编写Hadoop集群启停脚本
1.建立新文件,编写脚本程序
在hadoop101中操作,在/root/bin下新建文件:myhadoop,输入如下内容: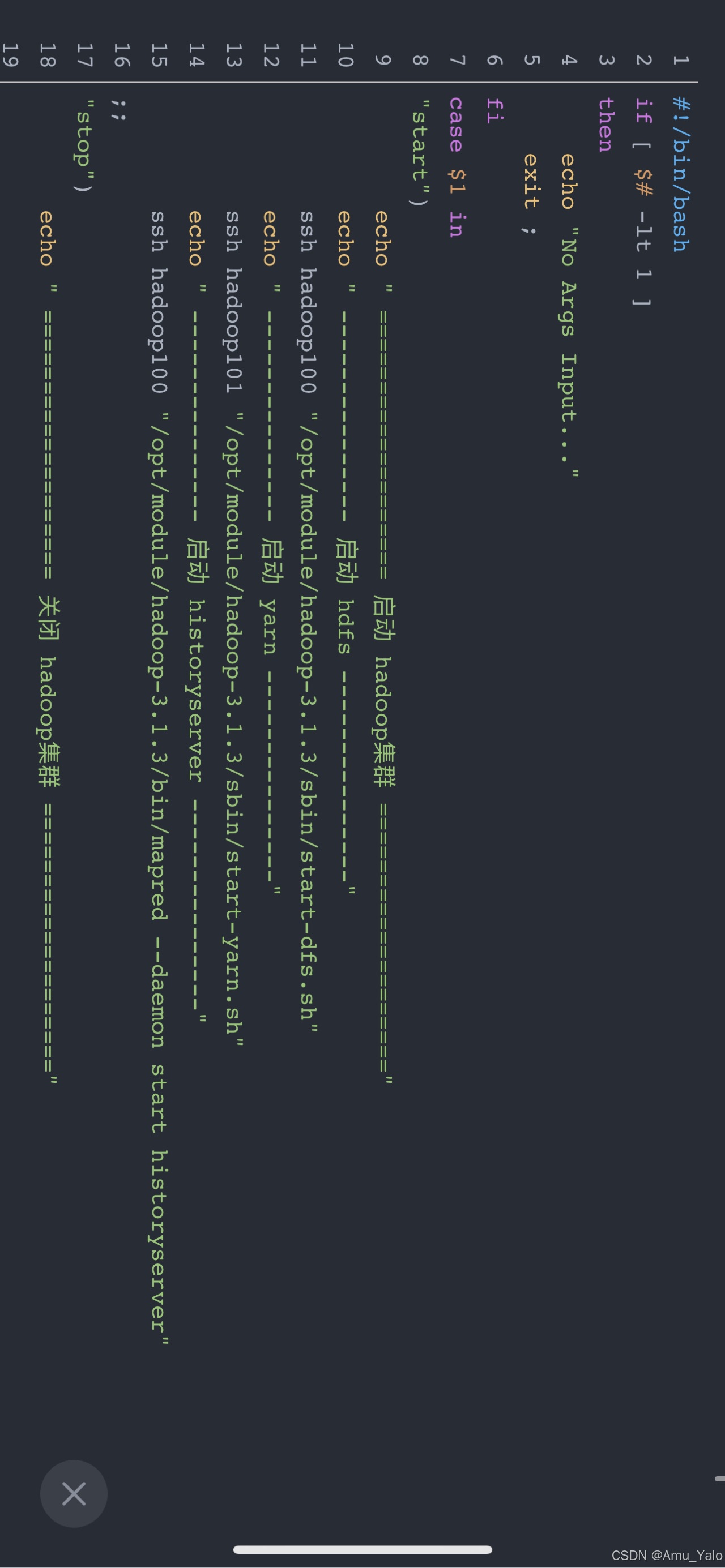

2.分发执行权限
保存后退出,然后赋予脚本执行权限
root@hadoop101 \~$ chmod +x /root/bin/myhadoop
像下图这样查看显示绿色即代表成功!
3.分发脚本
root@hadoop101 \~$ xsync /root/bin/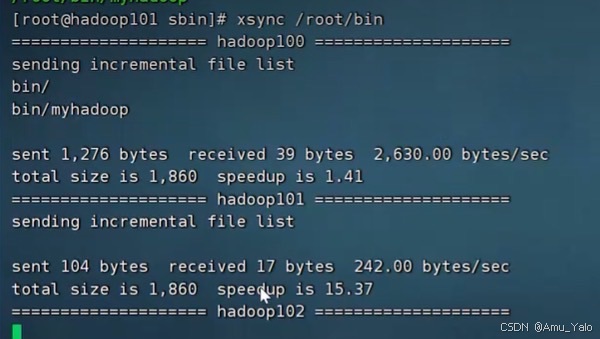
4.测试执行
分配完成后可在其他设备上关闭myhadoop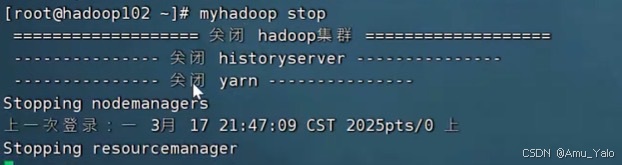
启动命令:root@hadoop100 sbin# myhadoop start
关闭命令:root@hadoop100 sbin# myhadoop stop