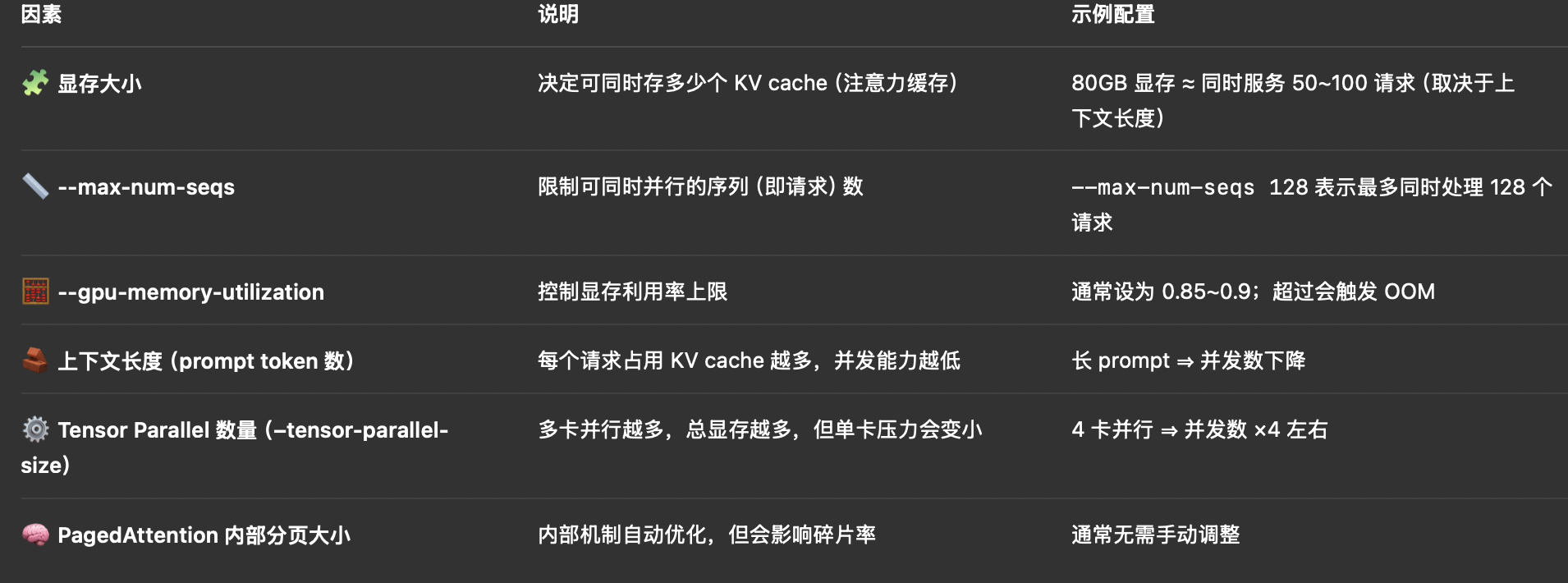
🧠 一、影响 vLLM 并发请求数的关键因素
⸻
🔍 二、实时查看当前并发请求数 / 队列情况
vLLM 本身有监控接口与日志输出,可以直接观察:
1️⃣ 查看日志输出
在你运行命令的终端或日志文件(例如你用的)
bash
nohup python3 -m vllm.entrypoints.openai.api_server ... > vllm_server.log 2>&1 &然后查看日志:
bash
tail -f vllm_server.log你会看到类似:
bash
INFO [Engine] num_requests_running=12 num_waiting=5 max_num_seqs=128解释:
• num_requests_running: 当前正在执行的请求数量
• num_waiting: 正在排队等待的请求数量
• max_num_seqs: 最大可同时运行请求数(来自你的配置)
⸻
2️⃣ 查看 HTTP 监控接口(推荐)
vLLM 启动后自带一个监控 API:
bash
GET http://localhost:8000/metrics执行命令查看:
bash
curl http://localhost:8000/metrics | grep vllm输出会包含 Prometheus 格式的监控指标,比如:
bash
vllm_running_requests 32
vllm_waiting_requests 8
vllm_num_finished_requests_total 1052
vllm_gpu_memory_usage_bytes 73400320000这几个指标直接告诉你当前:
• 有多少请求在运行
• 有多少在排队
• GPU 显存占用情况
你可以把这些 metrics 挂在 Prometheus + Grafana 做实时监控。
⸻
3️⃣ 代码中查看(OpenAI 兼容接口)
如果你在用 OpenAI 接口调用:
bash
openai.api_key = "none"
openai.base_url = "http://localhost:8000/v1"vLLM 会在负载过高时返回:
bash
{
"error": {
"message": "Server busy, please retry later",
"type": "server_overloaded"
}
}这表明当前已经达到 max-num-seqs 上限。
⸻
⚙️ 三、手动配置或限制最大并发请求数
1️⃣ 设置最大序列数
在启动命令中添加参数:
bash
--max-num-seqs 128👉 表示最多同时处理 128 个请求(包括生成和等待的 token 序列)。
2️⃣ 设置显存使用率上限
bash
--gpu-memory-utilization 0.9👉 vLLM 会在达到 90% 显存时拒绝新请求,自动排队或返回 "busy" 错误。
3️⃣ Nginx 层限流(上层防护)
在你的反向代理层可以加上:
bash
limit_conn_zone $binary_remote_addr zone=addr:10m;
limit_conn addr 20;
limit_req zone=req_limit_per_ip burst=5 nodelay;👉 限制每个客户端最多并发 20 个请求,超过的直接拒绝。
⸻
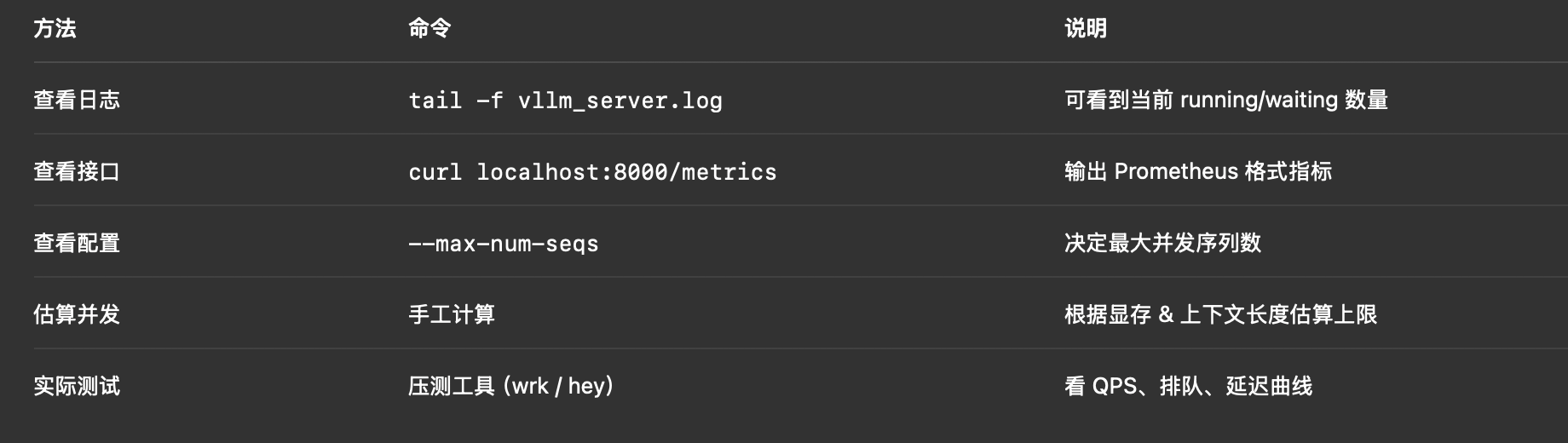
📈 四、估算最大可并发请求数
经验公式(粗略):
N m a x ≈ G P U _ 显存 ( G B ) × 利用率 上下文长度 × 0.001 N_{max} \approx \frac{GPU\_显存(GB) × 利用率}{上下文长度 × 0.001} Nmax≈上下文长度×0.001GPU_显存(GB)×利用率
例如:
参数 值
显存 80 GB
利用率 0.9
每请求上下文 2000 tokens
单 token KV cache ≈ 1 KB
⇒ 每请求占显存 ≈ 2MB
计算:
N m a x ≈ 80 × 0.9 × 1024 2 ≈ 36 , 864 ≈ 36 个请求(单卡) N_{max} ≈ \frac{80 × 0.9 × 1024}{2} ≈ 36,864 ≈ 36 个请求(单卡) Nmax≈280×0.9×1024≈36,864≈36个请求(单卡)
多卡(TP=4)约可达 120~150 个并发请求。
⸻
✅ 总结:查看并发能力的几种方式