Redis延迟双删是一种用于解决缓存与数据库数据一致性问题 的策略,通常在高并发场景下使用。以下是其核心内容:
1. 问题背景
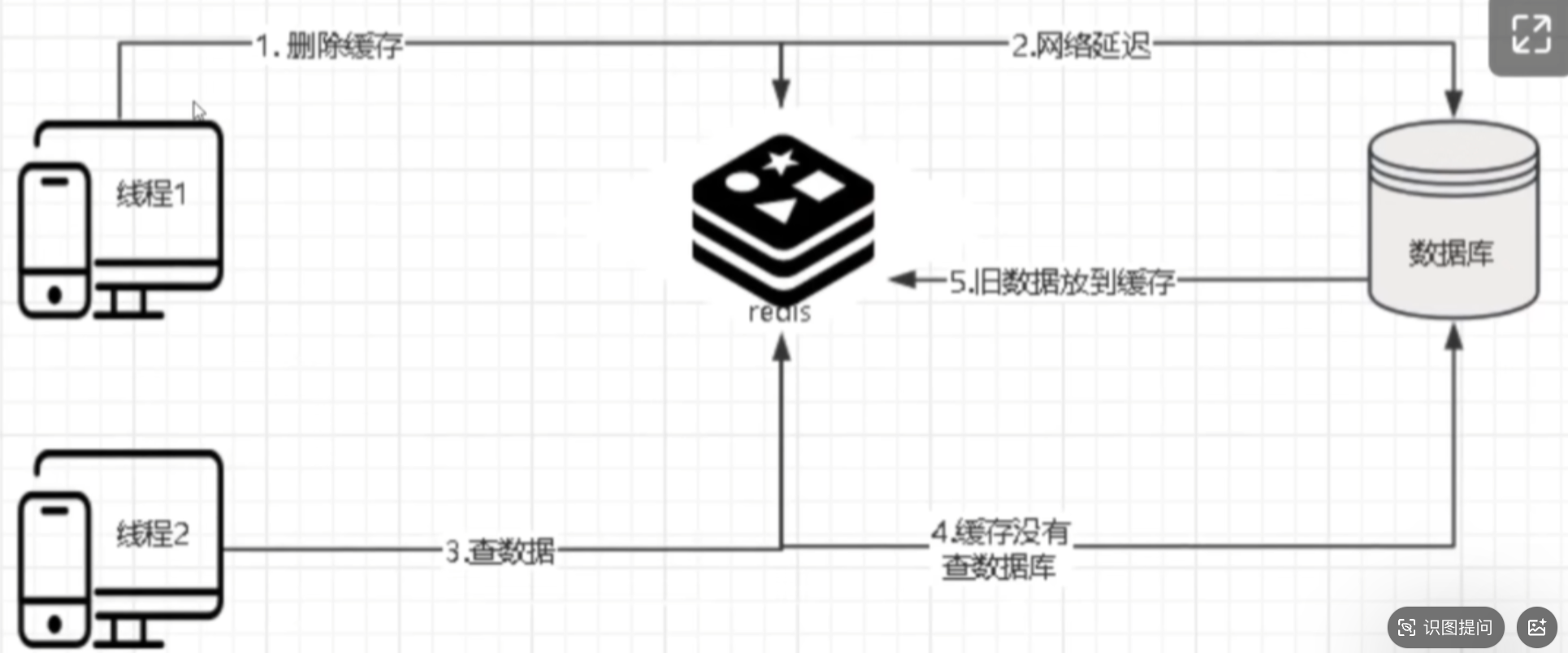
当更新数据库时,如果未及时删除或更新缓存,可能导致后续读请求仍从缓存中读取旧数据,造成数据不一致。
2. 延迟双删的核心逻辑
在更新数据库前后各执行一次缓存删除操作,并在第二次删除时增加延迟:
- 第一次删除缓存:在更新数据库前,先删除缓存中的旧数据。
- 更新数据库:执行数据库写操作。
- 延迟后第二次删除缓存:等待一段时间(如500ms),确保数据库写操作已完成,再次删除缓存。
示例代码(伪代码):
python
def update_data(key, new_value):
# 第一次删除缓存
redis.delete(key)
# 更新数据库
db.update(key, new_value)
# 延迟后第二次删除缓存(防止数据库更新过程中有新写入缓存)
time.sleep(0.5) # 延迟时间根据数据库性能调整
redis.delete(key)3. 为什么需要延迟?
- 数据库写入耗时:数据库写操作可能比缓存删除慢,延迟可确保数据库更新完成后再删除缓存。
- 避免脏读:若在更新数据库后立即删除缓存,可能因网络延迟等问题,导致缓存未及时删除,后续请求仍读取旧数据。
4. 适用场景
- 读多写少:频繁读取热点数据时,确保缓存与数据库一致。
- 强一致性要求:对数据一致性敏感的业务(如订单状态、库存)。
5. 优缺点
- 优点 :
- 简单直接,减少缓存与数据库不一致的概率。
- 适用于大多数高并发场景。
- 缺点 :
- 两次删除操作增加系统开销。
- 延迟时间需根据数据库性能合理设置,过短可能无效,过长影响性能。
6. 优化建议
- 设置缓存过期时间:作为双删的补充,即使双删失败,缓存也会在过期后自动更新。
- 异步处理延迟删除:通过消息队列(如Kafka)异步执行第二次删除,降低同步延迟对性能的影响。
- 监控与重试:记录双删失败的键,通过定时任务重试删除。
7. 替代方案
- 先更新数据库,再更新缓存:需处理缓存更新失败的重试逻辑。
- 异步删除缓存:通过订阅数据库binlog,异步触发缓存删除(如Canal工具)。
- 使用本地缓存+定时刷新:适用于允许短暂不一致的场景。
总结
延迟双删是一种折中方案,在保证数据一致性和系统性能之间取得平衡。实际应用中需结合业务需求选择策略,并通过监控和测试验证效果。