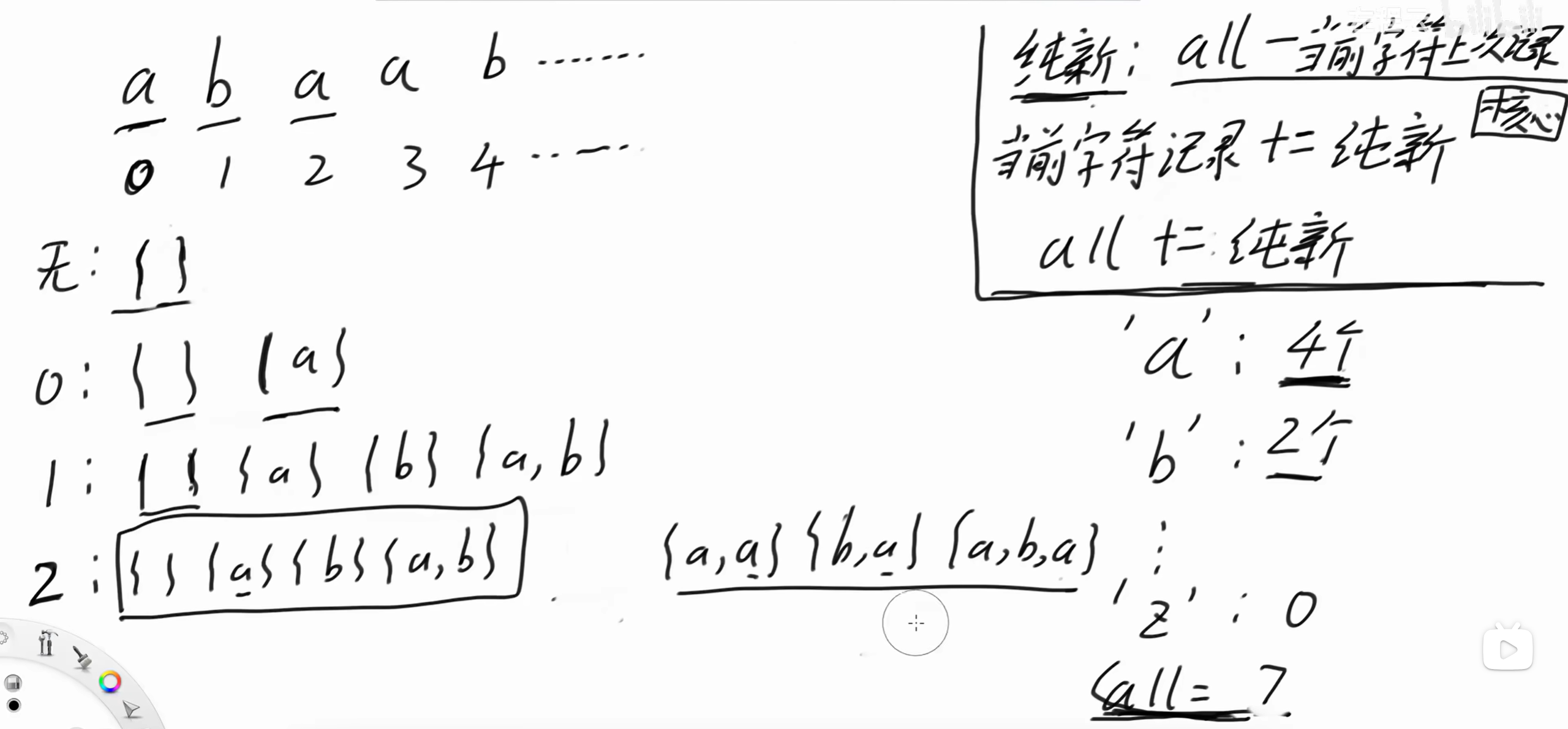
更改当前字符记录(a) = 1 + 3 = 4
all = 4 + 3 = 7


8.2 代码
java
public int distinctSubseqII(String str) {
int mod = 1000000007;
char[] s = str.toCharArray();
// 记录a-z中为结尾字符的子序列数量
int[] cnt = new int[26];
int all = 1,newAdd = 0;
for (char c : s) {
newAdd = (all - cnt[c - 'a'] + mod) % mod;
cnt[c-'a'] = (cnt[c-'a'] + newAdd) % mod;
all = (all + newAdd) % mod;
}
return (all -1 + mod) % mod;
}284605611)]
0位置是a,我们的操作是 保留之前的子序列,并将 a 加到之前的子序列后面。
之前的子序列是空集,所以 0 位置的子序列为 {}、{a}
以 'a' 为结尾的子序列数量 = 1。
all = 2( {}、{a})
外链图片转存中...(img-aqx2hv6r-1744284605611)
1位置是b,保留之前的子序列,并将 b 加到之前的子序列后面。
所以 1 位置的子序列为 {}、{a}、{b}、{a,b}
以 'b' 为结尾的子序列数量 = 2。
all = 4
解释一下右上角的规则(看本次修改前的记录):
纯新增的字符 = all - 当前字符('b') 上次的记录 = 2 - 0 = 2。(纯新增的字符是**{b}、{a,b}**)
当前字符的记录(也就是b的记录) = 之前的记录 + 纯新增的字符 = 0 + 2 = 2
all 之前是2,加上新增字符个数,all = 2 + 2 = 4
外链图片转存中...(img-2TL3sQAi-1744284605611)
2位置是'a',按照之前的操作,我们可以看到{a} 重复了。
按照右上角的规则:
纯新增的字符 = all - 当前字符上次的记录(a) = 4 - 1 = 3
所以新增了3个
外链图片转存中...(img-G9wJXr7K-1744284605611)
更改当前字符记录(a) = 1 + 3 = 4
all = 4 + 3 = 7
外链图片转存中...(img-y0tSvpOM-1744284605611)
外链图片转存中...(img-Ttc4FFnN-1744284605611)
8.2 代码
java
public int distinctSubseqII(String str) {
int mod = 1000000007;
char[] s = str.toCharArray();
// 记录a-z中为结尾字符的子序列数量
int[] cnt = new int[26];
int all = 1,newAdd = 0;
for (char c : s) {
newAdd = (all - cnt[c - 'a'] + mod) % mod;
cnt[c-'a'] = (cnt[c-'a'] + newAdd) % mod;
all = (all + newAdd) % mod;
}
return (all -1 + mod) % mod;
}