引言
由于GUI小工具【Deepseek API+Python 测试用例一键生成与导出】的不断升级实践,发现大模型的需求文档解析生成测试用例的可直接复用率不太理想,因此萌生了对老旧系统升级改造的想法。旧测试用例生成平台主要在于采集用户输入的字段名称、字段类型及具体的值静态规则和有限的自动化脚本进行用例生成,具有相当的局限性。然而,随着人工智能技术的发展,特别是大语言模型的应用,我们有机会革新这一过程,使测试用例的生成更加智能、高效且准确。本文将详细介绍如何通过阿里云百炼deepseek-r1接口对老旧测试平台的页面查询功能进行智能化升级,从而提升测试效率和质量。由于GUI小工具的不断升级实践,对用例生成平台也进行同步升级改造。
GUI小工具:
Deepseek API+Python 测试用例一键生成与导出 V1.0.6(加入分块策略,返回更完整可靠)
老旧平台:
测试用例生成平台,源码分享
首先简要介绍一下Django项目的启动。
启动Django项目
完成上述步骤后,你可以按照如下步骤启动你的Django项目:
-
进入项目目录
切换到包含
manage.py文件的项目根目录:bashcd myproject -
启动Django开发服务器
使用以下命令启动Django的内置开发服务器:
bashpython manage.py runserver
项目背景与目标
在开始之前,让我们先了解一下项目的背景和目标。老旧测试平台通常依赖于静态规则和有限的自动化脚本,这限制了它们适应复杂业务逻辑变化的能力。我们的目标是利用AI的力量来动态生成测试用例,不仅能够覆盖基本的功能需求,还能应对各种异常情况和边界条件。
技术实现细节
函数 search_page_generate_case_by_ai
该函数作为整个智能测试用例生成的核心入口点,首先打印信息表示开始异步大模型用例生成的过程,并仅响应POST请求以确保从前端接收包含所需参数的数据包。
python
def search_page_generate_case_by_ai(request):
print('开始进行异步大模型用例生成')
if request.method == 'POST':
# 收集用户输入的信息并准备数据数据收集与准备
1.进入常用功能用例管理-->查询功能用例管理页面。
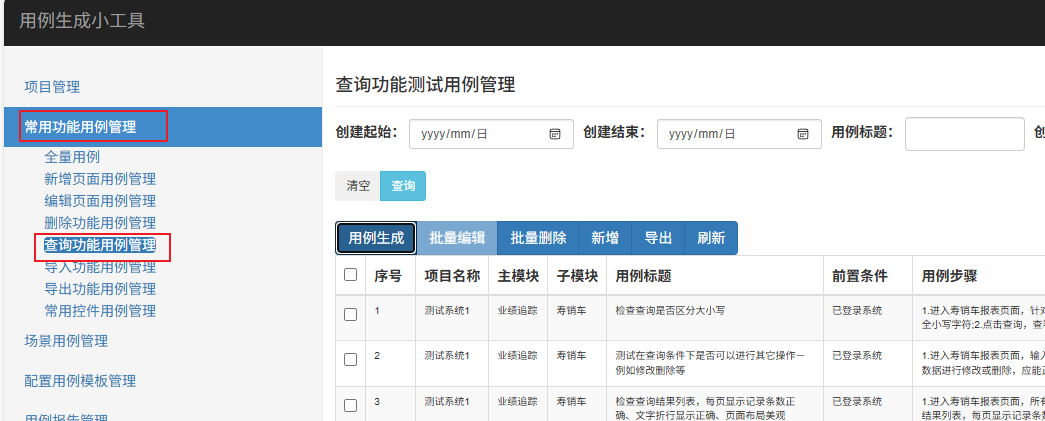
2.点击用例生成,选择系统,输入所属模块及页面名称,输入具体的查询字段及字段类型和枚举值。
json
{'字段名称': '品牌', '字段类型': '单选', '枚举值': '爱他美、美赞臣'}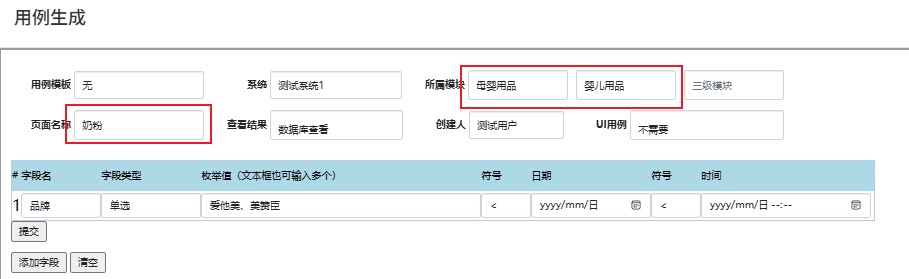
从请求中提取系统名称、模块名称、前置条件等必要信息,并为后续处理做准备。此步骤包括获取项目详细信息及ID。
python
project = Project.objects.get(project_name=case_system)
project_id = project.id3.构造提示词
generate_testcase_prompt 函数负责构造一个详细的提示词,用于指导大模型根据提供的系统名称、模块名称、页面名称以及参数列表来生成测试用例。这里定义了一系列测试方法及其描述、步骤和覆盖率标准,确保生成的测试用例能够覆盖各种情况。
python
method_library = {...}
desc_str = ''
method_list = ['等价类划分']
# 根据选择的方法构建描述字符串
for method in method_list:
selected_method = method_library.get(method, method_library["正交分析法"])
desc_str += f"""
使用{method}方法设计用例时要符合:{selected_method['desc']}
...
"""提示词效果如下:
txt
Role: 测试用例设计专家
Rules:
设计目标:
通过['等价类划分']实现:
用例数量:
尽可能多(不少于15条),若无法满足数量,以质量优先
系统名称: 测试系统1
模块: 母婴用品>>婴儿用品
页面名称: 奶粉
具体功能: 页面查询功能
用例设计需遵循:
使用等价类划分方法设计用例时要符合:将输入划分为有效/无效类,每个类选取代表值测试
关键步骤:
1. 定义有效等价类
2. 定义无效等价类
3. 生成代表值
示例:
[
{
"用例编号": "LOGIN-001",
"用例标题": "登录功能 [有效等价类]",
"前置条件": "用户已注册",
"测试数据": {
"用户名": "valid_user",
"密码": "correct_password"
},
"操作步骤": [
"1. 打开登录页面",
"2. 输入用户名为valid_user",
"3. 输入密码为correct_password",
"4. 点击登录按钮"
],
"预期结果": "登录成功,跳转到首页",
"优先级": "P1"
},
{
"用例编号": "LOGIN-002",
"用例标题": "登录功能 [无效等价类]",
"前置条件": "用户已注册",
"测试数据": {
"用户名": "invalid_user",
"密码": "random_password"
},
"操作步骤": [
"1. 打开登录页面",
"2. 输入用户名为invalid_user",
"3. 输入密码为random_password",
"4. 点击登录按钮"
],
"预期结果": "登录失败,提示用户名或密码错误",
"优先级": "P1"
}
]
质量标准:
- 每个等价类至少1个用例
- 正向场景用例占比60%
- 异常场景用例占比30%
- 边界场景用例占比10%
- 不要出现"A".repeat(300)这种数据,可以以输入300字符替换
参数:
字段名称:品牌;字段类型:单选;枚举值:爱他美、美赞臣
输出要求:
1. 格式:结构化JSON
2. 字段:
- 用例编号:<模块缩写>-<3位序号>
- 用例标题:<测试目标> [正例/反例]
- 前置条件:初始化状态描述
- 测试数据:参数值的具体组合,若需要测试字符长度测试,直接指定需用户输入多少字符;参数不要自行幻想;
- 操作步骤:带编号的明确步骤
- 预期结果:可验证的断言
- 优先级:P0(冒烟)/P1(核心)/P2(次要)
生成步骤:
1. 参数建模 → 2. 场景分析 → 3. 用例生成 → 4. 交叉校验调用大模型API
调用大模型API是整个智能测试用例生成过程中最关键的一环,它直接决定了最终输出的测试用例的质量和适用性。这一部分将详细解析如何通过阿里云百炼deepseek-r1接口来实现智能化的测试用例生成。
初始化OpenAI客户端
在generate_cases函数中,我们首先需要初始化一个OpenAI客户端实例。这个实例用于与阿里云百炼deepseek-r1服务进行通信。这里需要注意的是,实际应用中需要替换为有效的API密钥,并根据实际情况调整基础URL。获取API-KEY可以参考:结合pageassist与阿里百炼api实现deepseek-r1联网搜索功能
python
client = OpenAI(
api_key='sk-712a634dbaa7444d838d20b25eb938xx', # 替换为你的API密钥
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 根据需要调整
)构建请求消息
为了向大模型发送请求,我们需要构造一条包含用户角色和内容的消息。这里的"内容"即是我们之前通过generate_testcase_prompt函数精心准备的提示词(prompt),它包含了所有必要的上下文信息,如系统名称、模块名称、页面名称、参数列表等。
python
messages=[
{'role': 'user',
'content': prompt_param}
]发送请求并处理响应
接下来,我们使用client.chat.completions.create方法来发送请求。该方法接受一系列参数,包括模型名称(在这里使用的是deepseek-r1)、请求消息以及是否启用流式响应。
python
completion = client.chat.completions.create(
model="deepseek-r1", # 使用的模型名称
messages=messages,
stream=True, # 启用流式响应
)启用流式响应可以让我们实时接收来自大模型的输出,这对于长文本或复杂任务特别有用,因为它允许我们在接收到一部分结果时就开始处理,而不是等待整个过程完成。
处理流式响应
一旦请求被发送出去,我们将进入一个循环来处理返回的流式数据。每个数据块(chunk)都可能包含新的信息,我们需要对这些信息进行处理。
python
reasoning_content = "" # 定义完整思考过程
answer_content = "" # 定义完整回复
is_answering = False # 判断是否结束思考过程并开始回复
for chunk in completion:
if not chunk.choices:
print("\nUsage:")
print(chunk.usage)
else:
delta = chunk.choices[0].delta
if hasattr(delta, 'reasoning_content') and delta.reasoning_content is not None:
print(delta.reasoning_content, end='', flush=True)
reasoning_content += delta.reasoning_content
else:
if delta.content != "" and not is_answering:
print("\n" + "=" * 20 + "完整回复" + "=" * 20 + "\n")
is_answering = True
print(delta.content, end='', flush=True)
answer_content += delta.content在这个循环中,我们首先检查是否有可用的选择(choices)。如果存在,我们进一步检查是否存在推理内容(reasoning_content)。如果有,我们会将其添加到reasoning_content变量中;否则,我们认为这是大模型开始提供答案的标志,并将相应的内容追加到answer_content中。
结果整合
最后,经过处理的所有回答内容被整合在一起,形成最终的输出结果。这部分内容可以直接展示给用户,或者根据具体需求进一步处理。
python
return answer_content通过上述步骤,我们能够有效地利用阿里云百炼deepseek-r1的强大能力,自动且智能地生成高质量的测试用例,大大提高了测试效率和准确性。这不仅减轻了测试工程师的工作负担,也为软件开发流程中的自动化测试提供了强有力的支持。
结果解析与展示
为了确保结果可以被正确地解析和展示,extract_json_objects 函数用于从大模型返回的结果中提取有效的JSON对象。
python
json_objects = []
matches = re.findall(r'```json\s*([\s\S]*?)```', text, re.DOTALL)
for match in matches:
try:
json_objects.append(json.loads(match))
except json.JSONDecodeError as e:
print(f"Error decoding JSON: {e}")
print(match)
continue
return json_objects
页面展示效果:

对预览的用例可以执行写入数据库操作。
结论
通过对老旧测试平台的页面查询功能进行智能化改造,我们不仅提高了测试用例生成的效率和准确性,还显著减轻了测试工程师的工作负担。这种基于AI的方法让测试变得更加科学和精确,同时也为未来的自动化测试执行和结果分析铺平了道路。随着更多高级特性的集成,我们可以期待看到软件测试领域发生更大的变革,进一步提升软件质量和用户体验。持续改造升级中,希望可以越做越好,欢迎大家一起沟通交流学习。