大纲
1.两阶段提交Two-Phase Commit(2PC)
2.三阶段提交Three-Phase Commit(3PC)
3.ZAB协议算法
4.ZAB协议与Paxos算法
5.zk的数据存储原理之内存数据
6.zk的数据存储原理之事务日志
7.zk的数据存储原理之数据快照
8.zk的数据存储原理之数据初始化和数据同步流程
1.两阶段提交Two-Phase Commit(2PC)
(1)数据库事务通过undo和redo保证数据强一致性
(2)分布式事务通过2PC保证数据强一致性
(3)2PC的优点和缺点
(1)数据库事务通过undo和redo保证数据强一致性
2PC即二阶段提交算法,是强一致性算法。它是数据库领域内,为了使基于分布式系统架构下的所有节点,在进行事务处理过程中能够保持原子性和一致性而设计的算法。所以很适合用作数据库的分布式事务,其实数据库经常用到的TCC本身就是一种2PC。
在InnoDB存储引擎中,对数据库的事务修改都会写undo日志和redo日志。其实不只是数据库,很多需要事务支持的都会用到undo和redo思路。
一.对一条数据的修改操作首先写undo日志,记录数据原来的样子
二.然后执行事务修改操作,把数据写到redo日志里
三.万一事务失败了,可以从undo日志恢复数据
数据库通过undo和redo能保证数据强一致性。
(2)分布式事务通过2PC保证数据强一致性
解决分布式事务的前提就是节点是支持事务的。在这个前提下,2PC把整个分布式事务分两个阶段:投票阶段(Prepare)和执行阶段(Commit)。
阶段一:投票阶段
在阶段一中,各参与者投票表明是否要继续执行接下来的事务提交操作。
步骤一:协调者向参与者发起事务询问。协调者向所有的参与者发送事务内容,询问是否可以执行事务操作,并开始等待各参与者的响应。
步骤二:参与者收到协调者的询问后执行事务。各参与者节点执行事务操作,并将undo和redo信息记入事务日志中。
步骤三:参与者向协调者反馈事务询问的响应。如果参与者成功执行事务操作,就反馈协调者Yes响应,表示事务可执行。如果参与者没成功执行事务,就反馈协调者No响应,表示事务不可执行。
阶段二:执行阶段
在阶段二中,协调者会根据各参与者的反馈来决定是否可以进行事务提交。有两种提交可能:执行事务提交和中断事务。
可能一:执行事务提交
假如协调者从所有参与者获得的反馈都是Yes响应,那么就会执行事务提交。
步骤一:协调者向参与者发送提交请求,协调者向所有参与者节点发出commit请求。
步骤二:参与者收到协调者的commit请求后进行事务提交。参与者接收到commit请求后,会正式执行事务提交操作,并在完成提交之后释放在整个事务执行期间占用的事务资源。
步骤三:参与者向协调者反馈事务提交结果(Ack消息)。参与者在完成事务提交之后,向协调者发送Ack消息。
步骤四:协调者收到所有参与者反馈(Ack)后完成事务。协调者接收到所有参与者反馈的Ack消息后,完成事务。

可能二:中断事务
假如任何一个参与者向协调者反馈了No响应或者等待超时,那么协调者无法接收到所有参与者的反馈响应,就会中断事务。
步骤一:协调者向参与者发送回滚请求,协调者向所有参与者节点发出rollback请求。
步骤二:参与者收到协调者的rollback请求后进行事务回滚。参与者接收到rollback请求后,会利用undo信息来执行事务回滚操作,并在完成回滚之后释放占用的事务资源。
步骤三:参与者向协调者反馈事务回滚结果(Ack消息)。参与者在完成事务回滚之后,向协调者发送Ack消息。
步骤四:协调者收到所有参与者反馈(Ack)后中断事务。协调者接收到所有参与者反馈的Ack消息后,完成事务中断。

(3)2PC的优点和缺点
一.2PC优点
优点一:原理简单
优点二:实现方便
二.2PC缺点
总结来说有四个缺点:同步阻塞、单点故障、数据不一致、容错机制不完善。
缺点一:同步阻塞
在二阶段提交过程中,所有节点都在等其他节点响应,无法进行其他操作,这种同步阻塞极大的限制了分布式系统的性能。
缺点二:单点问题
协调者在整个二阶段提交过程中很重要。如果协调者在提交阶段出现问题,那么整个流程将无法运转。而且其他参与者会处于一直锁定事务资源的状态中,无法完成事务操作。
缺点三:数据不一致
假设当协调者向所有参与者发送commit请求后,发生了局部网络异常。或者是协调者在尚未发送完所有commit请求之前自身发生了崩溃,导致最终只有部分参与者收到了commit请求,这将导致数据不一致问题。
缺点四:容错性不好
二阶段提交协议没有较为完善的容错机制,任意一个参与者或协调者故障都会导致整个事务的失败。
2.三阶段提交Three-Phase Commit(3PC)
(1)第一阶段canCommit
(2)第二阶段preCommit
(3)第三阶段doCommit
(4)3PC的优缺点
(5)3PC与2PC区别
(1)第一阶段canCommit
步骤一:协调者向参与者发起事务询问。协调者向所有参与者发送一个包含事务内容的canCommit请求。询问是否可以执行事务提交操作,并开始等待各参与者响应。
步骤二:参与者收到协调者的询问后反馈响应。参与者在接收到协调者的canCommit请求后,如果认为可以顺利执行事务,会反馈Yes响应并进入预备状态,否则反馈No响应。
这一阶段其实就是确认所有的资源是否都是健康、在线的。因为有了这一阶段,大大的减少了2PC提交的阻塞时间。
因为这一阶段优化了以下这种情况:2PC提交时,如果有两个参与者1和2而恰好参与者2出现问题,参与者1执行了耗时的事务操作,最后却发现参与者2连接不上。
(2)第二阶段preCommit
包含两种可能:执行事务预提交和中断事务。
可能一:执行事务预提交
假如协调者从所有参与者获得的反馈都是Yes响应,则执行事务预提交。
步骤一:协调者向参与者发送预提交请求。协调者向所有参与者发出preCommit请求,然后协调者会进入预提交状态。
步骤二:参与者收到协调者的preCommit请求后执行事务。参与者接收到协调者发出的preCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
步骤三:参与者向协调者反馈事务执行的响应(Ack)。如果参与者成功执行了事务操作,那么就会反馈给协调者Ack响应。
可能二:中断事务
假如任何一个参与者向协调者反馈了No响应,或者等待超时。协调者无法接收到所有参与者的反馈响应,那么就会中断事务。
步骤一:协调者向参与者发送中断请求,协调者向所有参与者节点发出abort请求。
步骤二:参与者收到协调者abort请求则中断事务。无论是收到来自协调者的abort请求,或者在等待协调者请求过程中出现超时,参与者都会中断事务。
(3)第三阶段doCommit
包含两种可能:执行提交和中断事务。
可能一:执行提交
接收到来自所有参与者的Ack响应。
步骤一:协调者向参与者发送提交请求。协调者向所有参与者发出doCommit请求,由预提交状态进入提交状态。
步骤二:参与者收到协调者的doCommit请求后提交事务。参与者接收到doCommit请求后,会正式执行事务提交操作,并在完成提交之后释放整个事务执行期间占用的事务资源。
步骤三:参与者向协调者反馈事务提交结果。参与者在完成事务提交之后,向协调者发送Ack消息。
步骤四:协调者收到所有参与者反馈(Ack)完成事务。协调者接收到所有参与者反馈的Ack消息后,完成事务。
可能二:中断事务
假如任何一个参与者向协调者反馈了No响应,或者等待超时。协调者无法接收到所有参与者的反馈响应,那么就会中断事务。
步骤一:协调者向参与者发送回滚请求,协调者向所有参与者节点发出abort请求。
步骤二:参与者收到协调者的abort请求后进行事务回滚。参与者接收到协调者的abort请求后,会利用undo信息执行事务回滚操作,并在完成回滚之后释放占用的事务资源。
步骤三:参与者向协调者反馈事务回滚结果(Ack消息)。参与者在完成事务回滚之后,会向协调者发送Ack消息。
步骤四:协调者收到所有参与者反馈(Ack)后中断事务。协调者接收到所有参与者反馈的Ack消息后,完成事务中断。
注意: 一旦进入阶段三doCommit,无论出现哪一种故障:协调者出现了问题、协调者和参与者之间网络故障,最终都会导致参与者无法及时接收来自协调者的doCommit或abort请求。参与者都会在等待超时后,继续进行事务提交。
(4)3PC的优缺点
三阶段提交协议的优点
优点一:改善同步阻塞
与2PC相比,降低了参与者的阻塞范围。
优点二:改善单点故障
与2PC相比,出现单点故障后能继续达成一致。
三阶段提交协议的缺点
缺点一:同步阻塞
相比2PC虽然降低阻塞范围,但依然存在阻塞。
缺点二:单点故障
虽然单点故障后能继续提交,但单点故障依然存在。
缺点三:数据不一致
正因出现单点故障后能继续提交,所以数据不一致。
缺点四:容错机制不完善
参与者或协调者节点失败会导致事务失败,所以数据库的分布式事务一般都是采用2PC,而3PC更多是被借鉴扩散成其他的算法。
(5)3PC与2PC区别
区别一:3PC第二阶段才写undo和redo事务日志。
区别二:3PC第三阶段协调者出现异常或网络超时参与者也会Commit。
3.ZAB协议算法
(1)ZAB协议介绍
(2)ZAB协议的消息广播模式
(3)ZAB协议的崩溃恢复模式
(4)崩溃恢复模式中完成Leader选举后的数据同步
(1)ZAB协议介绍
一.ZAB协议的一主多从模式
二.ZAB协议的三个保证
三.Leader和非Leader对事务请求的处理
四.ZAB协议的由三个主要步骤
五.ZAB协议的两种基本模式
ZAB协议是为分布式协调服务zk设计的一种支持崩溃恢复的原子广播协议。它在设计之初并没有要求具有很好的扩展性,最初只是为了应对高吞吐量、低延迟、健壮、简单的分布式场景。ZAB协议并不像Paxos算法那样是一种通用的分布式一致性算法,它是特别为zk设计的支持崩溃恢复的原子广播算法。
一.ZAB协议的一主多从模式
zk主要依赖ZAB协议来实现分布式数据一致性。ZAB协议采用主从模式的系统架构来保证集群间各副本数据的一致性。具体如下:
ZAB协议会使用一个单一的主进程来接收并处理客户端的所有事务请求,然后该主进程会将请求的处理结果以Proposal形式广播到所有副本进程中。
二.ZAB协议的三个保证
保证同一时刻集群中只有一个主进程来广播数据变更,保证一个全局的变更序列被顺序应用,保证当主进程崩溃或重启时集群能自动恢复正常工作。
三.Leader和非Leader对事务请求的处理
ZAB协议只允许唯一一个Leader来处理事务请求。Leader接收到客户端事务请求后,会生成对应的Proposal提议并发起广播。非Leader接收到客户端事务请求后,会将事务请求转发给Leader。
四.ZAB协议的由三个主要步骤
步骤一: Leader发送Proposal提议给集群中的所有节点,包括它自己。
步骤二: 节点收到Proposal提议后把Proposal提议落盘,然后发送一个ACK给Leader。
步骤三: Leader收到过半节点的ACK后,发送Commit给集群中的所有节点。
五.ZAB协议的两种基本模式
分别是崩溃恢复模式和消息广播模式。ZAB协议中的状态同步是指,集群中过半机器和Leader的数据状态一致。当集群启动或Leader出现崩溃推出等异常时,就会进入恢复模式进行选举。当集群已有过半Follower完成和Leader的状态同步,就会进入广播模式。如果集群已存在Leader进行消息广播,新加入的服务器就会进入恢复模式。
ZAB协议进入崩溃恢复模式后,只要集群中存在过半服务器能相互通信,那么就可以产生一个新的Leader并再次进入消息广播模式。比如一个由3台机器组成的ZAB服务 = 1个Leader + 2个Follower。当其中一个Follower挂掉时,整个ZAB集群是不会中断服务的,因为Leader服务器依然能够获得过半机器(包括自己)的支持。
(2)ZAB协议的消息广播模式
一.ZAB协议的消息广播过程
二.ZAB协议的消息广播过程与2PC的区别
三.ZAB协议的消息广播过程能保证消息接收和发送的顺序性
一.ZAB协议的消息广播过程
ZAB协议的消息广播过程使用的是一个原子广播协议,类似于2PC过程。首先,Leader会为客户端的事务请求生成对应的事务Proposal并进行广播。然后,Leader会收集Follower返回的ACK是否已过半。若已过半,Leader则会发送Commit消息到所有Follower去提交事务。
二.ZAB协议的消息广播过程与2PC的区别
区别一: 移除了中断逻辑
在ZAB协议的消息广播(二阶段提交)过程中,移除了中断逻辑。所有的Follower要么正常反馈Leader提出的事务Proposal,要么不反馈。
区别二: 无需等所有Follower都反馈响应
移除了中断逻辑,意味着可以在过半Follower反馈ACK后就可以提交事务,不需要等待集群中的所有Follower都反馈ACK响应。
区别三: 添加崩溃恢复模式解决Leader崩溃退出导致的数据不一致问题
由于移除了中断逻辑 + 过半Follower反馈就可以提交事务,所以这时是无法处理Leader崩溃退出而带来的数据不一致问题的,因此ZAB协议添加了崩溃恢复模式来解决这个问题。
三.ZAB协议的消息广播过程能保证消息接收和发送的顺序性
另外,整个消息广播过程是基于FIFO特性的TCP协议来进行网络通信的,所以能够很容易保证消息广播过程中消息接收和发送的顺序性。广播时是由一个主进程Leader去通过FIFO的TCP协议进行发送,所以某Follower接收的多个Proposal和Commit请求都能按顺序入队和响应。
(3)ZAB协议的崩溃恢复模式
一.崩溃恢复过程可能出现数据不一致的两种情况
二.ZAB需要设计这样一个Leader选举算法
ZAB协议的这个基于原子广播协议的消息广播过程,正常情况下运行良好。但一旦Leader出现崩溃,或者由于网络Leader失去与过半Follower的联系。那么就会进入崩溃恢复模式,选举出一个新的Leader。
一.崩溃恢复过程可能出现数据不一致的两种情况
情况一: 假设一个事务在Leader上被提交了,并且已有过半Follower反馈ACK响应。但是在Leader将Commit消息发送给所有Follower前Leader挂了。所以ZAB协议需要确保已在Leader提交的Proposal提议也能被所有Follower提交。
情况二: 如果在崩溃恢复过程中出现一个需要被丢弃的Proposal提议,那么在崩溃恢复结束后需要跳过该Proposal提议,所以ZAB协议需要确保丢弃那些只在Leader上处理过的事务Proposal提议。
二.ZAB需要设计这样一个Leader选举算法
算法要求: 能够确保提交已经被Leader提交的事务Proposal提议,同时丢弃已经被跳过的事务Proposal提议。
算法设计: 让新选举出来的Leader拥有集群中ZXID最大的事务Proposal提议,那么就可以保证新Leader一定拥有所有已经提交的Proposal提议,同时也省去Leader去检查Proposal提议的提交和丢弃操作。
对于出现不一致的情况一: 如果Leader将Commit消息发送给所有Follower前,Leader崩溃了。那么Leader崩溃后,就会选举一个拥有最大ZXID的Follower作为Leader。这个Leader会检查事务日志:如果发现自己事务日志里有一个还没进行提交的Proposal提议,那么就说明旧Leader没来得及发送Commit消息就崩溃了,此时它作为新Leader会为这个Proposal提议向Follower发送Commit消息,从而保证旧Leader提交的事务最终可以被提交到所有Follower中。
对于不一致的情况二: 如果一个Leader刚把一个Proposal提议写入本地磁盘日志,还没来得及广播Proposal提议给全部Follower就崩溃了。那么当新Leader选举出来后,事务的epoch会自增长一位。然后当旧Leader重启后重新加入集群成为Follower时,会发现自己比新Leader多出一条Proposal提议,但该Proposal提议的epoch比新Leader的epoch低,所以会丢弃这条数据。
(4)崩溃恢复模式中完成Leader选举后的数据同步
一.ZAB协议在正常情况下的数据同步逻辑
二.ZAB协议如何处理需要丢弃的事务Proposal
一.ZAB协议在正常情况下的数据同步逻辑
完成Leader选举后,Leader会首先确认Follower是否完成数据同步,也就是Leader事务日志中的Proposal提议是否已被过半Follower提交。
Leader需要确保所有Follower能接收到每一条事务Proposal,并且能正确将所有已提交了的事务Proposal应用到内存数据库中。
Leader会为每个Follower都准备一个队列,并将那些没有被Follower同步的事务以Proposal提议的形式逐个发送给Follower,并在发送完每个Proposal提议消息后紧接着再发送一个Commit消息表示事务已提交。
等Follower将所有未同步的事务Proposal提议都同步并应用到内存数据库后,Leader就会将该Follower加入到真正的可用Follower列表中。
二.ZAB协议如何处理需要丢弃的事务Proposal
ZXID是一个64位的数字。低32位是一个递增计数器,Leader产生一个新Proposal都会对其+1。高32位是选举轮次的编号,每当选举产生一个新Leader都会对其+1。
4.ZAB协议与Paxos算法
(1)Paxos算法介绍
(2)联系和区别
(1)Paxos算法介绍
一.Paxos的三种角色
二.Paxos算法类似2PC的执行流程
三.Paxos的Learner如何学习被选定的value
四.Paxos算法如何保证活性
一.Paxos的三种角色
角色一:提案者(Proposer)
提出提案(Proposal),Proposal信息包括提案编号(ID)和提案的值(Value)。
角色二:决策者(Acceptor)
参与决策,回应Proposer的提案,收到提案后可以接受提案。若提案获得超半数Acceptor的接受,则称该提案被选定(批准)。
角色三:学习者(Learner)
不参与决策,从Proposer和Acceptor学习被选定的提案的值(Value)。
二.Paxos算法类似2PC的执行流程
下面是Paxos算法的概述:
与ZAB协议不同,Paxos算法处理来自客户端的事务请求时:
步骤一: 首先会触发一个或多个服务器进程,向其他服务器发起提案
步骤二: 然后其他服务器会向发起提案的服务器反馈提案的执行情况
步骤三: 接着发起提案的服务器会对接收到的反馈信息进行统计
步骤四: 当过半服务器批准该事务请求操作后,则可在本地执行提交
可见,Paxos算法对事务请求的投票过程与ZAB协议十分相似。但ZAB协议中发起投票的机器,是集群中运行的一台Leader服务器,而Paxos算法则是采用多副本的处理方式。也就是存在多个副本,每个副本分别包含提案者、决策者以及学习者。
下面是详细的Paxos两阶段提交算法:
阶段一.Prepare请求
步骤一: Proposer选择一个提案编号M,然后向半数以上的Acceptor发送编号为M的Prepare请求。
步骤二: 如果一个Acceptor收到一个编号为M的Prepare请求,且M大于该Acceptor已经响应过的所有Prepare请求的编号,那么它就会将它已经批准过的编号最大的提案作为响应反馈给Proposer,同时该Acceptor承诺不再批准任何编号小于M的提案。
阶段二.Accept请求
步骤一: 如果Proposer收到半数以上Acceptor,对其发出的编号为M的Prepare请求的响应,那么它就会发送一个针对M, V提案的Accept请求给半数以上的Acceptor。注意:V就是收到的响应中编号最大的提案的value。如果响应中不包含任何提案,那么V就由Proposer自己决定。
步骤二: 如果Acceptor收到一个针对M, V提案的Accept请求,只要该Acceptor没有对编号大于M的Prepare请求做出过响应,它就批准该提案。

三.Paxos的Learner如何学习被选定的value
Learner获取提案,有三种方案:
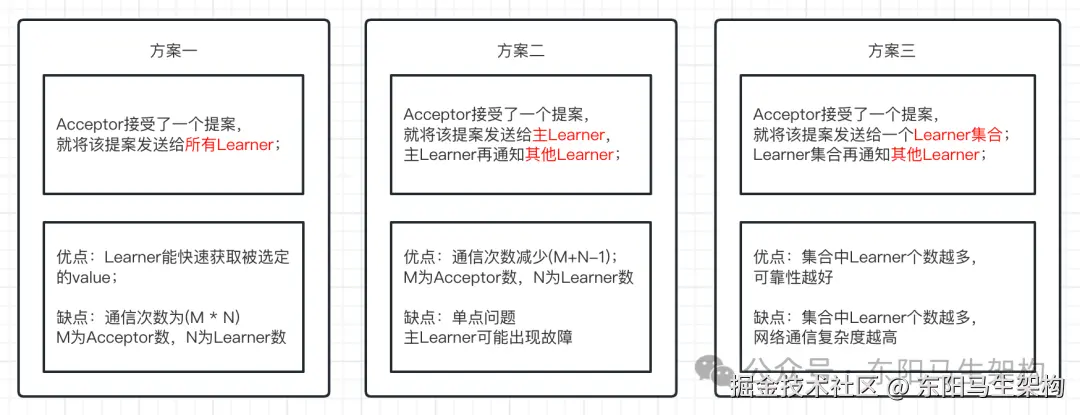
四.Paxos算法如何保证活性
一个极端的活锁场景:

(2)Paxos与ZAB的联系和区别
相同之处:
一.两者都存在一个类似于Leader进程的角色,由Leader角色负责协调多个Follower进程的运行。
二.Leader进程都会等待超过半数的Follower做出正确的反馈,之后才会将一个提案进行提交。
三.都存在一个标识表示当前的Leader周期,比如ZAB是epoch、Paxos是Ballot。
不同之处:
一.ZAB协议中发起投票的机器是集群中运行的一台Leader服务器,Paxos算法则是采用多副本的处理方式。即存在多个副本,每个副本分别包含提案者、决策者以及学习者。
二.两者的设计目标不一样。ZAB协议主要用于构建一个高可用的分布式数据主从系统,Paxos算法主要用于构建一个分布式的一致性状态机系统。
5.zk的数据存储原理之内存数据
(1)DataNode
(2)DataTree和nodes
(3)ZKDatabase
从数据存储位置角度看,zk产生的数据可以分为内存数据和磁盘数据。从数据的种类和作用看,又可以分为事务日志数据和全量数据快照。
zk的数据模型是一棵树。zk存储了整棵树的内容,包括所有的节点路径、节点数据及ACL信息等。zk会定时将整棵树的数据存储到磁盘上。
(1)DataNode
DataNode是数据存储的最小单元,DataNode会保存:节点的数据内容、ACL列表、节点状态和子节点列表。
kotlin
public class DataNode implements Record {
byte data[];//节点的数据内容
Long acl;//ACL列表
public StatPersisted stat;//节点状态
private Set<String> children = null;//子节点列表
...
}(2)DataTree和nodes
DataTree是zk内存数据存储的核心,代表了内存中的一份完整数据,它不包含任何与网络、客户端连接以及请求处理相关的逻辑。DataTree用于存储所有zk节点的路径、内容及其ACL信息,它的核心存储结构是一个ConcurrentHashMap类型的nodes。
在DataTree.nodes这个Map中,存放了zk上所有的数据节点。对zk数据的所有操作,都是对DataTree.nodes这个Map进行操作的。DataTree.nodes的key是节点路径path,value是节点内容DataNode。DataTree.ephemerals专门存储了zk的临时节点,以便实时访问和及时清理。
java
public class DataTree {
//在DataTree.nodes这个Map中,存放了zk上所有的数据节点,包括节点路径、内容及ACL信息
private final ConcurrentHashMap<String, DataNode> nodes = new ConcurrentHashMap<String, DataNode>();
//存储监听节点的WatchManager
private final WatchManager dataWatches = new WatchManager();
//存储监听子节点的WatchManager
private final WatchManager childWatches = new WatchManager();
//存储了zk的临时节点
private final Map<Long, HashSet<String>> ephemerals = new ConcurrentHashMap<Long, HashSet<String>>();
...
public void createNode(final String path, byte data[], List<ACL> acl, long ephemeralOwner, int parentCVersion, long zxid, long time, Stat outputStat) {
...
String parentName = path.substring(0, lastSlash);
...
DataNode parent = nodes.get(parentName);
...
synchronized (parent) {
...
nodes.put(path, child);
...
HashSet<String> list = ephemerals.get(ephemeralOwner);
if (list == null) {
list = new HashSet<String>();
ephemerals.put(ephemeralOwner, list);
}
synchronized (list) {
list.add(path);
}
}
...
dataWatches.triggerWatch(path, Event.EventType.NodeCreated);
childWatches.triggerWatch(parentName.equals("") ? "/" : parentName, Event.EventType.NodeChildrenChanged);
}
public Set<String> getEphemerals(long sessionId) {
HashSet<String> retv = ephemerals.get(sessionId);
if (retv == null) {
return new HashSet<String>();
}
HashSet<String> cloned = null;
synchronized (retv) {
cloned = (HashSet<String>) retv.clone();
}
return cloned;
}
...
}(3)ZKDatabase
ZKDatabase是zk的内存数据库,它负责管理zk的所有会话、DataTree存储和事务日志,它会定时向磁盘dump数据快照。在zk服务器启动时会通过磁盘上的事务日志和快照文件恢复ZKDatabase。
ini
public class ZKDatabase {
protected DataTree dataTree;//zk的内存数据
protected FileTxnSnapLog snapLog;//数据文件管理器
...
public ZKDatabase(FileTxnSnapLog snapLog) {
dataTree = createDataTree();
sessionsWithTimeouts = new ConcurrentHashMap<Long, Integer>();
this.snapLog = snapLog;
...
}
...
}6.zk的数据存储原理之事务日志
(1)事务日志的存储
(2)事务日志的写入之FileTxnLog的创建
(3)事务日志的写入之FileTxnLog写入日志的步骤
(4)事务日志截断
(1)事务日志的存储
部署zk集群时需要默认配置一个目录dataDir,用于存储事务日志文件。zk中也可以为事务日志单独分配一个文件存储目录dataLogDir。
zk的事务日志文件都具有两个特点:
一.文件大小都是64M
二.文件名后缀都是一个十六进制的、写入文件的第一条事务记录的ZXID
使用ZXID作为后缀,可迅速定位某一个事务操作所在的事务日志文件。由于ZXID的高32位当表当前Leader周期,低32位代表事务操作的计数器。所以将ZXID作为文件后缀,可以清楚看出当前运行的zk的Leader周期。
(2)事务日志的写入之FileTxnLog的创建
zk会通过FileTxnLog类来实现事务日志的写入操作。zk服务端启动时会先创建数据管理器FileTxnSnapLog,在FileTxnSnapLog的构造方法中便会创建FileTxnLog实例。
arduino
public class QuorumPeerMain {
protected QuorumPeer quorumPeer;
...
//1.启动程序入口
public static void main(String[] args) {
QuorumPeerMain main = new QuorumPeerMain();
try {
//启动程序
main.initializeAndRun(args);
} catch (IllegalArgumentException e) {
...
}
LOG.info("Exiting normally");
System.exit(0);
}
protected void initializeAndRun(String[] args) {
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
//2.解析配置文件
config.parse(args[0]);
}
//3.创建和启动历史文件清理器
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config.getDataDir(), config.getDataLogDir(), config.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();
//4.根据配置判断是集群模式还是单机模式
if (args.length == 1 && config.isDistributed()) {
//集群模式
runFromConfig(config);
} else {
//单机模式
ZooKeeperServerMain.main(args);
}
}
public void runFromConfig(QuorumPeerConfig config) {
...
ServerCnxnFactory cnxnFactory = null;
if (config.getClientPortAddress() != null) {
//1.创建网络连接工厂实例ServerCnxnFactory
cnxnFactory = ServerCnxnFactory.createFactory();
//2.初始化网络连接工厂实例ServerCnxnFactory
cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), false);
}
//接下来就是初始化集群版服务器实例QuorumPeer
//3.创建集群版服务器实例QuorumPeer
quorumPeer = getQuorumPeer();
//4.创建zk数据管理器FileTxnSnapLog
quorumPeer.setTxnFactory(new FileTxnSnapLog(config.getDataLogDir(), config.getDataDir()));
...
//5.创建并初始化内存数据库ZKDatabase
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
...
quorumPeer.initialize();
//6.初始化集群版服务器实例QuorumPeer
quorumPeer.start();
//join方法会将当前线程挂起,等待QuorumPeer线程结束后再执行当前线程
quorumPeer.join();
}
protected QuorumPeer getQuorumPeer() throws SaslException {
return new QuorumPeer();
}
}
public class FileTxnSnapLog {
private final File dataDir;//事务日志文件
private final File snapDir;//数据快照文件
private TxnLog txnLog;//事务日志实例
private SnapShot snapLog;//快照日志实例
...
public FileTxnSnapLog(File dataDir, File snapDir) throws IOException {
...
this.dataDir = new File(dataDir, version + VERSION);
this.snapDir = new File(snapDir, version + VERSION);
...
//创建FileTxnLog事务日志管理器的实例
txnLog = new FileTxnLog(this.dataDir);
//创建FileSnap数据快照管理器的实例
snapLog = new FileSnap(this.snapDir);
}
...
}(3)事务日志的写入之FileTxnLog写入日志的步骤
一.确定是否有事务日志文件可写,如果没有就创建一个事务日志文件
二.确定事务日志文件是否需要扩容--即预分配
三.对事务头和事务体进行序列化生成一个字节数组
四.生成Checksum来保证事务日志文件的完整性和数据的准确性
五.将序列化后的事务头、事务体和Checksum写入到文件流中
六.SyncRequestProcessor处理器会触发将事务日志刷入磁盘
FileTxnLog中进行事务日志的写入操作是由append()方法来负责的。
一.确定是否有事务日志文件可写,如果没有就创建一个事务日志文件
当zk服务器启动完需要进行第一次事务日志写入或上一个事务日志写满时,zk服务器都不会和任意一个事务日志文件进行关联。所以在进行事务日志写入前,FileTxnLog会先判断logStream是否为空,来判断FileTxnLog实例是否已经关联上一个可写的事务日志文件。
如果为空则根据该事务操作相关的ZXID作为后缀来创建一个事务日志文件,然后构建事务日志文件头信息:魔数 + 版本号 + dbid,接着将事务日志文件头信息写入到事务日志文件流中,最后将事务日志文件流fos添加到streamsToFlush。
二.确定事务日志文件是否需要扩容--即预分配
当检测到当前事务日志文件剩余空间不足4096字节时,就会开始进行扩容。扩容过程就是在现有文件大小的基础上,将文件增加64M+使用0进行填充。由于事务日志的写入过程可以看成是一个磁盘IO过程,所以文件的写入操作会触发磁盘IO为文件开辟新的磁盘块,即磁盘Seek。为了避免磁盘Seek频繁出现,zk在创建文件初就预分配一个64M磁盘块。一旦已分配的文件空间不足4K时,那么将会再次预分配,从而避免每次事务日志写入时由于文件大小的增长而带来的Seek开销。
三.对事务头和事务体进行序列化生成一个字节数组
事务序列化包括对事务头TxnHeader和事务体Record的序列化。
四.生成Checksum来保证事务日志文件的完整性和数据的准确性
为了保证事务日志文件的完整性和数据的准确性,在写入事务日志到文件前,会根据序列化的字节数组来计算Checksum。
五.将序列化后的事务头、事务体和Checksum写入到文件流中
由于zk使用BufferedOutputStream,此时写入的数据并非写入到文件。
六.SyncRequestProcessor处理器会触发将事务日志刷入磁盘
前面的步骤已经将事务操作日志写入了文件流中,但由于缓存的原因,这些事务操作日志还无法实时地写入磁盘文件中。因此zk会通过SyncRequestProcessor处理器发起事务日志刷盘操作,最终会调用到FileTxnLog的commit()方法来将事务日志刷入磁盘。也就是当需要刷盘的事务请求达到1000个时,才发起强制刷盘操作。FileTxnLog的commit()方法会从streamsToFlush中提取出文件流,然后调用FileChannel的force()方法强制将数据刷入磁盘文件中,而FileChannel的force()方法会调用到底层的fsync接口。
java
public class SyncRequestProcessor extends ZooKeeperCriticalThread implements RequestProcessor {
private final ZooKeeperServer zks;
private final LinkedBlockingQueue<Request> queuedRequests = new LinkedBlockingQueue<Request>();
private final LinkedList<Request> toFlush = new LinkedList<Request>();
private final Random r = new Random();
private static int snapCount = ZooKeeperServer.getSnapCount();
...
@Override
public void run() {
int logCount = 0;
int randRoll = r.nextInt(snapCount/2);
while (true) {
Request si = null;
if (toFlush.isEmpty()) {
si = queuedRequests.take();
} else {
si = queuedRequests.poll();
if (si == null) {
flush(toFlush);
continue;
}
}
...
if (si != null) {
//将事务请求写入到事务日志文件
if (zks.getZKDatabase().append(si)) {
logCount++;
if (logCount > (snapCount / 2 + randRoll)) {
randRoll = r.nextInt(snapCount/2);
//切换事务日志文件
zks.getZKDatabase().rollLog();
//每切换一个事务日志文件就尝试启动一个线程进行数据快照
if (snapInProcess != null && snapInProcess.isAlive()) {
LOG.warn("Too busy to snap, skipping");
} else {
snapInProcess = new ZooKeeperThread("Snapshot Thread") {
public void run() {
zks.takeSnapshot();
}
};
snapInProcess.start();
}
logCount = 0;
}
}
...
toFlush.add(si);
//当需要强制刷盘的请求达到1000个时,就发起批量刷盘操作
if (toFlush.size() > 1000) {
flush(toFlush);
}
}
}
}
private void flush(LinkedList<Request> toFlush) {
//将事务日志刷入磁盘
zks.getZKDatabase().commit();
while (!toFlush.isEmpty()) {
Request i = toFlush.remove();
if (nextProcessor != null) {
nextProcessor.processRequest(i);
}
}
if (nextProcessor != null && nextProcessor instanceof Flushable) {
((Flushable)nextProcessor).flush();
}
}
...
}
public class ZKDatabase {
protected FileTxnSnapLog snapLog;
...
//将事务请求写入到事务日志中
public boolean append(Request si) throws IOException {
return this.snapLog.append(si);
}
//切换事务日志文件
public void rollLog() throws IOException {
this.snapLog.rollLog();
}
//将事务日志刷入磁盘
public void commit() throws IOException {
this.snapLog.commit();
}
...
}
public class FileTxnSnapLog {
private TxnLog txnLog;
...
public boolean append(Request si) throws IOException {
return txnLog.append(si.getHdr(), si.getTxn());
}
public void commit() throws IOException {
txnLog.commit();
}
public void rollLog() throws IOException {
txnLog.rollLog();
}
...
}
public class FileTxnLog implements TxnLog, Closeable {
//和一个事务日志文件相关联的输出流
volatile BufferedOutputStream logStream = null;
//用来记录当前需要强制进行数据落盘的文件流
private LinkedList<FileOutputStream> streamsToFlush = new LinkedList<FileOutputStream>();
...
//传入的hdr是事务头,传入的txn是事务体
public synchronized boolean append(TxnHeader hdr, Record txn) throws IOException {
if (hdr == null) {
return false;
}
if (hdr.getZxid() <= lastZxidSeen) {
LOG.warn("Current zxid " + hdr.getZxid() + " is <= " + lastZxidSeen + " for " + hdr.getType());
} else {
lastZxidSeen = hdr.getZxid();
}
//1.确定是否有事务日志文件可写,如果没有就创建一个事务日志文件
if (logStream == null) {
if (LOG.isInfoEnabled()) {
LOG.info("Creating new log file: " + Util.makeLogName(hdr.getZxid()));
}
//使用ZXID作为后缀创建一个事务日志文件
logFileWrite = new File(logDir, Util.makeLogName(hdr.getZxid()));
fos = new FileOutputStream(logFileWrite);
//将创建的事务日志文件和logStream进行关联
logStream = new BufferedOutputStream(fos);
oa = BinaryOutputArchive.getArchive(logStream);
//构建事务日志文件头:魔数 + 版本号 + dbid
FileHeader fhdr = new FileHeader(TXNLOG_MAGIC, VERSION, dbId);
//将事务日志文件头写入到事务日志文件流中
fhdr.serialize(oa, "fileheader");
// Make sure that the magic number is written before padding.
logStream.flush();
//设置当前文件写入大小
filePadding.setCurrentSize(fos.getChannel().position());
//将事务日志文件流fos放入streamsToFlush集合,以便后续进行强制数据落盘
streamsToFlush.add(fos);
}
//2.确定事务日志文件是否需要扩容--即预分配
filePadding.padFile(fos.getChannel());
//3.对事务头hdr和事务体txn进行序列化生成一个字节数组
byte[] buf = Util.marshallTxnEntry(hdr, txn);
if (buf == null || buf.length == 0) {
throw new IOException("Faulty serialization for header " + "and txn");
}
//4.生成Checksum来保证事务日志文件的完整性和数据的准确性
Checksum crc = makeChecksumAlgorithm();
crc.update(buf, 0, buf.length);
//5.写入事务日志文件流
oa.writeLong(crc.getValue(), "txnEntryCRC");
Util.writeTxnBytes(oa, buf);
return true;
}
//切换事务日志文件
public synchronized void rollLog() throws IOException {
if (logStream != null) {
this.logStream.flush();
this.logStream = null;
oa = null;
}
}
//将事务日志刷入磁盘
public synchronized void commit() throws IOException {
if (logStream != null) {
logStream.flush();
}
for (FileOutputStream log : streamsToFlush) {
log.flush();
if (forceSync) {
long startSyncNS = System.nanoTime();
FileChannel channel = log.getChannel();
channel.force(false);
syncElapsedMS = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startSyncNS);
if (syncElapsedMS > fsyncWarningThresholdMS) {
if(serverStats != null) {
serverStats.incrementFsyncThresholdExceedCount();
}
}
}
}
while (streamsToFlush.size() > 1) {
streamsToFlush.removeFirst().close();
}
}
...
}
public class FilePadding {
private static long preAllocSize = 65536 * 1024;
private long currentSize;//当前文件写入大小
private static final ByteBuffer fill = ByteBuffer.allocateDirect(1);
...
long padFile(FileChannel fileChannel) throws IOException {
long newFileSize = calculateFileSizeWithPadding(fileChannel.position(), currentSize, preAllocSize);
if (currentSize != newFileSize) {
fileChannel.write((ByteBuffer) fill.position(0), newFileSize - fill.remaining());
currentSize = newFileSize;
}
return currentSize;
}
public static long calculateFileSizeWithPadding(long position, long fileSize, long preAllocSize) {
// If preAllocSize is positive and we are within 4KB of the known end of the file calculate a new file size
//如果当前事务日志文件的剩余空间不足4096字节
if (preAllocSize > 0 && position + 4096 >= fileSize) {
// If we have written more than we have previously preallocated we need to make sure the new file size is larger than what we already have
if (position > fileSize) {
fileSize = position + preAllocSize;
fileSize -= fileSize % preAllocSize;
} else {
fileSize += preAllocSize;
}
}
return fileSize;
}
...
}(4)事务日志截断
为了避免某Learner机器上的事务ID比Leader的还要大(peerLastZxid),只要集群中存在Leader,所有机器都必须与该Leader数据保持同步。
因此,只要发现一台Learner机器出现这样的情况,Leader就会发送TRUNC命令给该Learner,要求进行事务日志截断。该Learner收到命令后,就会删除所有大于peerLastZxid的事务日志文件。
7.zk的数据存储原理之数据快照
(1)文件存储
(2)数据快照过程
(1)文件存储
一.数据快照文件和事务日志文件的命名规则一样
二.数据快照文件没有采用事务日志文件中的预分配机制
一.数据快照文件和事务日志文件的命名规则一样
数据快照文件也是使用ZXID的十六进制来作为文件名后缀,数据快照文件名的后缀标识了本次数据快照开始时的服务器最新ZXID。在数据恢复阶段,zk会根据该ZXID来确定数据恢复的起始点。
二.数据快照文件没有采用事务日志文件中的预分配机制
所以不会像事务日志文件那样,文件内容中包含大量的0。由于每个数据快照文件中的所有内容都是有效的,因此数据快照文件的大小能一定程度反映当前zk内存中全量数据的大小。
(2)数据快照过程
一.确定是否需要进行数据快照
二.切换事务日志文件
三.创建数据快照异步线程
四.获取全量数据和会话信息
五.生成数据快照文件名
六.执行FileSnap.serialize方法进行数据序列化
zk会将客户端的每一次事务操作都记录到事务日志中。zk在进行若干次事务日志记录后,会将内存的全量数据Dump到文件中,这个过程就是数据快照。可以使用snapCount参数来配置每次数据快照间的事务操作次数,也就是zk会在snapCount次事务日志记录后执行一次数据快照。
FileSnap负责维护数据快照文件对外的接口,包括数据快照的写入和读取,数据快照的过程如下:
一.确定是否需要进行数据快照
每执行一次事务日志记录后,zk都会检测当前是否需要进行数据快照。理论上进行snapCount次事务操作后就会开始进行数据快照。但考虑到数据快照会对所在机器的整体性能造成一定影响,所以需要尽量避免zk集群中的所有机器都在同一时刻进行数据快照。因此在zk的具体实现中,会采取"过半随机"策略来进行数据快照。
scss
logCount > (snapCount / 2 + randRoll)其中logCount代表当前已经记录的事务日志数量,而randRoll代表1到snapCount/2之间的随机数。所以如果snapCount配置为10000,那么zk会在5000到10000次事务日志记录后进行一次数据快照。
二.切换事务日志文件
也就是当前的事务日志已经写满了,已经写入了snapCount条事务日志,需要重新创建一个新的事务日志文件。
三.创建数据快照异步线程
为保证数据快照不影响z的主流程,会创建一个异步线程来进行数据快照。
四.获取全量数据和会话信息
数据快照本质上就是将内存中的所有节点信息和会话信息保存到磁盘中,所以会先通过ZKDatabase的getDataTree()方法获取到DataTree,然后再通过ZKDatabase的getSessionWithTimeOuts()方法获取会话信息。
五.生成数据快照文件名
zk会根据当前已提交的最大ZXID来生成数据快照文件名。
六.执行FileSnap.serialize方法进行数据序列化
首先会序列化文件头信息:魔数 + 版本号 + dbid,然后序列化DataTree和会话信息,接着生成一个Checksum,再一起写入数据快照文件中。
java
public class SyncRequestProcessor extends ZooKeeperCriticalThread implements RequestProcessor {
private final ZooKeeperServer zks;
private final LinkedBlockingQueue<Request> queuedRequests = new LinkedBlockingQueue<Request>();
private final LinkedList<Request> toFlush = new LinkedList<Request>();
private final Random r = new Random();
private static int snapCount = ZooKeeperServer.getSnapCount();
...
@Override
public void run() {
int logCount = 0;
int randRoll = r.nextInt(snapCount/2);
while (true) {
Request si = null;
if (toFlush.isEmpty()) {
si = queuedRequests.take();
} else {
si = queuedRequests.poll();
if (si == null) {
flush(toFlush);
continue;
}
}
...
if (si != null) {
//将事务请求写入到事务日志文件
if (zks.getZKDatabase().append(si)) {
logCount++;//logCount代表当前已经记录的事务日志数量
//1.确定是否需要进行数据快照,采取"过半随机"策略进行数据快照
if (logCount > (snapCount / 2 + randRoll)) {
randRoll = r.nextInt(snapCount/2);//randRoll代表1到snapCount/2之间的随机数
//2.切换事务日志文件
zks.getZKDatabase().rollLog();
//每切换一个事务日志文件就尝试启动一个线程进行数据快照
if (snapInProcess != null && snapInProcess.isAlive()) {
LOG.warn("Too busy to snap, skipping");
} else {
//3.创建数据快照异步线程
snapInProcess = new ZooKeeperThread("Snapshot Thread") {
public void run() {
//进行数据快照
zks.takeSnapshot();
}
};
snapInProcess.start();
}
logCount = 0;
}
}
...
toFlush.add(si);
//当需要强制刷盘的请求达到1000个时,就发起批量刷盘操作
if (toFlush.size() > 1000) {
flush(toFlush);
}
}
}
}
...
}
public class ZooKeeperServer implements SessionExpirer, ServerStats.Provider {
private FileTxnSnapLog txnLogFactory = null;
private ZKDatabase zkDb;
...
public void takeSnapshot() {
//进行数据快照
takeSnapshot(false);
}
//进行数据快照
public void takeSnapshot(boolean syncSnap){
//4.获取全量数据和会话信息
txnLogFactory.save(zkDb.getDataTree(), zkDb.getSessionWithTimeOuts(), syncSnap);
}
...
}
public class FileTxnSnapLog {
private SnapShot snapLog;
...
public void save(DataTree dataTree, ConcurrentHashMap<Long, Integer> sessionsWithTimeouts, boolean syncSnap) {
//获取内存数据库最后处理的ZXID
long lastZxid = dataTree.lastProcessedZxid;
//5.生成数据快照文件名
File snapshotFile = new File(snapDir, Util.makeSnapshotName(lastZxid));
LOG.info("Snapshotting: 0x{} to {}", Long.toHexString(lastZxid), snapshotFile);
//6.开始数据序列化
snapLog.serialize(dataTree, sessionsWithTimeouts, snapshotFile, syncSnap);
}
...
}
public class FileSnap implements SnapShot {
...
//serialize the datatree and session into the file snapshot
public synchronized void serialize(DataTree dt, Map<Long, Integer> sessions, File snapShot, boolean fsync) {
if (!close) {
try (CheckedOutputStream crcOut = new CheckedOutputStream(
new BufferedOutputStream(
fsync ? new AtomicFileOutputStream(snapShot) : new FileOutputStream(snapShot)),
new Adler32())
) {
//CheckedOutputStream cout = new CheckedOutputStream()
OutputArchive oa = BinaryOutputArchive.getArchive(crcOut);
//构造文件头对象
FileHeader header = new FileHeader(SNAP_MAGIC, VERSION, dbId);
//序列化文件头 + DataTree + 会话信息
serialize(dt, sessions, oa, header);
//生成一个Checksum
long val = crcOut.getChecksum().getValue();
//写入数据快照文件中
oa.writeLong(val, "val");
oa.writeString("/", "path");
crcOut.flush();
lastSnapshotInfo = new SnapshotInfo(Util.getZxidFromName(snapShot.getName(), SNAPSHOT_FILE_PREFIX), snapShot.lastModified() / 1000);
}
} else {
throw new IOException("FileSnap has already been closed");
}
}
protected void serialize(DataTree dt,Map<Long, Integer> sessions, OutputArchive oa, FileHeader header) throws IOException {
if (header == null)
throw new IllegalStateException("Snapshot's not open for writing: uninitialized header");
//序列化文件头信息:魔数 + 版本号 + dbid
header.serialize(oa, "fileheader");
//序列化DataTree和会话信息
SerializeUtils.serializeSnapshot(dt,oa,sessions);
}
...
}8.zk的数据存储原理之数据初始化和数据同步流程
(1)zk的数据初始化流程
(2)zk的数据同步流程
(1)zk的数据初始化流程
一.初始化FileTxnSnapLog
二.初始化ZKDatabase
三.创建PlayBackListener监听器
四.开始处理数据快照文件
五.获取最新的100个数据快照文件
六.逐个解析数据快照文件
七.根据数据快照文件的文件名获取最新的ZXID
八.开始处理事务日志文件
九.获取所有最新ZXID之后提交的事务
十.进行事务应用
十一.获取最新ZXID
十二.校验epoch
zk的数据初始化过程,其实就是从磁盘中加载数据的过程,包括从数据快照文件中加载数据和根据事务日志文件来订正数据两个过程。
一.初始化FileTxnSnapLog
FileTxnSnapLog是zk的事务日志和数据快照访问层,FileTxnSnapLog是用来衔接上层业务和底层数据存储的。底层数据存储包含了事务日志和数据快照两部分。因此FileTxnSnapLog的初始化包括FileTxnLog和FileSnap的初始化,分别代表事务日志管理器和数据快照管理器的初始化。
二.初始化ZKDatabase
完成FileTxnSnapLog的初始化,就完成了zk服务器和底层数据存储的对接。接下来就会初始化ZKDatabase:首先会创建一个初始化的DataTree,然后创建一个用于保存客户端会话超时时间的记录器,接着将初始化好的FileTxnSnapLog交给ZKDatabase。
三.创建PlayBackListener监听器
PlayBackListener监听器主要用来接收事务应用过程中的回调。在zk数据恢复后期,会有一个事务订正的过程。这个过程中,就会回调PlayBackListener监听器来进行数据订正。
四.开始处理数据快照文件
完成内存数据库ZKDatabase的初始化后,就可以从磁盘中恢复数据了。
五.获取最新的100个数据快照文件
不能只获取最新的那个数据快照文件,因为有可能该文件是不可用的。
六.逐个解析数据快照文件
获取到这最多100个的最新数据快照文件后,zk会开始逐个解析。首先会对数据快照文件里的二进制数据反序列化,然后对文件进行CheckSum校验以确定快照文件的正确性。如果校验通过,那么就可以完成解析了。也就是说:只有当最新的数据快照文件不可用时,才会逐个进行解析。如果解析完这100个文件都无法恢复一个完整的DataTree和Session集合,则认为无法从磁盘中加载数据,服务器启动失败。
七.根据数据快照文件的文件名获取最新的ZXID
此时已基于数据快照文件构建了一个完整的DataTree实例和Session集合,所以接着会根据这个数据快照文件的文件名来解析出一个最新的ZXID。此时zk服务器的内存数据库已有一份近似全量的数据了,已完成从数据快照文件中加载数据的过程。
八.开始处理事务日志文件
由于此时zk服务器的内存数据库已有一份近似全量的数据了,所以接下来要进行根据事务日志文件来订正数据的过程。
九.获取所有最新ZXID之后提交的事务
根据恢复的内存数据库的最新ZXID,从事务日志文件中获取该ZXID之后提交的所有事务。
十.进行事务应用
将获取到的事务应用到基于数据快照文件恢复出的DataTree和Session中。每当有一个事务被应用到内存数据库后,需要回调PlayBackListener监听。以便将该事务操作记录转换成Proposal保存到ZKDatabase.commitedLog,让Learner可以进行快速同步。
十一.获取最新ZXID
十二.校验epoch
java
public class QuorumPeerMain {
protected QuorumPeer quorumPeer;
...
public void runFromConfig(QuorumPeerConfig config) {
...
quorumPeer = getQuorumPeer();
//1.创建zk数据管理器FileTxnSnapLog
quorumPeer.setTxnFactory(new FileTxnSnapLog(config.getDataLogDir(), config.getDataDir()));
...
//2.创建并初始化内存数据库ZKDatabase
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
...
//初始化集群版服务器实例QuorumPeer
quorumPeer.start();
...
}
}
//1.初始化FileTxnSnapLog
public class FileTxnSnapLog {
private TxnLog txnLog;//事务日志实例
private SnapShot snapLog;//快照日志实例
public FileTxnSnapLog(File dataDir, File snapDir) throws IOException {
...
//创建FileTxnLog事务日志管理器的实例
txnLog = new FileTxnLog(this.dataDir);
//创建FileSnap数据快照管理器的实例
snapLog = new FileSnap(this.snapDir);
}
...
}
//2.初始化ZKDatabase
public class ZKDatabase {
//保存zk所有节点的DataTree
protected DataTree dataTree;
//会话超时时间记录器
protected ConcurrentHashMap<Long, Integer> sessionsWithTimeouts;
//数据存储管理器
protected FileTxnSnapLog snapLog;
...
//3.创建PlayBackListener监听器
private final PlayBackListener commitProposalPlaybackListener = new PlayBackListener() {
public void onTxnLoaded(TxnHeader hdr, Record txn){
addCommittedProposal(hdr, txn);
}
};
...
public ZKDatabase(FileTxnSnapLog snapLog) {
//首先会创建一个初始化的DataTree
dataTree = createDataTree();
//创建一个用于保存所有客户端会话超时时间的记录器
sessionsWithTimeouts = new ConcurrentHashMap<Long, Integer>();
//将初始化好的FileTxnSnapLog交给ZKDatabase
this.snapLog = snapLog;
...
}
...
}
public class QuorumPeer extends ZooKeeperThread implements QuorumStats.Provider {
private ZKDatabase zkDb;
...
@Override
public synchronized void start() {
...
//4.从磁盘加载数据到内存
loadDataBase();
...
}
private void loadDataBase() {
//从磁盘加载数据到内存
zkDb.loadDataBase();
...
}
}
public class ZKDatabase {
protected FileTxnSnapLog snapLog;
public long loadDataBase() throws IOException {
//从磁盘中恢复数据
long zxid = snapLog.restore(dataTree, sessionsWithTimeouts, commitProposalPlaybackListener);
initialized = true;
return zxid;
}
...
}
public class FileTxnSnapLog {
...
public long restore(DataTree dt, Map<Long, Integer> sessions, PlayBackListener listener) throws IOException {
//4.处理快照文件
long deserializeResult = snapLog.deserialize(dt, sessions);
FileTxnLog txnLog = new FileTxnLog(dataDir);
RestoreFinalizer finalizer = () -> {
//8.处理事务日志,会根据事务日志订正数据
long highestZxid = fastForwardFromEdits(dt, sessions, listener);
return highestZxid;
};
if (-1L == deserializeResult) {
if (txnLog.getLastLoggedZxid() != -1) {
if (!trustEmptySnapshot) {
throw new IOException(EMPTY_SNAPSHOT_WARNING + "Something is broken!");
} else {
return finalizer.run();
}
}
save(dt, (ConcurrentHashMap<Long, Integer>)sessions, false);
return 0;
}
return finalizer.run();
}
...
}
public class FileSnap implements SnapShot {
...
public long deserialize(DataTree dt, Map<Long, Integer> sessions) throws IOException {
//5.获取最新的100个数据快照文件
List<File> snapList = findNValidSnapshots(100);
...
File snap = null;
boolean foundValid = false;
for (int i = 0, snapListSize = snapList.size(); i < snapListSize; i++) {
//6.逐个解析数据快照文件,直到某个数据快照文件可用
snap = snapList.get(i);
try (InputStream snapIS = new BufferedInputStream(new FileInputStream(snap));
CheckedInputStream crcIn = new CheckedInputStream(snapIS, new Adler32())) {
InputArchive ia = BinaryInputArchive.getArchive(crcIn);
//反序列化生成DataTree对象和SessionsWithTimeouts集合
deserialize(dt, sessions, ia);
//对文件进行CheckSum校验以确定快照文件的正确性
long checkSum = crcIn.getChecksum().getValue();
long val = ia.readLong("val");
if (val != checkSum) {
throw new IOException("CRC corruption in snapshot : " + snap);
}
foundValid = true;
break;
} catch (IOException e) {
LOG.warn("problem reading snap file " + snap, e);
}
}
...
//7.根据数据快照文件的文件名获取最新的ZXID
//此时,zk服务器内存已有一份近似全量的数据了,至此完成了从数据快照文件中加载快照数据的过程
dt.lastProcessedZxid = Util.getZxidFromName(snap.getName(), SNAPSHOT_FILE_PREFIX);
lastSnapshotInfo = new SnapshotInfo(dt.lastProcessedZxid, snap.lastModified() / 1000);
return dt.lastProcessedZxid;
}
...
}
public class FileTxnSnapLog {
...
//8.处理事务日志,接下来根据事务日志订正数据
public long fastForwardFromEdits(DataTree dt, Map<Long, Integer> sessions, PlayBackListener listener) throws IOException {
//9.根据恢复的内存数据库的最新ZXID,从事务日志中获取该ZXID之后提交的所有事务
TxnIterator itr = txnLog.read(dt.lastProcessedZxid + 1);
long highestZxid = dt.lastProcessedZxid;
TxnHeader hdr;
while (true) {
hdr = itr.getHeader();
if (hdr == null) {
return dt.lastProcessedZxid;
}
if (hdr.getZxid() < highestZxid && highestZxid != 0) {
LOG.error("{}(highestZxid) > {}(next log) for type {}", highestZxid, hdr.getZxid(), hdr.getType());
} else {
highestZxid = hdr.getZxid();
}
//10.事务应用
processTransaction(hdr,dt,sessions, itr.getTxn());
//10.回调PlayBackListener监听器
listener.onTxnLoaded(hdr, itr.getTxn());
if (!itr.next()) break;
}
return highestZxid;
}
...
}
public class FileSnap implements SnapShot {
...
public TxnIterator read(long zxid) throws IOException {
return read(zxid, true);
}
public TxnIterator read(long zxid, boolean fastForward) throws IOException {
return new FileTxnIterator(logDir, zxid, fastForward);
}
...
}
public class QuorumPeer extends ZooKeeperThread implements QuorumStats.Provider {
...
private void loadDataBase() {
//从磁盘加载数据到内存
zkDb.loadDataBase();
...
//11.获取最新ZXID
long lastProcessedZxid = zkDb.getDataTree().lastProcessedZxid;
long epochOfZxid = ZxidUtils.getEpochFromZxid(lastProcessedZxid);
...
currentEpoch = readLongFromFile(CURRENT_EPOCH_FILENAME);
...
//12.校验epoch
if (epochOfZxid > currentEpoch) {
File currentTmp = new File(getTxnFactory().getSnapDir(), CURRENT_EPOCH_FILENAME + AtomicFileOutputStream.TMP_EXTENSION);
if (currentTmp.exists()) {
long epochOfTmp = readLongFromFile(currentTmp.getName());
setCurrentEpoch(epochOfTmp);
} else {
throw new IOException("The current epoch, " + ZxidUtils.zxidToString(currentEpoch) + ", is older than the last zxid, " + lastProcessedZxid);
}
}
acceptedEpoch = readLongFromFile(ACCEPTED_EPOCH_FILENAME);
...
}
...
}(2)zk的数据同步流程
一.Leader获取Learner状态
二.Leader进行数据同步初始化
三.Leader在Learner完成注册后解析Learner最后处理的ZXID
四.Leader执行LearnerHandler.syncFollower方法决定以那种方式进行同步
当集群完成Leader选举后,Learner会向Leader进行注册。当Learner向Leader完成注册后,就会进入数据同步环节。数据同步过程就是:Leader将那些没有在Learner提交过的事务请求同步给Learner。
一.Leader获取Learner状态
在Learner向Leader注册的最后阶段,Learner会发送Leader一个ACK消息。Leader会从该消息中解析出该Learner的currentEpoch和lastZxid。
二.Leader进行数据同步初始化
在开始数据同步前,Leader会进行数据同步初始化。首先会从zk的内存数据库中提取出事务请求对应的提议缓存队列,然后完成对以下三个ZXID值的初始化:
peerLastZxid:Learner最后处理的ZXID
minCommittedLog:Leader的提议缓存队列committedLog中最小ZXID
maxCommittedLog:Leader的提议缓存队列committedLog中最大ZXID注意:数据初始化流程中回调PlayBackListener监听,就会触发数据同步流程中的初始化环节:添加请求到提议缓存队列等。
三.Leader在Learner完成注册后解析Learner最后处理的ZXID
四.Leader执行LearnerHandler.syncFollower方法决定以那种方式进行同步
方式一:直接差异化同步(DIFF同步),peerLastZxid介于minCommittedLog与maxCommittedLog之间。
方式二:先回滚再差异化同步(TRUNC + DIFF同步),peerLastZxid介于minCommittedLog与maxCommittedLog之间,但是Leader虽已将事务记录到了本地事务日志文件,却没能发起Proposal流程就挂了。
方式三:仅回滚同步(TRUNC同步),peerLastZxid大于maxCommittedLog。
方式四:全量同步(SNAP同步),peerLastZxid小于minCommittedLog,或者Leader没有提议缓存队列且peerLastZxid不等于Leader.lastProcessZxid。
java
public class ZKDatabase {
//minCommittedLog是Leader的提议缓存队列committedLog中最小ZXID
//maxCommittedLog是Leader的提议缓存队列committedLog中最大ZXID
protected long minCommittedLog, maxCommittedLog;
//Leader的提议缓存队列committedLog
protected LinkedList<Proposal> committedLog = new LinkedList<Proposal>();
...
private final PlayBackListener commitProposalPlaybackListener = new PlayBackListener() {
public void onTxnLoaded(TxnHeader hdr, Record txn){
addCommittedProposal(hdr, txn);
}
};
private void addCommittedProposal(TxnHeader hdr, Record txn) {
Request r = new Request(0, hdr.getCxid(), hdr.getType(), hdr, txn, hdr.getZxid());
addCommittedProposal(r);
}
public void addCommittedProposal(Request request) {
WriteLock wl = logLock.writeLock();
try {
wl.lock();
if (committedLog.size() > commitLogCount) {
committedLog.removeFirst();
minCommittedLog = committedLog.getFirst().packet.getZxid();
}
if (committedLog.isEmpty()) {
minCommittedLog = request.zxid;
maxCommittedLog = request.zxid;
}
byte[] data = SerializeUtils.serializeRequest(request);
QuorumPacket pp = new QuorumPacket(Leader.PROPOSAL, request.zxid, data, null);
Proposal p = new Proposal();
p.packet = pp;
p.request = request;
//将事务请求加入提议缓存队列
committedLog.add(p);
maxCommittedLog = p.packet.getZxid();
} finally {
wl.unlock();
}
}
...
}
public class LearnerHandler extends ZooKeeperThread {
final Leader leader;
//ZooKeeper server identifier of this learner
protected long sid = 0;
protected final Socket sock;
private BinaryInputArchive ia;
private BinaryOutputArchive oa;
//The packets to be sent to the learner
final LinkedBlockingQueue<QuorumPacket> queuedPackets = new LinkedBlockingQueue<QuorumPacket>();
...
@Override
public void run() {
leader.addLearnerHandler(this);
tickOfNextAckDeadline = leader.self.tick.get() + leader.self.initLimit + leader.self.syncLimit;
//将ia和oa与Socket进行绑定
//以便当Leader通过oa发送LeaderInfo消息给Learner时,可以通过ia读取到Learner的ackNewEpoch响应
ia = BinaryInputArchive.getArchive(bufferedInput);
bufferedOutput = new BufferedOutputStream(sock.getOutputStream());
oa = BinaryOutputArchive.getArchive(bufferedOutput);
QuorumPacket qp = new QuorumPacket();
ia.readRecord(qp, "packet");
byte learnerInfoData[] = qp.getData();
...
//根据LearnerInfo信息解析出Learner的SID
ByteBuffer bbsid = ByteBuffer.wrap(learnerInfoData);
if (learnerInfoData.length >= 8) {
this.sid = bbsid.getLong();
}
...
//根据Learner的ZXID解析出对应Learner的epoch
long lastAcceptedEpoch = ZxidUtils.getEpochFromZxid(qp.getZxid());
long zxid = qp.getZxid();
//将Learner的epoch和Leader的epoch进行比较
//如果Learner的epoch更大,则更新Leader的epoch为Learner的epoch + 1
long newEpoch = leader.getEpochToPropose(this.getSid(), lastAcceptedEpoch);
long newLeaderZxid = ZxidUtils.makeZxid(newEpoch, 0);
...
//发送一个包含该epoch的LeaderInfo消息给该LearnerHandler对应的Learner
QuorumPacket newEpochPacket = new QuorumPacket(Leader.LEADERINFO, newLeaderZxid, ver, null);
oa.writeRecord(newEpochPacket, "packet");
bufferedOutput.flush();
QuorumPacket ackEpochPacket = new QuorumPacket();
//发送包含该epoch的LeaderInfo消息后等待Learner响应
//读取Learner返回的ackNewEpoch响应
ia.readRecord(ackEpochPacket, "packet");
...
//等待过半Learner响应
leader.waitForEpochAck(this.getSid(), ss);
...
//解析Learner最后处理的ZXID,接下来执行与Learner的数据同步
peerLastZxid = ss.getLastZxid();
boolean needSnap = syncFollower(peerLastZxid, leader.zk.getZKDatabase(), leader);
if (needSnap) {
long zxidToSend = leader.zk.getZKDatabase().getDataTreeLastProcessedZxid();
oa.writeRecord(new QuorumPacket(Leader.SNAP, zxidToSend, null, null), "packet");
bufferedOutput.flush();
// Dump data to peer
leader.zk.getZKDatabase().serializeSnapshot(oa);
oa.writeString("BenWasHere", "signature");
bufferedOutput.flush();
}
LOG.debug("Sending NEWLEADER message to " + sid);
if (getVersion() < 0x10000) {
QuorumPacket newLeaderQP = new QuorumPacket(Leader.NEWLEADER, newLeaderZxid, null, null);
oa.writeRecord(newLeaderQP, "packet");
} else {
QuorumPacket newLeaderQP = new QuorumPacket(Leader.NEWLEADER, newLeaderZxid, leader.self.getLastSeenQuorumVerifier().toString().getBytes(), null);
queuedPackets.add(newLeaderQP);
}
bufferedOutput.flush();
//Start thread that blast packets in the queue to learner
startSendingPackets();
//Have to wait for the first ACK, wait until the leader is ready, and only then we can start processing messages.
qp = new QuorumPacket();
ia.readRecord(qp, "packet");
//阻塞等待过半Learner完成数据同步,接下来就可以启动QuorumPeer服务器实例了
leader.waitForNewLeaderAck(getSid(), qp.getZxid());
...
while (true) {
//这里有关于Leader和Learner之间保持心跳的处理
}
}
public boolean syncFollower(long peerLastZxid, ZKDatabase db, Leader leader) {
boolean isPeerNewEpochZxid = (peerLastZxid & 0xffffffffL) == 0;
//Keep track of the latest zxid which already queued
long currentZxid = peerLastZxid;
boolean needSnap = true;
boolean txnLogSyncEnabled = db.isTxnLogSyncEnabled();
ReentrantReadWriteLock lock = db.getLogLock();
ReadLock rl = lock.readLock();
try {
rl.lock();
long maxCommittedLog = db.getmaxCommittedLog();
long minCommittedLog = db.getminCommittedLog();
long lastProcessedZxid = db.getDataTreeLastProcessedZxid();
if (db.getCommittedLog().isEmpty()) {
minCommittedLog = lastProcessedZxid;
maxCommittedLog = lastProcessedZxid;
}
if (forceSnapSync) {
//Force leader to use snapshot to sync with follower
LOG.warn("Forcing snapshot sync - should not see this in production");
} else if (lastProcessedZxid == peerLastZxid) {
//Follower is already sync with us, send empty diff
LOG.info("Sending DIFF zxid=0x" + Long.toHexString(peerLastZxid) + " for peer sid: " + getSid());
queueOpPacket(Leader.DIFF, peerLastZxid);
needOpPacket = false;
needSnap = false;
} else if (peerLastZxid > maxCommittedLog && !isPeerNewEpochZxid) {
//Newer than committedLog, send trunc and done
//方式三:仅回滚同步(TRUNC同步),peerLastZxid大于maxCommittedLog
LOG.debug("Sending TRUNC to follower zxidToSend=0x" + Long.toHexString(maxCommittedLog) + " for peer sid:" + getSid());
queueOpPacket(Leader.TRUNC, maxCommittedLog);
currentZxid = maxCommittedLog;
needOpPacket = false;
needSnap = false;
} else if ((maxCommittedLog >= peerLastZxid) && (minCommittedLog <= peerLastZxid)) {
//Follower is within commitLog range
LOG.info("Using committedLog for peer sid: " + getSid());
Iterator<Proposal> itr = db.getCommittedLog().iterator();
currentZxid = queueCommittedProposals(itr, peerLastZxid, null, maxCommittedLog);
needSnap = false;
} else if (peerLastZxid < minCommittedLog && txnLogSyncEnabled) {
//方式四:全量同步(SNAP同步),peerLastZxid小于minCommittedLog
//Use txnlog and committedLog to sync
//Calculate sizeLimit that we allow to retrieve txnlog from disk
long sizeLimit = db.calculateTxnLogSizeLimit();
//This method can return empty iterator if the requested zxid is older than on-disk txnlog
Iterator<Proposal> txnLogItr = db.getProposalsFromTxnLog(peerLastZxid, sizeLimit);
if (txnLogItr.hasNext()) {
LOG.info("Use txnlog and committedLog for peer sid: " + getSid());
currentZxid = queueCommittedProposals(txnLogItr, peerLastZxid, minCommittedLog, maxCommittedLog);
LOG.debug("Queueing committedLog 0x" + Long.toHexString(currentZxid));
Iterator<Proposal> committedLogItr = db.getCommittedLog().iterator();
currentZxid = queueCommittedProposals(committedLogItr, currentZxid, null, maxCommittedLog);
needSnap = false;
}
//closing the resources
if (txnLogItr instanceof TxnLogProposalIterator) {
TxnLogProposalIterator txnProposalItr = (TxnLogProposalIterator) txnLogItr;
txnProposalItr.close();
}
} else {
LOG.warn("Unhandled scenario for peer sid: " + getSid());
}
LOG.debug("Start forwarding 0x" + Long.toHexString(currentZxid) + " for peer sid: " + getSid());
leaderLastZxid = leader.startForwarding(this, currentZxid);
} finally {
rl.unlock();
}
if (needOpPacket && !needSnap) {
// This should never happen, but we should fall back to sending
// snapshot just in case.
LOG.error("Unhandled scenario for peer sid: " + getSid() + " fall back to use snapshot");
needSnap = true;
}
return needSnap;
}
rivate void queueOpPacket(int type, long zxid) {
QuorumPacket packet = new QuorumPacket(type, zxid, null, null);
queuePacket(packet);
}
void queuePacket(QuorumPacket p) {
queuedPackets.add(p);
}
protected long queueCommittedProposals(Iterator<Proposal> itr, long peerLastZxid, Long maxZxid, Long lastCommittedZxid)
boolean isPeerNewEpochZxid = (peerLastZxid & 0xffffffffL) == 0;
long queuedZxid = peerLastZxid;
//as we look through proposals, this variable keeps track of previous proposal Id.
long prevProposalZxid = -1;
while (itr.hasNext()) {
Proposal propose = itr.next();
long packetZxid = propose.packet.getZxid();
//abort if we hit the limit
if ((maxZxid != null) && (packetZxid > maxZxid)) {
break;
}
//skip the proposals the peer already has
if (packetZxid < peerLastZxid) {
prevProposalZxid = packetZxid;
continue;
}
//If we are sending the first packet, figure out whether to trunc or diff
if (needOpPacket) {
//Send diff when we see the follower's zxid in our history
if (packetZxid == peerLastZxid) {
LOG.info("Sending DIFF zxid=0x" + Long.toHexString(lastCommittedZxid) + " for peer sid: " + getSid());
queueOpPacket(Leader.DIFF, lastCommittedZxid);
needOpPacket = false;
continue;
}
if (isPeerNewEpochZxid) {
//Send diff and fall through if zxid is of a new-epoch
LOG.info("Sending DIFF zxid=0x" + Long.toHexString(lastCommittedZxid) + " for peer sid: " + getSid());
queueOpPacket(Leader.DIFF, lastCommittedZxid);
needOpPacket = false;
} else if (packetZxid > peerLastZxid ) {
//Peer have some proposals that the leader hasn't seen yet
//it may used to be a leader
if (ZxidUtils.getEpochFromZxid(packetZxid) != ZxidUtils.getEpochFromZxid(peerLastZxid)) {
//We cannot send TRUNC that cross epoch boundary.
//The learner will crash if it is asked to do so.
//We will send snapshot this those cases.
LOG.warn("Cannot send TRUNC to peer sid: " + getSid() + " peer zxid is from different epoch" );
return queuedZxid;
}
LOG.info("Sending TRUNC zxid=0x" + Long.toHexString(prevProposalZxid) + " for peer sid: " + getSid());
queueOpPacket(Leader.TRUNC, prevProposalZxid);
needOpPacket = false;
}
}
if (packetZxid <= queuedZxid) {
// We can get here, if we don't have op packet to queue
// or there is a duplicate txn in a given iterator
continue;
}
//Since this is already a committed proposal, we need to follow it by a commit packet
queuePacket(propose.packet);
queueOpPacket(Leader.COMMIT, packetZxid);
queuedZxid = packetZxid;
}
if (needOpPacket && isPeerNewEpochZxid) {
//We will send DIFF for this kind of zxid in any case.
//This if-block is the catch when our history older than learner and there is no new txn since then.
//So we need an empty diff
LOG.info("Sending DIFF zxid=0x" + Long.toHexString(lastCommittedZxid) + " for peer sid: " + getSid());
queueOpPacket(Leader.DIFF, lastCommittedZxid);
needOpPacket = false;
}
return queuedZxid;
}
...
}