目录
[1 JournalNode的角色定位](#1 JournalNode的角色定位)
[2 核心职责详解](#2 核心职责详解)
[2.1 主要功能](#2.1 主要功能)
[2.2 与各组件交互关系](#2.2 与各组件交互关系)
[3 JournalNode集群工作原理](#3 JournalNode集群工作原理)
[3.1 Quorum写入机制](#3.1 Quorum写入机制)
[3.2 数据同步流程](#3.2 数据同步流程)
[4 JournalNode内部架构](#4 JournalNode内部架构)
[4.1 核心模块组成](#4.1 核心模块组成)
[4.2 文件存储结构](#4.2 文件存储结构)
[5 配置指南](#5 配置指南)
[5.1 关键配置参数](#5.1 关键配置参数)
[5.2 部署建议](#5.2 部署建议)
[6 故障处理与监控](#6 故障处理与监控)
[6.1 常见问题排查](#6.1 常见问题排查)
[6.2 关键监控指标](#6.2 关键监控指标)
[7 与ZooKeeper的协同工作](#7 与ZooKeeper的协同工作)
[8 总结](#8 总结)
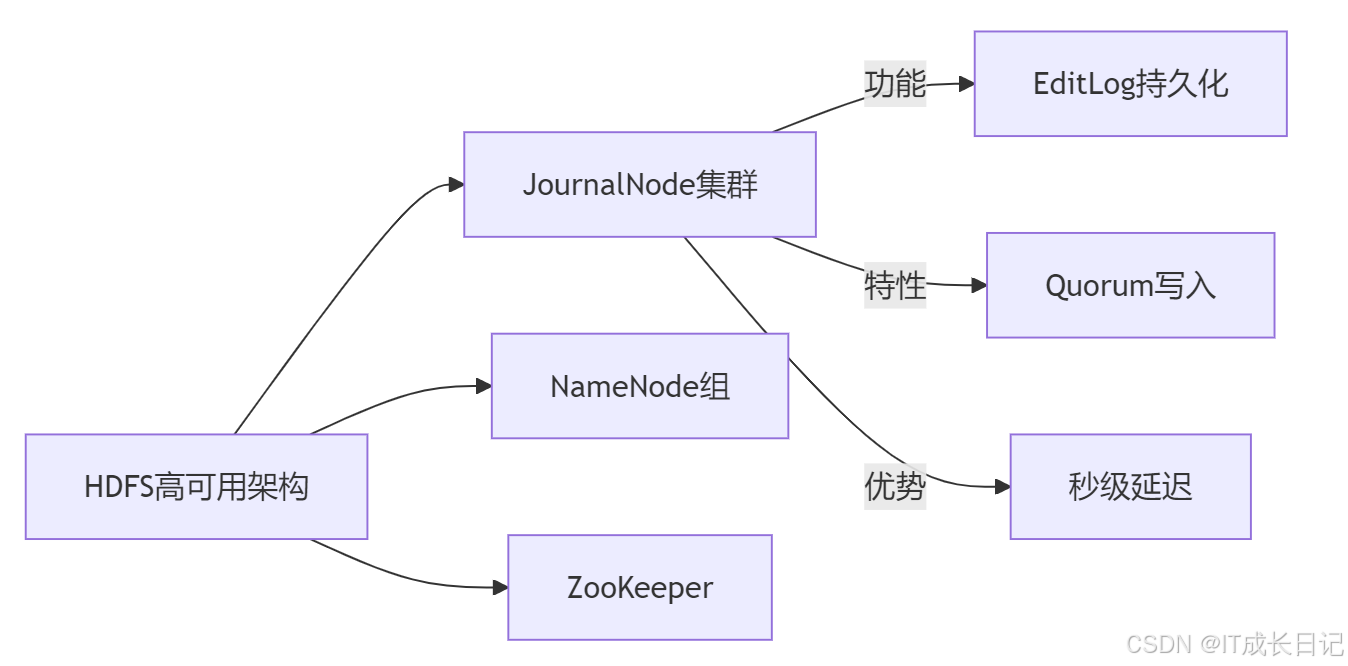
1 JournalNode的角色定位
JournalNode是HDFS高可用(HA)架构中的核心组件,承担着共享编辑日志存储的关键职责。在HA模式下,JournalNode是HDFS高可用(HA)架构中的关键组件,负责共享EditLog的存储与同步,确保Active和Standby NameNode之间的元数据一致性。
- **核心功能:**作为分布式日志存储节点,JournalNode集群为NameNode提供高可用的EditLog写入服务。
- **类比:**可将JournalNode视为"分布式日志账本",所有NameNode的元数据修改记录(EditLog)都会被写入该账本,供Standby NameNode实时同步。
2 核心职责详解
2.1 主要功能
- 共享编辑日志存储:集中管理所有命名空间修改记录
- 元数据变更传播:确保Active/Standby NameNode状态一致
- 故障恢复基础:提供完整的操作日志用于数据重建
2.2 与各组件交互关系
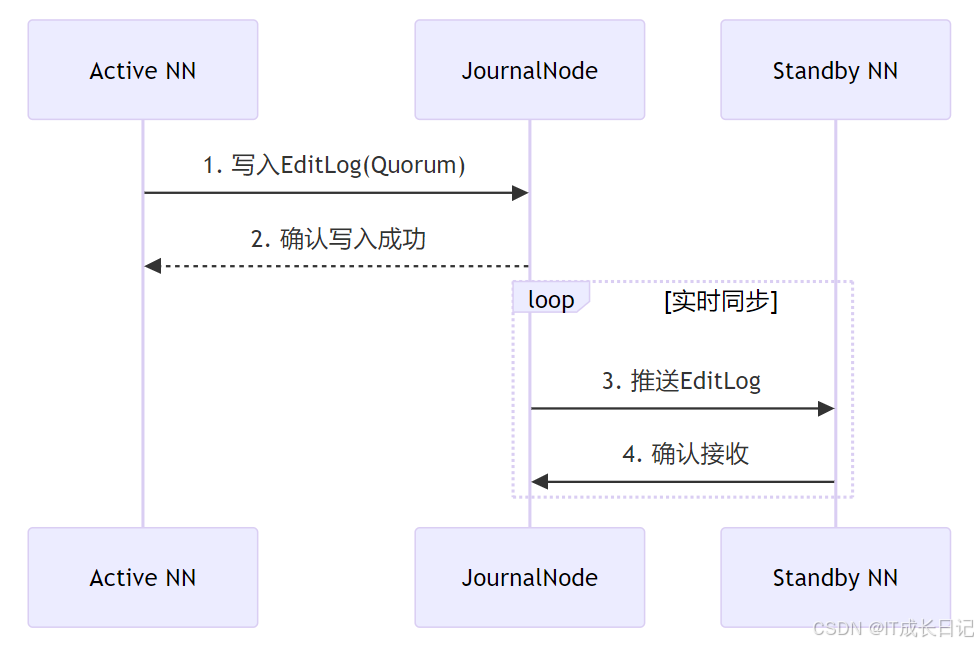
3 JournalNode集群工作原理
3.1 Quorum写入机制
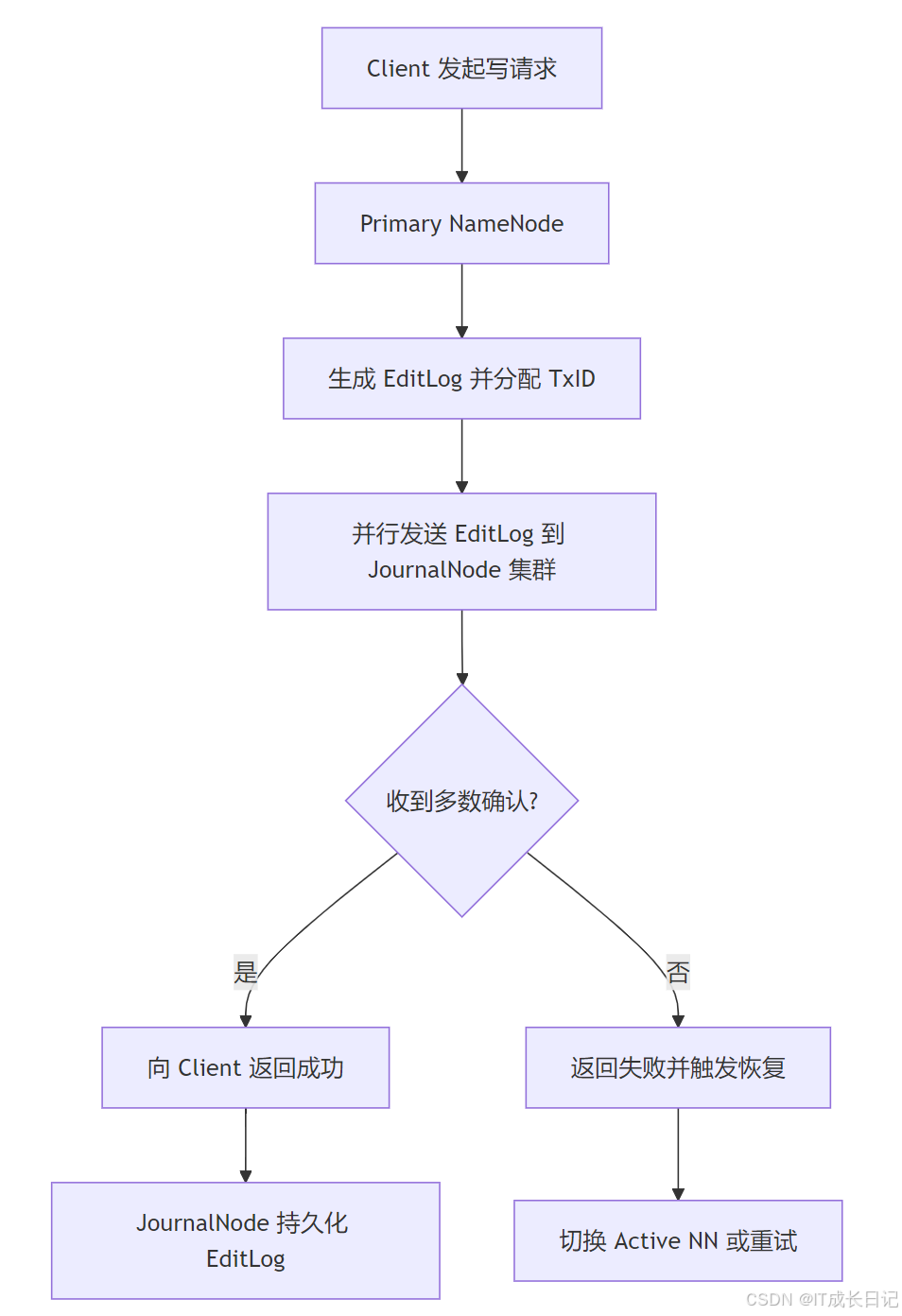
- 最少节点数:必须配置奇数个JournalNode(通常3或5个)
- 写入规则:需要(N/2 +1)个节点确认才算成功
- 容错能力:可容忍(N-1)/2个节点故障
3.2 数据同步流程

4 JournalNode内部架构
4.1 核心模块组成
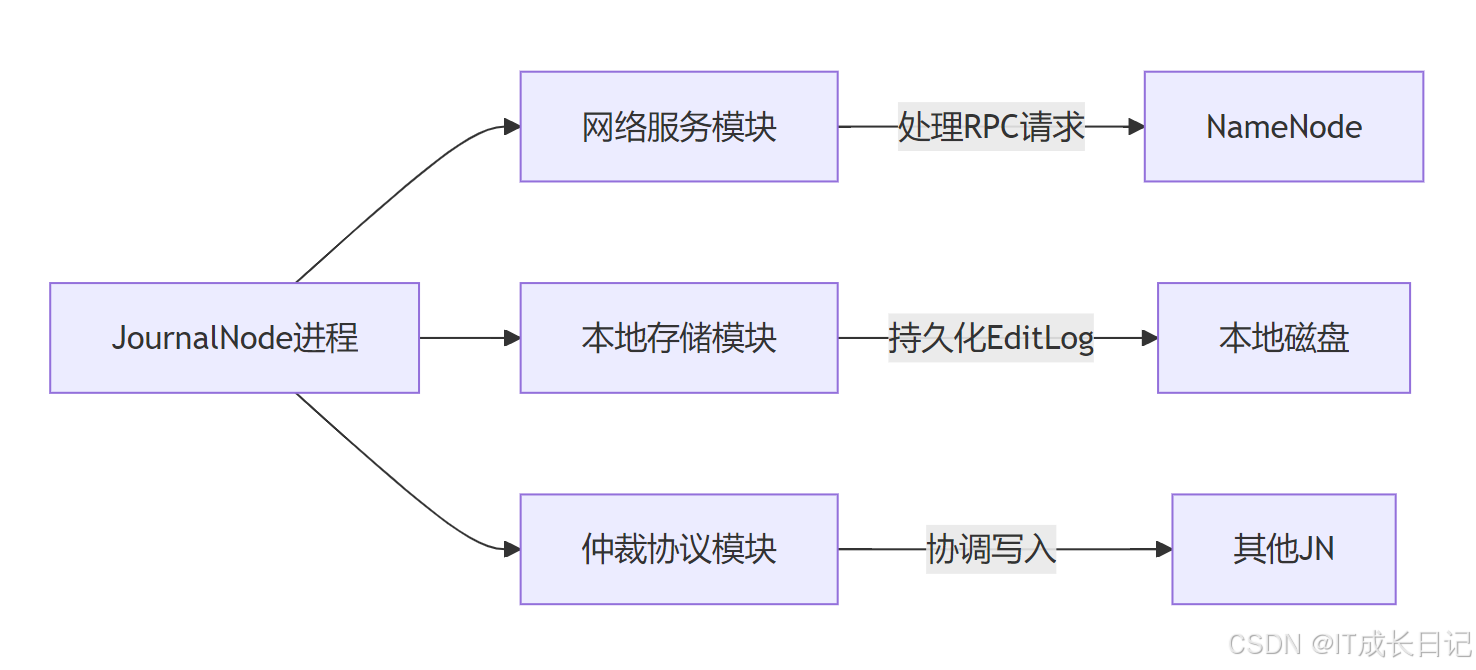
4.2 文件存储结构
${dfs.journalnode.edits.dir}/
└── current/
├── edits_0000000000000000001-0000000000000000002
├── edits_0000000000000000003-0000000000000000004
└── VERSION5 配置指南
5.1 关键配置参数
<!-- hdfs-site.xml -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hdfs/journal</value> <!-- 建议独立磁盘 -->
</property>
<property>
<name>dfs.qjournal.write-txns.timeout.ms</name>
<value>20000</value> <!-- 写入超时20秒 -->
</property>
<property>
<name>dfs.qjournal.select-input-streams.timeout.ms</name>
<value>30000</value> <!-- 读取超时30秒 -->
</property>5.2 部署建议
|--------|---------------|------------|
| 要素 | 推荐方案 | 说明 |
| 节点数量 | 3或5个 | 满足Quorum要求 |
| 硬件配置 | 独立服务器,SSD存储 | 避免资源竞争 |
| 网络要求 | 低延迟(小于1ms)高带宽 | 保障同步性能 |
| 位置分布 | 跨机架/可用区部署 | 提高容灾能力 |
6 故障处理与监控
6.1 常见问题排查
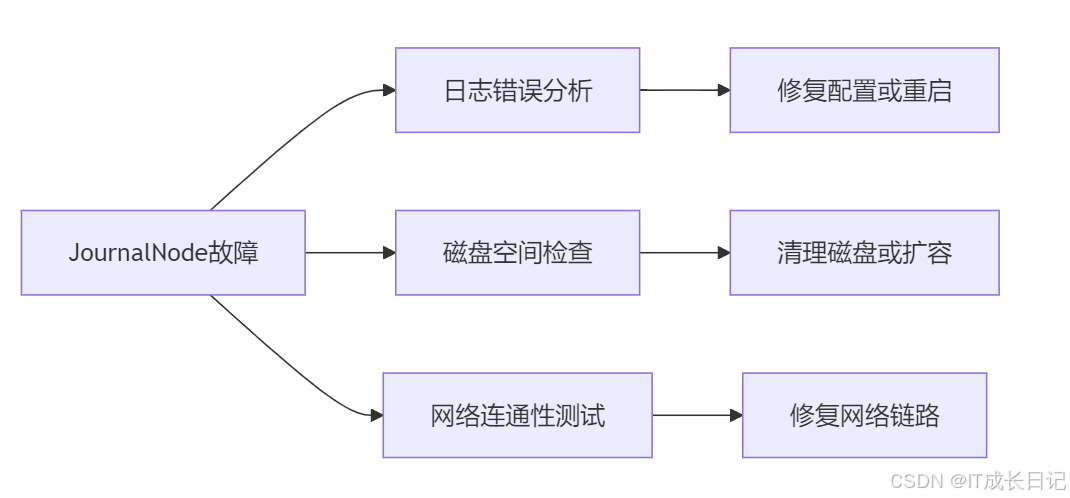
6.2 关键监控指标
# 检查JournalNode状态 \
hdfs haadmin -getJournalState <nameservice>
# 查看同步延迟
hdfs dfsadmin -fetchImage7 与ZooKeeper的协同工作
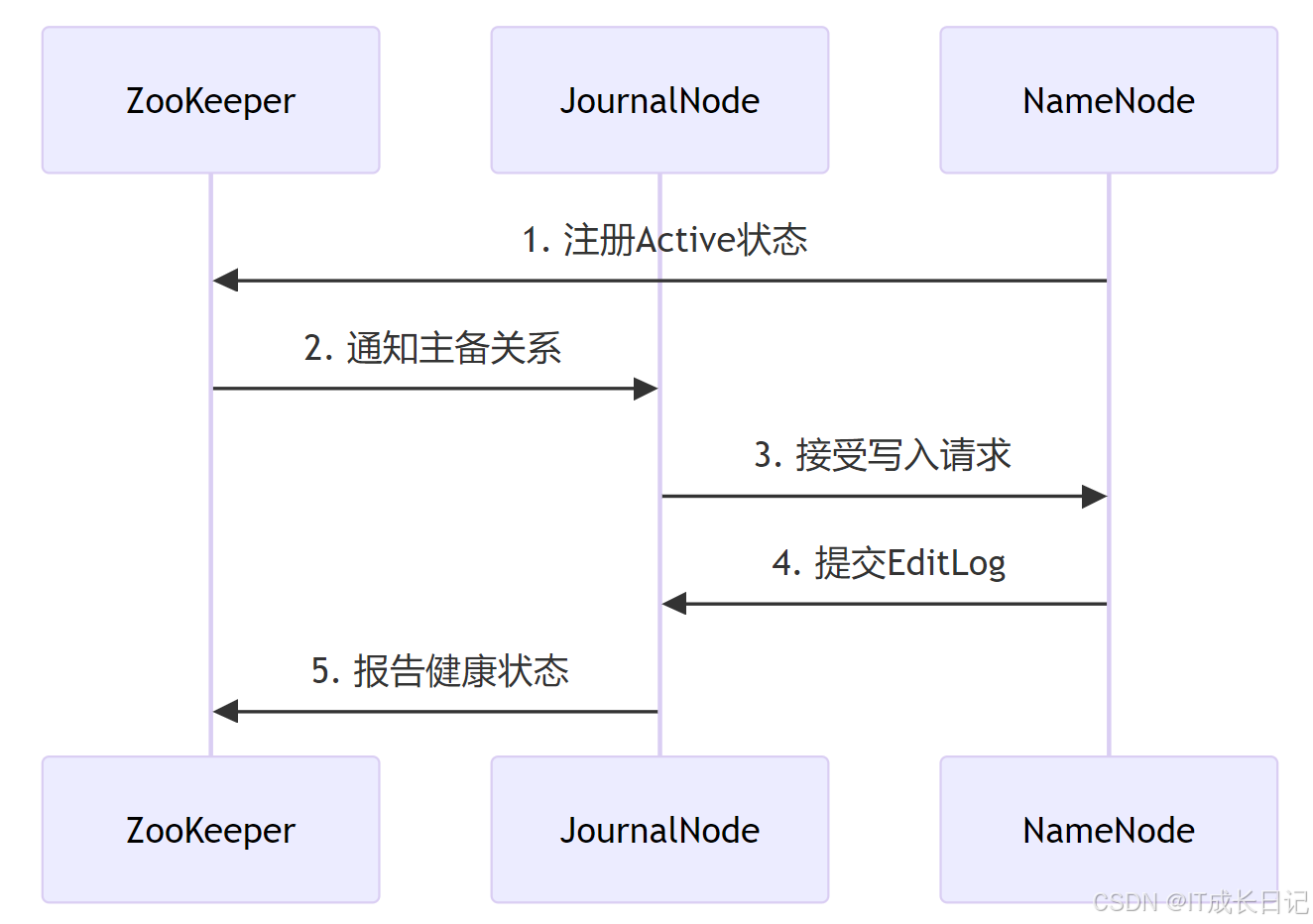
8 总结
JournalNode作为HDFS HA架构的中枢神经系统,其稳定运行直接关系到整个集群的可用性。理解其工作原理和运维要点,是保障生产环境HDFS高可用的关键所在。