本节课接着上节课的继续学习了Key-Value类型中的sortByKey、join、leftOuterJoin、cogroup,新学习了RDD行动算子,其中包括reduce、collect、foreach、count、first、take、takeOrdered、aggregate、fold、countByKey、save相关算子等;还学习了累加器跟广播变量
Key-Value类型
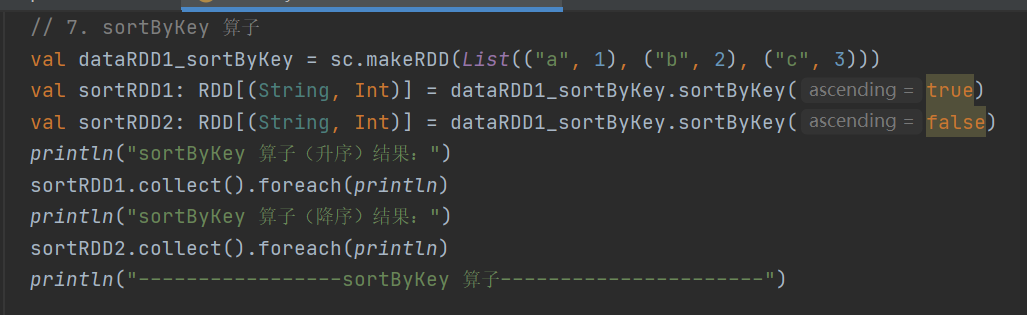
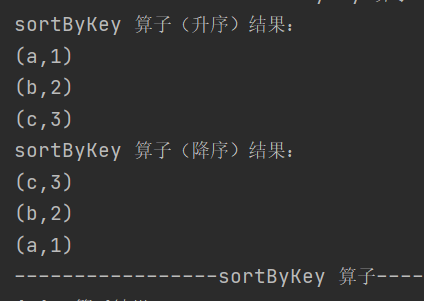
sortByKey
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
: RDD[(K, V)]按照 key 对 RDD 进行排序
join
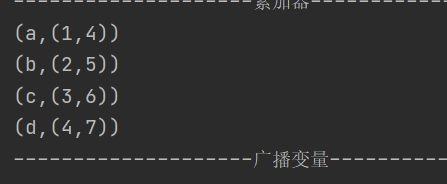
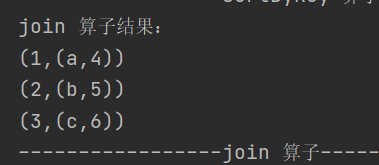
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]对两个类型为 (K, V) 和 (K, W) 的 RDD 进行连接操作

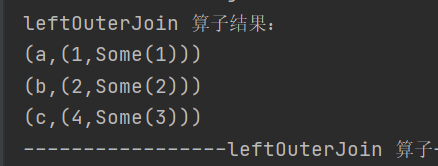
leftOuterJoin
def leftOuterJoin[W](other: RDD[(K, W)]): RDD[(K, (V, Option[W]))]类似于 SQL 中的左外连接

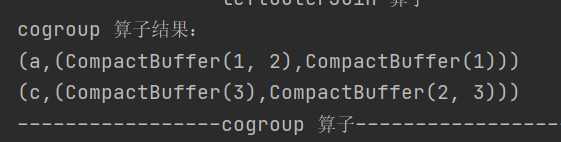
cogroup
def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]对两个类型为 (K, V) 和 (K, W) 的 RDD 进行分组操作

RDD行动算子
行动算子就是会触发action的算子,触发action的含义就是真正的计算数据。
先添加如下:

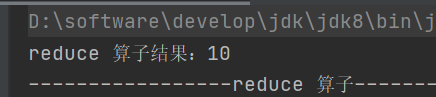
1.reduce
def reduce(f: (T, T) => T): T对 RDD 元素进行聚集操作,先聚合分区内数据,再聚合分区间数据

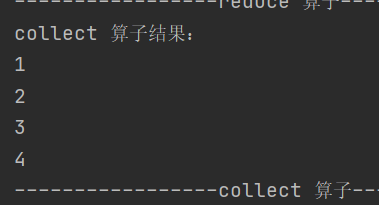
2. collect
def collect(): Array[T]将 RDD 所有元素以数组形式返回至驱动程序

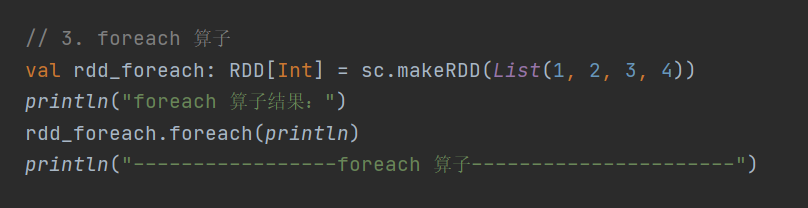
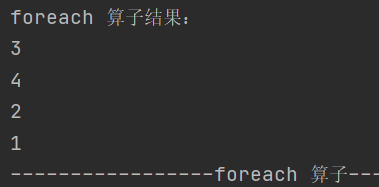
3. foreach
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}分布式遍历 RDD 元素并调用指定函数
4. count
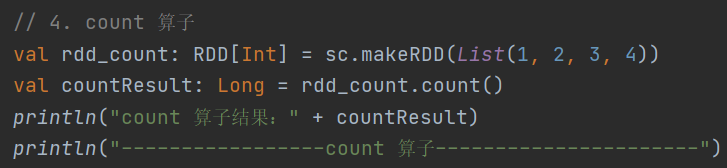
def count(): Long返回 RDD 中元素的数量

5. first
def first(): T返回 RDD 的第一个元素


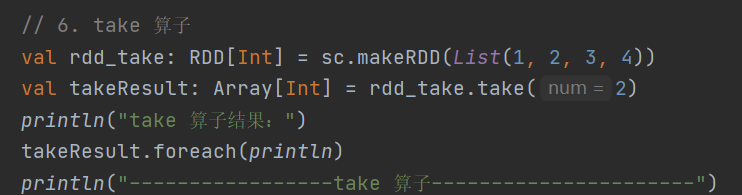
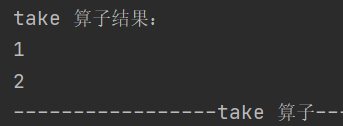
6.take
def take(num: Int): Array[T]返回 RDD 前n个元素组成的数组
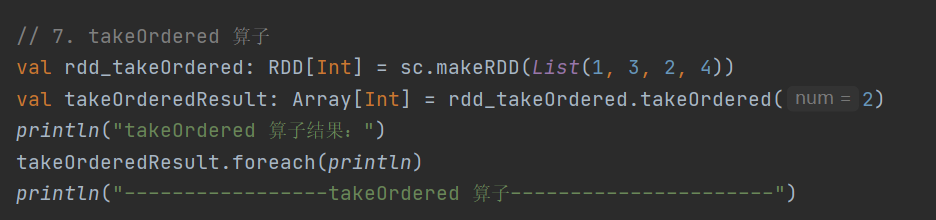
7. takeOrdered
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]返回 RDD 排序后的前n个元素组成的数组

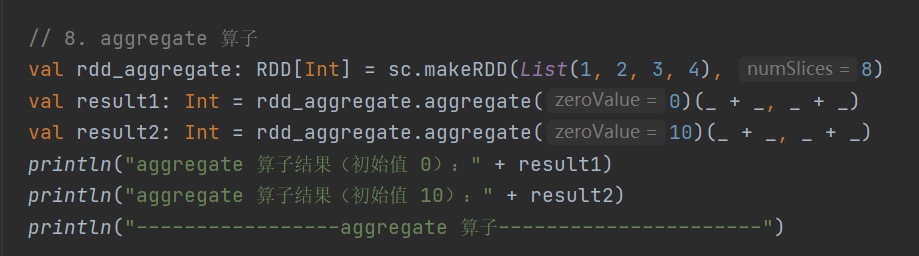
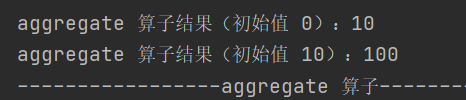
8) aggregate
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U分区内和分区间使用初始值进行数据聚合
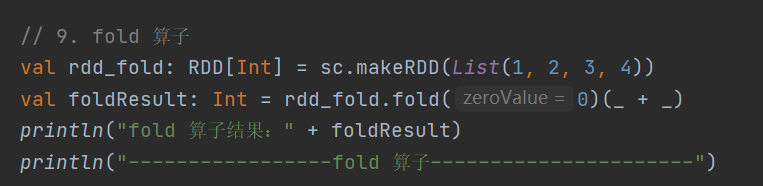
9. fold
def fold(zeroValue: T)(op: (T, T) => T): T是aggregate的简化操作

10. countByKey
def countByKey(): Map[K, Long]统计 RDD 中每种key的数量


11.save 相关算子
def saveAsTextFile(path: String): Unit
def saveAsObjectFile(path: String): Unit
def saveAsSequenceFile(
path: String,
codec: Option[Class[_ <: CompressionCodec]] = None): Unit //了解即可将 RDD 数据保存为不同格式的文件,如文本文件、对象文件等

累加器
把 Executor 端变量信息聚合到 Driver 端
// 累加器示例
val rdd = sparkContext.makeRDD(List(1, 2, 3, 4, 5))
// 声明累加器
var sum = sparkContext.longAccumulator("sum")
rdd.foreach(
num => {
// 使用累加器
sum.add(num)
}
)
// 获取累加器的值
println("sum = " + sum.value)
// 自定义累加器实现 wordcount
// 创建自定义累加器
class WordCountAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] {
var map: mutable.Map[String, Long] = mutable.Map()
override def isZero: Boolean = map.isEmpty
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = new WordCountAccumulator
override def reset(): Unit = map.clear()
override def add(v: String): Unit = {
map(v) = map.getOrElse(v, 0L) + 1L
}
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map1 = map
val map2 = other.value
map = map1.foldLeft(map2)(
(innerMap, kv) => {
innerMap(kv._1) = innerMap.getOrElse(kv._1, 0L) + kv._2
innerMap
}
)
}
override def value: mutable.Map[String, Long] = map
}
// 调用自定义累加器
val rddWords = sparkContext.makeRDD(
List("spark", "scala", "spark hadoop", "hadoop")
)
val acc = new WordCountAccumulator
sparkContext.register(acc)
rddWords.flatMap(_.split(" ")).foreach(
word => acc.add(word)
)
println(acc.value)
println("--------------------累加器---------------------")
广播变量
广播变量用于高效分发较大的只读对象到所有工作节点