文章目录
-
- [一、什么是 Redis 大 Key?](#一、什么是 Redis 大 Key?)
- [二、为什么要排查大 Key?](#二、为什么要排查大 Key?)
- [三、如何排查 Redis 大 Key?](#三、如何排查 Redis 大 Key?)
-
- [1、使用 Redis 自带的命令 bigkeys](#1、使用 Redis 自带的命令 bigkeys)
- [2、使用 SCAN + MEMORY USAGE](#2、使用 SCAN + MEMORY USAGE)
- [Redis 基本数据数据类型](#Redis 基本数据数据类型)
-
- String(字符串)
- [Hash(哈希)------ 类似一个小型的对象或 Map](#Hash(哈希)—— 类似一个小型的对象或 Map)
- [List(列表)------ 有序、可重复元素(类似队列)](#List(列表)—— 有序、可重复元素(类似队列))
- [Set(集合)------ 无序、去重元素](#Set(集合)—— 无序、去重元素)
- [Sorted Set(有序集合)------ 集合 + 分数(score)](#Sorted Set(有序集合)—— 集合 + 分数(score))
- [Bitmaps / HyperLogLog / GEO(高级场景)](#Bitmaps / HyperLogLog / GEO(高级场景))
一、什么是 Redis 大 Key?
大 key 是指:
-
单个 key 本身的内容过大(如一个超长字符串、超长列表、集合等)
-
或者一个集合类 key(如 hash、list、zset、set)中 元素数量过多
Redis 是单线程模型,一次性访问、删除大 key 可能阻塞主线程导致其他请求延迟。
常见的大 Key 类型:
| 数据类型 | 表现形式 |
|---|---|
| String | 超大字符串,如缓存整页 HTML、全文数据等 |
| List | 超长队列,如上万条记录未消费 |
| Hash | 字段数量巨大,如几万个属性 |
| Set/Sorted Set | 包含大量成员 |
二、为什么要排查大 Key?
大 Key 会带来如下问题:
- Redis 是单线程模型,操作大 Key 会阻塞其他请求,读取/写入大 Key 会拉长响应时间
- 单个 Key 占用大量内存,影响缓存命中率
- 影响客户端响应速度、增加网络传输负担
- 批量删除大 Key 极易引发"雪崩效应"
三、如何排查 Redis 大 Key?
1、使用 Redis 自带的命令 bigkeys
bash
redis-cli -h 113.44.85.42 -p 6379 -a root --bigkeys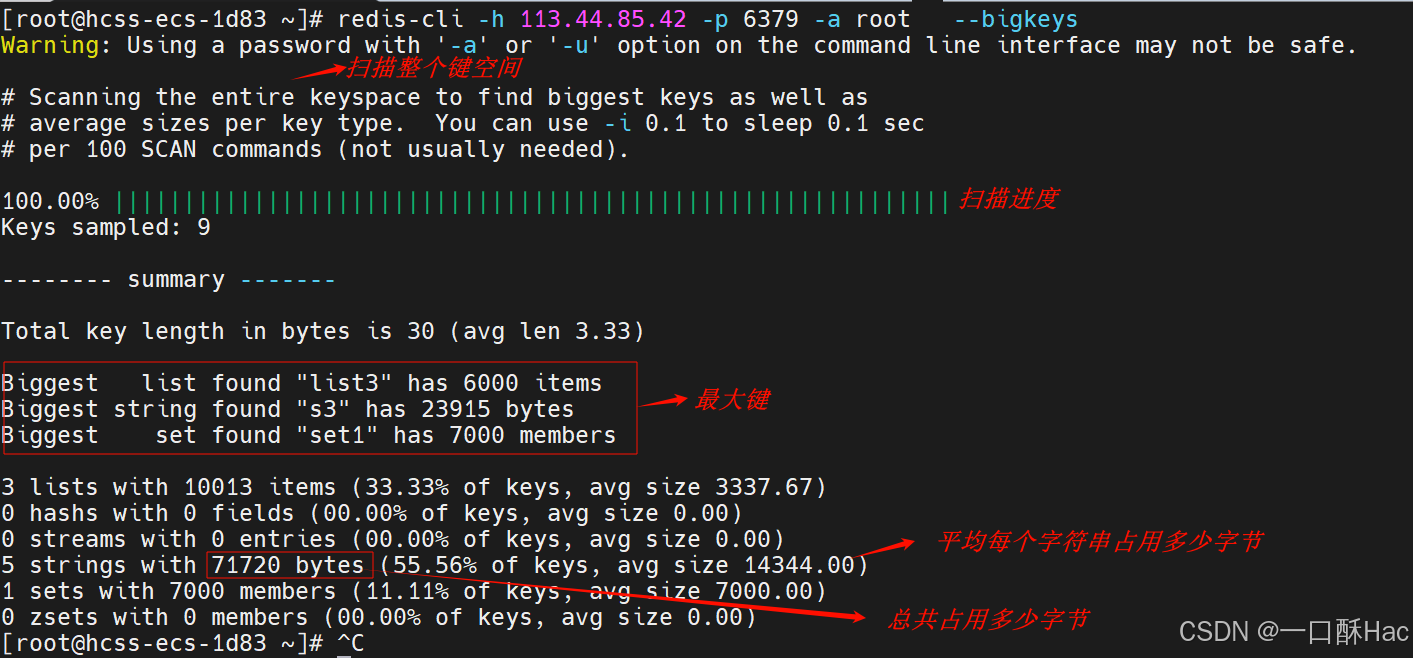
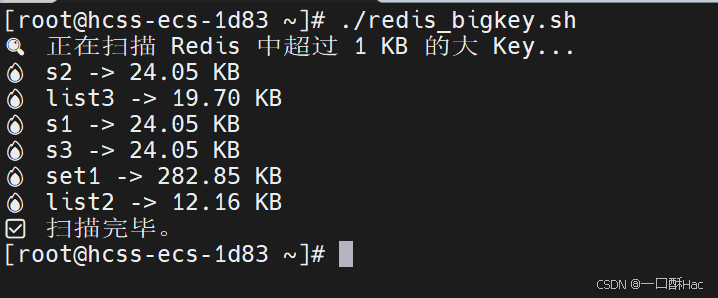
2、使用 SCAN + MEMORY USAGE
SCAN:用来遍历 Redis 的 key 空间,相比 KEYS * 更安全(不会阻塞服务器)

你可以配合 MEMORY USAGE 写脚本,批量找出大于某阈值(如 1MB)的 key。
shell脚本(阈值 1KB):
#!/bin/bash
# 配置部分
HOST=113.44.85.42
PORT=6379
PASSWORD="root" # 如果有密码,填入;没有则留空
THRESHOLD=1024 # 阈值,单位字节
COUNT=1000 # 每次 SCAN 的数量
# 设置 redis-cli 命令前缀,重定向 stderr(过滤警告)
REDIS_CLI="redis-cli -h $HOST -p $PORT"
if [[ -n "$PASSWORD" ]]; then
REDIS_CLI="$REDIS_CLI -a $PASSWORD"
fi
REDIS_CLI="$REDIS_CLI 2>/dev/null"
# 初始化游标
cursor=0
echo "🔍 正在扫描 Redis 中超过 $((THRESHOLD / 1024)) KB 的大 Key..."
# 扫描循环
while :
do
result=$(eval "$REDIS_CLI SCAN $cursor COUNT $COUNT")
cursor=$(echo "$result" | head -n 1)
keys=$(echo "$result" | tail -n +2)
for key in $keys
do
size=$(eval "$REDIS_CLI MEMORY USAGE \"$key\"")
if [[ "$size" -ge "$THRESHOLD" ]]; then
size_kb=$(awk "BEGIN { printf \"%.2f\", $size/1024 }")
echo "🔥 $key -> ${size_kb} KB"
fi
done
if [[ "$cursor" == "0" ]]; then
echo "✅ 扫描完毕。"
break
fi
done效果:
Redis 基本数据数据类型
String(字符串)
示例命令:
bash
SET username "chen123"
GET username
INCR counter
DECR counter
SETEX session:token 3600 "abcdefg" # 带过期时间场景举例:
- 缓存用户昵称、令牌
- 存储计数器(如访问次数)
Hash(哈希)------ 类似一个小型的对象或 Map
示例命令:
bash
HSET user:1001 name "Alice" age "25"
HGET user:1001 name
HGETALL user:1001
HINCRBY user:1001 age 1场景举例:
- 存储用户信息、商品信息等结构化数据
- 适合表示对象属性
List(列表)------ 有序、可重复元素(类似队列)
示例命令:
bash
LPUSH queue "task1"
LPUSH queue "task2"
RPOP queue # 出队
LRANGE queue 0 -1场景举例:
- 实现消息队列、任务列表
- 最近浏览记录(滚动窗口)
Set(集合)------ 无序、去重元素
示例命令:
bash
SADD tags "java" "redis" "backend"
SISMEMBER tags "java"
SMEMBERS tags
SREM tags "java"场景举例:
- 存用户兴趣标签、文章标签
- 用户去重签到等
Sorted Set(有序集合)------ 集合 + 分数(score)
示例命令:
bash
ZADD leaderboard 100 "player1"
ZADD leaderboard 200 "player2"
ZRANGE leaderboard 0 -1 WITHSCORES # 升序
ZREVRANGE leaderboard 0 1 WITHSCORES # 前2名(降序)
ZINCRBY leaderboard 50 "player1"场景举例:
- 排行榜(积分榜、点赞榜)
- 优先级队列(score 表示权重)
Bitmaps / HyperLogLog / GEO(高级场景)
- Bitmaps:用户签到、活跃状态
- HyperLogLog:高效统计去重(如 UV)
- GEO:地理位置查询,附近的人功能
❤觉得有用的可以留个关注~❤