( 一 ) hadoop 客户端环境 准备
hadoop集群我们配置好了,要与它进行交互,我们还需要准备hadoop的客户端。要分成两步:下载hadoop包、配置环境变量。
-
找到资料包路径下的Windows依赖文件夹,拷贝hadoop-3.1.0到非中文路径(比如d:\hadoop-3.1.0)
-
新建HADOOP_HOME环境变量,值就是保存hadoop的目录。
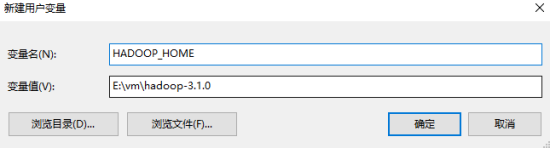
效果如下:
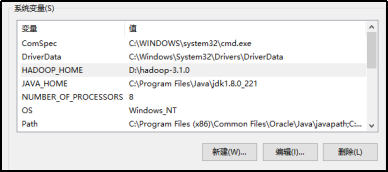
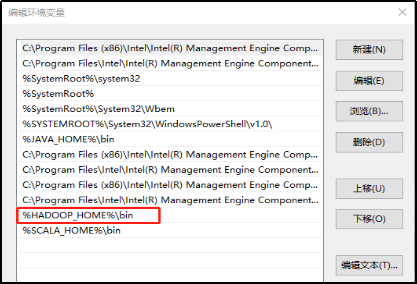
3.配置Path环境变量。
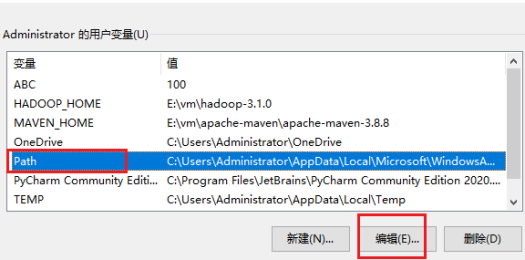
新建一个
4.验证Hadoop环境变量是否正常。

(二)不配置环境变量的影响
不配置 HADOOP_HOME
• 无法直接使用 Hadoop 命令:不配置 HADOOP_HOME 及其 PATH,你就不能在命令行直接使用 hadoop、hdfs 等命令,每次使用都得指定完整的命令路径,这会让操作变得麻烦。
• Hadoop 相关脚本无法正常运行:Hadoop 的一些启动脚本依赖于 HADOOP_HOME 环境变量,不配置的话这些脚本可能无法正常工作。
不配置 MAVEN_HOME
• 无法直接使用 Maven 命令:不配置 MAVEN_HOME 及其 PATH,你就不能在命令行直接使用 mvn 命令,同样每次使用都得指定完整的命令路径。
• IDE 无法自动识别 Maven:如果你使用 IDE(如 IntelliJ IDEA、Eclipse)进行开发,IDE 可能无法自动识别 Maven,也就无法正常使用 Maven 进行项目管理和依赖管理。