实验环境:已经部署好的Hadoop环境 Hadoop安装、配置与管理_centos hadoop安装-CSDN博客
实验目的:对输入文件统计单词频率
实验过程:
1、准备文件
test.txt文件,它是你需要准备的原始数据文件,存放在你的 Linux 系统(运行 Hadoop 命令的机器)本地磁盘上的某个位置。文件内容可以是任意文本数据,比如一些段落、句子、单词等,以便进行词频统计(wordcount)等操作。(里面可以随便复制一些相同的单词,可以进行文件内容查重统计)
新建一个测试数据文件test.txt ,上传到Linux虚拟机的/sample/test.txt目录(若没有目录则创建一个)

2、启动 Hadoop 服务
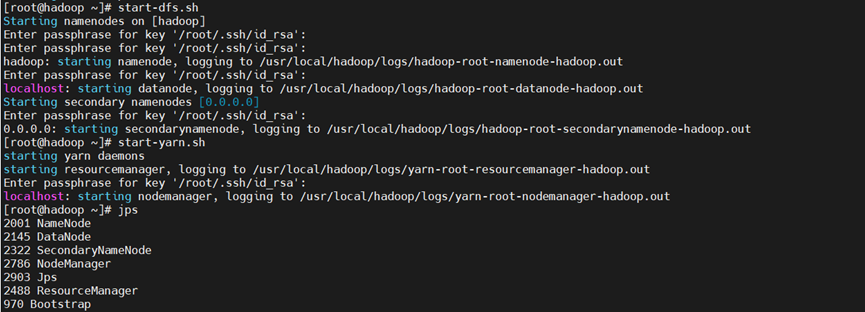
3、上传数据到 HDFS
在HDFS上创建目录,并将待处理的数据文件上传到该目录:
hdfs dfs -mkdir -p /sample/input
hdfs dfs -mkdir -p /sample/output
hdfs dfs -put /sample/test.txt /sample/input //将txt文件保存在/sample/input目录里

4、进行测试
先查找Hadoop-mapreduce-examples-2.7.3.jar解压包的位置
find / -name "hadoop-mapreduce-examples-2.7.3.jar"
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /sample/input/test.txt /sample/test-result

/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar //解压包的位置
/sample/input/test.txt //txt在hdfs里面的位置
/sample/test-result //文件查重之后生成文件所放的目录
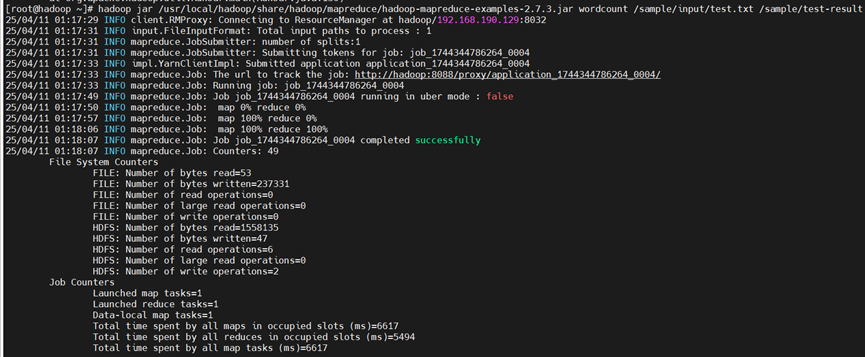
5、结果验证
查找以 part- 开头的结果文件: hdfs dfs -ls /sample/test-result

使用命令查看文件得到单词的词频统计结果:
hdfs dfs -cat /sample/test-result/part-r-00000
 每行的格式是 "单词 词频",中间以制表符分隔。这个结果是 MapReduce 作业成功执行后,对输入文本中单词出现次数的统计汇总。
每行的格式是 "单词 词频",中间以制表符分隔。这个结果是 MapReduce 作业成功执行后,对输入文本中单词出现次数的统计汇总。