一、引言
近年来,大型语言模型(LLMs)在自然语言处理领域取得了突破性进展,展现出惊人的能力。然而,LLMs 的巨大参数量和计算需求带来了高昂的部署成本和推理延迟,限制了它们在资源受限环境(如边缘设备)或需要低延迟场景下的应用。
模型量化技术应运而生,旨在通过降低模型参数的数值精度(例如,从 FP16/BF16 转换为 INT8 或 INT4)来压缩模型大小、减少内存占用并加速推理,同时尽可能地保持模型精度。
在众多量化方案中,后训练量化(Post-Training Quantization, PTQ)因其无需重新训练、简单高效而备受关注。GPTQ (Generative Pre-trained Transformer Quantization) 和 AWQ (Activation-aware Weight Quantization) 是目前业界领先的两种 PTQ 技术。
什么是量化?
大语言模型(LLM)由一系列权重和激活值构成。这些数值通常采用 32 位浮点型(float32)数据类型表示。
位数决定了数值表示能力:
-
float32 可表示 1.18e-38 至 3.4e38 之间的数值,覆盖范围极广!
-
位数越少,可表示的数值范围越窄。
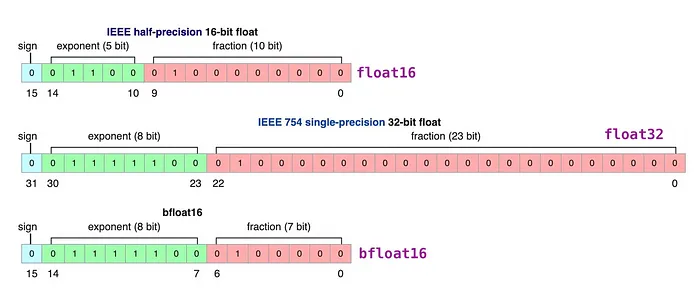
选择更低的位数会导致模型精度下降,但同时也减少了需表示的数值量,从而降低模型体积和内存需求。
量化技术的核心价值 :
量化是降低模型内存占用最有效的方法之一,可视为大语言模型的专用压缩技术。其核心目标是降低模型权重的精度:
-
典型操作:将权重从 16 位降至 8 位、4 位甚至 3 位。
-
技术关键:并非简单使用更小位数,而是通过映射算法在不丢失过多信息的前提下,将较大位表示转换为较小位。
为什么需要量化?
-
内存占用巨大: 一个 7B 参数的 Llama 2 模型,使用 FP16 精度存储需要约 14GB 显存,而 70B 模型则需要约 140GB 显存,这对于大多数消费级 GPU 甚至许多服务器级 GPU 来说都是巨大的挑战。
-
推理速度受限: 模型越大,计算量越大,推理所需时间越长,难以满足实时交互等低延迟需求。
-
部署成本高昂: 高显存、高性能的 GPU 硬件成本和能耗成本都非常高。
量化通过使用更少的比特位数来表示权重和/或激活值,可以:
-
显著减小模型大小: INT4 量化相比 FP16 可以将模型大小压缩近 4 倍。
-
大幅降低显存占用: 更小的模型意味着更低的运行时显存需求。
-
加速模型推理: 低比特运算通常更快,尤其是在支持 INT8/INT4 计算的现代硬件(如 NVIDIA Tensor Cores)上,可以利用专门的硬件指令集实现显著加速。
二、GPTQ: 基于近似二阶信息的逐层量化
核心思想
GPTQ 是一种基于量化误差最小化的 PTQ 方法。其核心思想是逐层 对模型权重进行量化,并在量化过程中,利用**近似的二阶信息(Hessian 矩阵的逆)**来更新剩余未量化的权重,以补偿当前层量化引入的误差。这种方法试图找到最佳的量化舍入策略,而不仅仅是简单的"四舍五入到最近"。
关键点:
-
逐层量化 (Layer-wise): 独立量化模型的每一层。
-
误差补偿: 量化当前层的权重后,根据其对后续层输出的影响(通过 Hessian 矩阵近似估计),调整剩余未量化层的权重,以最小化累积误差。
-
权重更新顺序: GPTQ 发现权重的量化顺序很重要,它会优先量化那些对模型输出影响较小的权重列。
-
分组量化 (Group Size): 为了在精度和压缩率之间取得平衡,GPTQ 通常将权重分组(例如,每 128 个值共享一组量化参数),而不是对每个权重使用独立的量化参数。
实践环节:使用 AutoGPTQ 库进行量化
AutoGPTQ 是一个易于使用的库,集成了 GPTQ 算法,并能与 transformers 无缝对接。
1. 环境准备:
bash
pip install transformers optimum accelerate auto-gptq # 确保安装支持 CUDA 的 torch
# 可能需要根据你的 CUDA 版本从源码编译 auto-gptq 以获得最佳性能
# git clone https://github.com/PanQiWei/AutoGPTQ.git
# cd AutoGPTQ
# pip install .2. 量化代码:
假设我们想量化 facebook/opt-125m 模型到 INT4。
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
from optimum.gptq import GPTQQuantizer # 使用 optimum 提供的接口更方便
import time
# --- 配置参数 ---
model_id = "facebook/opt-125m" # 替换为你需要量化的模型 ID
quantized_model_dir = f"{model_id}-GPTQ-4bit"
bits = 4 # 量化比特数
group_size = 128 # 权重分组大小
damp_percent = 0.01 # GPTQ 阻尼参数,防止 Hessian 逆矩阵计算不稳定
dataset_name = "wikitext2" # 校准数据集,用于计算量化参数和 Hessian 信息
num_samples = 128 # 校准样本数量
seq_len = 512 # 校准序列长度
# --- 加载模型和 Tokenizer ---
print(f"Loading base model: {model_id}")
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True)
# 使用 trust_remote_code=True 如果模型结构定义在远程代码中 (例如 Llama)
model = AutoModelForCausalLM.from_pretrained(model_id,
torch_dtype=torch.float16, # 建议使用 float16 加载
device_map="auto", # 自动分配到可用 GPU
trust_remote_code=True)
print("Model loaded.")
# --- 准备校准数据集 ---
# optimum 的 GPTQQuantizer 会自动处理数据集加载和预处理
# 这里仅作概念展示,实际使用时传入 dataset_name 即可
# from datasets import load_dataset
# dataset = load_dataset(dataset_name, split="train[:%d]" % num_samples)
# tokenized_dataset = dataset.map(lambda examples: tokenizer(examples["text"], max_length=seq_len, truncation=True, padding='max_length'), batched=True)
# --- 创建 GPTQ 配置 ---
# `use_exllama=False` 可以兼容更多 GPU,但 exllama kernel 推理更快
# `desc_act=False` 是否按激活顺序量化(通常 group_size 较小时效果好,但 AWQ 更关注激活)
gptq_config = GPTQConfig(bits=bits,
group_size=group_size,
dataset=dataset_name, # 直接传入数据集名称
tokenizer=tokenizer, # 传入 tokenizer 用于处理数据集
damp_percent=damp_percent,
desc_act=False, # GPTQ 原始论文设置为 False
sym=True, # 对称量化通常对权重效果更好
true_sequential=True, # 确保严格按顺序量化
use_exllama=False, # 设为 False 兼容性更好,设为 True 可能需要特定编译
)
# --- 执行量化 ---
print("Starting quantization...")
start_time = time.time()
# 使用 optimum 的 Quantizer
quantizer = GPTQQuantizer(bits=bits,
group_size=group_size,
dataset=dataset_name,
model_seqlen=seq_len,
block_name_to_quantize=None, # 量化所有线性层 (通常)
damp_percent=damp_percent,
desc_act=False,
sym=True,
true_sequential=True,
)
quantizer.quantize_model(model, tokenizer)
end_time = time.time()
print(f"Quantization finished in {end_time - start_time:.2f} seconds.")
# --- 保存量化后的模型和 Tokenizer ---
print(f"Saving quantized model to {quantized_model_dir}")
# 注意:Optimum 推荐的保存方式是直接使用 quantizer.save()
# model.save_pretrained(quantized_model_dir) # 这是 transformers 的标准保存,但对 GPTQ 配置可能不完整
quantizer.save(model, quantized_model_dir) # 保存模型权重和量化配置
tokenizer.save_pretrained(quantized_model_dir) # 保存 tokenizer
print("Quantized model saved.")
# --- (可选) 测试加载和推理 ---
print("Loading quantized model for testing...")
quantized_model = AutoModelForCausalLM.from_pretrained(
quantized_model_dir,
device_map="auto", # 加载到 GPU
torch_dtype=torch.float16, # 推理时也常用 float16
trust_remote_code=True
)
print("Quantized model loaded.")
text = "Hello, my name is"
inputs = tokenizer(text, return_tensors="pt").to(quantized_model.device)
outputs = quantized_model.generate(**inputs, max_new_tokens=50)
print("Generated text:", tokenizer.decode(outputs[0], skip_special_tokens=True))3. 代码解读:
-
model_id: 指定要量化的预训练模型。 -
bits: 目标量化位数,通常为 4 或 8。 -
group_size: 将多少个权重参数视为一组,共享相同的量化缩放因子 (scale) 和零点 (zero-point)。较小的group_size通常精度更高,但压缩率略低,计算开销略大。-1 表示逐通道量化 (per-channel)。 -
damp_percent: GPTQ 算法中的阻尼因子,用于稳定 Hessian 逆矩阵的计算,防止除以过小的特征值。 -
dataset: 校准数据集的名称或路径。GPTQ 使用这个数据集来计算权重的二阶信息(Hessian 矩阵)和量化参数。数据集的选择对量化后模型的性能有一定影响,通常选择与目标任务领域相似的数据。 -
num_samples,seq_len: 用于校准的数据量和序列长度。 -
GPTQConfig: 封装所有 GPTQ 相关参数的对象。optimum库简化了这个过程。 -
GPTQQuantizer:optimum提供的 GPTQ 量化器类。 -
quantize_model(): 执行核心量化过程。 -
quantizer.save(): 保存量化后的模型权重和quantization_config.json文件,该文件包含了加载量化模型所需的所有元信息。
4. 执行结果 :
-
模型大小:
opt-125mFP16 模型约 250MB,INT4 量化后模型大小约为 70-80MB(取决于 group_size 和其他元数据),显著减小。 -
显存占用: 加载量化模型所需的显存大幅降低。
-
量化时间: 取决于模型大小、GPU 性能和校准数据集大小,对于
opt-125m可能需要几分钟到十几分钟。 -
推理速度: 使用优化的推理后端(如
exllama或vLLM支持的 GPTQ kernel)时,相比 FP16 会有显著加速。单纯使用transformers加载可能加速不明显,因为它可能没有使用最优化的 INT4 计算核。 -
精度: 对于
opt-125m这种小模型,4bit 量化可能会观察到一些精度下降,但通常仍在可用范围内。对于更大的模型(如 7B+),GPTQ 4bit 通常能保持相当好的性能。
三、AWQ: 激活感知权重优先量化
核心思想
AWQ (Activation-aware Weight Quantization) 的出发点不同于 GPTQ。它观察到一个现象:LLM 中约 0.1%~1% 的权重对模型性能至关重要,而这些权重往往与较大的激活值(activation magnitudes)相关联。如果直接量化这些 "显著权重" (salient weights),会导致较大的精度损失。
因此,AWQ 的核心策略是:
-
识别显著权重: 通过分析校准数据集上的激活值分布,找到那些对应较大激活值的权重通道。
-
保护显著权重: 不量化这部分(通常占比较小,如 1%)对模型性能影响最大的权重,或者对它们使用更高的精度。在实践中,AWQ 并非完全跳过量化,而是通过缩放 (scaling) 的方式来保护它们。
-
权重缩放: 对每个通道的权重进行缩放,使得权重的动态范围更适合量化,特别是减小那些显著权重在量化前的绝对值,从而降低量化误差。这个缩放因子会在推理时乘回到激活值上,保持数学等价性。
-
量化非显著权重: 对剩余的大部分权重进行低比特量化(如 INT4)。
优势:
-
量化速度快: AWQ 主要涉及分析激活值和权重缩放,计算复杂度低于 GPTQ 计算 Hessian 逆矩阵。
-
精度保持良好: 通过保护重要权重,AWQ 在低比特(尤其是 INT4)下也能取得很好的性能。
-
硬件友好: AWQ 的量化格式(通常是 per-channel scaling)相对规则,易于实现高效的推理 kernel。
实践环节:使用 autoawq 库进行量化
autoawq 是官方推荐的 AWQ 实现库。
1. 环境准备:
bash
pip install transformers torch accelerate autoawq # 确保 torch 支持 CUDA2. 量化代码:
同样以 facebook/opt-125m 为例。
python
import torch
from awq import AutoAWQForCausalLM # 注意这里导入的是 AutoAWQForCausalLM
from transformers import AutoTokenizer
import time
# --- 配置参数 ---
model_id = "facebook/opt-125m" # 替换为你需要量化的模型 ID
quantized_model_dir = f"{model_id}-AWQ-4bit"
quant_config = {
"w_bit": 4, # 权重比特数
"q_group_size": 128, # 分组大小
"zero_point": True, # 是否使用零点 (AWQ 推荐 True 以获得更好性能)
"version": "GEMM" # AWQ kernel 版本,"GEMM" 适用于多数情况,"GEMV" 可能用于特定场景
}
# 校准数据集和样本数,AWQ 内部使用少量样本(如 128 条)即可
# AWQ 会自动从 "mit-han-lab/pile-10k" 加载数据,如果需要自定义参考其文档
# --- 加载模型和 Tokenizer ---
print(f"Loading base model: {model_id}")
# AWQ 加载时通常直接指定量化配置进行转换
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoAWQForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True, # 优化 CPU 内存使用
device_map="auto", # 如果内存不足,量化过程会更慢
trust_remote_code=True
)
print("Model loaded.")
# --- 执行量化 ---
print("Starting quantization...")
start_time = time.time()
# AWQ 量化是模型加载后调用 quantize 方法
model.quantize(tokenizer, quant_config=quant_config)
end_time = time.time()
print(f"Quantization finished in {end_time - start_time:.2f} seconds.")
# --- 保存量化后的模型和 Tokenizer ---
# AWQ 模型需要特殊的保存方式来包含量化参数和 kernel 信息
print(f"Saving quantized model to {quantized_model_dir}")
# 使用 model.save_quantized 方法
model.save_quantized(quantized_model_dir)
tokenizer.save_pretrained(quantized_model_dir) # Tokenizer 正常保存
print("Quantized model saved.")
# --- (可选) 测试加载和推理 ---
print("Loading quantized model for testing...")
# 加载 AWQ 模型也需要使用 AutoAWQForCausalLM
quantized_model = AutoAWQForCausalLM.from_quantized(
quantized_model_dir,
fuse_layers=True, # 使用 AWQ 优化的 fused kernels 加速推理
device_map="auto", # 加载到 GPU
trust_remote_code=True
)
print("Quantized model loaded.")
text = "Hello, my name is"
inputs = tokenizer(text, return_tensors="pt").to(quantized_model.device)
# 使用 AWQ 模型进行推理
outputs = quantized_model.generate(**inputs, max_new_tokens=50)
print("Generated text:", tokenizer.decode(outputs[0], skip_special_tokens=True))3. 代码解读:
-
AutoAWQForCausalLM:autoawq库提供的类,用于加载、量化和保存 AWQ 模型。 -
quant_config: 包含 AWQ 量化参数的字典。-
w_bit: 目标权重比特数。 -
q_group_size: 分组大小,与 GPTQ 类似。 -
zero_point: 是否使用非对称量化(即包含零点)。AWQ 论文表明使用True通常效果更好。 -
version: 指定使用的 AWQ kernel 类型,影响性能和兼容性。GEMM是通用且推荐的。
-
-
model.quantize(): 对已加载的 FP16 模型执行 AWQ 量化。它内部会处理校准数据的加载和激活分析。 -
model.save_quantized(): AWQ 模型专用的保存方法,确保所有量化元数据和配置被正确保存。 -
AutoAWQForCausalLM.from_quantized(): 加载已保存的 AWQ 量化模型。 -
fuse_layers=True: 加载时启用 AWQ 的融合层 (fused layers) 可以显著提升推理速度,因为它使用了高度优化的 CUDA kernel。
4. 执行结果 (预期):
-
模型大小: 与 GPTQ 类似,INT4 量化后大小显著减小。
-
显存占用: 大幅降低。
-
量化时间: 通常比 GPTQ 快,因为计算复杂度较低。对于
opt-125m可能只需要几分钟。 -
推理速度: 使用
fuse_layers=True加载时,AWQ 的推理速度通常非常快,可能优于未优化的 GPTQ kernel。 -
精度: AWQ 在 4bit 下通常能保持非常好的性能,尤其是在保护关键权重方面表现突出。
四、GPTQ vs. AWQ 对比分析
|-----------|----------------------------|--------------------------------------------|
| 特性 | GPTQ | AWQ |
| 核心原理 | 基于量化误差最小化,利用近似二阶信息补偿误差 | 基于激活感知,保护显著权重,对权重进行缩放 |
| 量化过程 | 逐层量化,更新剩余权重 | 分析激活,缩放权重,然后量化 |
| 计算复杂度 | 较高 (涉及 Hessian 逆矩阵近似计算) | 较低 (主要涉及激活统计和缩放) |
| 量化速度 | 相对较慢 | 相对较快 |
| 精度保持 | 通常很好,尤其在 6B+ 模型上 | 通常很好,尤其擅长保护对性能影响大的权重 |
| 推理速度 | 取决于 Kernel 实现 (Exllama 快) | 通常很快,尤其使用 Fused Kernels (fuse_layers=True) |
| 显存占用 | 类似 (取决于 bits 和 group_size) | 类似 (取决于 bits 和 group_size) |
| 主要库 | auto-gptq, optimum | autoawq |
| 适用场景 | 需要高精度,对量化时间不敏感 | 需要快速量化,关注推理速度和精度保持 |
| 实现细节 | 依赖校准数据计算 Hessian | 依赖校准数据分析激活分布 |
总结:
-
选型考虑:
-
如果量化时间是关键瓶颈,AWQ 是更好的选择。
-
如果追求极致的精度,并且有足够的时间进行量化,GPTQ 可能是个选择(尽管 AWQ 精度也非常接近甚至有时更好)。
-
对于推理速度 ,两者都需要配合优化的推理引擎/Kernel 才能发挥最大优势。AWQ 的
autoawq库自带了优化的 Fused Kernels,易用性上可能稍好。GPTQ 则常与Exllama,vLLM等后端结合使用。 -
易用性: 两者的库 (
auto-gptq/optimum和autoawq) 都做得相对简单易用。
-
-
重要趋势: AWQ 由于其较快的量化速度和良好的性能,正变得越来越受欢迎。许多模型(如 Mixtral, Llama 等)现在都有官方或社区提供的 AWQ 量化版本。
五、部署优化策略
仅仅完成量化是不够的,高效部署量化模型同样关键
选择合适的推理引擎:
vLLM: 一个非常流行的 LLM 推理和服务框架,支持 PagedAttention 等技术,对 AWQ 和 GPTQ (通过 pip install vllm[gptq] 或原生支持) 都有较好的支持,能显著提升吞吐量和降低延迟。
TensorRT-LLM: NVIDIA 官方推出的高性能 LLM 推理库,支持多种量化方式(包括 INT4/INT8 权重仅量化、SmoothQuant 等),可以编译生成高度优化的 TensorRT 引擎。它对 AWQ 和类 GPTQ 的 INT4 权重仅量化有很好的支持。编译过程相对复杂,但性能通常是顶尖的。
Text Generation Inference (TGI): Hugging Face 开发的推理服务器,支持多种模型和量化格式,包括 GPTQ 和 AWQ (需要特定分支或版本)。
llama.cpp: 主要面向 CPU 推理,但也支持 GPU。它使用自己的 GGUF 格式,支持多种量化方法(Q2_K, Q3_K, Q4_K, Q5_K, Q6_K, Q8_0 等),性能优异,跨平台性好。可以使用 convert.py 脚本将 GPTQ/AWQ 模型(通常先转回 FP16)转换为 GGUF 格式。
Exllama / Exllama v2: 专门为 GPTQ(尤其是 4-bit)量化模型设计的高效推理库,以其极低的显存占用和高速度著称。
使用优化的 Kernel:
无论是 GPTQ 还是 AWQ,其推理速度很大程度上依赖于底层计算 Kernel 的效率。AWQ 的 autoawq 库自带了 GEMM/GEMV kernel,并可通过 fuse_layers=True 启用。GPTQ 则需要依赖 exllama 或集成到 vLLM/TGI 等框架中的优化 Kernel。确保你使用的推理环境能调用这些优化 Kernel。
*
模型格式转换
对于追求极致性能的场景,可以将量化模型(有时需要先反量化回 FP16 再进行后续处理)转换为更底层的优化格式,如 ONNX 或直接编译成 TensorRT 引擎。这个过程通常需要额外的步骤和专业知识。
*
硬件选择:
现代 NVIDIA GPU(如 Ampere, Hopper 架构)对 INT8 和 FP8 运算有硬件加速(Tensor Cores)。虽然对 INT4 的直接硬件支持较少,但优化的 INT4 Kernel 仍能带来显著的速度提升。部署时选择合适的硬件至关重要。
*
部署流程 (使用 vLLM):
python
from vllm import LLM, SamplingParams
# 假设你已经保存了 AWQ 或 GPTQ 量化模型
# 对于 AWQ:
model_path = "./facebook/opt-125m-AWQ-4bit"
llm = LLM(model=model_path, quantization="awq", dtype="auto") # vLLM 自动识别 AWQ
# 对于 GPTQ (需要安装 vllm[gptq])
# model_path = "./facebook/opt-125m-GPTQ-4bit"
# llm = LLM(model=model_path, quantization="gptq", dtype="auto") # vLLM 识别 GPTQ
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95, max_tokens=50)
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")GPTQ 和 AWQ 作为当前主流的 PTQ 量化技术,极大地推动了大型语言模型在实际应用中的落地。它们都能在显著压缩模型、降低显存占用的同时,较好地保持模型性能。
-
GPTQ 通过引入二阶信息来优化量化过程,精度通常有保障。
-
AWQ 则另辟蹊径,通过保护激活显著的权重通道,实现了更快的量化速度和同样出色的性能,尤其在推理速度优化方面表现突出。
选择哪种方案取决于具体的应用需求,包括对量化时间、最终精度和推理速度的侧重。无论选择哪种方案,结合 vLLM、TensorRT-LLM 等高性能推理引擎进行部署优化,都是发挥量化模型潜力的关键一步。