中间接手一台服务器,应客户要求部署DeepSeek-r1:32B,服务器是一台公司定制的,里面安装了四张英伟达的T4卡,好在开机后发现已经安装了CentOS7.9,并且也已经安装了英伟达的显卡驱动,能省不少事情。
网络环境准备简单,因为在内网里面,配置网卡 BOOTPROTO="dhcp",先采用客户内网地址能直接访问互联网即可。
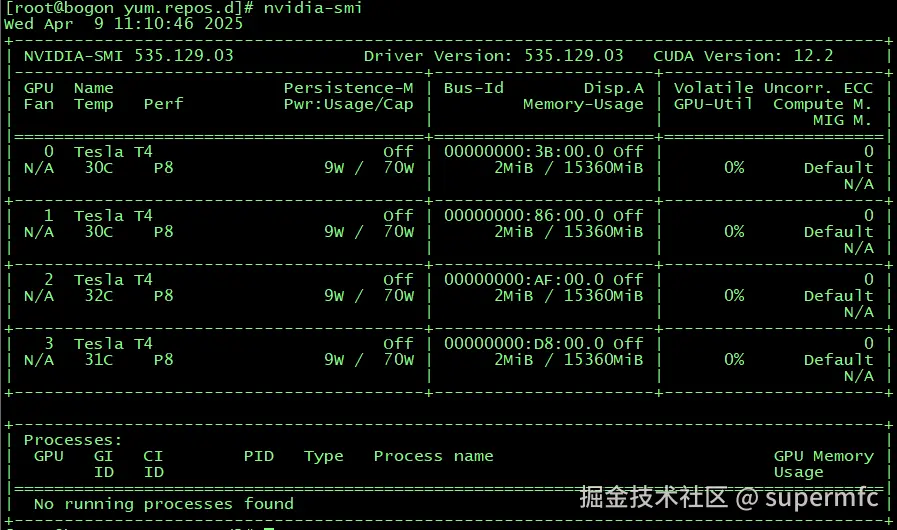
配置GPU驱动内存常驻模式使得GPU驱动模式设置为常驻内存: nvidia-smi -pm 1
安装CUDA
到英伟达网站的CUDA专区,选择自己的OS和版本:

下面有下载链接:
wget https://developer.download.nvidia.com/compute/cuda/12.2.0/local_installers/cuda_12.2.0_535.54.03_linux.run
粘贴到shell窗口,下载即可完成。
然后使用sh cuda_12.2.0_535.54.03_linux.run进行安装,由于已经安装了T4卡的驱动,在组件选择页面取消安装驱动前的X。
安装完毕后提示需要修改PATH环境变量:

可以修改/etc/profile文件,或者在/etc/profile.d/下面新建一个cudu.sh,内容如下:
bash
export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:$LD_LIBRARY_PATH
PATH=/usr/local/cuda-12.2/bin:$PATH
export PATH然后source /etc/profile
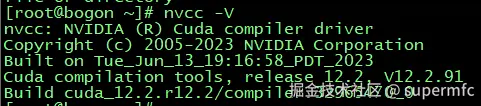
执行nvcc -V进行验证:
PS:如果想卸载CUDA Toolkit, 执行 /usr/local/cuda-12.2/bin 下的cuda-uninstaller即可。
安装cuDNN
安装Ollama
采用了官网的一键脚本 curl -fsSL https://ollama.com/install.sh | sh 后来发现1.6G的下载文件,居然要10多个小时,停掉,采用镜像加速:
到xiake.pro/ ,将ollama最新release版本的github地址github.com/ollama/olla... 粘贴进去:
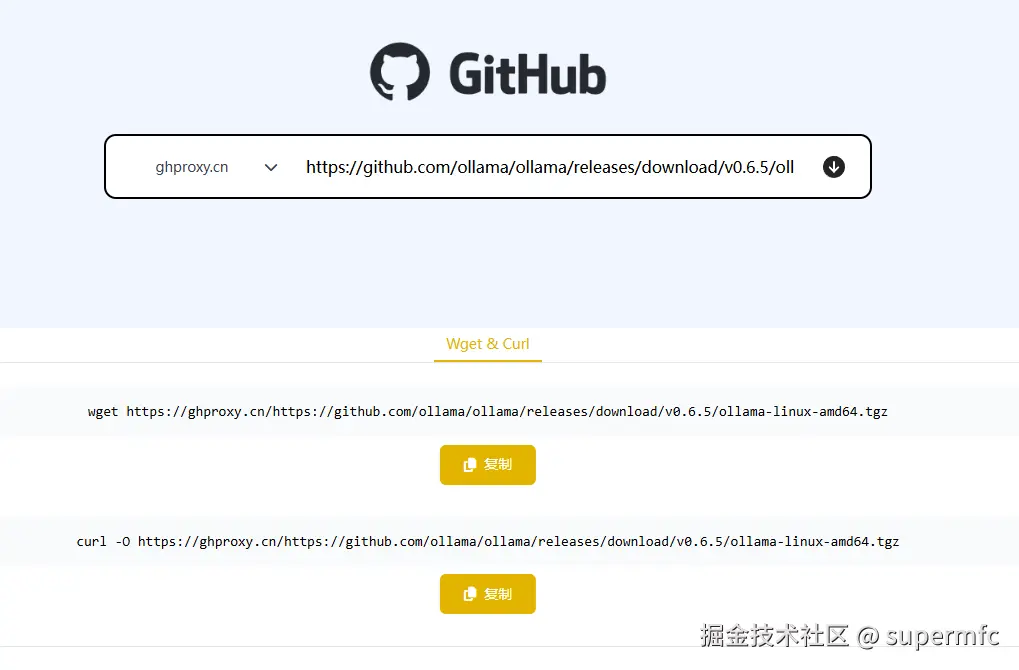
直接复制wget方式生成的命令,进行下载,如果觉得速度不行,可以在粘贴框前面切换不同的加速源,这里选择了ghproxy.cn。测试一下,挑选一个速度快的。
网上看到很多需要自己下载后再解压,并且创建用户组、修改启动文件等,比较繁琐,这里还是利用ollama官网提供的脚本。
bash
export OLLAMA_MIRROR="https://ghproxy.cn/https://github.com/ollama/ollama/releases/latest/download"
curl -fsSL https://ollama.com/install.sh | sed "s|https://ollama.com/download|$OLLAMA_MIRROR|g" | sh原理也很简单,先导出环境变量OLLAMA_MIRROR,设置成我们第一步生成的地址(部分),然后将脚本通过sed将原始地址全局替换成我们的地址后进行下载再安装,最简单的办法。

安装后执行ollama serve 居然提示错误:/lib64/libm.so.6: version 'GLIBC_2.27' not found 使用ldd --version 提示 libc库是2.17版本的,看来最新的ollama(0.6.5)需要glibc库至少是2.27。网上看了一下升级有些风险,最终采取了降级部署的方式:
bash
export OLLAMA_MIRROR="https://ghproxy.cn/https://github.com/ollama/ollama/releases/download/v0.5.12"
curl -fsSL https://ollama.com/install.sh | sed "s|https://ollama.com/download|$OLLAMA_MIRROR|g" | OLLAMA_VERSION=0.5.12 sh测试正常后,修改监听端口,将默认的11434修改成其它端口,并添加防火墙允许端口。 修改默认端口后,使用ollama命令会提示无法连接app,这是环境变量的原因,需要修改~/.bash_profile文件,在最后添加一行:
export OLLAMA_HOST="0.0.0.0:xxxx"
source ~/.bash_profile 以后登录即可正常。
一些配置:
ini
Environment="CUDA_VISIBLE_DEVICES=0,1,2,3" 代表让ollama能识别到第几张显卡,因为4张显卡,从0开始编号,所以为0,1,2,3
Environment="OLLAMA_SCHED_SPREAD=1" #这几张卡均衡使用
Environment="OLLAMA_KEEP_ALIVE=-1" #模型一直加载, 不自动卸载
Environment="OLLAMA_MODELS=/xxxx/ollama/models" #模型保存目录
Environment="OLLAMA_HOST=0.0.0.0:xxxx" #监听地址firewall-cmd --add-port=xxxx/tcp --permanent
安装docker compose
bash
curl -L "https://github.com/docker/compose/releases/download/v2.34.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose添加执行权限:
chmod +x /usr/local/bin/docker-compose
验证:
docker-compose --version
安装Dify
先到目标文件夹:git clone https://github.com/langgenius/dify.git 克隆下来dify仓库。
切换到docker目录,cp .env.example .env ,然后 vi .env,修改里面的文件大小限制、暴露端口号等配置信息。
然后启动容器 docker-compose up -d
依然这一步拉取速度超慢,需要通过国内镜像进行加速。
正常启动后,通过端口号即可访问dify。