这是一篇 ACM Transactions on Graphic 上的文章,这篇文章中介绍的应用还挺有意思的,关于可逆的图像灰度化。
Abstract
一旦彩色图像被转换为灰度图像,人们普遍认为,即使采用最先进的彩色化方法,原始颜色也无法完全恢复。在本文中,我们提出了一种创新方法来合成可逆灰度图像。这种灰度图像能够完全恢复其原始颜色。其关键思路是将原始颜色信息编码到合成的灰度图像中,且采用的方式要让用户无法察觉任何异常之处。我们提议通过卷积神经网络(CNN)来学习并嵌入颜色编码方案。该方案由一个将彩色图像转换为灰度图像的编码网络,以及一个将灰度图像还原为彩色图像的解码网络组成。然后,我们设计了一个损失函数,以确保经过训练的网络具备三个必要特性:(a)颜色可逆性;(b)灰度一致性;(c)对量化误差的抗性。我们针对大量彩色图像进行了深入的定量实验和用户研究,以验证所提出的方法。无论彩色输入图像的类型和内容如何,在所有情况下都取得了令人信服的结果。
Introduction

- 图 1
人们出于各种目的和应用将彩色图像转换为灰度图像,范围从黑白打印、艺术摄影,到传统显示器的向后兼容性。然而,在彩色到灰度的转换过程中,颜色信息会丢失。尽管人们可以使用现有的彩色化方法(如饭塚等人 2016 年的研究;张等人 2016 年的研究)对灰度图像进行彩色化处理,但所添加的颜色可能并非原始的颜色。
在本文中,我们提出了一种创新方法,可将彩色图像转换为灰度图像,并且之后该灰度图像能够被还原回其彩色版本。我们将其称为可逆灰度图像。图 1 展示了由彩色输入图像(左侧)生成的可逆灰度图像(中间),而右侧的图像则是还原后的彩色图像。这里的关键思路是将原始颜色信息编码到生成的灰度图像中,以便在后续的颜色还原过程中能够恢复所编码的颜色信息。图 1 底行放大后的灰度子图像揭示了颜色是如何被编码成不明显的图案的。然而,由于输入内容的多样性是无边界的,手动设计这样一种颜色编码方案极其复杂。
相反,我们提议通过卷积神经网络(CNN)来学习并嵌入颜色编码方案。我们的系统由一个将彩色图像转换为灰度图像的编码神经网络,以及一个将灰度图像还原为彩色图像的解码神经网络组成。运用卷积神经网络的一个关键在于设计合适的损失函数。我们的损失函数由可逆性损失、灰度一致性损失和量化损失组成。
可逆性损失确保还原后的彩色图像与真实的彩色图像尽可能相似,这样我们就能还原出彩色图像。灰度一致性损失确保生成的灰度图像看起来像是彩色输入图像的灰度版本。这要求生成的灰度图像保留彩色输入图像的结构、对比度和亮度。量化损失模拟了当我们以每个像素 8 位的形式存储可逆灰度图像时的量化过程。
一旦颜色编码和还原方案经过训练,我们就可以将其应用于任意彩色图像,且对图像的视觉内容没有任何限制。为了验证我们的模型,我们在 3000 张不同类型和内容的自然图像上进行了测试。我们进行了定性和定量评估,以及用户研究。在所有实验中都获得了令人信服的统计数据。例如,在将还原后的彩色图像与原始输入图像进行比较时,我们实现了非常高的平均结构相似性指数(SSIM)为 0.9681,平均峰值信噪比(PSNR)为 36.02 分贝。我们的贡献可以总结如下:
- 我们提出了一种创新方法,可将彩色图像转换为灰度图像,并且在必要时能够将该灰度图像还原回其彩色版本。
- 我们提出在神经网络框架中制定颜色编码方案,从而为生成可逆灰度图像提供一种有效且高效的解决方案。
虽然我们当前的方法是专门为解决可逆的彩色转灰度问题而设计的,但所提出的通用神经网络框架可以应用于许多其他需要具备可逆能力的应用场景。在生成的图像中要编码的信息可以是颜色,或者是任何其他信息。该框架用于以视觉上不明显的方式对信息进行编码,同时编码后的信息可以通过解码网络进行恢复。
Overview
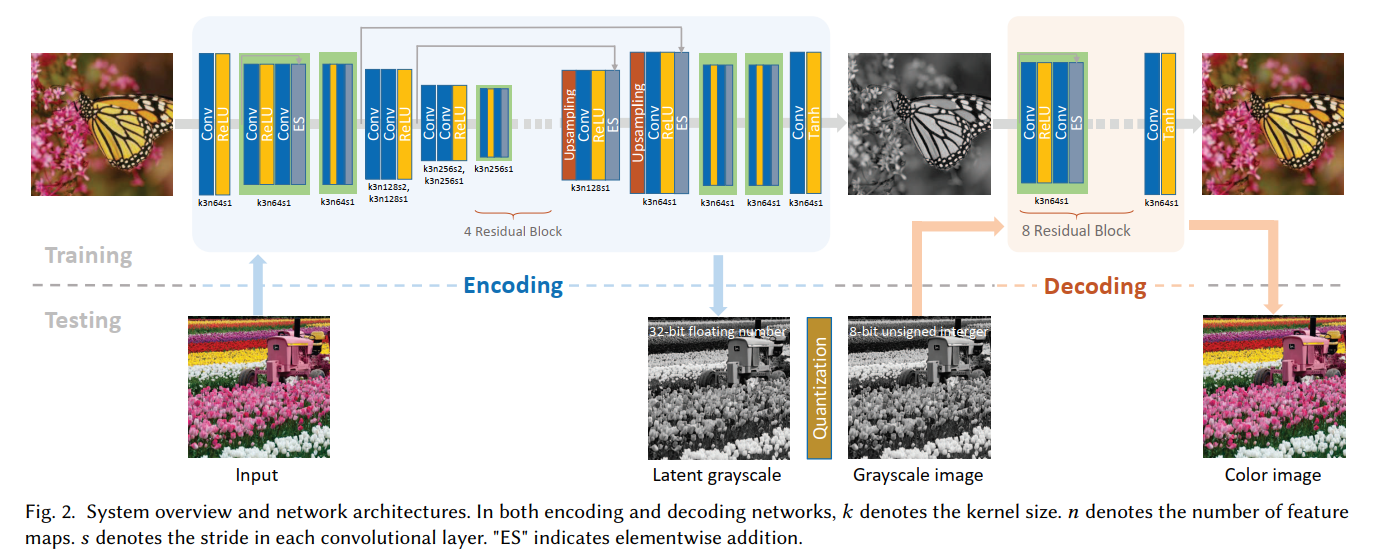
- 图 2
我们的系统概览如图 2 所示,它由一个编码神经网络 E E E 和解码神经网络 D D D 组成。编码神经网络 E E E 将 RGB 色彩空间中的任何彩色图像转换为灰度图像。相反,解码神经网络 D D D 将任何灰度图像转换为 RGB 空间中的彩色图像。 E E E 和 D D D 的网络架构将在第 4 节中详细介绍。
在训练阶段,对于训练数据集中的每一幅彩色图像 I I I,我们使用编码器 E E E 将其转换为灰度图像 G G G,然后使用解码器 D D D 从 G G G 中还原出一幅彩色图像 R R R。也就是说:
G = E ( I ) (1) G=E(I) \tag{1} G=E(I)(1)
R = D ( G ) = D ( E ( I ) ) (2) R = D(G) = D(E(I)) \tag{2} R=D(G)=D(E(I))(2)
通过对灰度图像 G G G 和还原后的彩色图像 R R R 提出要求,进而对编码器 E E E 和解码器 D D D 提出要求,我们对 E E E 和 D D D 进行联合训练。具体来说,我们设计了三种损失函数:可逆性损失 L V ( E , D ) \mathcal{L}_V(E, D) LV(E,D),它确保图像 I I I 和图像 R R R 相似;灰度一致性损失 L C ( E ) \mathcal{L}_C(E) LC(E),它确保灰度图像 G G G 看起来像一幅灰度图像且与彩色图像 I I I 相符;量化损失 L Q ( E ) \mathcal{L}_Q(E) LQ(E),它促使灰度图像 G G G 的像素值为整数。然后,总体损失函数 L ( E , D ) \mathcal{L}(E, D) L(E,D)被表示为这三种损失的加权和:
L ( E , D ) = L V ( E , D ) + ω 1 L C ( E ) + ω 2 L Q ( E ) (3) L(E, D) = L_V(E, D) + \omega_1L_C(E) + \omega_2L_Q(E) \quad \tag{3} L(E,D)=LV(E,D)+ω1LC(E)+ω2LQ(E)(3)
这些损失函数的详细设计将在第 5 节中讨论。训练方案将在第 6 节中详细阐述。由于权重在不同的训练阶段有所不同,权重参数也会在第 6 节中进行讨论。在测试阶段,对于任意给定的彩色输入图像 I I I,我们首先使用编码器 E E E 将其转换为灰度图像 G = E ( I ) G = E (I) G=E(I)。需要注意的是, G G G 的每个像素实际上是一个 32 位的浮点数。因此,我们必须将 G G G 量化为一个 8 位的灰度图像 G ˉ \bar{G} Gˉ,这样 G ˉ \bar{G} Gˉ 中的所有像素值都是介于 0, 255 之间的整数。还原后的彩色图像 R R R 可以通过 R = D ( G ˉ ) R = D (\bar{G}) R=D(Gˉ) 得到。结果以及深入的验证实验将在第 7 节中呈现。
Network Architecture
如前所述,我们的系统由一个将彩色输入转换为灰度图像的编码网络,以及一个将灰度图像转换为彩色图像的解码网络组成。乍一看,这似乎是彩色图像和灰度图像之间的循环转换,并且似乎可以用 CycleGAN(朱等人,2017 年)来解决。然而,CycleGAN 仅能保证输出图像符合相应的图像类别(灰度或彩色)。由于 CycleGAN 具有无监督的特性,无法保证生成的灰度图像像我们所要求的那样与相应的输入彩色图像相符。
我们的编解码框架也与哈希自动编码器(卡雷拉 - 佩皮南和拉齐佩尔奇科拉埃伊,2015 年;恩等人,2017 年)相近。然而,尽管现有的自动编码器可能实现可逆性,但它们都没有对潜在表示的视觉外观提出任何要求。在我们的情况中,我们要求潜在的稀疏表示能够可视化为一幅与彩色输入相符的灰度图像。
我们所提出的编码网络和解码网络的详细架构如图 2 所示,每个模块下方都标注了关键参数。编码网络包含两个下卷积模块、两个上卷积模块、八个残差模块(何等人,2016 年)以及两个平面卷积层。在这里,下 / 上卷积结构用于扩大感受野以进行特征提取。解码网络包含八个残差模块和一个平面卷积层。
我们仅在编码网络中采用下 / 上卷积结构,这是因为在将颜色信息编码到灰度图像中时,需要更丰富的邻域上下文信息,而将灰度图像解码回彩色图像则相对局部化。
在使用下 / 上卷积结构的同时,我们还在编码网络中采用了跳跃连接策略(龙内贝格尔等人,2015 年),以抑制在降采样 / 升采样过程中出现的模糊伪影。图 3 展示了不使用和使用下 / 上卷积结构的对比情况。如图 3 (b) 所示,在不使用下 / 上卷积结构时,在墙壁上可以观察到明显的伪影。
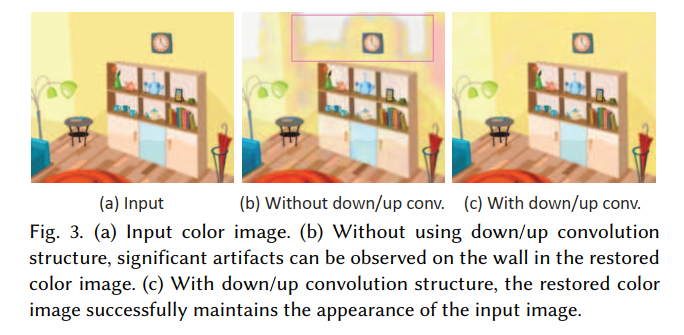
- 图 3 (a) 输入的彩色图像。(b) 在不使用下采样 / 上采样卷积结构的情况下,在恢复后的彩色图像中,墙壁上可以观察到明显的伪影。© 使用了下采样 / 上采样卷积结构后,恢复的彩色图像成功保留了输入图像的外观。
Loss Function
如公式 3 所示,我们的损失函数由三项组成:可逆性损失 L V ( E , D ) \mathcal{L}_V(E, D) LV(E,D)、灰度一致性损失 L C ( E ) \mathcal{L}_C(E) LC(E) 以及量化损失 L Q ( E ) \mathcal{L}_Q(E) LQ(E)。
Invertibility Loss
给定一个输入彩色图像I以及还原后的彩色输出 R = D ( E ( I ) ) R = D(E(I)) R=D(E(I)),可逆性损失 L V ( E , D ) L_V(E, D) LV(E,D) 确保 I I I 和 R R R 尽可能相似。我们简单地使用逐像素均方误差(MSE)来规范这种相似性:
L V ( E , D ) = E I ∈ I { ∥ R − I ∥ 2 2 } (4) L_V(E, D) = E_{I \in \mathcal{I}}\{\|R - I\|_2^2\} \tag{4} LV(E,D)=EI∈I{∥R−I∥22}(4)
这里, ∥ ⋅ ∥ 2 \|\cdot\|_2 ∥⋅∥2表示 L 2 L_2 L2范数(均方误差), E E E 表示在训练数据集 I \mathcal{I} I 中所有图像上的平均算子。由于 R R R 是通过编码器 E E E 和解码器 D D D 共同生成的,这种损失有效地对 E E E 和 D D D 的参数都施加了约束。
Grayscale Conformity Loss
给定彩色输入图像 I I I 以及转换后的灰度图像 G = E ( I ) G = E(I) G=E(I),一致性损失 L C ( E ) L_C(E) LC(E) 确保灰度图像 G G G 在视觉上与原始彩色输入图像 I I I 相符,并且符合人们对灰度图像外观的普遍预期。在此,我们再次强调,灰度转换并没有绝对的标准。简单的灰度表示方法是采用 CIE Lab 色彩空间中的 L L L 通道,或者 YIQ/YUV 色彩空间中的 Y Y Y 通道作为灰度,这些方法并不着重保留区域对比度。一些去色方法(如刘等人 2015 年、陆等人 2012 年的研究)采用了更为复杂的计算来保留对比度。就我们的情况而言,我们的主要目标是以不明显的模式对颜色信息进行编码。因此,我们需要一种相对宽松的形式作为灰度一致性损失,而不是仅仅限制均方误差。具体来说,我们的灰度一致性损失由三个子项组成:亮度损失、对比度损失和局部结构损失。
Lightness Loss ,亮度损失确保生成的灰度图像 G G G 在视觉上与彩色图像 I I I 的亮度相符。也就是说,亮的区域依然保持亮,暗的区域依然保持暗。然而,我们需要为颜色编码留出一定的空间。这是通过在公式中允许存在一个灰度差异 θ \theta θ 来实现的。具体而言,如果差异小于阈值 θ \theta θ,则亮度保持损失 ℓ l ( E ) \ell_l (E) ℓl(E)被视为 0:
ℓ l ( E ) = E I ∈ I { ∥ max { ∣ G − L ( I ) ∣ − M θ , M 0 } ∥ 1 } (5) \ell_l(E) = \mathbb{E}{I \in \mathcal{I}}\{\| \max\{|G - L(I)| - M{\theta}, M_{0}\} \|_1\} \tag{5} ℓl(E)=EI∈I{∥max{∣G−L(I)∣−Mθ,M0}∥1}(5)
这里, ∥ ⋅ ∥ 1 \|\cdot\|1 ∥⋅∥1 表示 L 1 L_1 L1 范数。 ∣ ⋅ ∣ |\cdot| ∣⋅∣ 是按元素的绝对值运算符。 L ( I ) L(I) L(I)表示图像 I I I 的亮度通道。 max { ⋅ , ⋅ } \max\{\cdot, \cdot\} max{⋅,⋅}是两个相同大小矩阵之间按元素的取最大值运算符。 M θ / M 0 M{\theta} / M_{0} Mθ/M0 是与 G G G 大小相同的矩阵,其中 M θ M_{\theta} Mθ 的每个元素都等于 θ \theta θ, M 0 M_{0} M0 的每个元素都等于0。由于图像 I I I 和 G G G 中的像素值定义在 0 , 255 0, 255 0,255 范围内,在我们所有的实验中,根据经验将 θ \theta θ 设置为70。请注意,这个要求极其宽松,目的是为了能有更大的搜索空间。
Contrast Loss ,对比度损失旨在让生成的灰度图像 G G G 保留输入彩色图像I的全局对比度。我们发现,预训练的 VGG - 19 网络(西蒙扬和齐斯曼,2014 年)所定义的高层特征在表示全局对比度方面效果极佳。因此,我们将对比度损失 ℓ c ( E ) \ell_c(E) ℓc(E) 定义为图像 I I I 和 G G G 对应 VGG 层之间的相似度,具体如下:
ℓ c ( E ) = E I ∈ I { ∥ V G G k ( G ) − V G G k ( I c ) ∥ 1 } (6) \ell_c(E) = \mathbb{E}_{I \in \mathcal{I}}\{\|VGG_k(G) - VGG_k(I_c)\|_1\} \tag{6} ℓc(E)=EI∈I{∥VGGk(G)−VGGk(Ic)∥1}(6)
这里, V G G k ( ⋅ ) VGG_k(\cdot) VGGk(⋅) 表示从一幅图像中提取的第 k k k 个 VGG 层。具体来说,我们使用图像 G G G 和 I I I 的'conv4_4'层来强化全局对比度的相似度。c是图像I的颜色通道索引,取值范围为 { 1 , 2 , 3 } \{1, 2, 3\} {1,2,3}。
Local Structure Loss , 最后一项子损失旨在让灰度图像G保留彩色输入图像I的局部结构。也就是说,如果输入图像中的某个像素在局部是平滑的,那么在生成的灰度图像中它也应保持平滑。这可以防止灰度图像中的颜色编码模式过于明显。为了衡量结构相似度,我们采用了简单而有效的局部方差方法。因此,局部结构损失 ℓ s ( E ) \ell_s(E) ℓs(E)可以表示为:
ℓ s ( E ) = E I ∈ I { ∥ Var ( G ) − Var ( I ) ∥ 1 } (7) \ell_s(E) = E_{I \in \mathcal{I}}\{\| \text{Var}(G) - \text{Var}(I) \|_1\} \tag{7} ℓs(E)=EI∈I{∥Var(G)−Var(I)∥1}(7)
其中, Var ( ⋅ ) \text{Var}(\cdot) Var(⋅)是一个计算图像局部方差均值的函数。
Combined Loss, 组合损失。整体的灰度一致性损失是上述三个子项的加权和:
L C ( E ) = ℓ l ( E ) + α ℓ c ( E ) + β ℓ s ( E ) (8) L_C(E) = \ell_l (E) + \alpha\ell_c(E) + \beta\ell_s(E) \tag{8} LC(E)=ℓl(E)+αℓc(E)+βℓs(E)(8)
其中, α \alpha α 和 β \beta β 是权重因子。我们根据经验将 α \alpha α 设为 e − 7 e ^{-7} e−7,以平衡卷积特征空间和图像像素空间之间的量级差异。权重 β = 0.5 \beta = 0.5 β=0.5 用于平衡局部结构损失和其他损失。实际上,我们发现训练结果对这些超参数并不敏感。因此,在所有实验中都采用固定值。图 4 展示了灰度一致性损失及其每个子项的重要性。如果没有灰度一致性损失,图(b)中生成的灰度图像看起来并不像彩色输入图像的灰度版本。如果去掉亮度项,如图(c)中花瓣所示,对比度可能会反转。如果去掉全局对比度项,灰度图像无法保留彩色输入图像的整体对比度,导致如图(d)所示的 "灰暗" 结果。如果去掉局部结构项,模型无法有效抑制颜色编码模式,如图(e)所示(与图(f)中对应的放大图相比)。只有当所有项都包含在内时,才能得到如图(f)所示的、没有明显颜色编码模式且视觉上吸引人的灰度图像。

- 图 4:灰度一致性损失及其每个子项的重要性
Quantization Loss
到目前为止,我们所讨论的图像(灰度或彩色)精度为 32 位浮点数。在实际应用中,灰度图像的每个像素以 8 位无符号整数精度存储。这种量化误差可能会在将量化后的灰度图像恢复为彩色版本时导致伪影,如图 5 (a) 所示。因此,我们提出通过以下量化损失来惩罚所有非整数像素值:
L Q ( E ) = ⟨ ∥ min d = 0 255 { ∣ G − M d ∣ } ∥ 1 ⟩ I ( 9 ) L_Q(E) = \langle \| \min_{d = 0}^{255} \{ |G - M_d| \} \|_1 \rangle_I \quad (9) LQ(E)=⟨∥d=0min255{∣G−Md∣}∥1⟩I(9)
其中, min { ⋅ } \min\{\cdot\} min{⋅}是一组相同大小矩阵之间的逐元素最小运算符。 M d M_d Md是一个与G大小相同的矩阵,其中 M d M_d Md的每个元素都等于d。通过引入量化损失,我们可以抑制量化引入的伪影,并取得显著更好的效果(图 5 (b))。
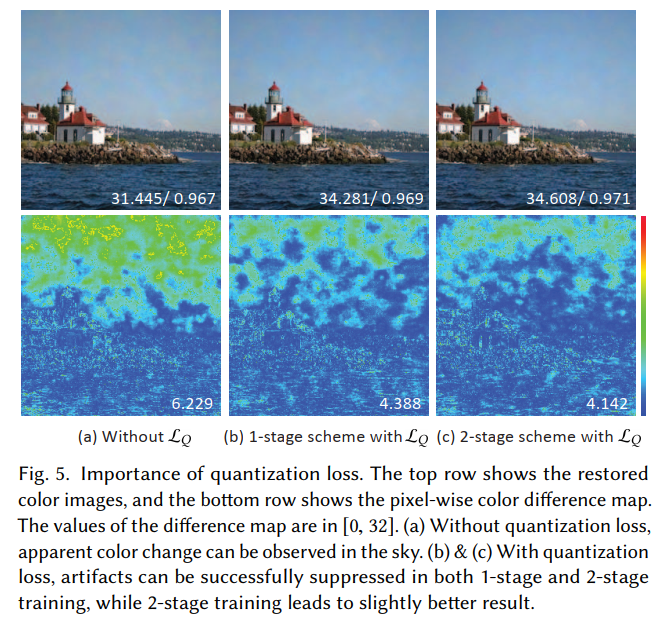
- 图 5:量化损失的重要性。上图展示的是恢复后的彩色图像,下图展示的是逐像素的颜色差异图。差异图中的值范围在 0, 32 之间。(a) 不使用量化损失时,可以明显观察到天空部分出现了颜色变化。(b) 和 © 使用量化损失时,无论是单阶段训练还是两阶段训练,都能成功抑制伪影,且两阶段训练的效果略好一些。
Training
Training Data
由于输出的真实值与输入完全相同,我们的系统实际上可以获取任意彩色图像 I I I,并将 ⟨ I , I ⟩ \langle I, I\rangle ⟨I,I⟩用作有监督训练的训练图像对。在我们的实验中,我们使用了 2012 年视觉对象分类挑战赛(VOC2012)数据集(埃弗林厄姆等人,2012)进行训练和测试。该数据集中总共有 17125 张彩色图像。其中,13758 张用于训练,其余的图像用于测试。尽管我们的数据量不是非常大,但实验表明,我们能够实现极高质量的恢复效果(平均结构相似性指数(SSIM)为 0.9681,平均峰值信噪比(PSNR)为 36.02 分贝)。使用更大的数据集,我们系统的性能可能会进一步提升,但提升幅度非常小。在训练过程中,所有输入图像都被裁剪并调整为 256×256 的分辨率,不过在测试过程中可以处理任意分辨率的图像。
Two-stage Training
我们的模型使用公式 3 中定义的损失函数进行端到端的训练。我们可以从头开始训练网络(单阶段方案),并且将训练损失随实际运行时间的变化情况绘制成图 6 中的绿色曲线。然而,量化损失是一个分段函数,既难以训练,又占用大量内存空间。因此,我们没有选择从头开始训练,而是提出了一种两阶段训练方案,以加快训练速度并减少内存消耗。在第一阶段,我们只考虑可逆性损失和灰度一致性损失。在第二阶段,则将三种损失都纳入考量。为了实现这一点,我们将公式 3 中的 ω 2 \omega_2 ω2 设置为 0,以便在前 90 个训练周期(第一阶段)中忽略量化损失,然后将其设置为一个相对较大的值,以便在随后的 30 个训练周期(第二阶段)中主要关注量化损失。公式 8 中的权重 α \alpha α 和 β \beta β 在两个阶段中保持不变。详细的参数值列于表 1 中。两阶段训练方案的训练损失随实际运行时间的变化情况绘制成图 6 中的红色曲线。每个点代表一个训练周期。两阶段训练(按实际时间计算)比单阶段训练收敛得快得多。即使训练周期数相同,两阶段训练所消耗的总时间也更少。在训练过程中,学习率初始化为 0.0002,然后在 120 个训练周期内线性递减至 0.000002。我们的模型使用 ADAM 求解器进行优化。
