Prompt Tuning 和 P-Tuning 都属于 参数高效微调方法(PEFT, Parameter-Efficient Fine-Tuning),主要是为了避免对大模型全部参数进行训练,而是通过小规模参数(prompt embedding)来适配下游任务。但两者的实现方式和应用场景有一些区别:
提示微调 仅在输入嵌入层中加入可训练的提示向量。在离散提示方法的基础上,提示微调首先在输入端 插入一组连续嵌入数值的提示词元,这些提示词元可以以自由形式 或前 缀形式 来增强输入文本,用于解决特定的下游任务。在具体实现中,只需要 将可学习的特定任务提示向量与输入文本向量结合起来一起输入到语言模型中。 P-tuning 提出了使用自由形式来组合输入文本和提示向量,通过双向 LSTM 来学习软提示词元的表示,它可以同时适用于自然语言理解和生成任务。另一种 代表性方法称为 Prompt Tuning ,它以前缀形式添加提示,直接在输入前拼 接连续型向量。在提示微调的训练过程中,只有提示的嵌入向量会根据特定任务 进行监督学习,然而由于只在输入层中包含了极少量的可训练参数,有研究工作 表明该方法的性能高度依赖底层语言模型的能力 。下图 展示了提示微调算 法的示意图。
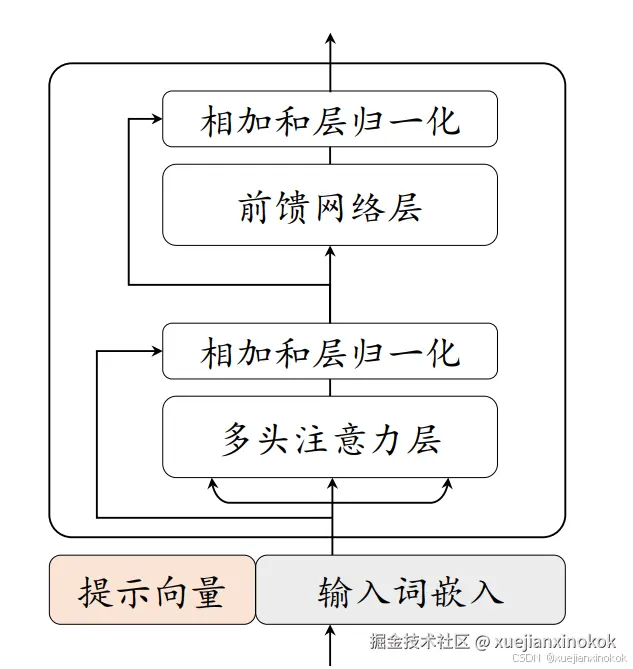
1. Prompt Tuning
-
提出者:Lester et al., 2021(Google)
-
核心思想:
- 在输入序列前面加上 可学习的"虚拟token embedding"(prompt embedding),而不是直接调模型的原始参数。
- 这些 prompt embeddings 在训练时会被更新,而模型的其他参数保持冻结。
-
应用方式:
- 常用于 encoder-decoder模型(如T5) 或 decoder-only(如GPT)任务。
- 输入
[Prompt Embeddings] + [下游任务输入]→ 模型输出。
-
特点:
- 训练参数量极小(只训练 prompt embedding)。
- Prompt 是直接加在 embedding 层,和 token embedding 维度相同。
- 更偏向 NLP生成/分类任务。
2. P-Tuning
-
提出者:Liu et al., 2021(清华)
-
核心思想:
- 最初的 P-Tuning v1:用 连续可学习 embedding 代替离散 prompt。
- P-Tuning v2 (改进版,ACL 2022):通过 深层插入虚拟 prompt embedding 到 Transformer 的多层中(不是只在输入层)。
-
应用方式:
- 适用于 分类、生成、信息抽取 等多种任务。
- v2 更适合 小数据集场景,因为它的表示能力比单层 prompt tuning 更强。
-
特点:
- P-Tuning v1 和 Prompt Tuning 类似,都是加连续 embedding。
- P-Tuning v2 比 Prompt Tuning 更强,因为不仅在输入层,而且在 Transformer 各层都插入可学习参数。
- 表现更接近全参数微调,但仍保持参数高效。
3. 区别总结
| 对比点 | Prompt Tuning | P-Tuning (v1) | P-Tuning v2 |
|---|---|---|---|
| 参数位置 | 输入层前加虚拟 embedding | 输入层前加连续 embedding | 各层 Transformer 插入虚拟 prompt |
| 训练参数量 | 极少 | 极少 | 较少(但比 Prompt Tuning 多) |
| 表达能力 | 相对较弱 | 类似 Prompt Tuning | 更强,接近全量微调 |
| 适用任务 | NLP下游任务(分类、生成) | NLP任务 | 小数据/复杂任务,泛化更好 |
| 提出方 | Google (Lester et al., 2021) | 清华 (Liu et al., 2021) | 清华 (v2, ACL 2022) |
一句话总结:
- Prompt Tuning:只在输入 embedding 层加可学习 prompt → 轻量但表达能力有限。
- P-Tuning:不仅能在输入层加 embedding,还能在 Transformer 深层插入虚拟 prompt(尤其 v2) → 表达能力更强,效果接近全参数微调。
举例说明。
1. 普通 Embedding(离散 token embedding)
在 NLP 里,输入通常是离散的 token(如 "apple"、"我"、"中国")。 这些 token 会先通过 词表查找 变成向量:
例如词表大小 = 10000,embedding 维度 = 768:
scss
"apple" → [0.12, -0.34, 0.98, ... , 0.45] (768维向量)
"中国" → [0.87, 0.22, -0.54, ... , -0.11]这些 embedding 是模型在预训练时学好的。
2. 虚拟 embedding(virtual tokens / prompt embedding)
- 意思 :人为加一些 不存在于词表中的"假token",但是它们有 embedding 向量。
- 这些向量是 随机初始化 的,然后通过训练学习,而不是固定的词表 lookup。
- 它们本身没有对应的文字,只是模型前面附加的"提示信号"。
举例:
假设我们要做 情感分类(句子 → 积极/消极),输入是:
arduino
"这部电影很精彩"用 Prompt Tuning 时,可以加 5 个虚拟 token:
css
[v1][v2][v3][v4][v5] 这部电影很精彩其中 [v1]...[v5] 就是 虚拟 embedding:
css
[v1] → [0.01, 0.77, -0.32, ...]
[v2] → [0.55, -0.88, 0.14, ...]
...这些 embedding 不属于词表,但会在训练过程中学会 如何引导模型输出"积极/消极"。
3. 连续 embedding(continuous prompt)
- 意思 :Prompt 不再用自然语言("Please classify the sentiment..."),而是直接用 连续向量。
- 这个概念最早是 P-Tuning v1 提的,本质和虚拟 embedding 很像,但强调它是 连续空间里的可学习向量,而不是离散 token(不可再映射回"文字")。
举例:
离散 prompt(人写的文字)可能是:
arduino
"这部电影很精彩 [MASK]"连续 prompt(P-Tuning)则是:
scss
[0.12, -0.33, 0.98, ...] (embedding1)
[0.54, 0.11, -0.66, ...] (embedding2)
[0.22, -0.77, 0.44, ...] (embedding3)
这部电影很精彩区别在于:
- 离散 prompt = 用真实 token(如 "Please", "answer")拼出来。
- 连续/虚拟 prompt = 直接用可训练的向量,不需要映射回文字。
4. 总结
-
虚拟 embedding = 给模型输入前面加"假 token",它们的 embedding 随训练调整。
-
连续 embedding = 直接训练连续的 embedding 向量,不一定对应词表里的任何 token。
-
本质上两者差别不大,很多时候是不同论文里对类似概念的叫法,区别主要在:
- Prompt Tuning 强调 虚拟 token embedding
- P-Tuning 强调 连续可学习 embedding(不依赖离散 token)
下边是一个 PyTorch 示例 ,演示如何在输入序列前面加上 虚拟/连续 embedding。
假设我们有一个简化的模型(类似 BERT),输入是 token embedding,我们想在输入前面加几个可学习的 prompt embedding。
🔹 PyTorch 示例代码
python
import torch
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self, vocab_size=10000, embed_dim=16, prompt_len=5):
super().__init__()
# 普通 embedding (词表)
self.embedding = nn.Embedding(vocab_size, embed_dim)
# prompt embedding (虚拟/连续向量,不属于词表)
self.prompt_embedding = nn.Parameter(torch.randn(prompt_len, embed_dim))
# 一个简单的分类头
self.fc = nn.Linear(embed_dim, 2) # 假设2分类任务
def forward(self, input_ids):
"""
input_ids: [batch_size, seq_len] (普通输入token的id)
"""
batch_size = input_ids.size(0)
# 1. 把 token id 转换成 embedding
token_embeds = self.embedding(input_ids) # [batch, seq_len, embed_dim]
# 2. prompt embedding (复制到 batch 维度)
prompt_embeds = self.prompt_embedding.unsqueeze(0).expand(batch_size, -1, -1) # [batch, prompt_len, embed_dim]
# 3. 拼接 prompt 和原始输入
full_embeds = torch.cat([prompt_embeds, token_embeds], dim=1) # [batch, prompt_len+seq_len, embed_dim]
# 假设我们只取最后一个 token 位置做分类
last_hidden = full_embeds[:, -1, :] # [batch, embed_dim]
# 分类
logits = self.fc(last_hidden)
return logits
# ======================
# 🔹 测试
# ======================
batch_size = 2
seq_len = 4
vocab_size = 10000
embed_dim = 16
prompt_len = 5
model = SimpleModel(vocab_size, embed_dim, prompt_len)
# 模拟两个样本,每个长度为4
input_ids = torch.randint(0, vocab_size, (batch_size, seq_len))
print("输入 token ids:\n", input_ids)
logits = model(input_ids)
print("输出 logits:\n", logits)🔹 运行逻辑说明
-
普通 embedding:把输入 token id 转成向量。
- 例如
[12, 87, 325, 99] → 4个 embedding
- 例如
-
prompt embedding :训练时额外引入的向量,例如
5 个虚拟 token。- 例如
[p1, p2, p3, p4, p5] → 5个 embedding
- 例如
-
拼接输入:
csharp[p1, p2, p3, p4, p5, token1, token2, token3, token4] -
模型只更新 prompt embedding ,而原始模型参数可以冻结(只让
self.prompt_embedding学习)。