在一长串努力的基础上,现在我们应该可以构建较为完整的数据预处理到分析的流程了。下面我们从单容器开始,逐步构建集群化的数据处理分析环境------当然这个环境仍然是初步的,我们暂时还只能将其限制在对pcap文件的批量导入处理上。毕竟,还有好多东西我们尚未涉足。
一、构建单一容器
在CENTOS上的网络安全工具(二十六)SPARK+NetSA Security Tools容器化部署(2)中,我们构建的pig/silk:dpi镜像,实际只是将yaf、super_mediator等工具安装在了一个容器中,并没有进行合理的配置,所以每次使用时我们都需要从命令行手工执行yaf及super_mediator的命令,并不可避免的要设置复杂、难以记忆的命令集。所以,如果能够构建一个工具容器镜像,把一切都设置好,我们只需要把待处理的文件放在指定的位置就行,那样就方便多了。
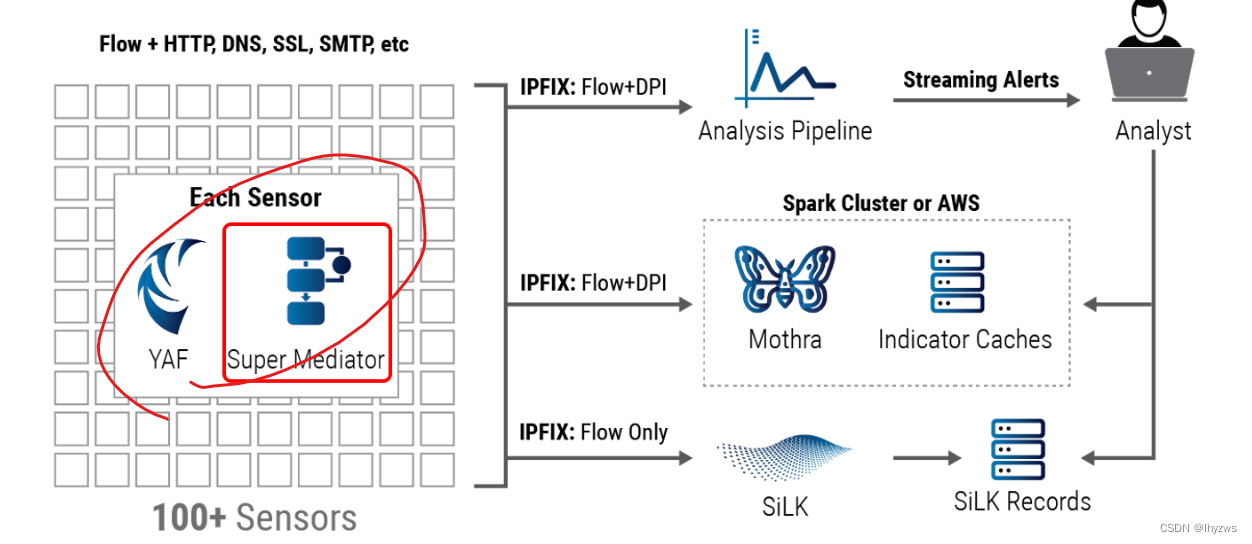
我们要实现的,仍是官网图示中的传感器部分,主要包括两个组件:yaf和super_mediator,yaf负责读取指定位置的输入pcap文件,完成协议解析、IE(Information Element,官方用语,信息要素,可以理解为协议元数据、协议字段)提取后,转化为流文件输出给super_mediator;super_mediator完成IP fix转化并分发------在单容器中,我们指将输出结果存放到指定文件夹。
1. 相关命令及参数使用
(1)super_mediator
首先我们需要构建的是super_mediator服务,其主要作用是在主机的指定端口上监听yaf处理结果,并将其转化为ipfix格式文件向指定文件夹输出。我们用到的参数的含义,官方的详细指南可参考super_mediator --- Super Mediator: Documentation (cert.org),我们也曾在CENTOS上的网络安全工具(二十五)SPARK+NetSA Security Tools容器化部署(1)中给出过简单的介绍。在经过好几篇的尝试后,应该能够体会理解得更加深刻。这里,结合具体得使用场景,再一次解释如下:
①后台执行设置
--daemonize设置该参数,指示super_mediator以后台方式执行,这样程序会在启动监听后返回命令行。在容器中,我们可以考虑依靠super_mediator挂住容器进程,可以不适用该模式。
--pidfile如果设置了daemonize模式,则需要指定保存进程pid的pid文件。貌似也可以省略。
--log在daemon模式下,必须指定log文件的输出位置,否则super_mediator会默认向stdout输出,但在daemon模式下不允许向stdout输出,所以会导致启动失败。
②输入设置
我们需要super_mediator以在线监听服务的方式运行,所以需要设置主机名(IP)、端口和协议3要素。需要注意的是,super_mediator是以" super_mediator option input "的命令行形式运行的。所以,主机名(IP)没有专门的可选参数指示,而是直接写在命令行中。
--ipfix-input指定输入模式,在线监听时,为链接的协议类型,支持tcp和udp,建议tcp
--ipfix-port结合命令行中给出的localhost,指监听地址为 localhost:18000。默认也就是18000,如果不显式指定的话。
--fields仅在super_mediator使用TEXT模式输出的时候,指定输出的IE列表。
③输出设置
--out指示输出的位置,在输出文件的情况下,这里应该设置文件的路径。进一步,因为我们设置为监听服务的形式,所以可能输出的数据量很大,应该采取循环输出的方式。那么,在循环方式下,--out指示的不仅是文件路径、文件名,而是以此为参考的模板。super_mediator会在此基础上进一步添加时间及编号信息到文件名上。
--output-mode设置输出文件的模式,一般来说有tcp、udp、text和json取值。默认情况下,不设置该参数,代表以ipfix文件的形式输出数据------这 是我们的运用场景下需要的模式。
--rotate设置该参数将指示循环模式和循环时间。系统默认循环时间为30秒。但是在input为文件的形势下,设置超长的时间可能不起作用。因为super_mediator会对应输入文件的切分方式切分输出文件。
按照上述参数设置,在容器中启动super_mediator如下:
[root@6096af498dcd data]# super_mediator --daemonize --pidfile=./sm.pid --log=./log/t.log --ipfix-input=tcp --ipfix-port=18000 --out=/data/ie-repo/ipfix --rotate=3600 localhost
[root@6096af498dcd data]# Initialization Successful, starting...
[root@6096af498dcd data]# netstat -nltp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:18000 0.0.0.0:* LISTEN 239/super_mediator 可以看到super_mediator已经在本机的18000端口上准备就绪,结果将向/data/ie-repo目录数处,文件名形式为"ipfix-时间-序号.med"。如下所示:(当然,在yaf没给输入之前,这里是不会有结果的)
[root@6096af498dcd ie-repo]# ls -l
total 7172
-rw-r--r-- 1 root root 1713736 Jul 7 14:17 ipfix-20230707141628-00000.med
-rw-r--r-- 1 root root 1376673 Jul 7 14:17 ipfix-20230707141710-00001.med
-rw-r--r-- 1 root root 1059688 Jul 7 14:17 ipfix-20230707141710-00002.med
-rw-r--r-- 1 root root 1004873 Jul 7 14:17 ipfix-20230707141710-00003.med
-rw-r--r-- 1 root root 1193706 Jul 7 14:17 ipfix-20230707141710-00004.med
-rw-r--r-- 1 root root 959598 Jul 7 14:17 ipfix-20230707141710-00005.med
-rw-r--r-- 1 root root 19827 Jul 8 03:10 ipfix-20230708030559-00000.med(2)YAF
虽然yaf支持实时数据流监听------但我们当前的场景并不涉及真的去搞个传感器,所以还是希望yaf能够以批量文件作为输入。在批量文件输入方面,yaf支持以通配符匹配和caplist方式。但通配符形式有个很不好的地方是难以控制文件输入的顺序,所以我们最终还是要选择--caplist。
另外,yaf在监听的时候可以使用--live模式,但在使用文件形式作为输入的时候,就不支持一直监听某个文件夹了(比如像super_mediator一样,使用--move参数和--polling-interval参数)。这意味着,无论如何,我们不能通过向某个目录简单存入文件,就指望容器能够在另一个目录返回我们所要的结果------我们必须在准备好数据之后,手动触发一次yaf。
比如,准备caplist:
将所有需要输入的文件拷贝到一个目录下,然后按时间序获得caplist:
[root@6096af498dcd /]# ls -1 /pcap/*
/pcap/test1.pcap
/pcap/test2.pcap
/pcap/test3.pcap
/pcap/test4.pcap
/pcap/test5.pcap记得将这个结果重定向到文件filelist中去。然后执行yaf:
[root@6096af498dcd /]# yaf --in filelist --caplist --out=localhost --ipfix=tcp --ipfix-port=18000 --pcap=/data/pcap-repo/record --max-pcap=100 --pcap-meta-file=/data/pcap-meta/meta --applabel --dpi --max-payload=4096
[2023-07-07 14:08:07] running as root in --caplist mode, but not dropping privilege
[2023-07-07 14:08:07] Rejected 257938 out-of-sequence packets.下面注意说明执行yaf时的这些参数
①输入参数
--in标识输入文件的路径
--caplist表示输入文件是待处理pcap文件的列表,否则可以是允许包含通配符的文件名。只有担当使用--live参数时,才是监听端口的形式。
--force-read-allyaf会处理所有失序包,但仍然会丢弃失序片段......不知啥意思。
②流数据输出参数
--out主机名或者文件名,这里我们打算输出给正在监听的super_mediator,所以使用主机名
--ipfix指定传输协议,一般为tcp
--ipfix-port后端处理程序super_mediator的监听端口,默认为18000
--lock表示锁定正在输出的文件(这有助于这种后面有个程序在监听的情况,可以防止文件尚未写完就被监听程序处理。不过由于我们并没有通过输出循环文件的方式连接super_mediator,所以可以不必携带该参数。更何况super_mediator对应的输入参数选项--no-locked-files,官方给出的说法是unimplemented......。
③pcap文件输出
yaf在监听网络端口或者处理pcap文件的同时,也可以输出带索引的pcap文件,这样可以方便后期使用yafmeta2pcap,从流分析结果锁定原始数据包。
--pcap=PATH指示循环pcap文件输出的目录,以及文件名模板"record",同样yaf会使用时间加序号的方式进行命名。
--max-pcap=100指循环pcap文件最大100MB。虽然也有按间隔时间分割的方式,但考虑到输入文件的不确定性,我们还是使用了大小分割方法。
--index-pcap和--pcap、--pcap-meta-file一并使用,表示需要存储流在原始数据中索引。
--pcap-meta-file指定metafile存放的目录。metafile并不大,用于存储会话流在原始数据中的索引信息,一般来说到达2GB后会被yaf截断。使用命令yafmeta2pcap时,需要提供该文件。
④DPI配置
--dpi 如果需要使用dpi信息,就需要显示指出。我们就为这个来的,当然必须得填。
--applabel一般来说指定dpi就默认指定了applabel
--map-payload默认4096为好
当然还可以使用 --dpi-select 指定需要处理的applabel类型。
在已经启动super_mediator的主机上,执行如上yaf命令,可以得到如下结果------当然最好在执行命令之前就将目录准备好:
[root@6096af498dcd /]# ls /data/* -l
/data/ie-repo:
total 7172
-rw-r--r-- 1 root root 1713736 Jul 7 14:17 ipfix-20230707141628-00000.med
-rw-r--r-- 1 root root 1376673 Jul 7 14:17 ipfix-20230707141710-00001.med
-rw-r--r-- 1 root root 1059688 Jul 7 14:17 ipfix-20230707141710-00002.med
-rw-r--r-- 1 root root 1004873 Jul 7 14:17 ipfix-20230707141710-00003.med
-rw-r--r-- 1 root root 1193706 Jul 7 14:17 ipfix-20230707141710-00004.med
-rw-r--r-- 1 root root 959598 Jul 7 14:17 ipfix-20230707141710-00005.med
-rw-r--r-- 1 root root 19827 Jul 8 03:10 ipfix-20230708030559-00000.med
/data/log:
total 4
-rw-r--r-- 1 root root 324 Jul 8 03:05 t.log
/data/pcap-meta:
total 2196
-rw-r--r-- 1 root root 2246523 Jul 7 14:17 meta20230707141709_00000.meta
/data/pcap-repo:
total 497476
-rw-r--r-- 1 root root 104859364 Jul 7 14:17 record20230707141709_00000.pcap
-rw-r--r-- 1 root root 104901974 Jul 7 14:17 record20230707141710_00001.pcap
-rw-r--r-- 1 root root 104872626 Jul 7 14:17 record20230707141710_00002.pcap
-rw-r--r-- 1 root root 104922033 Jul 7 14:17 record20230707141710_00003.pcap
-rw-r--r-- 1 root root 89852026 Jul 7 14:17 record20230707141710_00004.pcap2. 容器化处理工具
这一步,我们打算将如上的命令打包到容器中,在容器启动时镜像输入输出文件夹,并通过初始化脚本直接开始执行,这样我们就可以通过启动一个容器的方式比较方便的得到数据处理的结果了。
#! /bin/bash
#清理并构造输出文件夹
rm /output/* -rf
cd /output
mkdir ipfix
mkdir pcap-data
mkdir pcap-meta
mkdir log
#构造caplist
ls -1 /input/* > /output/filelist.txt
#刷一下环境变量,否则工具无法启动,我在这里卡好久,想当然了
source /root/.bashrc
#执行工具
cd /root
#super_mediator --log=/super_mediator.log --out=/output/ipfix/ipfix --rotate=3600 --ipfix-input=tcp --ipfix-port=18000 localhost
super_mediator --daemonize --pidfile=/output/log/super_mediator.pid \
--log=/output/log/super_mediator.log \
--out=/output/ipfix/ipfix --rotate=3600 \
--ipfix-input=tcp --ipfix-port=18000 localhost
yaf --in /output/filelist.txt --caplist --force-read-all \
--out=localhost --ipfix=tcp --ipfix-port=18000 \
--pcap=/output/pcap-data/pcap --max-pcap=100 \
--index-pcap --pcap-meta-file=/output/pcap-meta/meta \
--applabel --dpi --max-payload=4096
#去掉这一句,执行完成后,容器会自行退出
#tail -f /dev/null主要的问题是需要记住在脚本开始的时候执行以下source .bashrc;之前我们搭环境的时候,都认为dockers会自动帮助我们执行------确实也没错,只有当我们使用docker exec进入已经启动的容器时,docker会帮我们干这事(所以我每次进去检查代码时,代码都正常的一批);然而当我们使用docker run第一次启动容器的时候,docker是不会帮助我们source的------所以当我认为代码正确,直接启动容器时,容器内的工具总是不能正常执行(因为LD_LIBRARY_PATH环境变量没设,所以libpcap库就是找不到......)。
所以,一定要记得source ~/.bashrc,更新环境变量。
然后,准备好输入文件夹和输出文件夹,我们只需要把容器启动起来,然后等待它退出就可以了:
[root@pighost dpi]# docker run -itd --name pig -v /root/share/pcap:/input:ro -v /root/share/testdata:/output:rw pig/silk:dpi
6645f7a68e608bbb64b4d802ce6b026ed9bef5422e731690a93d8d37f9fcd7a1
[root@pighost dpi]#
[root@pighost dpi]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6645f7a68e60 pig/silk:dpi "/root/init-silk.sh" 2 minutes ago Up 2 minutes pig
[root@pighost dpi]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6645f7a68e60 pig/silk:dpi "/root/init-silk.sh" 2 minutes ago Exited (0) 9 seconds ago pig二、索引pcap文件
在上面的yaf命令中,我们通过--index-pcap、--pcap和--pcap-meta-file等选项,重构了pcap文件,并对pcap文件建立了索引。这样,在通过IE进行分析后,对需要进一步深入分析的会话,我们就可以很方便的通过yafMeta2Pcap工具提取对应的pcap包。
1. 载入数据
将前面我们预处理过的数据载入到spark-shell中
scala> val all = spark.read.fields(IPFIXFields.everything).ipfix("g:/share/testdata/ipfix/*.med")
all: org.apache.spark.sql.DataFrame = [startTime: timestamp, endTime: timestamp ... 184 more fields]
scala> all.count
res0: Long = 29768这一过程中,我们遇到尾部的med文件存在索引错误的情况。可能是因为数据处理到尾部不完整造成的,删掉尾巴后面的一个文件好了。
然后仅选取我们关注的有限几个字段------主要时由于yafFlowKeyHash这个字段不在default字段的范围内,所以我们还是按照everything载入,然后从中间提取出来的本办法
scala> val five = all.select('sourceIPAddress,'sourcePort,'destinationIPAddress,'destinationPort,'protocolIdentifier,'startTime,'yafFlowKeyHash)
five: org.apache.spark.sql.DataFrame = [sourceIPAddress: string, sourcePort: int ... 5 more fields]show一下:
scala> five.show(false)
+---------------+----------+--------------------+---------------+------------------+-----------------------+--------------+
|sourceIPAddress|sourcePort|destinationIPAddress|destinationPort|protocolIdentifier|startTime |yafFlowKeyHash|
+---------------+----------+--------------------+---------------+------------------+-----------------------+--------------+
.............................. |
|192.168.182.76 |63142 |172.2.118.41 |80 |6 |2022-11-15 09:42:34.624|2173542517 |
..............................
+---------------+----------+--------------------+---------------+------------------+-----------------------+--------------+
only showing top 20 rows2. 提取对应流的pcap
得到流的hash值,我们就可以用它去寻找流的原始数据包了。当然,如果还能知道精确到ms的流开始和结束时间则更好。这里数据量小,且时间并不是最必要的,暂时不弄了,就看看使用hash如何得到流吧。
yafMeta2Pcap工具需要单独下载或者安装。当然,我们之前在构造pig/silk:single镜像的时候就装过,所以可以把它请出来,并把之前输出的文件夹给映射进去:
[root@pighost dpi]# docker run -it --name pig -v /root/share/testdata:/data pig/silk:single bash然后可以在其中运行工具,指定meta data和pcap data的路径,以及我们从商标中得到的流的hash,指定输出文件的文件名,如果指定文件名为"-",则通过标准输出输出。
[root@962755dfe75f /]# yafMeta2Pcap -f /data/pcap-meta/* -p /data/pcap-data/* -h 2173542517 -o t.pcap
Found 3 packets that match criteria.可以看到,有3个包匹配这个流hash。我们通过wireshark将其打开,确实是这个流:

三、编程使用mothra
基于vscode构建scala+java的混合spark编程环境,VSCODE SPARK 容器式编程环境构建一文中我们已有记录,此处不赘述。