文章目录
- 摘要
- Abstract
- [1. 引言](#1. 引言)
- [2. 框架](#2. 框架)
-
- [2.1 模型](#2.1 模型)
-
- [2.1.1 简介](#2.1.1 简介)
- [2.1.2 RAG-Sequence模型](#2.1.2 RAG-Sequence模型)
- [2.1.3 RAG-Token模型](#2.1.3 RAG-Token模型)
- [2.2 检索器:DPR](#2.2 检索器:DPR)
- [2.3 生成器:BART](#2.3 生成器:BART)
- [2.4 训练](#2.4 训练)
- [2.5 解码](#2.5 解码)
-
- [2.5.1 RAG-Sequence](#2.5.1 RAG-Sequence)
- [2.5.2 RAG-Token](#2.5.2 RAG-Token)
- [2.6 使用RAG对指定数据集进行检索](#2.6 使用RAG对指定数据集进行检索)
- [3. 创新点和不足](#3. 创新点和不足)
-
- [3.1 创新点](#3.1 创新点)
- [3.2 不足](#3.2 不足)
- 参考
- 总结
摘要
RAG在知识密集型NLP任务中的创新点主要体现在其独特的架构设计和训练范式上。该模型首次将参数化记忆(如预训练的BART-large生成器)与非参数化记忆(基于Wikipedia的密集向量索引)相结合,通过端到端训练实现检索器与生成器的联合优化,无需依赖显式的检索监督信号。这种混合架构不仅突破了传统预训练模型在知识更新上的局限------通过替换文档索引即可动态更新知识库而无需重新训练整个模型,还引入了灵活的检索增强机制:利用最大内积搜索(MIPS)从2100万文档中快速定位Top-K相关段落,并通过边缘化潜在变量的方式将检索结果融入生成过程。特别值得关注的是其提出的两种解码模式------RAG-Sequence采用固定文档生成完整序列再概率融合,而RAG-Token允许每个token动态切换参考文档,这种设计在保持语义连贯性的同时增强了多文档交叉引用能力。此外,模型通过将检索到的具体文档内容作为生成依据,显著减少了传统生成模型的"幻觉"问题,使输出文本更具事实性和可验证性。
Abstract
The innovation of RAG in knowledge-intensive NLP tasks is primarily reflected in its unique architecture design and training paradigm. This model is the first to combine parametric memory (such as the pre-trained BART-large generator) with non-parametric memory (a dense vector index based on Wikipedia), achieving joint optimization of the retriever and generator through end-to-end training without relying on explicit retrieval supervision signals. This hybrid architecture not only breaks through the limitations of traditional pre-trained models in updating knowledge---by allowing the knowledge base to be dynamically updated through a simple replacement of the document index without retraining the entire model---but also introduces a flexible retrieval-augmented mechanism: using Maximum Inner Product Search (MIPS) to quickly pinpoint the top-K relevant passages from 21 million documents, and incorporating the retrieval results into the generation process via marginalization over latent variables. Notably, the model proposes two decoding modes: RAG-Sequence, which generates a complete sequence using a fixed document and then probabilistically fuses the results, and RAG-Token, which allows each token to dynamically switch its reference document. This design enhances cross-referencing across multiple documents while maintaining semantic coherence. Furthermore, by using the specific content from the retrieved documents as the basis for generation, the model significantly reduces the "hallucination" problems common in traditional generative models, making the output text more factual and verifiable.
1. 引言
预训练的自然语言模型已经被证明能在不获取额外知识的情况下从数据中学习到大量深入的知识,它们可以看作是参数化的隐式知识库。尽管它们能发展到如此程度,但是这些模型也存在如下的缺点:它们不能轻易地扩展或修改记忆;不能直接提供对由它们产生的预测的洞见;甚至会产生幻觉,生成看似合理实际错误的内容。解决上述问题的方法是使用联合了参数化记忆和非参数化记忆如基于检索的记忆的模型,因为在使用这种混合模型的情况知识可以直接修改和扩展,并且访问的知识可以检查和解释。
2. 框架
RAG的训练流程:首先通过查询编码器编码查询得到 q ( x ) q(x) q(x),接着将所有文档通过文档编码器编码为文档索引 d ( z ) d(z) d(z),再由 q ( x ) q(x) q(x)和 d ( z ) d(z) d(z)计算出所有文档的得分,然后通过最大内积搜索法得到前K个文档,接着按照RAG-Token或RAG-Sequence的方式将输入 x x x、文档 z z z、之前所有的目标序列输入到生成器。
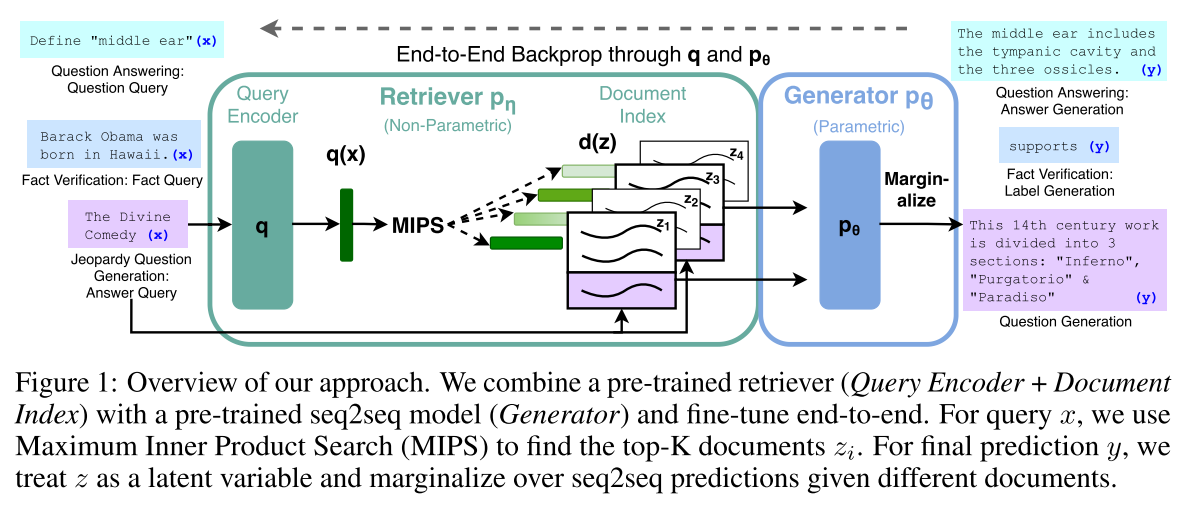
2.1 模型
2.1.1 简介
RAG模型的作用是使用输入序列 x x x来检索文本文档 z z z,然后将检索得到的结果用作生成目标序列 y y y时额外的上下文。RAG模型主要由两部分组成:一部分是带有参数 η \eta η的检索器 p η ( z ∣ x ) p_\eta(z|x) pη(z∣x),它返回由查询 x x x在文本中的前K个答案;另一部分是带有参数 θ \theta θ的生成器 p θ ( y i ∣ x , z , y 1 : i − 1 ) p_{\theta}(y_i|x,z,y_{1:i-1}) pθ(yi∣x,z,y1:i−1),它基于由原始输入 x x x、检索文章 z z z和前 i − 1 i-1 i−1个词元 y 1 : i − 1 y_{1:i-1} y1:i−1构成的上下文返回当前词元 y i y_i yi。
为了端到端地训练检索器和生成器,论文将检索文档看作一个潜变量。论文提出了两个边缘化潜在文档的模型以达到使用不同的方式来产生一个关于生成文本的分布。其中一个模型RAG-Sequence使用同一个文档来预测每个目标词元;而另一个模型RAG-Token基于不同的文档来预测每个目标词元。
2.1.2 RAG-Sequence模型
RAG-Sequence使用同一个检索出来的文档来生成目标序列,它将检索到的单个文档当作单个边缘化的潜变量,然后通过Top-K近似来获得序列到序列的概率 p ( y ∣ x ) p(y|x) p(y∣x)。具体实现过程是检索器首先检索出前K个文档,然后生成器根据每个文档产生输出目标序列的概率,最终进行近似。
p R A G − S e q u e n c e ( y ∣ x ) ≈ ∑ z ∈ top − k ( p ( ⋅ ∣ x ) ) p η ( z ∣ x ) p θ ( y ∣ x , z ) = ∑ z ∈ top − k ( p ( ⋅ ∣ x ) ) p η ( z ∣ x ) ∏ i N p θ ( y i ∣ x , z , y 1 : i − 1 ) . \begin{aligned}p_{RAG-Sequence}(y|x)&\approx\sum_{z\in \text{top}-k(p(·|x))}p_{\eta}(z|x)p_{\theta}(y|x,z)\\ &=\sum_{z\in\text{top}-k(p(·|x))}p_{\eta}(z|x)\prod_{i}^Np_{\theta}(y_i|x,z,y_{1:i-1}).\end{aligned} pRAG−Sequence(y∣x)≈z∈top−k(p(⋅∣x))∑pη(z∣x)pθ(y∣x,z)=z∈top−k(p(⋅∣x))∑pη(z∣x)i∏Npθ(yi∣x,z,y1:i−1).
2.1.3 RAG-Token模型
RAG-Token模型使用不同的文档来生成不同的目标词元并相应地进行近似,如此允许生成器使用不同文档的上下文来生成答案。具体实现过程是首先通过检索器检索出前K个文档,然后生成器在近似前对每个文档生成一个关于下一个输出词元的分布,重复这个过程直到生成完所有的输出序列。
p R A G − T o k e n ( y ∣ x ) ≈ ∏ i N ∑ z ∈ top − k ( p ( ⋅ ∣ x ) ) p η ( z ∣ x ) p θ ( y i ∣ x , z i , y 1 : i − 1 ) . \begin{aligned}p_{RAG-Token}(y|x)&\approx\prod_{i}^N\sum_{z\in\text{top}-k(p(·|x))}p_{\eta}(z|x)p_{\theta}(y_i|x,z_i,y_{1:i-1}).\end{aligned} pRAG−Token(y∣x)≈i∏Nz∈top−k(p(⋅∣x))∑pη(z∣x)pθ(yi∣x,zi,y1:i−1).
2.2 检索器:DPR
检索器 p η ( z ∣ x ) p_{\eta}(z|x) pη(z∣x)是基于密集文章检索DPR的。DPR是一个双编码器架构:
d ( z ) = BERT d ( z ) q ( x ) = BERT q ( x ) p η ( z ∣ x ) ∝ exp ( d ( z ) T q ( x ) ) . \begin{aligned}d(z)&=\text{BERT}_d(z)\\ q(x)&=\text{BERT}q(x)\\ p{\eta}(z|x)&\propto\text{exp}(d(z)^Tq(x)).\end{aligned} d(z)q(x)pη(z∣x)=BERTd(z)=BERTq(x)∝exp(d(z)Tq(x)).
其中 d ( z ) d(z) d(z)是由BERT-BASE文档编码器生成的关于一个文档的密集表示; q ( x ) q(x) q(x)是由基于BERT-BASE的查询编码器生成的查询表示;计算 top − k ( p η ( ⋅ ∣ x ) ) \text{top}-k(p_{\eta}(·|x)) top−k(pη(⋅∣x))是一个最大内积搜索问题。
论文使用了DPR的预训练模型来初始化检索器并构建文档索引,而这些文档索引被称为非参数化记忆。
2.3 生成器:BART
生成器 p θ ( y i ∣ x , z , y 1 : i − 1 ) p_{\theta}(y_i|x,z,y_{1:i-1}) pθ(yi∣x,z,y1:i−1)能使用任何编解码器模型来建模,因此论文使用了BART-large模型。为了联合输入 x x x和检索出的文档 z z z,论文将两者拼接起来后输入到BART模型中。BART使用去噪目标和各种不同的去噪函数进行预训练。论文将BART生成器的参数 θ \theta θ称为参数化记忆。
2.4 训练
论文联合训练检索器和生成器组件,而不直接监督应该检索什么文档。给定输入/输出对的微调训练语料库 ( x j , y j ) (x_j,y_j) (xj,yj),论文最小化每个目标的负对数似然函数 ∑ j − log p ( y j ∣ x j ) \sum_{j}-\text{log}p(y_j|x_j) ∑j−logp(yj∣xj)。训练中冻结 BERT d \text{BERT}_d BERTd,微调 BERT q \text{BERT}_q BERTq和BART。
2.5 解码
在预测时,RAG-Sequence和RAG-Token需要不同的方式来近似 arg max y p ( y ∣ x ) \arg\max\limits_yp(y|x) argymaxp(y∣x)。
2.5.1 RAG-Sequence
为了解码,论文使用 p θ ( y ∣ x , z i ) p_{\theta}(y|x,z_i) pθ(y∣x,zi)来对每个文档进行beam搜索,然后得到一系列候选集 Y Y Y。对于 Y Y Y中未出现在所有文档beam搜索结果的序列 y y y,需要通过如下公式重新计算概率:
p θ ( y ∣ x , z i ) = ∏ t N p θ ( y t ∣ x , z i , y 1 : t − 1 ) . p_{\theta}(y|x,z_i)=\prod_t^Np_{\theta}(y_t|x,z_i,y_{1:t-1}). pθ(y∣x,zi)=t∏Npθ(yt∣x,zi,y1:t−1).
接着计算 y y y在所有文档上的概率:
p ( y ∣ x ) = ∑ z ∈ top − k ( p ( ⋅ ∣ x ) ) p η ( z ∣ x ) p θ ( y ∣ x , z ) . p(y|x)=\sum_{z\in\text{top}-k(p(·|x))}p_{\eta}(z|x)p_{\theta}(y|x,z). p(y∣x)=z∈top−k(p(⋅∣x))∑pη(z∣x)pθ(y∣x,z).
以上是彻底解码的过程。为了避免过多的计算量,当 y y y没有出现文档 z i z_i zi的候选集中时,假设 p θ ( y ∣ x , z i ) ≈ 0 p_{\theta}(y|x,z_i)\approx0 pθ(y∣x,zi)≈0。这是快速解码与彻底解码的不同之处。
2.5.2 RAG-Token
RAG-Token模型可以被看作一个标准的带有转移概率、自回归的seq2seq生成器。转移概率为:
p θ ′ ( y i ∣ x , y 1 : i − 1 ) = ∑ z ∈ top − k ( p ( ⋅ ∣ x ) ) p η ( z i ∣ x ) p θ ( y i ∣ x , z i , y 1 : i − 1 ) . p'{\theta}(y_i|x,y{1:i-1})=\sum_{z\in\text{top}-k(p(·|x))}p_{\eta}(z_i|x)p_{\theta}(y_i|x,z_i,y_{1:i-1}). pθ′(yi∣x,y1:i−1)=z∈top−k(p(⋅∣x))∑pη(zi∣x)pθ(yi∣x,zi,y1:i−1).
为了解码,论文将 p θ ′ ( y i ∣ x , y 1 : i − 1 ) p'{\theta}(y_i|x,y{1:i-1}) pθ′(yi∣x,y1:i−1)送入到beam搜索中产生多个最优序列。
2.6 使用RAG对指定数据集进行检索
代码:
python
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-nq", retriever=retriever)
input_dict = tokenizer("who holds the record in 100m freestyle", return_tensors="pt")
generated = model.generate(input_ids=input_dict["input_ids"])
print(tokenizer.batch_decode(generated, skip_special_tokens=True)[0])结果:
bash
michael phelps3. 创新点和不足
3.1 创新点
RAG的核心创新点在于提出了一种融合参数化与非参数化记忆的混合架构,通过端到端训练实现了检索与生成的协同优化。该研究首次将预训练序列生成模型(如BART-large)与基于密集向量索引的外部知识库(如维基百科)动态结合,允许模型在生成过程中实时检索并利用外部知识。不同于传统模型依赖固定参数化知识,RAG通过最大内积搜索(MIPS)从海量文档中筛选前K个相关片段作为上下文,并将检索结果作为潜在变量进行边缘化处理,既保留生成灵活性又增强事实一致性。此外,RAG开创性地设计了两种解码策略------RAG-Sequence(全局依赖单一文档)和RAG-Token(逐token动态切换文档),分别适应不同任务对连贯性与多样性的需求。该方法还突破了传统模型知识更新的瓶颈,仅需替换外部索引即可实现知识库的动态迭代,无需重新训练整个模型,同时通过检索增强显著降低了生成内容的幻觉风险。
3.2 不足
检索过程高度依赖外部知识库的质量和检索器的准确性,当检索到无关或错误文档时(如包含过时信息或语义漂移的段落),生成器可能被误导而产生事实性幻觉;检索算法对关键词匹配的过度依赖导致其难以捕捉复杂语义关系,例如同义词替换或跨领域概念的关联性,尤其在处理长尾知识时召回率显著下降;生成阶段的信息整合能力受限,当多个检索片段存在矛盾或冗余时,模型缺乏有效的冲突消解机制,可能导致生成内容逻辑断裂或关键细节遗漏。此外,系统架构的静态性制约了动态适应能力,无法像人类一样根据反馈实时调整检索策略,且文档索引的更新需要人工干预,难以应对高频知识迭代场景。
参考
Patrick Lewis, Ethan Perez, Aleksandra Piktus, and et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
总结
RAG的训练流程:首先通过查询编码器编码查询得到 q ( x ) q(x) q(x),接着将所有文档通过文档编码器编码为文档索引 d ( z ) d(z) d(z),再由 q ( x ) q(x) q(x)和 d ( z ) d(z) d(z)计算出所有文档的得分,然后通过最大内积搜索法得到前K个文档,接着按照RAG-Token或RAG-Sequence的方式将输入 x x x、文档 z z z、之前所有的目标序列输入到生成器。尽管RAG在某些领域上回答问题的效果好,但是它仍然面临以下的问题:知识滞后、语义失准、检索僵化、冗余冲突等。