单层感知机,是一种最简单的人工神经网络
输入层input layer,输入的样本特征
输出层output layer,输出的预测结果
权值W=(w0,w1,w2,...,wn)^T,感知机的权值参数,其中的w0叫做偏置,也称截距,类似逻辑回归决策函数中的b
激活函数
多层感知机是基于单层感知机之上加入隐藏层。隐藏层的层数是任意的,每一层人工神经元的个数也任意。
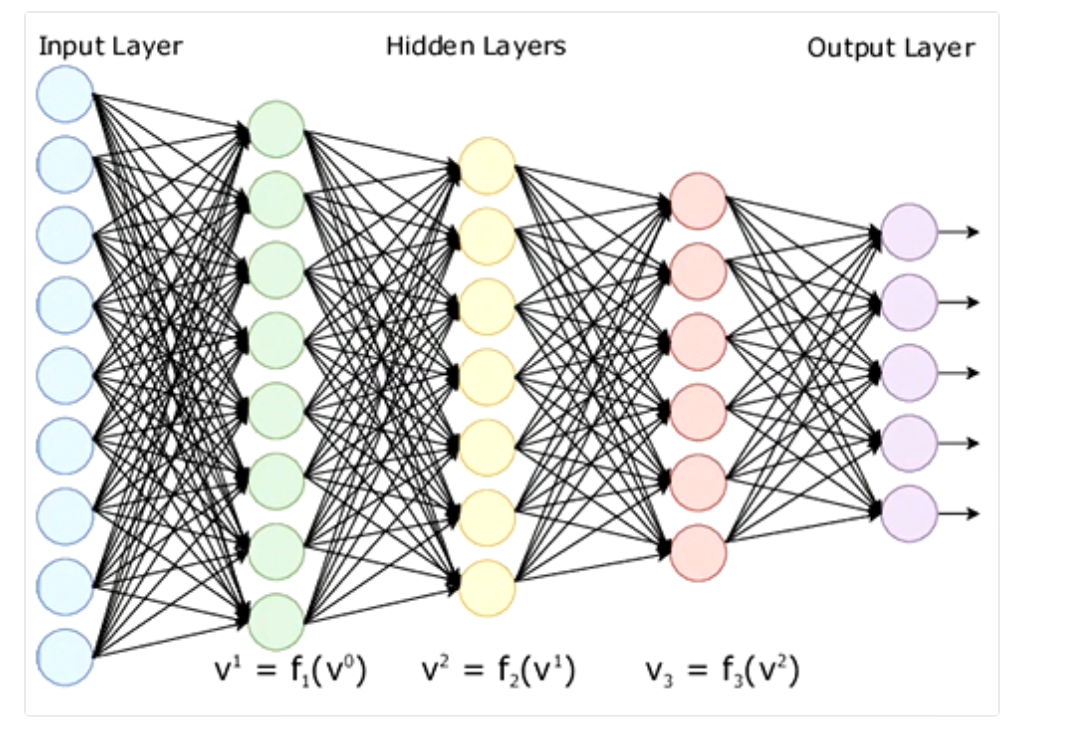
多层感知机中,每一个节点与下一个节点都有连接,这样的神经网络称为全连接神经网络full connected neural network
基于多层感知机构造的神经网络中,神经元的层数是不唯一的
由输入层向隐藏层最终到达输出层获得输出结果的过程,将其称作前向传播、前向计算,forward,即按照神经网络的决策函数:
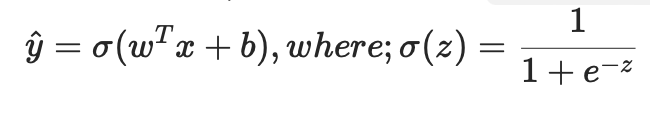
由输入特征x参与上式计算后得到yhat的过程。
神经网络模型的优化过程是基于决策函数给出模型的损失函数,并使用梯度下降法对损失函数做极小化,伴随迭代梯度下降过程不断对目标权重(参数)进行优化,最终求得权重的最优解,这个过程称为反向传播,backword。
损失函数描述的是预测结果与真实结果的偏离程度
需要先经过前向计算得到预测结果,再反向由预测结果与真实结果的偏离程度构建损失函数
使用梯度下降法完成极小化,最终求解权重的最优解
即对损失函数反向链式求导的过程
反向链式求导,求梯度就是求一个向量,这个向量的模长就是方向导数的最大值,求解方向导数只需能够求解出对所有自变量的偏导数再结合方向即可,所以求梯度回归本质就是求偏导
所以就是反向传播
多层感知机所构成的神经网络,其模型的求解思路是固定的,无论感知机构成的是何种网络,CNN,RNN,生成式GAN网络、Transformer。。。都遵循基本通用思路
CNN
RNN
生成式GAN
Transformer
确定网络的决策函数,需先确定网络的结构
依据决策函数完成前向计算,获得输出结果,即预测结果
依据前向计算过程得到的预测结果给出损失函数
完成反向传播,根据梯度下降法对损失函数极小化,优化更新模型的权重,获得最优解
网络的训练过程即复杂的调参过程
参数训练前需要合理的初始化
参数训练中需确保想着最优解的方向进行优化
参数训练完毕要能够获得最优解
调参。。。前路漫漫又灿灿
仅用于本人学习
来源:网络