1、概述
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。它由俄罗斯的互联网巨头Yandex为解决其内部数据分析需求而开发,并于2016年开源。专为大规模数据分析,实时数据分析和复杂查询设计,具有高性能、实时数据和可扩展性等特点。
2、主要特性
(1)、列式存储
- 原理:
将数据按列存储,而非传统的行式存储(如 MySQL)。- 优势:
- 高效查询:仅读取相关列,减少I/O开销,尤其是对于聚合类操作时,性能非常高效。
- 高压缩率:相同列的数据压缩效率更高(如ZSTD、LZ4算法)。
- 向量化执行:CPU 可批量处理同一列的多行数据,提升计算速度。
- 优势:
(2)、MPP架构(分布式处理)
- MPP(大规模集群并行处理):
支持分布式计算,查询可拆分为多个任务并行执行,具有良好的扩展性。- 分布式表:
将数据分片(Shard)存储在多个节点,查询时自动合并结果。 - 副本机制:
每个分片可配置多个副本(Replica),确保高可用性。
- 分布式表:
(3)、高性能查询引擎
- 向量化执行:
以 数据块(Block) 为单位处理数据(默认 8192 行/块),利用 SIMD 指令加速计算。 - 预计算与索引:
- Projection(投影):预定义数据的排序、过滤和聚合规则,查询时直接使用预处理数据。
- 物化视图(Materialized View):预先计算复杂查询结果,实时更新。
(4)、SQL 支持
基本使用类似Mysql,熟悉SQL的用户可以快速上手。
- 功能丰富:
- 支持标准 SQL(SELECT、JOIN、GROUP BY 等)。
- 扩展函数:如数组操作(arrayJoin)、窗口函数(ROW_NUMBER)、聚合函数(quantile)。
- 实时写入:
支持批量插入(INSERT)和流式数据(如 Kafka、MySQL Binlog)。
(5)、分布式与扩展性
- 集群模式:
通过 Distributed 表引擎管理分片和副本,自动负载均衡。 - 数据分区(Partition):
按时间或字段分区(如 PARTITION BY toYYYYMM(date)),加速范围查询。
(6)、安全与权限
- RBAC(基于角色的访问控制):
支持用户、角色、行级权限管理。 - 数据加密:
支持 SSL/TLS 加密传输,存储加密需依赖外部工具。
(7)、多核并行处理
能够充分利用现代服务器的多核架构,提高查询执行速度。
(8)、外部存储集成
除了本地文件系统之外,还支持从HDFS等多种外部存储系统中读取数据。
3、适用场景
ClickHouse非常适合需要快速响应的大规模数据查询任务。
(1)、大数据分析
如用户行为分析、广告点击统计,支持PB级数据的多维分析。
特别适合那些需要对大量历史数据进行复杂查询分析的业务场景。
(2)、实时数据分析与监控
生成实时业务指标(如电商 GMV、DAU),广告网络及RTB(实时竞价),支持高并发查询。
(3)、日志存储与检索
高效压缩存储日志数据(如 Nginx 日志),快速检索关键信息,电信行业中的通话记录分析。
4、架构特点
(1)、分布式MPP架构
通过分片(Sharding)和副本(Replication)实现数据分布式存储与计算,支持跨节点并行查询。
(2)、存储引擎
- 核心表引擎:
- MergeTree 家族:
- MergeTree:基础引擎,支持排序、分区、数据合并。
- RepliatedMergeTree:分布式场景下保证数据一致性。
- TinyLog/StripeLog:简单存储引擎,无并发控制(适合小数据测试)。
- MergeTree 家族:
- 其他引擎:
- Memory:内存表,重启后数据丢失。
- Distributed:分布式表,协调分片查询。
(3)、高效压缩与数据类型
每列独立选择压缩算法(如 LZ4、ZSTD),支持 UInt/Int 系列、日期/时间、字符串等丰富数据类型。
(4)、数据写入机制
- 追加写入(Append-Only):
数据以 块(Block) 形式追加到磁盘,不可直接更新或删除(需 ALTER TABLE ... DELETE 语句,但性能较低)。 - Merge Tree 合并:
定期合并小数据块为大块,优化查询性能。
5、使用示例
(1)、查询执行流程:
- 查询解析:
SQL 转换为执行计划,优化器选择最优路径。 - 并行执行:
查询拆分到多个分片,每个分片在本地执行。 - 结果聚合:
各节点返回结果后,协调节点合并最终结果。
(2)、具体示例:
1. 创建表
-- 使用 MergeTree 引擎,按日期分区,按订单ID排序
java
CREATE TABLE orders (
order_id UInt32,
customer_id UInt32,
product_id UInt32,
order_date Date,
order_amount Float32
) ENGINE = MergeTree()
PARTITION BY toYYYYMM(order_date)
ORDER BY order_id;2. 数据插入
-- 批量插入提升效率
java
INSERT INTO orders VALUES
(1, 101, 1001, '2024-07-01', 500.0),
(2, 102, 1002, '2024-07-01', 300.0),
(3, 103, 1003, '2024-07-02', 700.0);3. 复杂查询
-- 订单金额按日期聚合
java
SELECT
order_date,
COUNT(order_id) AS order_count,
SUM(order_amount) AS total_amount
FROM orders
GROUP BY order_date
ORDER BY order_date;6、使用建议
(1)、性能优化
-
分区表:
按时间或高频查询字段分区(如 PARTITION BY toYYYYMM(date))。
-
Projection(投影):
预定义数据排序和过滤规则,加速特定查询。
sql示例:
CREATE PROJECTION orders_projection
(order_date, customer_id, order_amount)
PARTITION BY toYYYYMM(order_date)
ORDER BY (customer_id, order_date)
SETTINGS index_granularity = 8192;
-
批量插入:
减少单次插入数据量,避免频繁小批量操作。
-
合理索引:
使用 MARK 或稀疏索引(如 index_granularity)加速范围查询。
(2)、分布式配置
- 分片策略:
根据查询热点合理分配分片,避免数据倾斜。 - 副本机制:
每个分片至少 3 个副本,确保高可用性。
(3)、资源管理
- 内存控制:
调整 max_memory_usage 防止查询 OOM。 - 日志与监控:
使用 system.parts、system.merges 监控数据合并状态。
7、局限性和适用场景
(1)、局限性
- 不支持复杂事务:
仅保证单行写入原子性,不支持 ACID 事务。 - 数据更新与删除:
通过 ALTER TABLE ... DELETE 语句实现,但性能较低(建议通过新数据覆盖旧数据)。 - 索引限制:
仅支持基于主键的排序索引,不支持 B-Tree 索引。
(2)、适用场景
- OLAP 场景:
高并发查询、实时分析、大数据量(TB/PB 级)。 - 读多写少:
适合批量写入、频繁读取的场景(如日志分析、报表生成)。
(3)、不适用场景
- OLTP 场景:
高频事务性操作(如订单系统)。 - 复杂事务:
需要多行事务或细粒度更新的场景。
8、与其他数据库的对比
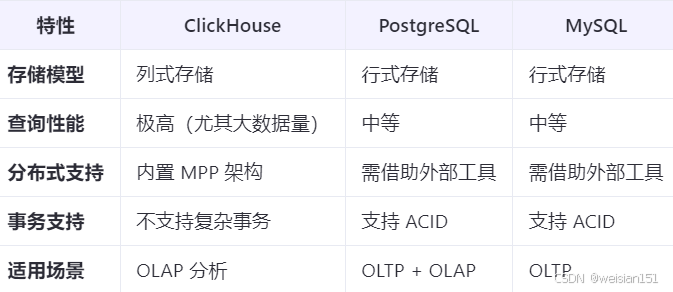
9、社区与生态
- 开源社区:
GitHub 仓库:https://github.com/ClickHouse/ClickHouse。 - 企业支持:
ClickHouse Inc. 提供云服务(ClickHouse Cloud)和企业版(高级功能、技术支持)。 - 工具生态:
- 客户端:clickhouse-client、DBeaver。
- ETL 工具:Airflow、Kafka、Debezium。
10、ClickHouse总结
ClickHouse是一款专为高性能OLAP分析设计的列式数据库,凭借列式存储、分布式架构和实时分析能力,特别适合处理海量数据的实时查询和复杂分析。
不过,其局限性在于不支持事务和行级更新,更适用于读多写少、批量写入的分析型业务。
在选择使用ClickHouse之前,也需要考虑其相对复杂的配置(如:表结构、使用Projection、分布式配置)和调优过程,以及与其他系统集成时可能遇到的挑战。
逆风翻盘,Dare To Be!!!