基于Oracle ADG通过dblink创建物化视图同步数据到目标库
环境说明:源端环境Oracle ADG一主一备,版本11.2.0.4,目标端版本11.2.0.4,测试通过dblink方式在目标库创建物化视图同步ADG备库的数据。
PROD --> STANDBY -- > TARGET
第一步:在目标端创建dblink访问standby
create database link dblink_scims
connect to scims identified by "scims"
using '(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 10..0.0.0)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = orcl)))';
SELECT * FROM USER_DB_LINKS ;
SELECT * FROM tscim@dblink_scims第二步:在目标端创建物化视图,失败了,提示tscim表不带实体日志表,即物化视图日志表
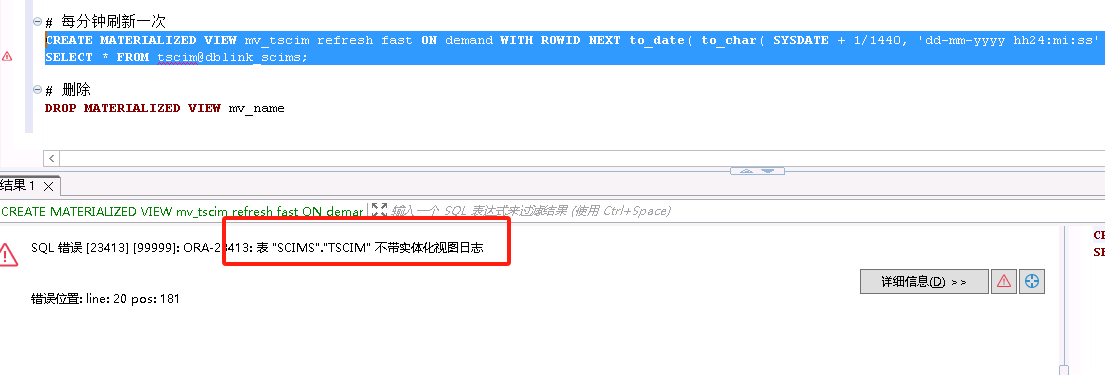
第三步:尝试给tscim添加物化视图日志表
SQL> CREATE MATERIALIZED VIEW LOG ON scims.TSCIM WITH ROWID;
实体化视图日志已创建。
SQL>第四步:再次在目标库创建物化视图,任然失败了,大概意思是不能从ADG备库创建
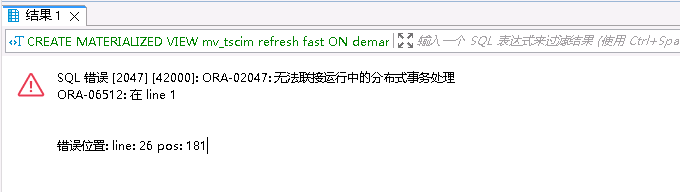
第五步:创建到ADG主库的dblink
create database link dblink_scims_prod
connect to scims identified by "scims"
using '(DESCRIPTION =(ADDRESS_LIST =(ADDRESS = (PROTOCOL = TCP)(HOST = 10.0.0.0)(PORT = 1521)))(CONNECT_DATA =(SERVICE_NAME = orcl)))';
SELECT * FROM USER_DB_LINKS ;
SELECT * FROM tscim@dblink_scims_prod;第六步:再次在目标端创建物化视图,成功创建。

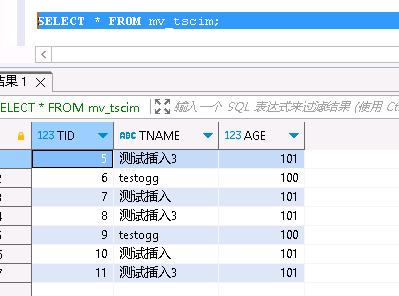
第七步:目标端查询验证数据
附:可能存在的风险,物化视图会占用实际的物理空间,如果是比较大的表需要留意存储空间以及对性能的影响。