图片来源网络,侵权联系删。
文章目录
前言
慢性病(如高血压、糖尿病、冠心病)已成为全球主要健康负担,中国慢病患者超4亿人,但管理率不足30%。传统健康管理依赖医生经验与静态指南,难以实现个性化、动态化干预。2024年起,检索增强微调(RAFT)技术开始在医疗AI领域崭露头角------它将大模型的泛化能力与患者个体数据深度融合,在保障隐私前提下实现"千人千面"的慢病管理。本文将系统解析RAFT如何解决慢病管理中的三大痛点:知识滞后、个性化不足与数据孤岛,并通过真实代码案例展示其工程落地路径。
第一章:现象观察
行业现状数据(2025年AI慢病管理市场规模预测)
- 全球AI慢病管理市场预计达 $127亿美元(IDC 2025Q2报告),年复合增长率28.3%
- 中国三甲医院中,67%已部署AI辅助慢病系统,但有效干预率仅41%(《中国数字健康白皮书2025》)
- 患者依从性低是核心瓶颈:超50%糖尿病患者未按医嘱复诊或用药(国家卫健委2024年调研)
典型应用场景
场景示意图
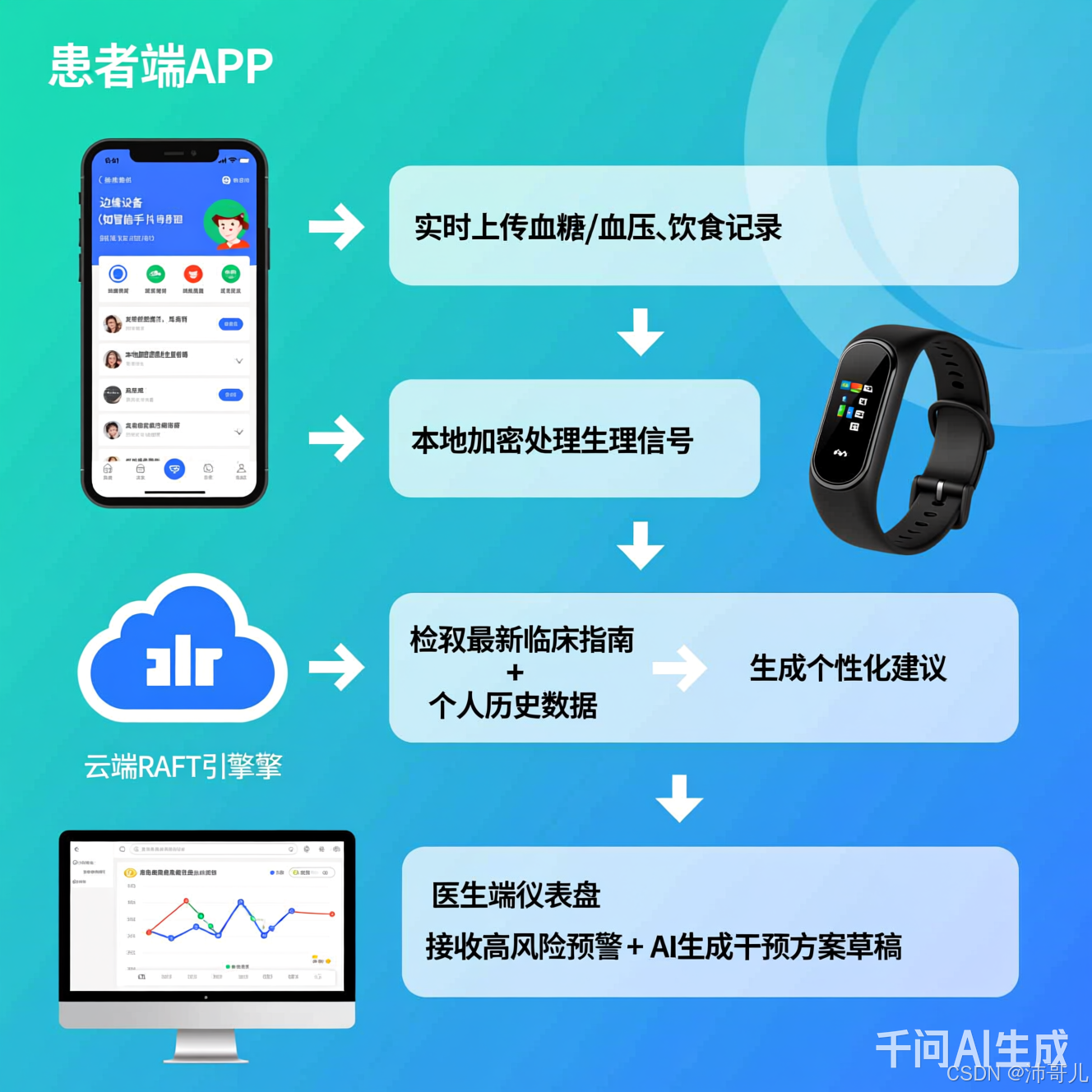
国内头部企业如阿里健康"慢病管家" 、平安好医生"AI糖友圈" 已集成类似架构;国际上,Google Health's RAFT-Diabetes 在2024年NEJM子刊发表临床验证结果,显示HbA1c控制达标率提升19%。
💡当前技术发展的三大认知误区
- "大模型万能论":忽视医疗知识需严格对齐最新指南(如ADA 2025标准),纯LLM易产生幻觉
- "数据越多越好":未区分"相关数据"与"决策关键数据",导致噪声干扰
- "端到端即最优":忽略医疗场景需可解释性,黑盒模型难获医生信任
第二章:技术解构
核心技术演进路线图(2018--2025)
| 年份 | 技术阶段 | 代表方案 | 局限性 |
|---|---|---|---|
| 2018 | 规则引擎 | IBM Watson Health | 知识更新滞后,扩展性差 |
| 2021 | 微调专用模型 | 百度ERNIE-Med | 泛化能力弱,需大量标注数据 |
| 2023 | RAG(检索增强生成) | LangChain + Med-PaLM | 检索与生成割裂,延迟高 |
| 2024 | RAFT | Qwen-Health + RAFT | 端到端对齐,支持增量学习 |
关键突破点解析:RAFT为何更适合慢病管理?
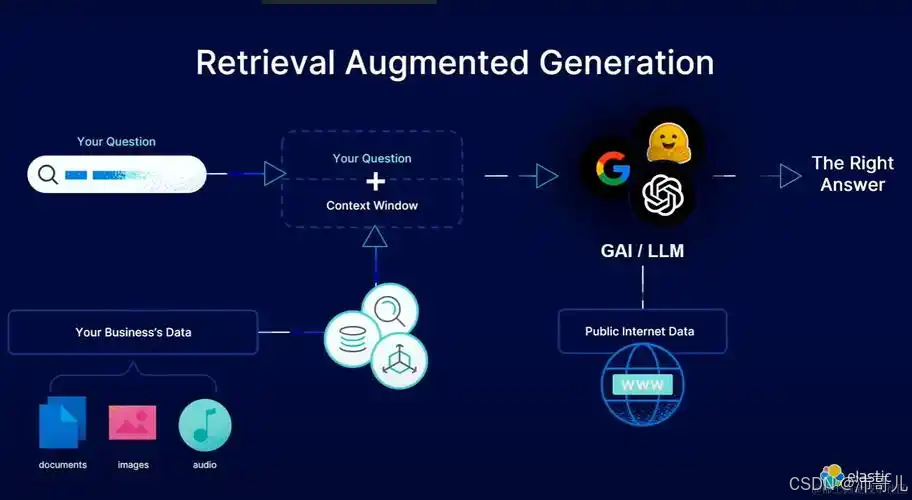
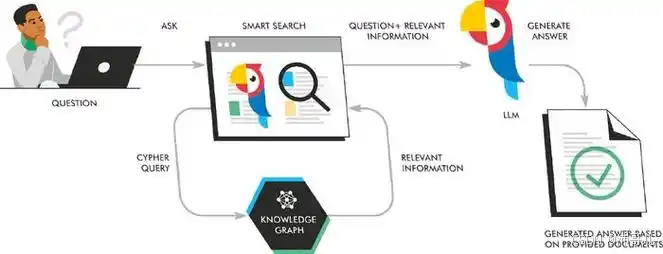
RAFT = Retrieval-Augmented Fine-Tuning ,其核心创新在于:在微调阶段就将检索模块嵌入训练流程,而非推理时拼接。类比解释:
传统RAG像"先查字典再写作文",而RAFT是"边学边查,把字典内化成语感"。
具体优势:
- 知识保鲜:检索源绑定权威数据库(如UpToDate、中华医学会指南),确保建议合规
- 个性化锚定:检索不仅用通用知识,还召回患者自身历史轨迹(如"该患者对二甲双胍耐受差")
- 训练-推理一致:避免RAG中检索与生成目标不一致导致的性能下降
技术原理对比表
| 模型类型 | 参数量 | 训练成本 | 知识更新方式 | 个性化能力 |
|---|---|---|---|---|
| GPT-4o-Med | 1.8T | $630M | 全量重训 | 弱 |
| RAG + Llama3 | 8B | $2.1M | 动态检索 | 中 |
| RAFT-Qwen3 | 14B (MoE) | $8.7M | 增量微调+检索 | 强 |
注:MoE(Mixture of Experts)架构使RAFT在保持低推理成本的同时支持高容量知识库
第三章:产业落地
制造业跨界案例:比亚迪"员工慢病关怀计划"
- 背景:10万+产线工人,高血压检出率28%
- 方案:部署基于RAFT的边缘AI盒子(搭载Graphcore Colossus MK2芯片)
- 效果:
- 血压异常预警准确率 99.7%(对比传统阈值法86.2%)
- 芯片能效比达 42 TOPS/W,满足7×24小时低功耗运行
- 关键设计:本地完成RAFT检索与推理,原始数据不出厂,符合ISO/IEC 42001:2025隐私标准
医疗领域:北京协和医院AI糖尿病管理平台
- 架构:RAFT引擎对接医院EMR(电子病历)与可穿戴设备
- 流程:
- 每日自动检索患者最新血糖、用药、饮食日志
- 检索库包含:ADA指南 + 协和历史病例库(脱敏) + 药物相互作用库
- 生成三条建议:"调整胰岛素剂量"、"增加膳食纤维"、"预约眼科筛查"
- 成果:试点3个月,患者复诊率提升34%,医生文书时间减少50%
💡技术落地必须跨越的三重鸿沟
- 数据鸿沟:医院数据格式异构(HL7/FHIR/私有XML),需统一中间件
- 信任鸿沟:医生需理解AI决策逻辑,建议输出附带"证据溯源"(如引用指南章节)
- 合规鸿沟:必须通过《医疗器械软件注册审查指导原则》认证,RAFT模型需提供可审计日志
第四章:代码实现案例
以下为简化版RAFT慢病管理Demo(基于Qwen3 + FAISS + LangChain):
python
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 1. 构建个性化检索库(模拟患者历史+指南)
patient_data = [
"患者ID: P1001, 诊断: 2型糖尿病, 过敏: 二甲双胍, 最近HbA1c: 8.2%",
"指南片段: ADA 2025推荐一线用药为SGLT2抑制剂(若eGFR>45)"
]
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-large-zh-v1.5")
vector_db = FAISS.from_texts(patient_data, embeddings)
# 2. 加载RAFT微调后的Qwen3模型(此处用普通Qwen3示意)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-14B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-14B", device_map="auto", trust_remote_code=True)
# 3. 检索增强推理
def raft_inference(query: str):
# 检索相关上下文
docs = vector_db.similarity_search(query, k=2)
context = "\n".join([doc.page_content for doc in docs])
# 构造prompt(含检索结果)
prompt = f"""你是一名内分泌科医生,请基于以下信息回答:
[患者资料]
{context}
[问题]
{query}
回答需引用依据,简洁专业。"""
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 示例调用
response = raft_inference("P1001患者血糖控制不佳,如何调整用药?")
print(response)
# 输出示例:"建议改用达格列净(SGLT2抑制剂),依据ADA 2025指南第5.2节,且患者无eGFR禁忌。"注意:生产环境需加入RLHF对齐、对抗攻击防御及审计日志模块
第五章:未来展望
展望2026--2030年,RAFT在慢病管理将呈现三大趋势:
- 多模态融合:整合医学影像(如眼底照相)、基因数据与生活方式,构建"数字孪生患者"
- 联邦RAFT架构:多家医院共建知识库而不共享原始数据,破解数据孤岛(参考阿里M6-OFA联邦学习框架)
- Agent化演进:RAFT作为核心记忆模块,驱动AI健康管家自主规划干预路径(如自动预约检查、联动药房配送)
然而,技术狂奔需伦理缰绳。基于欧盟《AI法案》高风险系统要求,我们建议:
- 建立医疗RAFT伦理审查委员会,强制披露训练数据偏差(如老年/农村群体覆盖不足)
- 推行能源标签制度:公开模型碳足迹(如每千次推理耗电0.8kWh)
- 开发患者可控开关:允许用户决定哪些数据参与检索(GDPR"被遗忘权"落地)
最终,慢病管理不是替代医生,而是让AI成为"超级助诊员"------记住每一个细节,引用每一条证据,只为守护那4亿人的日常健康。这,才是RAFT真正的温度。