目录
[📌 核心特性](#📌 核心特性)
[📌 运行原理](#📌 运行原理)
[📌 缓存机制](#📌 缓存机制)
Streamlit 是一个开源的 Python 库,专为快速构建数据科学和机器学习 Web 应用而设计。它无需前端开发经验,通过简单 API 即可创建交互式界面,适合原型开发和数据展示
Streamlit官方地址:Streamlit • A faster way to build and share data apps
📌 核心特性
- 极简代码:用纯 Python 实现界面交互
- 实时预览:保存代码后自动刷新页面
- 丰富组件:支持图表、表格、滑块、文件上传等
- 无缝集成:兼容 Pandas、Matplotlib、PyTorch 等主流库
安装Streamlit
bash
pip3 install streamlit先通过一个简单的Hello World案例来了解Streamlit
python
import streamlit as st
# 显示标题
st.title("Hello World,I'm echola")
# 显示文本
st.write("这是一个由Streamlit搭建的Web平台")运行:
bash
streamlit run hello.py结果:
 是不是很强悍,三行代码搞定一个Web应用
是不是很强悍,三行代码搞定一个Web应用
📌 运行原理
Streamlit 的运行逻辑围绕脚本的线性执行 和响应式更新展开,其核心设计是让开发者以极简的方式构建交互式应用。以下是关键逻辑分步解析:
1、启动Web服务器
- Streamlit 启动一个本地 Web 服务器,默认监听 8501 端口
- 打开浏览器并导航到http://localhost:8501,展示应用界面
2、解析和执行脚本:
- Streamlit 解析hello.py文件,生成抽象语法树(AST)
- 动态执行脚本中的代码,按照顺序执行每个 Streamlit 组件(如 st.title 和 st.write)
3、组件渲染
- 每个 Streamlit 组件(如st.title和 st.write)会被注册到当前页面的状态中
- 页面会根据组件的顺序和内容进行渲染
4、实时更新:
- 基于Websocket通信:浏览器与服务器保持长连接,脚本输出的文本、图表等实时推送至前端
- 增量更新机制:Streamlit只能对比前后两次执行的输出差异,仅向浏览器发送差异部分,也就是只更新变化的部分(而非刷新整个页面),Streamlit 会自动重新运行政整个脚本(而非局部更新)并更新页面,确保了开发过程中的高效性和实时性
上述增量更新可能会有一点矛盾,简而言之就是,「全脚本执行 + 差异更新 」的设计,让 Streamlit 在开发便捷性 (无需手动管理更新)和运行效率(局部渲染)之间取得了完美平衡
(1)全脚本执行
⚠️:也要避免全局作用域的冗余计算(需用缓存优化)
下来使用一个简单的案例,来模拟Streamlit加载全脚本的耗时过程
python
import time
import streamlit as st
# 全脚本执行部分:以下代码每次交互都会运行
st.title("TimeOut Example") # ✅ 标题会重复渲染,但 Streamlit 会优化为"增量更新"
# 局部增量执行:以下代码仅在按钮点击时触发
if st.button("Click me"):
processing_bar = st.progress(0) # 每次点击时新建进度条
with st.spinner("Loading..."):
for percent_complete in range(100):
time.sleep(0.05)
processing_bar.progress(percent_complete + 1)
st.success("Loading completed!")当用户点击按钮时,触发 if 条件判断,显示加载提示框 "Loading..."。开始模拟耗时操作,通过循环和 time.sleep 模拟耗时。每次循环中,更新进度条的值,进度条从0%逐渐增加到100%
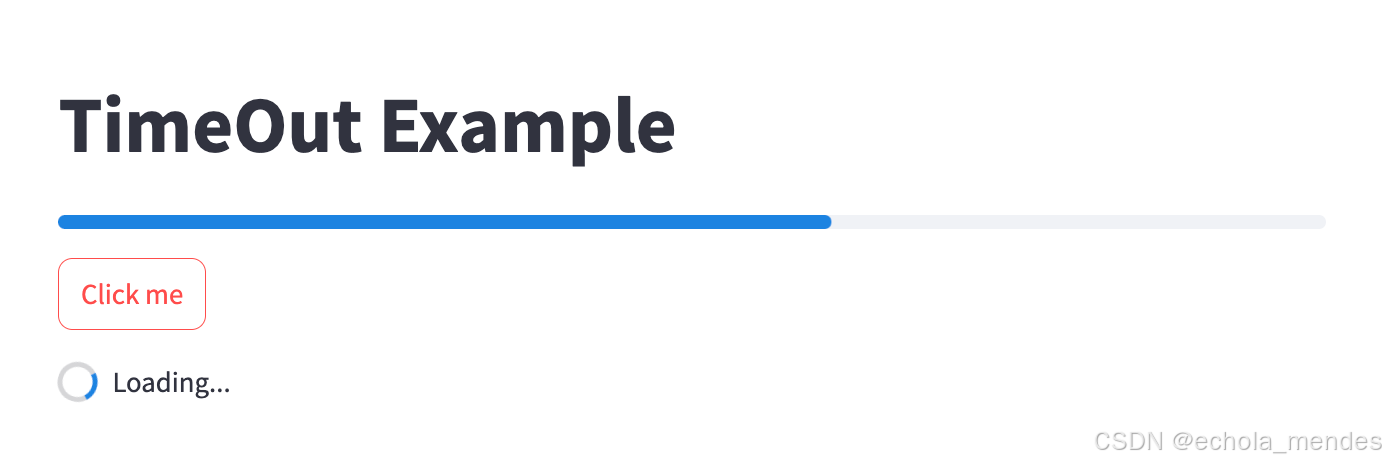
直至耗时完成5s后,隐藏加载提示框,显示成功消息框"Loading completed"

再次点击【Click me】, 重复上述效果图
可以从上述效果中看出,无论是页面首次加载、按钮点击,还是其他组件交互(如下拉框选择),Streamlit都会从头到尾重新执行整个脚本
虽然脚本会全量执行,但Streamlit内部通过智能的组件状态管理和缓存机制,只更页面中发生变化的部分(如按钮触发的进度条),而不是刷新整个页面
接下来会使用缓存机制进行优化
(2)差异更新
可以高效渲染(减少网络传输数据量和浏览器渲染开销)和无缝体验(用户输入状态,如:文本框焦点、滚动条位置,不会因为局部更新而丢失)
⚠️:也要关注复杂UI的组件键(Key)的稳定性
📌 缓存机制
❓为什么使用缓存?
🔴 问题 :每次点击click按钮时,代码会从执行整个耗时操作(for循环 +time.sleep),即使操作结果不变
🥀 缓存的作用:将耗时操作的结果缓存起来,后续重复调用时直接读取缓存,避免重复计算
解决重复计算问题:通过装饰器**@st.cache_data**(缓存数据)或**@st.cache_resource**(缓存资源如模型、数据库连接),避免脚本执行导致的重复计算
python
@st.cache_data
def heavy_computation():
# 此函数仅在输入参数或代码变更时重新执行
return result使用**@st.cache_data****的优化方案**
那优化一下上面提到的问题
python
import time
import streamlit as st
st.title("Optimize Example")
# 缓存耗时操作的结束(假设操作是无参数)
@st.cache_data
def expensive_operation():
# 模拟耗时操作(例如:数据计算)
result = []
for _ in range(100):
time.sleep(0.05) # 假设这是实际的计算步骤
result.append(_) # 模拟中间结果
return result
if st.button("Click me"):
processing_bar = st.progress(0) # 每次点击时新建进度条
with st.spinner("Loading..."):
# 获取数据(首次点击执行耗时操作,后续点击直接读缓存)
data = expensive_operation()
for percent_complete in range(len(data)):
processing_bar.progress(percent_complete + 1)
st.success("Loading completed!")首次点击【Click me】,会出现

大概5s后,执行完成
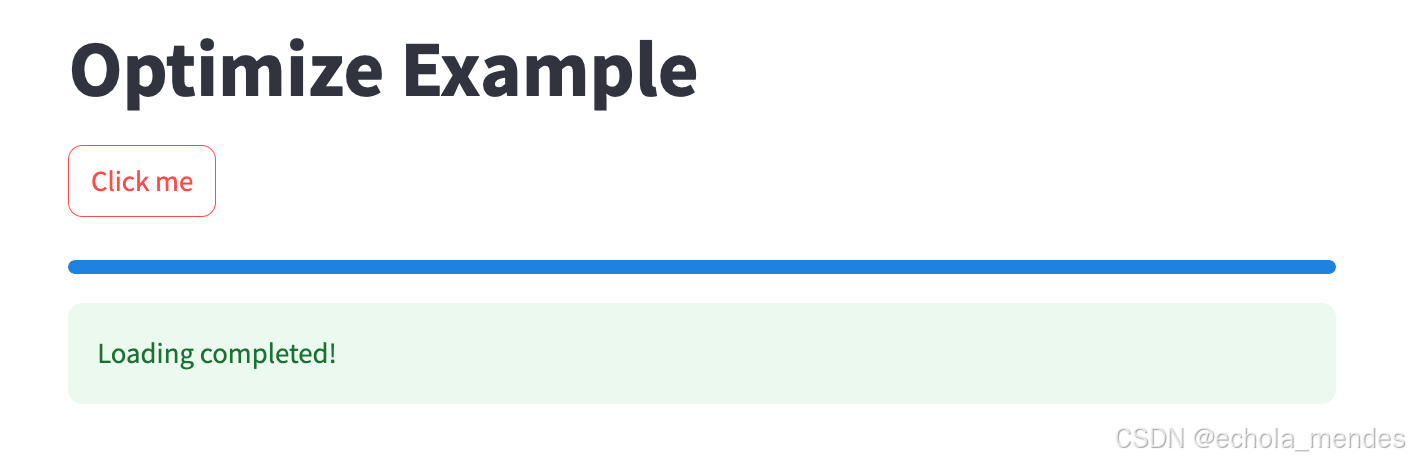 重复点击【Click me】 ,不会重复加载进度条,由于直接读取缓存结果,无需重复计算,数据已缓存,进度条会快速更新到100%
重复点击【Click me】 ,不会重复加载进度条,由于直接读取缓存结果,无需重复计算,数据已缓存,进度条会快速更新到100%
通过 @st.cache_data装饰器缓存耗时操作的结果,避免每次点击按钮时都重新执行耗时操作
不是所有耗时操作都必须使用缓存
缓存适用场景
- 需要缓存的场景 :
- 耗时操作的结果是 静态的(例如读取文件、初始化模型、复杂计算)。
- 操作结果 不依赖外部变量或用户输入。
- 不适用缓存场景 :
- 操作结果 依赖动态参数(例如用户输入的变量),此时需通过函数参数触发缓存更新。
- 操作需要 实时更新(例如每次点击都需重新计算)
如果耗时操作 依赖参数,可以通过函数参数控制缓存版本:
python
@st.cache_data
def expensive_operation(param1, param2):
# 根据参数执行不同计算
results = []
for _ in range(100):
time.sleep(0.05)
results.append(param1 + param2 + _)
return results
# 在按钮点击时传入参数
data = expensive_operation(10, 20) # 参数不同会生成不同缓存可以看出:
- 缓存机制 :通过 **
@st.cache_data**缓存静态计算结果,减少重复执行。 - 进度条优化:将耗时操作与进度条更新分离,首次加载缓存后,后续交互可快速完成
那上述代码就没有什么问题了吗?
⚠️接下来分析原代码存在的弊端:
- 进度条重复创建 :每次点击按钮都会新建processing_bar,导致多次点击时进度条堆叠
- 无法阻止重复提交:在耗时操作执行期间,用户仍可多次点击按钮,导致逻辑混乱
- 状态丢失:进度完成后的状态(如success提示)无法持久化
使用st.session_state的优化方案
1、保存进度条实例
python
if "processing_bar" not in st.session_state:
st.session_state.processing_bar = None # 初始化进度条容器
if st.button("Click me"):
# 仅在第一次点击时创建进度条
if not st.session_state.processing_bar:
st.session_state.processing_bar = st.progress(0)
# 后续操作复用已有进度条
with st.spinner("Loading..."):
data = expensive_operation()
for i in range(len(data)):
st.session_state.processing_bar.progress(i + 1)
# 完成后清空引用
st.session_state.processing_bar = None
st.success("Done!")2. 防止重复提交
python
if "is_processing" not in st.session_state:
st.session_state.is_processing = False # 状态锁
if st.button("Click me") and not st.session_state.is_processing:
st.session_state.is_processing = True # 锁定
try:
# 执行耗时操作...
finally:
st.session_state.is_processing = False # 释放3. 持久化完成状态
python
if "load_complete" not in st.session_state:
st.session_state.load_complete = False
if st.button("Click me"):
# 执行操作...
st.session_state.load_complete = True
if st.session_state.load_complete:
st.success("数据已加载完成!")
st.balloons() # 显示动画效果完整优化代码
python
import time
import streamlit as st
st.title("Optimized Example")
# 初始化会话状态
if "processing_bar" not in st.session_state:
st.session_state.processing_bar = None
if "is_processing" not in st.session_state:
st.session_state.is_processing = False
if "load_complete" not in st.session_state:
st.session_state.load_complete = False
@st.cache_data
def expensive_operation():
result = []
for _ in range(100):
time.sleep(0.05)
result.append(_)
return result
if st.button("Click me") and not st.session_state.is_processing:
st.session_state.is_processing = True
try:
# 创建或复用进度条
if not st.session_state.processing_bar:
st.session_state.processing_bar = st.progress(0)
with st.spinner("Loading..."):
data = expensive_operation()
for i in range(len(data)):
st.session_state.processing_bar.progress(i + 1)
st.session_state.load_complete = True
finally:
st.session_state.is_processing = False
st.session_state.processing_bar = None # 重置进度条
if st.session_state.load_complete:
st.success("操作成功!")
st.balloons()关键作用总结
| 会话状态项 | 功能说明 |
|---|---|
processing_bar |
保持进度条对象引用,防止重复创建 |
is_processing |
实现类似互斥锁,防止重复提交 |
load_complete |
持久化完成状态,实现跨脚本执行记忆 |
通过 st.session_state 实现了:
- 状态持久化:在 Streamlit 的全脚本重执行机制中保持关键状态
- 资源管理:避免 DOM 元素重复创建
- 交互安全:防止用户误操作导致的逻辑冲突
这种模式特别适合需要保持复杂交互状态的场景(如多步骤表单、长任务处理)
📌总结
通过 缓存机制 减少重复计算,结合 st.session_state 管理会话状态,Streamlit 可以高效处理复杂交互场景,同时保持代码简洁和用户体验流畅。这种优化策略尤其适合需要频繁交互、状态保持或耗时操作的 Web 应用开发