场景
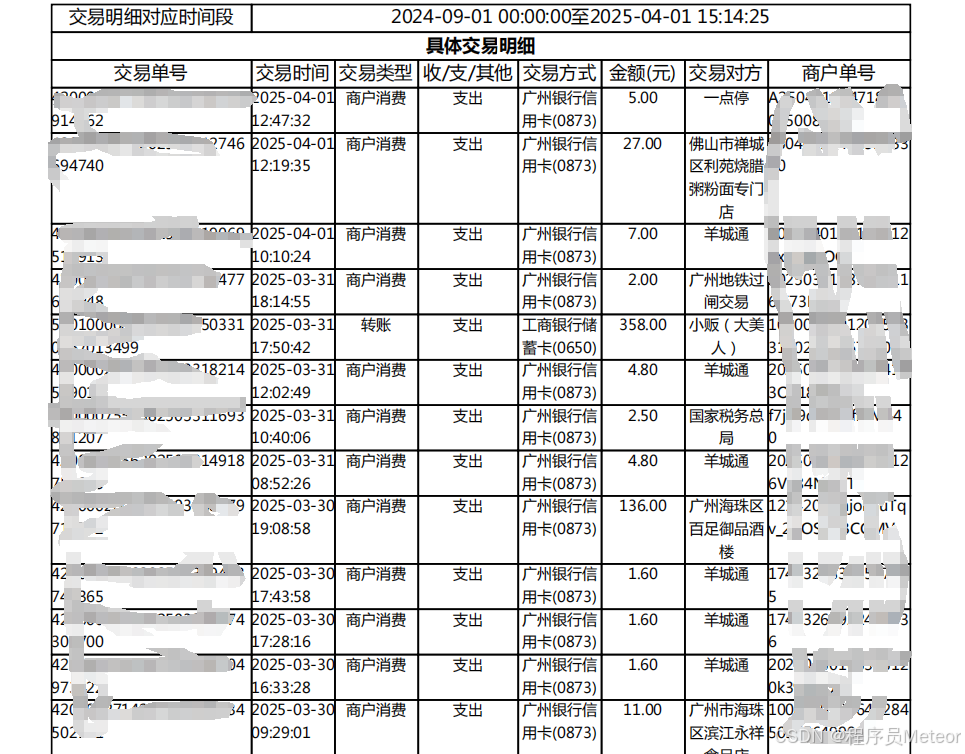
在日常业务需求中,往往会遇到解析pdf数据获取文本的需求,常见的做法是使用 pdfbox 来做,但是它只适合做一些简单的段落文本解析,无法处理表格这种复杂类型,因为单元格中的文本有换行的情况,无法对应到我们业务具体的属性上面去。而 tabula 在它的基础上做了表格的特殊处理,使用案例如下:
引入依赖
xml
<!-- PDF解析,内含pdfbox -->
<dependency>
<groupId>technology.tabula</groupId>
<artifactId>tabula</artifactId>
<version>1.0.5</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.53</version>
</dependency>代码实现
java
package net.lab1024.sa.admin.util;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import technology.tabula.*;
import technology.tabula.extractors.SpreadsheetExtractionAlgorithm;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
@Slf4j
public class PdfUtil {
public static void main(String[] args) {
JSONArray jsonArray = readPdfTable("C:\\Users\\admin\\Desktop\\xxx.pdf");
System.out.println(jsonArray);
}
/**
* 解析pdf的表格
*
* @param filePath
* @return
*/
public static JSONArray readPdfTable(String filePath) {
// 表头
// todo 这里自己先定义了,使用时可读取表头的中文作为key或者将中文翻译成英文作为key
List<String> fieldList = new ArrayList<>();
fieldList.add("jydh");
fieldList.add("jysj");
fieldList.add("jylx");
fieldList.add("szqt");
fieldList.add("jyfs");
fieldList.add("je");
fieldList.add("jydf");
fieldList.add("shdh");
JSONArray jsonArray = new JSONArray();
// 表格提取算法
SpreadsheetExtractionAlgorithm algorithm = new SpreadsheetExtractionAlgorithm();
try (PDDocument document = PDDocument.load(new File(filePath))) {
ObjectExtractor extractor = new ObjectExtractor(document);
PageIterator pi = extractor.extract();
// 遍历页
while (pi.hasNext()) {
Page page = pi.next();
List<Table> tableList = algorithm.extract(page);
// 遍历表
for (Table table : tableList) {
List<List<RectangularTextContainer>> rowList = table.getRows();
// 遍历行
for (List<RectangularTextContainer> row : rowList) {
JSONObject jsonObject = new JSONObject();
// 遍历列
for (int i = 0; i < row.size(); i++) {
RectangularTextContainer cell = row.get(i);
String text = cell.getText().replace("\r", "");
jsonObject.put(fieldList.get(i), text);
}
jsonArray.add(jsonObject);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
return jsonArray;
}
}