1 MapReduce核心原理
MapReduce是一种分布式计算框架,专为处理大规模数据集设计。其核心理念是将复杂计算任务分解为两个核心阶段:
- **Map阶段:**将输入数据分割为独立片段,并行处理生成中间键值对
- **Reduce阶段:**对Map阶段输出的中间键值对进行聚合,生成最终结果
执行流程:
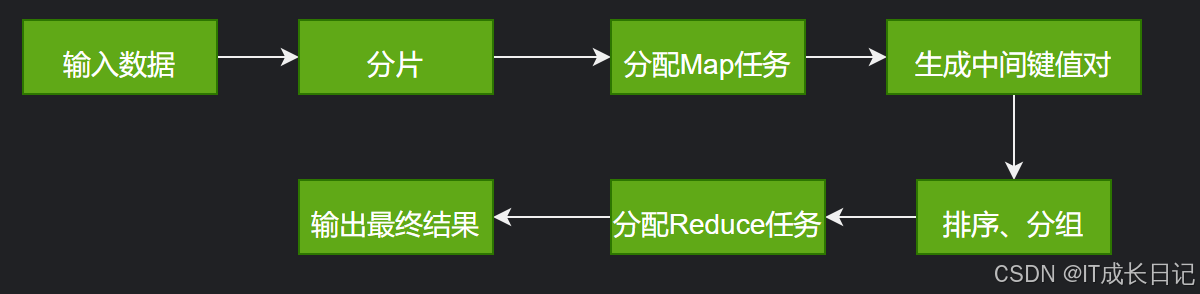
2 MapReduce离线计算的优势
- **高可扩展性:**支持水平扩展,通过增加节点处理PB级数据
- **容错性强:**自动检测任务失败并重试,数据冗余存储(如HDFS)
- **简化并行编程:**隐藏底层分布式细节,开发者只需关注Map/Reduce逻辑
3 MapReduce离线计算的典型应用场景
- **日志分析:**处理服务器日志,统计访问量、错误码分布等
- **数据仓库ETL:**清洗、转换大规模数据,加载至数据仓库
- **图计算:**处理社交网络、推荐系统等图结构数据
- **机器学习预处理:**特征提取、数据归一化等批量处理任务
4 MapReduce离线计算的局限性
- **实时性不足:**批处理模式延迟较高,不适合秒级响应需求
- **编程灵活性低:**强制Map/Reduce模型,难以表达复杂迭代算法
- **磁盘I/O开销大:**中间结果需写入磁盘,影响性能
5 总结
MapReduce作为离线计算的经典框架,凭借其高可扩展性和容错性,在日志分析、ETL等场景中仍具不可替代性。然而,随着实时计算需求的增长,其局限性逐渐显现。实际应用中需结合业务场景选择技术栈:
- **离线批处理:**优先MapReduce(如Hadoop)
- **迭代计算/机器学习:**推荐Spark
- **实时流处理:**选择Flink或Kafka Streams