[MongoDB 基础](#MongoDB 基础)
[MongoDB 是什么?](#MongoDB 是什么?)
MongoDB 是一个基于 分布式文件存储 的开源 NoSQL 数据库系统,由 C++ 编写的。MongoDB 提供了 面向文档 的存储方式,操作起来比较简单和容易,支持"无模式 "的数据建模,可以存储比较复杂的数据类型,是一款非常流行的 文档类型数据库 。
在高负载的情况下,MongoDB 天然支持水平扩展和高可用,可以很方便地添加更多的节点/实例,以保证服务性能和可用性。在许多场景下,MongoDB 可以用于代替传统的关系型数据库或键/值存储方式,皆在为 Web 应用提供可扩展的高可用高性能数据存储解决方案。
[MongoDB 的存储结构是什么?](#MongoDB 的存储结构是什么?)
MongoDB 的存储结构区别于传统的关系型数据库,主要由如下三个单元组成:
- 文档(Document):MongoDB 中最基本的单元,由 BSON 键值对(key-value)组成,类似于关系型数据库中的行(Row)。
- 集合(Collection):一个集合可以包含多个文档,类似于关系型数据库中的表(Table)。
- 数据库(Database):一个数据库中可以包含多个集合,可以在 MongoDB 中创建多个数据库,类似于关系型数据库中的数据库(Database)。
也就是说,MongoDB 将数据记录存储为文档 (更具体来说是BSON 文档),这些文档在集合中聚集在一起,数据库中存储一个或多个文档集合。
SQL 与 MongoDB 常见术语对比:
| SQL | MongoDB |
|---|---|
| 表(Table) | 集合(Collection) |
| 行(Row) | 文档(Document) |
| 列(Col) | 字段(Field) |
| 主键(Primary Key) | 对象 ID(Objectid) |
| 索引(Index) | 索引(Index) |
| 嵌套表(Embedded Table) | 嵌入式文档(Embedded Document) |
| 数组(Array) | 数组(Array) |
文档
MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。字段的值可能包括其他文档、数组和文档数组。

文档的键是字符串。除了少数例外情况,键可以使用任意 UTF-8 字符。
- 键不能含有
\0(空字符)。这个字符用来表示键的结尾。 .和$有特别的意义,只有在特定环境下才能使用。- 以下划线
_开头的键是保留的(不是严格要求的)。
BSON bee·sahn 是 Binary JSON的简称,是 JSON 文档的二进制表示,支持将文档和数组嵌入到其他文档和数组中,还包含允许表示不属于 JSON 规范的数据类型的扩展。有关 BSON 规范的内容,可以参考 bsonspec.org,另见BSON 类型。
根据维基百科对 BJSON 的介绍,BJSON 的遍历速度优于 JSON,这也是 MongoDB 选择 BSON 的主要原因,但 BJSON 需要更多的存储空间。
与 JSON 相比,BSON 着眼于提高存储和扫描效率。BSON 文档中的大型元素以长度字段为前缀以便于扫描。在某些情况下,由于长度前缀和显式数组索引的存在,BSON 使用的空间会多于 JSON。

集合
MongoDB 集合存在于数据库中,没有固定的结构 ,也就是 无模式 的,这意味着可以往集合插入不同格式和类型的数据。不过,通常情况下,插入集合中的数据都会有一定的关联性。

集合
MongoDB 集合存在于数据库中,没有固定的结构 ,也就是 无模式 的,这意味着可以往集合插入不同格式和类型的数据。不过,通常情况下,插入集合中的数据都会有一定的关联性。
集合不需要事先创建,当第一个文档插入或者第一个索引创建时,如果该集合不存在,则会创建一个新的集合。
集合名可以是满足下列条件的任意 UTF-8 字符串:
- 集合名不能是空字符串
""。 - 集合名不能含有
\0(空字符),这个字符表示集合名的结尾。 - 集合名不能以"system."开头,这是为系统集合保留的前缀。例如
system.users这个集合保存着数据库的用户信息,system.namespaces集合保存着所有数据库集合的信息。 - 集合名必须以下划线或者字母符号开始,并且不能包含
$。
数据库
数据库用于存储所有集合,而集合又用于存储所有文档。一个 MongoDB 中可以创建多个数据库,每一个数据库都有自己的集合和权限。
MongoDB 预留了几个特殊的数据库。
- admin : admin 数据库主要是保存 root 用户和角色。例如,system.users 表存储用户,system.roles 表存储角色。一般不建议用户直接操作这个数据库。将一个用户添加到这个数据库,且使它拥有 admin 库上的名为 dbAdminAnyDatabase 的角色权限,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如关闭服务器。
- local : local 数据库是不会被复制到其他分片的,因此可以用来存储本地单台服务器的任意 collection。一般不建议用户直接使用 local 库存储任何数据,也不建议进行 CRUD 操作,因为数据无法被正常备份与恢复。
- config : 当 MongoDB 使用分片设置时,config 数据库可用来保存分片的相关信息。
- test : 默认创建的测试库,连接 mongod 服务时,如果不指定连接的具体数据库,默认就会连接到 test 数据库。
数据库名可以是满足以下条件的任意 UTF-8 字符串:
- 不能是空字符串
""。 - 不得含有
' '(空格)、.、$、/、\和\0(空字符)。 - 应全部小写。
- 最多 64 字节。
数据库名最终会变成文件系统里的文件,这也就是有如此多限制的原因。
[MongoDB 有什么特点?](#MongoDB 有什么特点?)
- admin : admin 数据库主要是保存 root 用户和角色。例如,system.users 表存储用户,system.roles 表存储角色。一般不建议用户直接操作这个数据库。将一个用户添加到这个数据库,且使它拥有 admin 库上的名为 dbAdminAnyDatabase 的角色权限,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如关闭服务器。
- local : local 数据库是不会被复制到其他分片的,因此可以用来存储本地单台服务器的任意 collection。一般不建议用户直接使用 local 库存储任何数据,也不建议进行 CRUD 操作,因为数据无法被正常备份与恢复。
- config : 当 MongoDB 使用分片设置时,config 数据库可用来保存分片的相关信息。
- test : 默认创建的测试库,连接 mongod 服务时,如果不指定连接的具体数据库,默认就会连接到 test 数据库。
数据库名可以是满足以下条件的任意 UTF-8 字符串:
- 不能是空字符串
""。 - 不得含有
' '(空格)、.、$、/、\和\0(空字符)。 - 应全部小写。
- 最多 64 字节。
数据库名最终会变成文件系统里的文件,这也就是有如此多限制的原因。
[MongoDB 适合什么应用场景?](#MongoDB 适合什么应用场景?)
MongoDB 的优势在于其数据模型和存储引擎的灵活性、架构的可扩展性以及对强大的索引支持。
选用 MongoDB 应该充分考虑 MongoDB 的优势,结合实际项目的需求来决定:
- 随着项目的发展,使用类 JSON 格式(BSON)保存数据是否满足项目需求?MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
- 是否需要大数据量的存储?是否需要快速水平扩展?MongoDB 支持分片集群,可以很方便地添加更多的节点(实例),让集群存储更多的数据,具备更强的性能。
- 是否需要更多类型索引来满足更多应用场景?MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
- ......
[MongoDB 存储引擎](#MongoDB 存储引擎)
[MongoDB 支持哪些存储引擎?](#MongoDB 支持哪些存储引擎?)
存储引擎(Storage Engine)是数据库的核心组件,负责管理数据在内存和磁盘中的存储方式。
与 MySQL 一样,MongoDB 采用的也是 插件式的存储引擎架构 ,支持不同类型的存储引擎,不同的存储引擎解决不同场景的问题。在创建数据库或集合时,可以指定存储引擎。
插件式的存储引擎架构可以实现 Server 层和存储引擎层的解耦,可以支持多种存储引擎,如 MySQL 既可以支持 B-Tree 结构的 InnoDB 存储引擎,还可以支持 LSM 结构的 RocksDB 存储引擎。
在存储引擎刚出来的时候,默认是使用 MMAPV1 存储引擎,MongoDB4.x 版本不再支持 MMAPv1 存储引擎。
现在主要有下面这两种存储引擎:
- WiredTiger 存储引擎 :自 MongoDB 3.2 以后,默认的存储引擎为 WiredTiger 存储引擎 。非常适合大多数工作负载,建议用于新部署。WiredTiger 提供文档级并发模型、检查点和数据压缩(后文会介绍到)等功能。
- In-Memory 存储引擎 :In-Memory 存储引擎在 MongoDB Enterprise 中可用。它不是将文档存储在磁盘上,而是将它们保留在内存中以获得更可预测的数据延迟。
此外,MongoDB 3.0 提供了 可插拔的存储引擎 API ,允许第三方为 MongoDB 开发存储引擎,这点和 MySQL 也比较类似。
[WiredTiger 基于 LSM Tree 还是 B+ Tree?](#WiredTiger 基于 LSM Tree 还是 B+ Tree?)
目前绝大部分流行的数据库存储引擎都是基于 B/B+ Tree 或者 LSM(Log Structured Merge) Tree 来实现的。对于 NoSQL 数据库来说,绝大部分(比如 HBase、Cassandra、RocksDB)都是基于 LSM 树,MongoDB 不太一样。
上面也说了,自 MongoDB 3.2 以后,默认的存储引擎为 WiredTiger 存储引擎。在 WiredTiger 引擎官网上,我们发现 WiredTiger 使用的是 B+ 树作为其存储结构:
WiredTiger maintains a table's data in memory using a data structure called a B-Tree ( B+ Tree to be specific), referring to the nodes of a B-Tree as pages. Internal pages carry only keys. The leaf pages store both keys and values.此外,WiredTiger 还支持 LSM(Log Structured Merge) 树作为存储结构,MongoDB 在使用 WiredTiger 作为存储引擎时,默认使用的是 B+ 树。
如果想要了解 MongoDB 使用 B+ 树的原因,可以看看这篇文章:【驳斥八股文系列】别瞎分析了,MongoDB 使用的是 B+ 树,不是你们以为的 B 树。
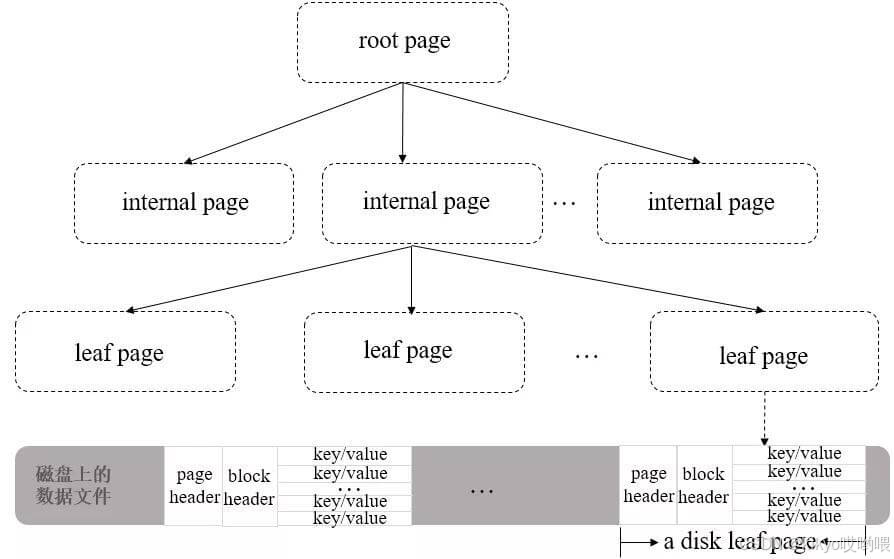
使用 B+ 树时,WiredTiger 以 page 为基本单位往磁盘读写数据。B+ 树的每个节点为一个 page,共有三种类型的 page:
- root page(根节点):B+ 树的根节点。
- internal page(内部节点):不实际存储数据的中间索引节点。
- leaf page(叶子节点):真正存储数据的叶子节点,包含一个页头(page header)、块头(block header)和真正的数据(key/value),其中页头定义了页的类型、页中实际载荷数据的大小、页中记录条数等信息;块头定义了此页的 checksum、块在磁盘上的寻址位置等信息。
其整体结构如下图所示:
如果想要深入研究学习 WiredTiger 存储引擎,推荐阅读 MongoDB 中文社区的 WiredTiger 存储引擎系列