目录
- 前记
- LangChain 是什么?
- 模型层(Models)
- 提示层(Prompts)
- 链层(Chains)
前记
本系列分为以下四篇,本篇为本系列的第一篇
- LangChain 核心组件基础篇
- LangChain 核心组件进阶篇
- 基于LangChain的 AI Agent 开发
- 基于LangChain的 MCP 开发
本篇目标: 掌握 LangChain 的核心概念和最常用的基础模块,能够构建简单的 LLM 应用。
- LangChain 核心概念与架构:
- LangChain 是什么? 它解决了哪些传统 LLM 开发的缺点?
- 模块概览:
Models(LLMs/Chat Models),Prompts,Chains,Data Connection(Retrieval),Memory,Agents,Callbacks。 - *LangChain* 的优势: 模块化、可组合性、统一接口。
- 模型层(Models):
- 封装器:
langchain_openai.OpenAI、langchain.chat_models.init_chat_model - 同步与异步调用:理解
invoke()与ainvoke()。 - 模型参数配置:在 LangChain 中设置
temperature,max_tokens等。
- 封装器:
- 提示层(Prompts):
- PromptTemplate: 定义通用文本提示模板,使用占位符。
- ChatPromptTemplate: 专为聊天模型设计,包含系统、用户、助手消息。
- 输出解析器(Output Parsers):将 LLM 的自由文本输出结构化。
- 链层(Chains):
- LangChain Expression Language (LCEL)
- 顺序链
- 多输入输出:
RunnableParallel - 路由链:
RunnableBranch - 记忆(Memory)
- 缓存(Caching)
一、LangChain 是什么?
LangChain 是一个用于构建大语言模型(LLM)应用的框架。它的核心目标是简化开发流程,通过模块化设计,让开发者可以将不同组件(如模型、提示模板、数据检索、记忆、工具代理等)灵活组合,快速构建强大的 LLM 应用。它解决了传统 LLM 开发中的几个关键痛点:
- 单独使用 LLM API 难以处理复杂工作流
- 不同 LLM 接口不统一,切换成本高
- 难以实现记忆、外部数据连接等高级功能
- 缺乏标准化的组件组合方式
LangChain的核心优势是模块化 和可组合性,通过统一接口将不同功能封装为可拼接的组件,主要包括:
| 模块名 | 作用 |
|---|---|
models |
封装各种 LLM 或聊天模型(如 ChatOpenAI) |
prompts |
提示模板组件 |
chains |
链式调用组件 |
memory |
对话记忆模块 |
retrievers |
检索模块,如向量数据库 |
agents |
智能体 Agent 系统 |
tools |
可由 Agent 调用的工具 |
output_parsers |
将 LLM 输出结构化 |
callbacks |
跟踪执行细节,用于调试或日志记录 |

二、模型层(Models)
模型参数
| 参数 | 作用 | 推荐场景 |
|---|---|---|
temperature |
控制采样随机度。0.0 趋于确定性,1.0 趋于多样性 | 精确回答:0--0.3;创意生成:0.7 |
max_tokens |
最大生成长度(token 数),超过会截断 | 简短回答:256;长文:1024+ |
frequency_penalty |
对重复 token 施加惩罚,减少冗余输出 | 文本去重 |
presence_penalty |
鼓励引入新话题,避免「原地打转」 | 回答多样性 |
model |
模型名称,支持 "deepseek-chat"、"deepseek-instruct" 等 |
视任务场景选择 |
ainvoke异步
LangChain 提供了同步和异步两种调用模型的方式:
-
invoke(): 用于同步调用模型。当您只需要单次调用,或者在脚本中按顺序执行时,可以使用此方法。 -
ainvoke(): 用于异步调用模型。当您需要并发执行多个模型请求(例如,同时处理多个用户查询)时,ainvoke()结合asyncio可以显著提高效率,避免阻塞。import os
import timefrom dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain.prompts import ChatPromptTemplate1. 加载 .env 中的环境变量
load_dotenv()
api_key = os.getenv("DEEPSEEK_API_KEY")
api_base = os.getenv("DEEPSEEK_API_BASE")
ifnot api_key ornot api_base:
raise EnvironmentError("请在 .env 中设置 DEEPSEEK_API_KEY 和 DEEPSEEK_API_BASE")2. 定义 Prompt 模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一位乐于助人的 AI 助手。"),
("human", "{input}")
])3. 初始化 DeepSeek 聊天模型
chat_model = init_chat_model(
model="deepseek-chat",
temperature=0.6, # 随机性:0.0(最确定)--1.0(最随机)
max_tokens=512, # 最多返回多少 token
api_key=api_key,
api_base=api_base
)4. 链式组合:Prompt → ChatModel
pipeline = prompt | chat_model
5. 同步调用
def main():
question = "请用一句话解释什么是 LangChain?"
answer = pipeline.invoke({"input": question})
print("Q:", question)
print("A:", answer)
if name == "main":
main()
import asyncio
asyncdef ask(q):
returnawait pipeline.ainvoke({"input": q})asyncdef batch_questions():
a1=time.time()
qs = [
"LangChain 是什么?",
"如何配置模型参数?",
"LangChain 有哪些核心模块?"
]
# 并发执行
results = await asyncio.gather(*(ask(q) for q in qs))
for q, r in zip(qs, results):
print(f"Q: {q}\nA: {r}\n")
a2=time.time()
print(a2-a1)#22.283571004867554if name == "main":
asyncio.run(batch_questions())
三、提示层(Prompts)
PromptTemplate
import os
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain.prompts import PromptTemplate
# 1. 加载环境变量
load_dotenv()
API_KEY = os.getenv("DEEPSEEK_API_KEY")
API_BASE = os.getenv("DEEPSEEK_API_BASE")
assert API_KEY and API_BASE, "请配置 .env 中的 DEEPSEEK_API_KEY / DEEPSEEK_API_BASE"
# 2. 定义模板
template = PromptTemplate(
template="将下面这句话翻译成中文:\n\n{text}",
input_variables=["text"]
)
# 3. 初始化 instruct 模型
llm = init_chat_model(
model="deepseek-chat",
temperature=0.6, # 随机性:0.0(最确定)--1.0(最随机)
max_tokens=512, # 最多返回多少 token
)
# 4. 合成管道
pipeline = template | llm
# 5. 调用
result = pipeline.invoke({"text": "Hello, how are you?"})
print("翻译结果:", result)ChatPromptTemplate
对话式场景,模型具有 system/user/assistant 三角色概念。
import os
from dotenv import load_dotenv
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import init_chat_model
from langchain_core.output_parsers import StrOutputParser
# 1. 环境加载
load_dotenv()
API_KEY = os.getenv("DEEPSEEK_API_KEY")
API_BASE = os.getenv("DEEPSEEK_API_BASE")
# 2. 定义 ChatPromptTemplate
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是一位专业的翻译助理。"),
("human", "请将以下英语翻译成中文:\n\n{sentence}")
])
# 3. 初始化聊天模型
chat_model = init_chat_model(
model="deepseek-chat",
temperature=0.2,
max_tokens=512,
api_key=API_KEY,
api_base=API_BASE
)
# 4. 组装管道
chat_pipeline = chat_prompt | chat_model |StrOutputParser()
# 5. 同步调用
out = chat_pipeline.invoke({"sentence": "LangChain is awesome!"})
print("翻译成中文:", out)OutputParser
| 解析器名称 | 简要描述 | 典型应用场景 | 示例模型输出 | 解析后结果类型 |
|---|---|---|---|---|
StrOutputParser |
最基础的解析器,直接提取 LLM 响应的原始字符串内容。 | 默认解析器,当不需要任何结构化时。 | "地球是一个蓝色的星球。" | str |
JsonOutputParser |
将 LLM 响应解析为 JSON 格式的 Python 字典或 Pydantic 对象。 | 需要从 LLM 获取结构化数据(如用户资料、产品属性、复杂指令)。 | {"name": "Alice", "age": 30} |
dict 或 Pydantic 对象 |
CommaSeparatedListOutputParser |
将 LLM 响应解析为逗号分隔的列表。 | 从 LLM 获取一个项目列表,如商品名称、关键词、建议。 | "苹果,香蕉,橙子" | list |
BooleanOutputParser |
将 LLM 响应解析为 Python 的 布尔值 (True 或 False)。 |
需要 LLM 进行二元判断,如"是/否"、"真/假"、"同意/不同意"。 | "是" 或 "True" 或 "否" 或 "False" | bool |
DatetimeOutputParser |
将 LLM 响应解析为 Python 的 日期时间对象 (datetime)。 |
需要 LLM 抽取或生成特定日期或时间点。 | "2023-10-26" 或 "明天下午三点" | datetime |
EnumOutputParser |
将 LLM 响应解析为预定义的 枚举值。 | 限制 LLM 输出为特定选项之一,如颜色、状态、严重程度。 | "RED" 或 "high" (对应枚举类中的成员) | Enum 成员 |
四、链层(Chains)
LangChain Expression Language (LCEL)
CEL(LangChain Expression Language)是 LangChain 提供的声明式语法,用于以管道形式(|)组合 Prompt、LLM、工具、解析器等组件,构建复杂链式逻辑。其链式逻辑用 | 连接,代码更清晰;且组件可自由组合,易于扩展。
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
load_dotenv()
# 1. 初始化 DeepSeek 模型
model = init_chat_model(
model="deepseek-chat",
temperature=0.7
)
# 第一步:生成描述
prompt1 = PromptTemplate.from_template("详细描述 {topic} 的用途。")
# 第二步:总结
prompt2 = PromptTemplate.from_template("总结以下内容为一句话:{description}")
# 创建顺序链
chain = (
{"description": prompt1 | model | StrOutputParser()}
| prompt2
| model
| StrOutputParser()
)
# 运行
result = chain.invoke({"topic": "云计算"})
print(result)多输入输出
from langchain_core.runnables import RunnableParallel
# 定义两个并行链
chain1 = PromptTemplate.from_template("介绍 {topic}") | llm | StrOutputParser()
chain2 = PromptTemplate.from_template("列出 {topic} 的应用") | llm | StrOutputParser()
# 并行运行
parallel_chain = RunnableParallel(intro=chain1, applications=chain2)
# 运行
result = parallel_chain.invoke({"topic": "人工智能"})
print(result) # 输出:{"intro": "...", "applications": "..."}路由链
import time
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.runnables import RunnableBranch, RunnablePassthrough
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
load_dotenv()
# 1. 初始化 DeepSeek 模型
llm = init_chat_model(
model="deepseek-chat",
temperature=0.7
)
# 定义分支提示
technical_prompt = PromptTemplate.from_template("回答技术问题:{question}")
general_prompt = PromptTemplate.from_template("回答一般问题:{question}")
# 定义路由逻辑
router_prompt = PromptTemplate.from_template(
"如果是技术问题,返回 'technical',否则返回 'general':{question}"
)
router_chain = router_prompt | llm | StrOutputParser()
# 定义分支
branch = RunnableBranch(
(lambda x: "technical"in x["route"].lower(), technical_prompt | llm | StrOutputParser()),
(lambda x: "general"in x["route"].lower(), general_prompt | llm | StrOutputParser()),
general_prompt | llm | StrOutputParser() # 默认分支
)
# 组合链
chain = {
"question": RunnablePassthrough(),
"route": router_chain
} | branch
# 运行
result = chain.invoke({"question": "如何优化 Python 代码?"})
print(result)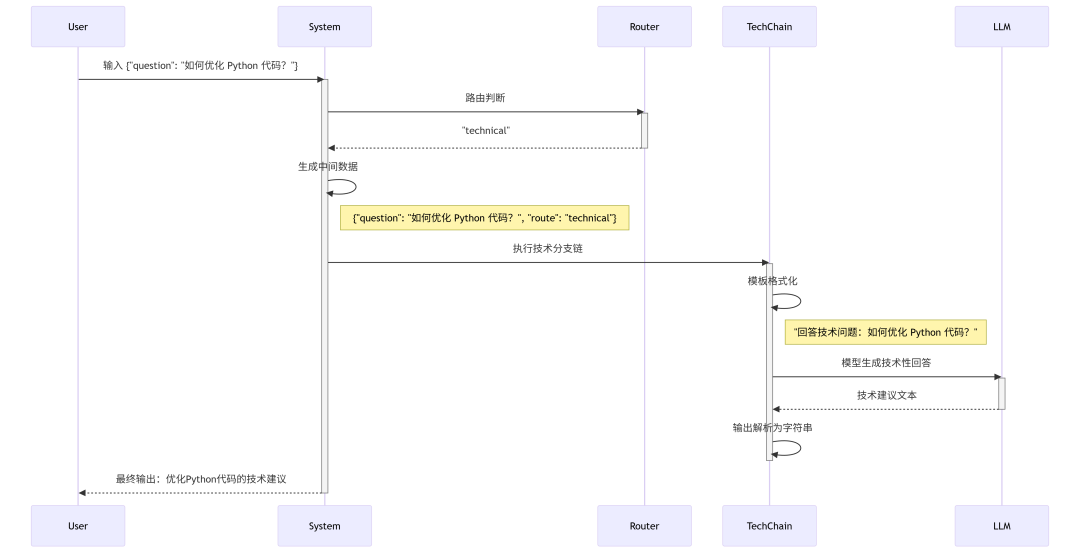
输入处理:
RunnablePassthrough():直接传递原始问题router_chain:生成路由结果
步骤如下:
-
输入:
{"question": "如何优化 Python 代码?"} -
路由链判断:输出应为"technical"
-
生成中间数据:
{ "question": "如何优化 Python 代码?", "route": "technical" } -
分支选择:匹配第一个条件,执行技术分支链
-
技术链处理:
- 模板格式化 → "回答技术问题:如何优化 Python 代码?"
- 模型生成技术性回答
- 输出解析为字符串
-
最终输出:优化Python代码的技术建议
Memory
import time
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
load_dotenv()
# 1. 初始化 DeepSeek 模型
llm = init_chat_model(
model="deepseek-chat",
temperature=0.7
)
# 模拟会话存储
store = {}
def get_session_history(session_id: str):
if session_id notin store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 定义提示
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个助手"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}")
])
# 创建链
chain = prompt | llm | StrOutputParser()
# 添加记忆
chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="history"
)
# 运行
config = {"configurable": {"session_id": "user1"}}
config2 = {"configurable": {"session_id": "user2"}}
print(chain_with_history.invoke({"input": "你好,我是季灾"}, config))
print(chain_with_history.invoke({"input": "我刚才说了什么?"}, config))
print(chain_with_history.invoke({"input": "我的名字叫什么?"}, config2))
print(chain_with_history.invoke({"input": "我的名字叫什么?"}, config))Caching
import time
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.globals import set_llm_cache
from langchain_core.caches import InMemoryCache
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
load_dotenv()
# 1. 初始化 DeepSeek 模型
llm = init_chat_model(
model="deepseek-chat",
temperature=0.7
)
# 开启缓存
set_llm_cache(InMemoryCache())
# 定义链
prompt = PromptTemplate.from_template("简单用一句话介绍 {topic}")
chain = prompt | llm | StrOutputParser()
# 运行(第一次调用 API)
print(chain.invoke({"topic": "区块链"}))
print("第二次")
# 运行(从缓存读取)
print(chain.invoke({"topic": "区块链"}))普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云 合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现"AI+行业"跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要) 

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中...
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发